机器学习系统:设计和实现(第一版)



金雪锋
MindSpore架构师













张清华
华为工程师

梁志博
华为工程师

余坚峰
华为工程师

褚金锦
华为工程师

蔡福璧
华为工程师

张任伟
华为工程师

刘超
华为工程师

陈钢
华为工程师

黎明奇
华为工程师

韩刚强
华为工程师

唐业辉
华为工程师

翟智强
华为工程师

吴天诚
华为工程师

李小慧
华为工程师

李昊阳
华为工程师

谭志鹏
华为工程师

李姗妮
华为工程师

郭志建
华为工程师
目录
- 前言
- 基础篇
- 进阶篇
- 拓展篇
- 附录
前言
缘起
我在2020年来到了爱丁堡大学信息学院,爱丁堡大学是AI(Artificial Intelligence, 人工智能)研究的发源地之一,很多学生慕名而来学习机器学习技术。爱丁堡大学拥有许多出色的机器学习课程(如自然语言处理、计算机视觉、计算神经学等),同时也拥有一系列关于计算机系统的基础课程(如操作系统、编程语言、编译器、计算机体系架构等)。但是当我在教学的过程中问起学生:机器学习是如何利用计算机系统实现计算加速和部署?许多学生会投来疑惑的眼神。这促使我思考在爱丁堡大学乃至于其他世界顶尖大学的教学大纲中,是不是缺一门衔接机器学习和计算机系统的课程。
我的第一反应是基于一门已有的课程来进行拓展。那时,加州大学伯克利分校的AI Systems(人工智能系统)课程较为知名。这门课描述了机器学习系统的不同研究方向,内容以研读论文为主。可惜的是,许多论文已经无法经受住时间的检验。更重要的是,这门课缺乏对于知识的整体梳理,未能形成完整的知识体系架构。学习完这门课程,学生未能对于从头搭建机器学习系统有明确的思路。我将目光投向其他学校,华盛顿大学曾短期开过Deep Learning Systems(深度学习系统)课程,这门课程讲述了机器学习程序的编译过程。而由于这门课程以讲述Apache TVM深度学习编译器为主要目的,对于机器学习系统缺乏完整的教学。另外,斯坦福大学的课程Machine Learning Systems Design(机器学习系统设计)因为课程设计人的研究领域以数据库为主,因此该课程专注于数据清洗、数据管理、数据标注等主题。
当时觉得比较合适的是微软亚洲研究院的AI Systems课程。这门课程讲述了机器学习系统背后的设计理念。但是当我准备将其教授给本科生的时候,我发现这门课对于机器学习系统核心设计理念讲解得很浅,同时要求学生有大量计算机系统的背景知识,实际上它更适合教授给博士生。上述的课程共同问题是:其课程结构都以研读相关论文为主,因此教授的内容都是高深和零散的,而不是通俗易懂,知识脉络清晰的教科书,这给学习机器学习系统造成了极大的困难。
回首2020年,我们已经拥有了优秀的操作系统、数据库、分布式系统等基础性教材。同时,在机器学习相关算法方面也有了一系列教材。然而,无论是国内外,我很难找到一本系统性讲述机器学习系统的教材。因此,许多公司和高校实验室不得不花费大量的人力和物力从头培养学生和工程师,使他们加强对于机器学习底层基础设施的认识。这类教材的缺乏已经制约了高校的人才培养,不利于高校培养出符合业界学界和时代发展的人才了。因此,我开始思考:我们是不是应该推出一本机器学习系统的教科书了呢?
开端
带着写书的构想,我开始和朋友沟通。大家都非常认可编写这类书的巨大价值,但是现实的情况是:很少有人愿意做这么一件费力的事情。我当时的博士后导师也劝我:你现在处在教职生涯的初期,追求高影响力的学术论文是当务之急,写一本书要耗费大量的时间和精力,最后可能也无法出版面世。而我和同行交流时也发现:他们更愿意改进市面上已经有的教科书,即做有迹可循的事情,而不是摸着石头过河,做从无到有的事情。特别是对于机器学习系统这个快速发展,频繁试错的领域,能不能写出经受时间检验的书也是一个未知数。
考虑到写作的巨大挑战,我将写书的想法藏于心中,直到一次回国和MindSpore的架构师金雪锋聊天。和雪锋的相识大约是在2019年的圣诞节,雪锋来伦敦访问,他正在领导MindSpore的开发(当时MindSpore 1.0还没有发布)。而对于机器学习系统的开发,我也有很深的兴趣。我在2018年也和好友一起从头搭建一个机器学习框架(类似于PyTorch),虽然最终资源不足无疾而终,不过许多的思考成就了我之后发表的多篇机器学习系统论文。和雪锋聊起来,我们都对AI系统开发之难深有同感。我们共同的感慨就是:找到懂机器学习系统开发的人太难了。现今的学生都一心学习机器学习算法,很多学生对于底层的运作原理理解得很浅。而当他们在实际中应用机器学习技术时才意识到系统的重要性,那时想去学习,却没有了充沛的学习时间。我对雪锋苦笑道:“我是准备写一本机器学习系统教材的,但是可能还要等3,4年才能完成。” 雪锋说:“我也有这个想法啊。你要是写的话,我能帮助到你吗?”
这句话点醒了我。传统的图书写作,往往依赖于一,两个教授将学科十余年的发展慢慢总结整理成书。这种模式类似于传统软件开发的瀑布流方式。可是,在科技的世界,这已经变了!软件的发展从传统的瀑布流进化到如今的开源敏捷开发。而图书的写作为什么还要停留在传统方式呢?MXNet开源社区编写的专注于深度学习算法的图书Deep Dive into Deep Learning就是一个很好的例子啊。我因此马上找到当年一起创立TensorLayer开源社区的小伙伴:北京大学的董豪,我们一拍即合,说干就干。雪锋也很高兴我和董豪愿意开始做这件事,也邀请了他的同事干志良来帮忙。我们终于开始图书的写作了!
经过几轮的讨论,我们将书名定为《机器学习系统:设计和实现》。我们希望通过教给学生机器学习系统设计原理,同时也为学生提供大量的系统实现经验分享,让他们在将来工作和科研中遇到实际问题知道该如何分析和解决。
社区的构建
考虑到机器学习系统本身就是一个不断发展并且孕育细分领域的学科。我从一开始就在思考:如何设计一个可扩展(Scalable)的社区架构保证这本书的可持续发展呢?因为我专注于大规模软件系统,故决定借鉴几个分布式系统的设计要点构建社区:
