模型更新
通过以上两节的学习,我们了解了推荐系统的基本组件和运行流程。然而在实际的生产环境中,因为种种原因,推荐系统必须经常性地对模型参数进行更新。在保证上亿在线用户的使用体验的前提下,更新超大规模推荐模型是极具挑战性的。本节首先介绍为何推荐系统需要持续更新模型参数,然后介绍一种主流的离线更新方法,以及一个支持在线更新的推荐系统。
持续更新模型的需求
在学习过程中,我们用到的数据集通常都是静态的,例如ImageNet [1],WikiText [2]。其中的数据分布通常是不变的,因此训练一个模型使其关键指标,如准确率(Accuracy)和困惑度(Perplexity),达到一定要求之后训练任务就结束了。然而在线服务中使用的推荐模型需要面临高度动态的场景。这里的动态主要指两个方面:
- 推荐模型所服务的用户和所囊括的物品是在不断变化的,每时每刻都会有新的用户和新的物品。如图 图12.3.1所示,如果嵌入表中没有新用户所对应的嵌入项,那么推荐模型就很难服务于这个用户;同理如果新加入的物品没有在推荐模型的嵌入表中,如图 图12.3.2所示,就无法出现在推荐流水线中,从而导致不能被推荐给目标用户。
- 推荐模型所面临的用户兴趣是在不断变化的,如果推荐模型不能及时地改变权重以适应用户新的兴趣,那么推荐效果就会下降。例如在一个新闻推荐的应用中,每天的热点新闻都是不一样的,如果推荐模型总是推荐旧的热点,用户的点击率就会持续下降。

图12.3.1 用户嵌入项缺失
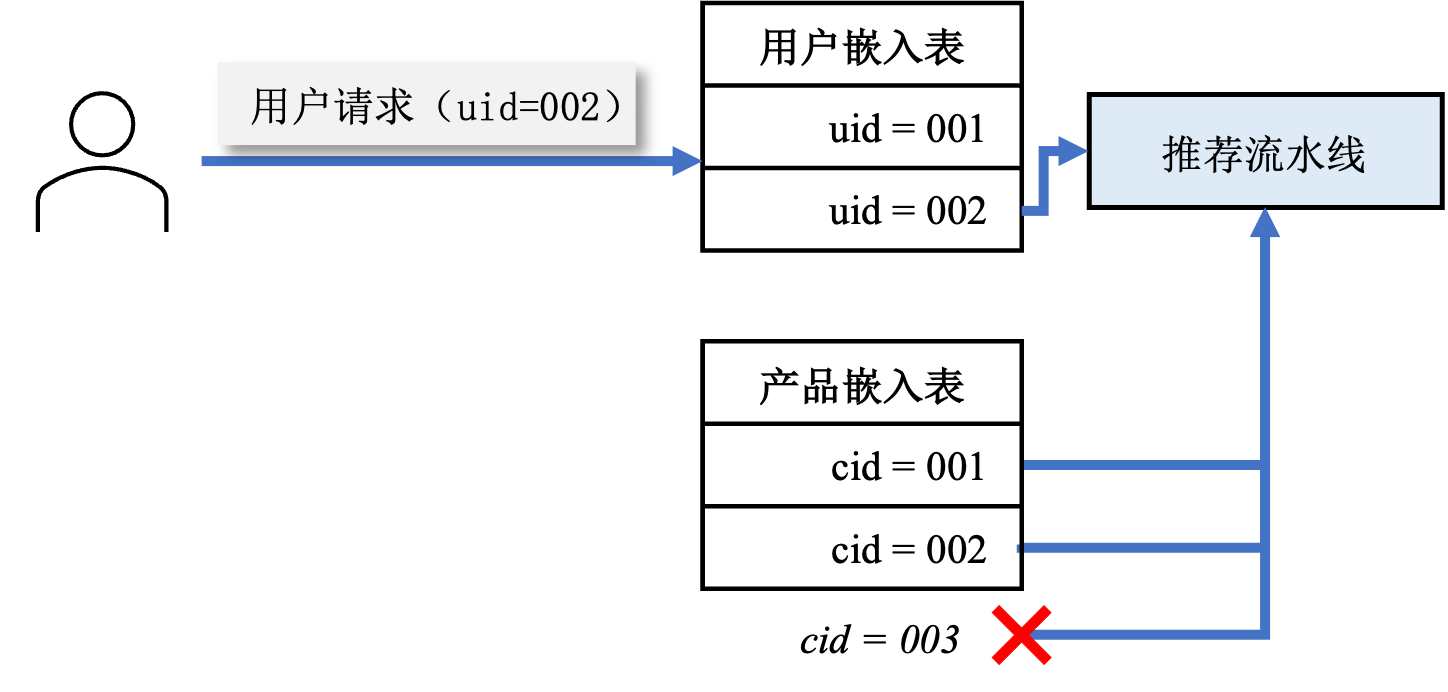
图12.3.2 物品嵌入项缺失
以上问题虽然也可以通过人工制定的规则来处理,例如,在直接在推荐结果中加入新物品,或者基于统计的热点物品,但是这些规则只能在短时间内一定程度上缓解问题,而不能彻底解决问题,因为基于人工规则的推荐性能和推荐模型存在较大差距。
离线更新
传统的推荐系统采用基于模型检查点的离线更新的方式,更新频率从每天到每小时不等,如图 图12.3.3所示。
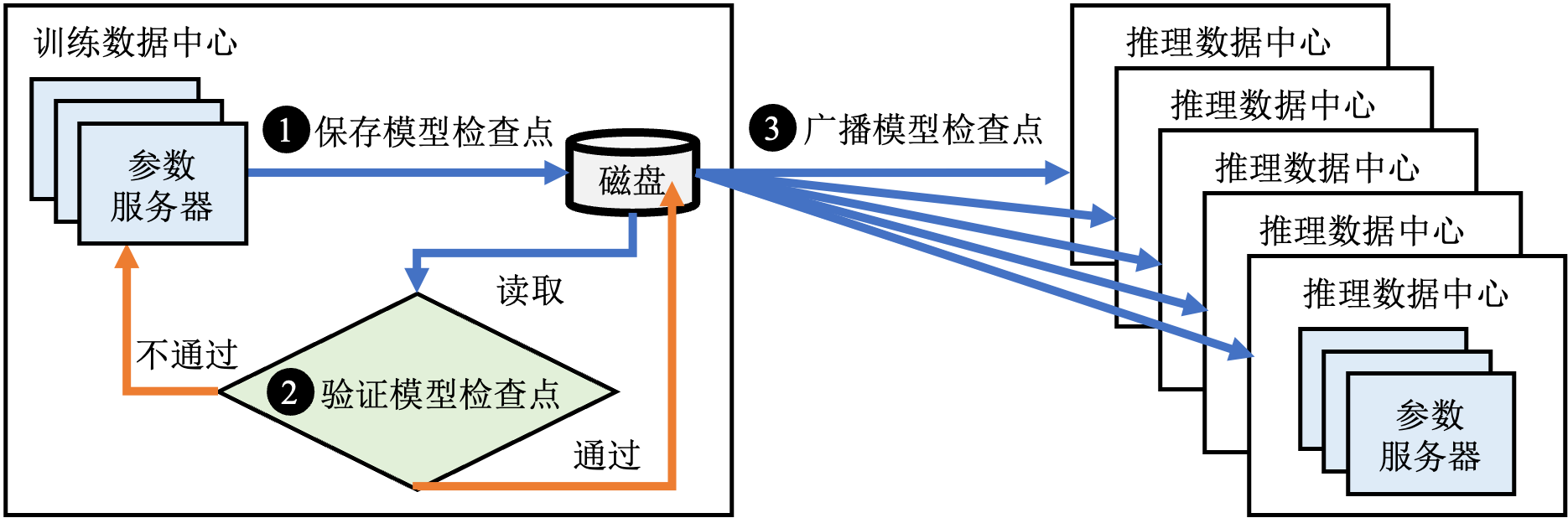
图12.3.3 离线更新
具体来讲,在训练一段时间之后,有如下步骤:
- 从训练数据中心的参数服务器上保存一份模型检查点到磁盘中;
- 基于离线数据集对模型检查点进行验证,如果离线验证不通过则继续训练;
- 如果离线验证通过,则将检查点以广播的方式发送到所有的推理数据中心。
这一流程耗费的时间从数分钟到数小时不等。也有一些系统对保存和发送检查点的过程进行了优化,可以做到分钟级模型更新。
然而随着互联网服务的进一步发展,分钟级的模型更新间隔在一些场景下依然是远远不够的:
- 一些应用非常看重其中物品的实时性。例如在短视频推荐场景下,内容创作者可能会根据实时热点创作视频,如果这些视频不能被及时推荐出去,等热点稍过观看量可能会远远不及预期。
- 无法获取用户特征或者特征有限的场景。近年来,随着用户隐私保护意识的增长和相关数据保护法规的完善,用户常常倾向于匿名使用应用,或者尽量少地提供非必要的数据。这就使得推荐系统需要在用户使用的这段极短的时间内时间内在线学习到用户的兴趣。
- 需要使用在线训练范式的场景。传统的推荐系统通常采用离线训练的方式,即累计一段时间(例如,一天)的训练数据来训练模型,并将训练好的模型在低峰期(例如,凌晨)上线。最近越来越多的研究和实践表明,增大训练频率可以有效提升推荐效果。将训练频率增加到最高的结果就是在线训练,即流式处理训练数据并送给模型,模型持续地基于在线样本调整参数,模型更新被即时用于服务于用户。模型更新作为在线训练的一个主要环节,必须要降低延迟以达到更好的训练效果。
在下一小节,我们将详细分析一个前沿的推荐系统是如何解决模型快速更新的问题的。
参考文献
- Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael. Imagenet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV). 2015. ↩
- Merity, Stephen and Xiong, Caiming and Bradbury, James and Socher, Richard. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843. 2016. ↩