-
预防单点故障和瓶颈:现代分布式系统往往采用控制层和数据层分离的设计避免单点故障和瓶颈。那么我们在设计高度可扩展的写作社区的时候也要如此。因此,我们设计了如下分布式机制:编辑决定花最多的时间来寻找优秀的、主动的、负责任的书稿章节负责人。章节负责人可以进一步寻找其他作者共同协作。章节负责人和章节作者进行密切的沟通,按照给定时间节点,全速异步推进。编辑和章节负责人设定了每周讨论同步写作的进展,确保并行完成的章节内容质量能够持续符合编辑和社区的整体预期。
-
迭代式改进:深度学习的优化算法随机梯度下降本质上是在复杂问题中利用局部梯度进行海量迭代,最终找到局部最优解。因此我利用了同样的思路设计图书质量的迭代提高。我们首先在Overleaf上写作好书籍的初版(类似于初始参数)。接下来,将图书的内容做成标准的Git代码仓库。建立机制鼓励开源社区和广大读者开启GitHub问题(Issue)和拉取请求(Pull Request,PR),持续改进图书质量,而我们设置好完善的书籍构建工具、持续集成工具、贡献者讨论会等,就可以让图书的质量持续提高实现随机梯度下降(Stochastic Gradient Descent)一样的结果最优性。
-
高可用性:构建7 \(\times\) 24小时在线的写作平台,让图书参与者可以在全球任何时区、任何语言平台下都能参与开发图书,倾听社区的反馈。因此将Git仓库放置在GitHub上,并准备之后在Gitee做好镜像。这样,就搭建了一套高可用的写作平台了。
-
内容中立:一个分布式系统要能长久运行,其中的每一个节点都要同等对待,遇到故障才能用统一的办法进行故障恢复。考虑到图书写作中的故障(设计无法经受时间检验,写作人中途不得不退出等)可能来源于方方面面,我们让不同背景的参与者共同完成每一个章节,确保写出中立、客观、包容的内容,并且写作不会因为故障而中断。
现状和未来
机制一旦建立好,写作就自动化地跑起来了,参与者也越来越多,我带过的学生袁秀龙、丁子涵、符尧、任杰、梁文腾也很用心参与编写,董豪邀请了鹏城实验室的韩佳容和赖铖,志良邀请了许多MindSpore的小伙伴进来做贡献,许多资深的机器学习系统设计者也和我们在各个渠道展开讨论,提供了非常多宝贵的写作建议。另外,学界和产业界的反响也很热烈。海外很多优秀的学生(斯坦福大学的孙建凯、卡耐基梅隆大学的廖培元、剑桥大学的王瀚宸、爱丁堡大学的穆沛),产业界的朋友(英国葛兰素史克公司机器学习团队的肖凯严)都加入了我们的写作。同时,学界的教授(英国伦敦帝国理工学院的Peter Pietzuch教授、香港科技大学的陈雷教授等)也持续给我们提供了写作意见,改进了图书质量。
充分发动了“分布式系统”的力量后,图书的内容得以持续高质量地添加。当我们开源了图书以后,图书的受众快速增长,GitHub上关注度的增长让我们受宠若惊。在社区的推动下,图书的中文版、英文版、阿拉伯语版都已经开始推进。这么多年来,我第一次意识到我在分布式系统和机器学习中学习到的知识,在解决现实复杂问题的时候是如此的有用!
很多时候,当我们面对未知而巨大的困难时,个人的力量真的很渺小。而和朋友、社区一起就变成了强大的力量,让我们鼓起勇气,走出了最关键的第一步!希望我的一些思考,能给其他复杂问题的求解带来一些小小的启发。
截止2022年5月,本书已经拥有了以下贡献者参与了各章节的编写:导论(麦络、董豪、干志良)、编程模型(赖铖、麦络、董豪)、计算图(韩佳容、麦络、董豪)、AI编译器和前端技术(梁志博、张清华、黄炳坚、余坚峰、干志良)、AI编译器后端和运行时(褚金锦、穆沛、蔡福璧)、硬件加速器(张任伟、任杰、梁文腾、刘超、陈钢、黎明奇)、数据处理(袁秀龙)、模型部署(韩刚强、唐业辉、翟智强、李姗妮)、分布式训练(麦络、廖培元)、联邦学习系统(吴天诚、王瀚宸)、推荐系统(符尧、裴贝、麦络)、强化学习系统(丁子涵)、可解释AI系统(李昊阳、李小慧)、机器人系统(孙建凯、肖凯严)。
最后,我们非常欢迎新成员的加入以提升书籍质量,扩展内容。感兴趣的读者可以通过书籍的OpenMLSys社区 联系我们。我们非常期待和大家一起努力,编写出一本推动业界发展的机器学习系统图书!
麦络
英国爱丁堡
2022年5月4日
导论
本章将会介绍机器学习应用,梳理出机器学习系统的设计目标,总结出机器学习系统的基本组成原理,让读者对机器学习系统有自顶而下的全面了解。
机器学习应用
机器学习应用
通俗来讲,机器学习是指从数据中学习出有用知识的技术。以学习模式分类,机器学习可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)等。
- 监督学习是已知输入和输出的对应关系下的机器学习场景。比如给定输入图像和它对应的离散标签。
- 无监督学习是只有输入数据但不知道输出标签下的机器学习场景。比如给定一堆猫和狗的图像,自主学会猫和狗的分类,这种无监督分类也称为聚类(Clustering)。
- 强化学习则是给定一个学习环境和任务目标,算法自主地去不断改进自己以实现任务目标。比如 AlphaGo围棋就是用强化学习实现的,给定的环境是围棋的规则,而目标则是胜利得分。
从应用领域上划分,机器学习应用包括计算机视觉、自然语言处理和智能决策等。 狭义上来讲,基于图像的应用都可归为计算机视觉方面的应用,典型的应用有人脸识别、物体识别、目标跟踪、人体姿态估计、图像理解等。 计算机视觉方法广泛应用于自动驾驶、智慧城市、智慧安防等领域。
自然语言处理涉及文本或者语音方面的应用,典型的应用包括语言翻译、文本转语音、语音转文本、文本理解、图片风格变换等。 计算机视觉和自然语言处理有很多交集,如图像的文本描述生成、基于文本的图像生成、基于文本的图像处理等应用都同时涉及语言和图像两种数据类型。
智能决策的应用往往通过结合计算机视觉、自然语言处理、强化学习、控制论等技术手段,实现决策类任务。智能决策方法广泛用于机器人、自动驾驶、游戏、推荐系统、智能工厂、智能电网等领域。
不同的机器学习应用底层会应用不同的机器学习算法,如支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistic Regression)、朴素贝叶斯(Naive Bayes)算法等。近年来,得益于海量数据的普及,神经网络(Neural Networks)算法的进步和硬件加速器的成熟,深度学习(Deep Learning)开始蓬勃发展。虽然机器学习算法很多,但无论是经典算法还是深度学习算法的计算往往以向量和矩阵运算为主体,因此本书主要通过神经网络为例子展开机器学习系统的介绍。
机器学习框架的设计目标
机器学习框架的设计目标
为了支持在不同应用中高效开发机器学习算法,人们设计和实现了机器学习框架(如TensorFlow、PyTorch、MindSpore等)。广义来说,这些框架实现了以下共性的设计目标:
-
神经网络编程: 深度学习的巨大成功使得神经网络成为了许多机器学习应用的核心。根据应用的需求,人们需要定制不同的神经网络,如卷积神经网络(Convolutional Neural Networks)和自注意力神经网络(Self-Attention Neural Networks)等。这些神经网络需要一个共同的系统软件进行开发、训练和部署。
-
自动微分: 训练神经网络会具有模型参数。这些参数需要通过持续计算梯度(Gradients)迭代改进。梯度的计算往往需要结合训练数据、数据标注和损失函数(Loss Function)。考虑到大多数开发人员并不具备手工计算梯度的知识,机器学习框架需要根据开发人员给出的神经网络程序,全自动地计算梯度。这一过程被称之为自动微分。
-
数据管理和处理: 机器学习的核心是数据。这些数据包括训练、验证、测试数据集和模型参数。因此,需要系统本身支持数据读取、存储和预处理(例如数据增强和数据清洗)。
-
模型训练和部署: 为了让机器学习模型达到最佳的性能,需要使用优化方法(例如Mini-Batch SGD)来通过多步迭代反复计算梯度,这一过程称之为训练。训练完成后,需要将训练好的模型部署到推理设备。
-
硬件加速器: 神经网络的相关计算往往通过矩阵计算实现。这一类计算可以被硬件加速器(例如,通用图形处理器-GPU)加速。因此,机器学习系统需要高效利用多种硬件加速器。
-
分布式执行: 随着训练数据量和神经网络参数量的上升,机器学习系统的内存用量远远超过了单个机器可以提供的内存。因此,机器学习框架需要天然具备分布式执行的能力。
在设计机器学习框架之初,开发者曾尝试通过传统的神经网络开发库(如Theano和Caffe)、以及数据处理框架(如Apache Spark和Google Pregel)等方式达到以上设计目标。可是他们发现, 神经网络库虽然提供了神经网络开发、自动微分和硬件加速器的支持,但缺乏管理和处理大型数据集、模型部署和分布式执行的能力,无法满足当今产品级机器学习应用的开发任务。 另一方面,虽然并行数据计算框架具有成熟的分布式运行和数据管理能力,但缺乏对神经网络、自动微分和加速器的支持,并不适合开发以神经网络为核心的机器学习应用。
- 考虑到上述已有软件系统的种种不足,许多公司开发人员和大学研究人员开始从头设计和实现针对机器学习的软件框架。在短短数年间,机器学习框架如雨后春笋般出现(较为知名的例子包括TensorFlow、PyTorch、MindSpore、MXNet、PaddlePaddle、OneFlow、CNTK等),极大推进了人工智能在上下游产业中的发展。表 comparison_of_ml_frameworks 总结了机器学习框架和相关系统的区别。
-
机器学习框架和相关系统的区别
机器学习框架的基本组成原理
机器学习框架的基本组成原理
一个完整的机器学习框架一般具有如图 图1.3.1 所示的基本架构。
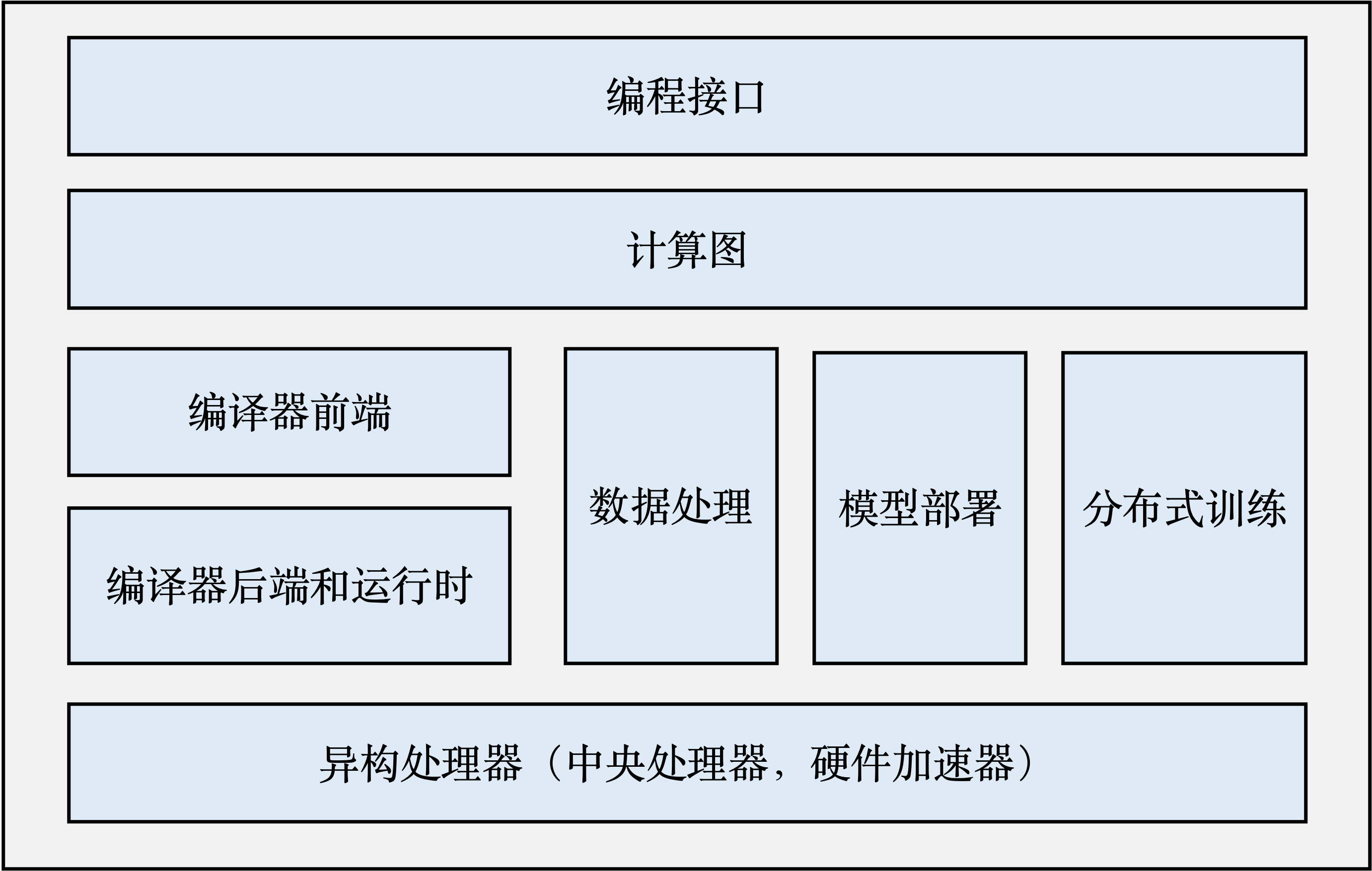
图1.3.1 机器学习框架基本构成
-
编程接口: 考虑到机器学习开发人员背景的多样性,机器学习框架首先需要提供以高层次编程语言(如Python)为主的编程接口。同时,机器学习框架为了优化运行性能,需要支持以低层次编程语言(如C和C++)为主的系统实现,从而实现操作系统(如线程管理和网络通讯等)和各类型硬件加速器的高效使用。
-
计算图: 利用不同编程接口实现的机器学习程序需要共享一个运行后端。实现这一后端的关键技术是计算图技术。计算图定义了用户的机器学习程序,其包含大量表达计算操作的算子节点(Operator Node),以及表达算子之间计算依赖的边(Edge)。
-
编译器前端: 机器学习框架往往具有AI编译器来构建计算图,并将计算图转换为硬件可以执行的程序。这个编译器首先会利用一系列编译器前端技术实现对程序的分析和优化。编译器前端的关键功能包括实现中间表示、自动微分、类型推导和静态分析等。
-
编译器后端和运行时: 完成计算图的分析和优化后,机器学习框架进一步利用编译器后端和运行时实现针对不同底层硬件的优化。常见的优化技术包括分析硬件的L2/L3缓存大小和指令流水线长度,优化算子的选择或者调度顺序。
-
异构处理器: 机器学习应用的执行由中央处理器(Central Processing Unit,CPU)和硬件加速器(如英伟达GPU、华为Ascend和谷歌TPU)共同完成。其中,非矩阵操作(如复杂的数据预处理和计算图的调度执行)由中央处理器完成。矩阵操作和部分频繁使用的机器学习算子(如Transformer算子和Convolution算子)由硬件加速器完成。
-
数据处理: 机器学习应用需要对原始数据进行复杂预处理,同时也需要管理大量的训练数据集、验证数据集和测试数据集。这一系列以数据为核心的操作由数据处理模块(例如TensorFlow的tf.data和PyTorch的DataLoader)完成。
-
模型部署: 在完成模型训练后,机器学习框架下一个需要支持的关键功能是模型部署。为了确保模型可以在内存有限的硬件上执行,会使用模型转换、量化、蒸馏等模型压缩技术。同时,也需要实现针对推理硬件平台(例如英伟达Orin)的模型算子优化。最后,为了保证模型的安全(如拒绝未经授权的用户读取),还会对模型进行混淆设计。
-
分布式训练: 机器学习模型的训练往往需要分布式的计算节点并行完成。其中,常见的并行训练方法包括数据并行、模型并行、混合并行和流水线并行。这些并行训练方法通常由远端程序调用(Remote Procedure Call, RPC)、集合通信(Collective Communication)或者参数服务器(Parameter Server)实现。
机器学习系统生态
机器学习系统生态
以机器学习框架为核心,人工智能社区创造出了庞大的机器学习系统生态。广义来说,机器学习系统是指实现和支持机器学习应用的各类型软硬件系统的泛称。图 图1.4.1 总结了各类型的机器学习系统。
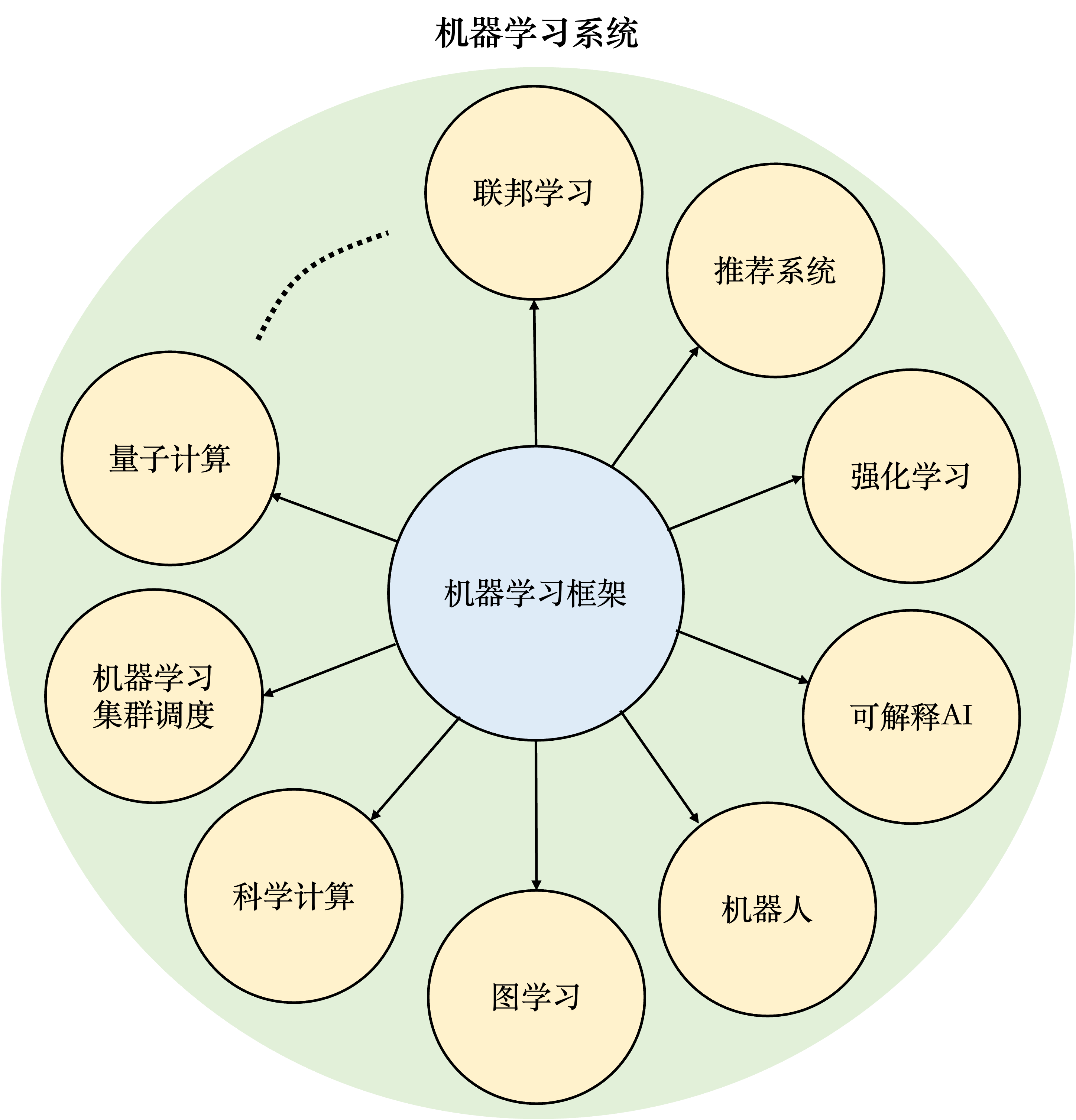
图1.4.1 机器学习系统和相关生态
-
联邦学习: 随着用户隐私保护和数据保护法的出现,许多机器学习应用无法直接接触用户数据完成模型训练。因此这一类应用需要通过机器学习框架实现联邦学习(Federated Learning)。
-
推荐系统: 将机器学习(特别是深度学习)引入推荐系统在过去数年取得了巨大的成功。相比于传统基于规则的推荐系统,深度学习推荐系统能够有效分析用户的海量特征数据,从而实现在推荐准确度和推荐时效性上的巨大提升。
-
强化学习: 强化学习具有数据收集和模型训练方法的特殊性。因此,需要基于机器学习框架进一步开发专用的强化学习系统。
-
可解释AI: 随着机器学习在金融、医疗和政府治理等关键领域的推广,基于机器学习框架进一步开发的可解释性AI系统正得到日益增长的重视。
-
机器人: 机器人是另一个开始广泛使用机器学习框架的领域。相比于传统的机器人视觉方法,机器学习方法在特征自动提取、目标识别、路径规划等多个机器人任务中获得了巨大成功。
-
图学习: 图(Graph)是最广泛使用的数据结构之一。许多互联网数据(如社交网络、产品关系图)都由图来表达。机器学习算法已经被证明是行之有效的分析大型图数据的方法。这种针对图数据的机器学习系统被称之为图学习系统(Graph Learning System)。
-
科学计算: 科学计算覆盖许多传统领域(如电磁仿真、图形学、天气预报等),这些领域中的许多大规模问题都可以有效利用机器学习方法求解。因此,针对科学计算开发机器学习系统变得日益普遍。
-
机器学习集群调度: 机器学习集群一般由异构处理器、异构网络甚至异构存储设备构成。同时,机器学习集群中的计算任务往往具有共同的执行特点(如基于集合通信算子AllReduce迭代进行)。因此,针对异构设备和任务特点,机器学习集群往往具有特定的调度方法设计。
-
量子计算: 量子计算机一般通过混合架构实现。其中,量子计算由量子计算机完成,而量子仿真由传统计算机完成。由于量子仿真往往涉及到大量矩阵计算,许多量子仿真系统(如TensorFlow Quantum和MindQuantum)都基于机器学习框架实现。
本书受限于篇幅,将不会对所有机器学习系统进行深入讲解。目前,本书会从系统设计者的角度出发,对应用在联邦学习、推荐系统、强化学习、可解释AI和机器人中的相关核心系统进行讲解。
图书结构和读者
图书结构和读者
本书由浅入深地讨论机器学习系统的设计原理和实现经验。其中,基础篇覆盖编程接口设计和计算图等框架使用者需要了解的核心概念。进阶篇覆盖编译器前端、编译器后端、数据管理等框架设计者需要了解的核心概念。最后,拓展篇覆盖重要的机器学习系统类别(如联邦学习和推荐系统等),从而为各领域的机器学习爱好者提供统一的框架使用和设计入门教学。
本书的常见读者包括:
-
学生: 本书将帮助学生获得大量机器学习系统的设计原则和一手实践经验,从而帮助其更全面理解机器学习算法的实践挑战和理论优劣。
-
科研人员: 本书将帮助科研人员解决机器学习落地实践中面临的种种挑战,引导设计出能解决大规模实际问题的下一代机器学习算法。
-
开发人员: 本书将帮助开发人员深刻理解机器学习系统的内部架构,从而帮助其开发应用新功能、调试系统性能,并且根据业务需求对机器学习系统进行定制。
编程接口
现代机器学习框架包含大量的组件,辅助用户高效开发机器学习算法、处理数据、部署模型、性能调优和调用硬件加速器。在设计这些组件的应用编程接口(Application Programming Interface,API)时,一个核心的诉求是:如何平衡框架性能和易用性?为了达到最优的性能,开发者需要利用硬件亲和的编程语言如:C和C++来进行开发。这是因为C和C++可以帮助机器学习框架高效地调用硬件底层API,从而最大限度发挥硬件性能。同时,现代操作系统(如Linux和Windows)提供丰富的基于C和C++的API接口(如文件系统、网络编程、多线程管理等),通过直接调用操作系统API,可以降低框架运行的开销。
从易用性的角度分析,机器学习框架的使用者往往具有丰富的行业背景(如数据科学家、生物学家、化学家、物理学家等)。他们常用的编程语言是高层次脚本语言:Python、Matlab、R和Julia。相比于C和C++,这些语言在提供编程易用性的同时,丧失了C和C++对底层硬件和操作系统进行深度优化的能力。因此,机器学习框架的核心设计目标是:具有易用的编程接口来支持用户使用高层次语言,如Python实现机器学习算法;同时也要具备以C和C++为核心的低层次编程接口来帮助框架开发者用C和C++实现大量高性能组件,从而在硬件上高效执行。在本章中,将讲述如何达到这个设计目标。
本章的学习目标包括:
-
理解机器学习系统的工作流和以Python为核心的编程接口设计。
-
理解机器学习系统以神经网络模块为核心的接口设计原理和实现。
-
理解机器学习系统的底层C/C++执行算子的实现和与上层Python接口的调用实现。
-
了解机器学习系统编程接口的演进方向。
机器学习系统编程模型的演进
机器学习系统编程模型的演进

图2.1.1 机器学习编程库发展历程
随着机器学习系统的诞生,如何设计易用且高性能的API接口就一直成为了系统设计者首要解决的问题。在早期的机器学习框架中(如 图2.1.1所示),人们选择用Lua(Torch)和Python(Theano)等高层次编程语言来编写机器学习程序。这些早期的机器学习框架提供了机器学习必须的模型定义,自动微分等功能,其适用于编写小型和科研为导向的机器学习应用。
深度神经网络在2011年来快速崛起,很快在各个AI应用领域(计算机视觉、语音识别、自然语言处理等)取得了突破性的成绩。训练深度神经网络需要消耗大量的算力,而以Lua和Python为主导开发的Torch和Theano无法发挥这些算力的最大性能。与此同时,计算加速卡(如英伟达GPU)的通用API接口(例如CUDA C)日趋成熟,且构建于CPU多核技术之上的多线程库(POSIX Threads)也被广大开发者所接受。因此,许多的机器学习用户希望基于C和C++来开发高性能的深度学习应用。这一类需求被Caffe等一系列以C和C++作为核心API的框架所满足。
然而,机器学习模型往往需要针对部署场景、数据类型、识别任务等需求进行深度定制,而这类定制任务需要被广大的AI应用领域开发者所实现。这类开发者的背景多样,往往不能熟练使用C和C++。因此Caffe这一类与C和C++深度绑定的编程框架,成为了制约框架快速推广的巨大瓶颈。
在2015年底,谷歌率先推出了TensorFlow。相比于传统的Torch,TensorFlow提出前后端分离相对独立的设计,利用高层次编程语言Python作为面向用户的主要前端语言,而利用C和C++实现高性能后端。大量基于Python的前端API确保了TensorFlow可以被大量的数据科学家和机器学习科学家接受,同时帮助TensorFlow能够快速融入Python为主导的大数据生态(大量的大数据开发库如Numpy、Pandas、SciPy、Matplotlib和PySpark)。同时,Python具有出色的和C/C++语言的互操作性,这种互操作性已经在多个Python库中得到验证。因此,TensorFlow兼有Python的灵活性和生态,同时也通过C/C++后端得以实现高性能。这种设计在日后崛起的PyTorch、MindSpore和PaddlePaddle等机器学习框架得到传承。
随着各国大型企业开源机器学习框架的出现,为了更高效地开发机器学习应用,基于开源机器学习框架为后端的高层次库Keras和TensorLayerX应运而生,它们提供Python API 可以快速导入已有的模型,这些高层次API进一步屏蔽了机器学习框架的实现细节,因此Keras和TensorLayerX可以运行在不同的机器学习框架之上。
随着深度神经网络的进一步发展,对于机器学习框架编程接口的挑战也日益增长。因此在2020年前后,新型的机器学习框架如MindSpore和JAX进一步出现。其中,MindSpore在继承了TensorFlow、PyTorch的Python和C/C++的混合接口的基础上,进一步拓展了机器学习编程模型从而可以高效支持多种AI后端芯片(如华为Ascend、英伟达GPU和ARM芯片),实现了机器学习应用在海量异构设备上的快速部署。
同时,超大型数据集和超大型深度神经网络崛起让分布式执行成为了机器学习编程框架的核心设计需求。为了实现分布式执行,TensorFlow和PyTorch的使用者需要花费大量代码来将数据集和神经网络分配到分布式节点上,而大量的AI开发人员并不具有分布式编程的能力。因此MindSpore进一步完善了机器学习框架的分布式编程模型的能力,从而让单节点的MindSpore程序可以无缝地运行在海量节点上。
在本小节中,我们将以MindSpore作为例子讲解一个现代机器学习框架的Python前端API和C/C++后端API的设计原则。这些设计原则和PyTorch,TensorFlow相似。
机器学习工作流
机器学习工作流
机器学习系统编程模型的首要设计目标是:对开发者的整个工作流进行完整的编程支持。一个常见的机器学习任务一般包含如 图2.2.1所示的工作流。这个工作流完成了训练数据集的读取,模型的训练,测试和调试。通过归纳,我们可以将这一工作流中用户所需要自定义的部分通过定义以下API来支持(我们这里假设用户的高层次API以Python函数的形式提供):
-
数据处理: 首先,用户需要数据处理API来支持将数据集从磁盘读入。进一步,用户需要对读取的数据进行预处理,从而可以将数据输入后续的机器学习模型中。
-
模型定义: 完成数据的预处理后,用户需要模型定义API来定义机器学习模型。这些模型带有模型参数,可以对给定的数据进行推理。
-
优化器定义: 模型的输出需要和用户的标记进行对比,这个对比差异一般通过损失函数(Loss function)来进行评估。因此,优化器定义API允许用户定义自己的损失函数,并且根据损失来引入(Import)和定义各种优化算法(Optimisation algorithms)来计算梯度(Gradient),完成对模型参数的更新。
-
训练: 给定一个数据集,模型,损失函数和优化器,用户需要训练API来定义一个循环(Loop)从而将数据集中的数据按照小批量(mini-batch)的方式读取出来,反复计算梯度来更新模型。这个反复的过程称为训练。
-
测试和调试: 训练过程中,用户需要测试API来对当前模型的精度进行评估。当精度达到目标后,训练结束。这一过程中,用户往往需要调试API来完成对模型的性能和正确性进行验证。

图2.2.1 机器学习系统工作流
环境配置
下面以MindSpore框架实现多层感知机为例,了解完整的机器学习工作流。代码运行环境为MindSpore1.5.2,Ubuntu16.04,CUDA10.1。 在构建机器学习工作流程前,MindSpore需要通过context.set_context来配置运行需要的信息,如运行模式、后端信息、硬件等信息。 以下代码导入context模块,配置运行需要的信息。
import os
import argparse
from mindspore import context
parser = argparse.ArgumentParser(description='MindSpore MLPNet Example')
parser.add_argument('--device_target', type=str, default="CPU", choices=['Ascend', 'GPU', 'CPU'])
args = parser.parse_known_args()[0]
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target)
上述配置样例运行使用图模式。根据实际情况配置硬件信息,譬如代码运行在Ascend AI处理器上,则–device_target选择Ascend,代码运行在CPU、GPU同理。
数据处理
配置好运行信息后,首先讨论数据处理API的设计。这些API提供了大量Python函数支持用户用一行命令即可读入常见的训练数据集(如MNIST,CIFAR,COCO等)。 在加载之前需要将下载的数据集存放在./datasets/MNIST_Data路径中;MindSpore提供了用于数据处理的API模块 mindspore.dataset,用于存储样本和标签。在加载数据集前,通常会对数据集进行一些处理,mindspore.dataset也集成了常见的数据处理方法。 以下代码读取了MNIST的数据是大小为\(28 \times 28\)的图片,返回DataSet对象。
import mindspore.dataset as ds
DATA_DIR = './datasets/MNIST_Data/train'
mnist_dataset = ds.MnistDataset(DATA_DIR)
有了DataSet对象后,通常需要对数据进行增强,常用的数据增强包括翻转、旋转、剪裁、缩放等;在MindSpore中是使用map将数据增强的操作映射到数据集中的,之后进行打乱(Shuffle)和批处理(Batch)。
# 导入需要用到的模块
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
# 数据处理过程
def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
# 定义数据集
mnist_ds = ds.MnistDataset(data_path)
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# 定义所需要操作的map映射
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml * rescale, shift_nml)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
# 使用map映射函数,将数据操作应用到数据集
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=[resize_op, rescale_nml_op,hwc2chw_op], input_columns="image",num_parallel_workers=num_parallel_workers)
# 进行shuffle、batch操作
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
return mnist_ds
模型定义
使用MindSpore定义神经网络需要继承mindspore.nn.Cell,神经网络的各层需要预先在__init__方法中定义,然后重载__construct__方法实现神经网络的前向传播过程。 因为输入大小被处理成\(32 \times 32\)的图片,所以需要用Flatten将数据压平为一维向量后给全连接层。 全连接层的输入大小为\(32 \times 32\),输出是预测属于\(0 \sim 9\)中的哪个数字,因此输出大小为10,下面定义了一个三层的全连接层。
# 导入需要用到的模块
import mindspore.nn as nn
# 定义线性模型
class MLPNet(nn.Cell):
def __init__(self):
super(MLPNet, self).__init__()
self.flatten = nn.Flatten()
self.dense1 = nn.Dense(32*32, 128)
self.dense2 = nn.Dense(128, 64)
self.dense3 = nn.Dense(64, 10)
def construct(self, inputs):
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
logits = self.dense3(x)
return logits
# 实例化网络
net = MLPNet()
损失函数和优化器
有了神经网络组件构建的模型我们还需要定义损失函数来计算训练过程中输出和真实值的误差。均方误差(Mean Squared Error,MSE)是线性回归中常用的,是计算估算值与真实值差值的平方和的平均数。 平均绝对误差(Mean Absolute Error,MAE)是计算估算值与真实值差值的绝对值求和再求平均。 交叉熵(Cross Entropy,CE)是分类问题中常用的,衡量已知数据分布情况下,计算输出分布和已知分布的差值。
有了损失函数,我们就可以通过损失值利用优化器对参数进行训练更新。对于优化的目标函数\(f(x)\);先求解其梯度\(\nabla\)\(f(x)\),然后将训练参数\(W\)沿着梯度的负方向更新,更新公式为:\(W_t = W_{t-1} - \alpha\nabla(W_{t-1})\),其中\(\alpha\)是学习率,\(W\)是训练参数,\(\nabla(W_{t-1})\)是方向。 神经网络的优化器种类很多,一类是学习率不受梯度影响的随机梯度下降(Stochastic Gradient Descent)及SGD的一些改进方法,如带有Momentum的SGD;另一类是自适应学习率如AdaGrad、RMSProp、Adam等。
SGD的更新是对每个样本进行梯度下降,因此计算速度很快,但是单样本更新频繁,会造成震荡;为了解决震荡问题,提出了带有Momentum的SGD,该方法的参数更新不仅仅由梯度决定,也和累计的梯度下降方向有关,使得增加更新梯度下降方向不变的维度,减少更新梯度下降方向改变的维度,从而速度更快也减少震荡。
自适应学习率AdaGrad是通过以往的梯度自适应更新学习率,不同的参数\(W_i\)具有不同的学习率。AdaGrad对频繁变化的参数以更小的步长更新,而稀疏的参数以更大的步长更新。因此对稀疏的数据表现比较好。Adadelta是对AdaGrad的改进,解决了AdaGrad优化过程中学习率\(\alpha\)单调减少问题;Adadelta不对过去的梯度平方进行累加,用指数平均的方法计算二阶动量,避免了二阶动量持续累积,导致训练提前结束。Adam可以理解为Adadelta和Momentum的结合,对一阶二阶动量均采用指数平均的方法计算。
MindSpore提供了丰富的API来让用户导入损失函数和优化器。在下面的例子中,计算了输入和真实值之间的softmax交叉熵损失,导入Momentum优化器。
# 定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义优化器
net_opt = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.9)
训练及保存模型
MindSpore提供了回调Callback机制,可以在训练过程中执行自定义逻辑,使用框架提供的ModelCheckpoint为例。ModelCheckpoint可以保存网络模型和参数,以便进行后续的Fine-tuning(微调)操作。
# 导入模型保存模块
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
# 设置模型保存参数
config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)
# 应用模型保存参数
ckpoint = ModelCheckpoint(prefix="checkpoint_lenet", config=config_ck)
通过MindSpore提供的model.train接口可以方便地进行网络的训练,LossMonitor可以监控训练过程中loss值的变化。
# 导入模型训练需要的库
from mindspore.nn import Accuracy
from mindspore.train.callback import LossMonitor
from mindspore import Model
def train_net(args, model, epoch_size, data_path, repeat_size, ckpoint_cb, sink_mode):
"""定义训练的方法"""
# 加载训练数据集
ds_train = create_dataset(os.path.join(data_path, "train"), 32, repeat_size)
model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(125)], dataset_sink_mode=sink_mode)
其中,dataset_sink_mode用于控制数据是否下沉,数据下沉是指数据通过通道直接传送到Device上,可以加快训练速度,dataset_sink_mode为True表示数据下沉,否则为非下沉。
有了数据集、模型、损失函数、优化器后就可以进行训练了,这里把train_epoch设置为1,对数据集进行1个迭代的训练。在train_net和 test_net方法中,我们加载了之前下载的训练数据集,mnist_path是MNIST数据集路径。
train_epoch = 1
mnist_path = "./datasets/MNIST_Data"
dataset_size = 1
model = Model(net, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
train_net(args, model, train_epoch, mnist_path, dataset_size, ckpoint, False)
测试和验证
测试是将测试数据集输入到模型,运行得到输出的过程。通常在训练过程中,每训练一定的数据量后就会测试一次,以验证模型的泛化能力。MindSpore使用model.eval接口读入测试数据集。
def test_net(model, data_path):
"""定义验证的方法"""
ds_eval = create_dataset(os.path.join(data_path, "test"))
acc = model.eval(ds_eval, dataset_sink_mode=False)
print("{}".format(acc))
# 验证模型精度
test_net(model, mnist_path)
在训练完毕后,参数保存在checkpoint中,可以将训练好的参数加载到模型中进行验证。
import numpy as np
from mindspore import Tensor
from mindspore import load_checkpoint, load_param_into_net
# 定义测试数据集,batch_size设置为1,则取出一张图片
ds_test = create_dataset(os.path.join(mnist_path, "test"), batch_size=1).create_dict_iterator()
data = next(ds_test)
# images为测试图片,labels为测试图片的实际分类
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
# 加载已经保存的用于测试的模型
param_dict = load_checkpoint("checkpoint_lenet-1_1875.ckpt")
# 加载参数到网络中
load_param_into_net(net, param_dict)
# 使用函数model.predict预测image对应分类
output = model.predict(Tensor(data['image']))
# 输出预测分类与实际分类
print(f'Predicted: "{predicted[0]}", Actual: "{labels[0]}"')
定义深度神经网络
定义深度神经网络
在上一节我们使用MindSpore构建了一个多层感知机的网络结构,随着深度神经网络的飞速发展,各种深度神经网络结构层出不穷,但是不管结构如何复杂,神经网络层数量如何增加,构建深度神经网络结构始终遵循最基本的元素:1.承载计算的节点;2.可变化的节点权重(节点权重可训练);3.允许数据流动的节点连接。因此在机器学习编程库中深度神经网络是以层为核心,它提供了各类深度神经网络层基本组件;将神经网络层组件按照网络结构进行堆叠、连接就能构造出神经网络模型。
以层为核心定义神经网络
神经网络层包含构建机器学习网络结构的基本组件,如计算机视觉领域常用到卷积(Convolution)、池化(Pooling)、全连接(Fully Connected);自然语言处理常用到循环神经网络(Recurrent Neural Network,RNN);为了加速训练,防止过拟合通常用到批标准化(BatchNorm)、Dropout等。
全连接是将当前层每个节点都和上一层节点一一连接,本质上是特征空间的线性变换;可以将数据从高维映射到低维,也能从低维映射到高维度。 图2.3.1展示了全连接的过程,对输入的n个数据变换到大小为m的特征空间,再从大小为m的特征空间变换到大小为p的特征空间;可见全连接层的参数量巨大,两次变换所需的参数大小为\(n \times m\)和\(m \times p\)。

图2.3.1 全连接层
卷积操作是卷积神经网络中常用的操作之一,卷积相当于对输入进行滑动滤波。根据卷积核(Kernel)、卷积步长(Stride)、填充(Padding)对输入数据从左到右,从上到下进行滑动,每一次滑动操作是矩阵的乘加运算得到的加权值。 如 图2.3.2卷积操作主要由输入、卷积核、输出组成输出又被称为特征图(Feature Map)。

图2.3.2 卷积操作的组成
卷积的具体运算过程我们通过 图2.3.3进行演示。该图输入为\(4 \times 4\)的矩阵,卷积核大小为\(3 \times 3\),卷积步长为1,不填充,最终得到的\(2 \times 2\)的输出矩阵。 计算过程为将\(3 \times 3\)的卷积核作用到左上角\(3 \times 3\)大小的输入图上;输出为\(1 \times 1 + 2 \times 0 + 2 \times 1 + 3 \times 0 + 2 \times 1 + 3 \times 0 + 4 \times 1 + 1 \times 0 + 3 \times 1 = 12\), 同理对卷积核移动1个步长再次执行相同的计算步骤得到第二个输出为11;当再次移动将出界时结束从左往右,执行从上往下移动1步,再进行从左往右移动;依次操作直到从上往下再移动也出界时,结束整个卷积过程,得到输出结果。我们不难发现相比于全连接,卷积的优势是参数共享(同一个卷积核遍历整个输入图)和参数量小(卷积核大小即是参数量)。

图2.3.3 卷积的具体运算过程
在卷积过程中,如果我们需要对输出矩阵大小进行控制,那么就需要对步长和填充进行设置。还是上面的输入图,如需要得到和输入矩阵大小一样的输出矩阵,步长为1时就需要对上下左右均填充一圈全为0的数。
在上述例子中我们介绍了一个输入一个卷积核的卷积操作。通常情况下我们输入的是彩色图片,有三个输入,这三个输入称为通道(Channel),分别代表红、绿、蓝(RGB)。此时我们执行卷积则为多通道卷积,需要三个卷积核分别对RGB三个通道进行上述卷积过程,之后将结果加起来。 具体如 图2.3.4描述了一个输入通道为3,输出通道为1,卷积核大小为\(3 \times 3\),卷积步长为1的多通道卷积过程;需要注意的是,每个通道都有各自的卷积核,同一个通道的卷积核参数共享。如果输出通道为\(out_c\),输入通道为\(in_c\),那么需要\(out_c\)\(\times\)\(in_c\)个卷积核。

图2.3.4 多通道卷积
池化是常见的降维操作,有最大池化和平均池化。池化操作和卷积的执行类似,通过池化核、步长、填充决定输出;最大池化是在池化核区域范围内取最大值,平均池化则是在池化核范围内做平均。与卷积不同的是池化核没有训练参数;池化层的填充方式也有所不同,平均池化填充的是0,最大池化填充的是\(-inf\)。 图2.3.5是对\(4 \times 4\)的输入进行\(2 \times 2\)区域池化,步长为2,不填充;图左边是最大池化的结果,右边是平均池化的结果。

图2.3.5 池化操作
有了卷积、池化、全连接组件就可以构建一个非常简单的卷积神经网络了, 图2.3.6展示了一个卷积神经网络的模型结构。 给定输入\(3 \times 64 \times 64\)的彩色图片,使用16个\(3 \times 3 \times 3\)大小的卷积核做卷积,得到大小为\(16 \times 64 \times 64\)的特征图; 再进行池化操作降维,得到大小为\(16 \times 32 \times 32\)的特征图; 对特征图再卷积得到大小为\(32 \times 32 \times 32\)特征图,再进行池化操作得到\(32 \times 16 \times 16\)大小的特征图; 我们需要对特征图做全连接,此时需要把特征图平铺成一维向量这步操作称为Flatten,压平后输入特征大小为\(32\times 16 \times 16 = 8192\); 之后做一次全连接对大小为8192特征变换到大小为128的特征,再依次做两次全连接分别得到64,10。 这里最后的输出结果是依据自己的实际问题而定,假设我们的输入是包含\(0 \sim 9\)的数字图片,做分类那输出对应是10个概率值,分别对应\(0 \sim 9\)的概率大小。

图2.3.6 卷积神经网络模型
有了上述基础知识,对卷积神经网络模型构建过程使用伪代码描述如下:
# 构建卷积神经网络的组件接口定义:
全连接层接口:fully_connected(input, weights)
卷积层的接口:convolution(input, filters, stride, padding)
最大池化接口:pooling(input, pool_size, stride, padding, mode='max')
平均池化接口:pooling(input, pool_size, stride, padding, mode='mean')
# 构建卷积神经网络描述:
input:(3,64,64)大小的图片
# 创建卷积模型的训练变量,使用随机数初始化变量值
conv1_filters = variable(random(size=(3, 3, 3, 16)))
conv2_filters = variable(random(size=(3, 3, 16, 32)))
fc1_weights = variable(random(size=(8192, 128)))
fc2_weights = variable(random(size=(128, 64)))
fc3_weights = variable(random(size=(64, 10)))
# 将所有需要训练的参数收集起来
all_weights = [conv1_filters, conv2_filters, fc1_weights, fc2_weights, fc3_weights]
# 构建卷积模型的连接过程
output = convolution(input, conv1_filters, stride=1, padding='same')
output = pooling(output, kernel_size=3, stride=2, padding='same', mode='max')
output = convolution(output, conv2_filters, stride=1, padding='same')
output = pooling(output, kernel_size=3, stride=2, padding='same', mode='max')
output = flatten(output)
output = fully_connected(output, fc1_weights)
output = fully_connected(output, fc2_weights)
output = fully_connected(output, fc3_weights)
随着深度神经网络应用领域的扩大,诞生出了丰富的模型构建组件。在卷积神经网络的计算过程中,前后的输入是没有联系的,然而在很多任务中往往需要处理序列信息,如语句、语音、视频等,为了解决此类问题诞生出循环神经网络(Recurrent Neural Network,RNN); 循环神经网络很好的解决了序列数据的问题,但是随着序列的增加,长序列又导致了训练过程中梯度消失和梯度爆炸的问题,因此有了长短期记忆(Long Short-term Memory,LSTM); 在语言任务中还有Seq2Seq它将RNN当成编解码(Encoder-Decoder)结构的编码器(Encoder)和解码器(Decode); 在解码器中又常常使用注意力机制(Attention);基于编解码器和注意力机制又有Transformer; Transformer又是BERT模型架构的重要组成。随着深度神经网络的发展,未来也会诞生各类模型架构,架构的创新可以通过各类神经网络基本组件的组合来实现。
神经网络层的实现原理
3.3.1中使用伪代码定义了一些卷积神经网络接口和模型构建过程,整个构建过程需要创建训练变量和构建连接过程。随着网络层数的增加,手动管理训练变量是一个繁琐的过程,因此3.3.1中描述的接口在机器学习库中属于低级API。机器学习编程库大都提供了更高级用户友好的API,它将神经网络层抽象出一个基类,所有的神经网络层都继承基类来实现,如MindSpore提供的mindspore.nn.Cell;PyTorch提供的torch.nn.Module。基于基类他们都提供了高阶API,如MindSpore 提供的mindspore.nn.Conv2d、mindspore.nn.MaxPool2d、mindspore.dataset;PyTorch提供的torch.nn.Conv2d、torch.nn.MaxPool2d、torch.utils.data.Dataset。
图2.3.7描述了神经网络构建过程中的基本细节。基类需要初始化训练参数、管理参数状态以及定义计算过程;神经网络模型需要实现对神经网络层和神经网络层参数管理的功能。在机器学习编程库中,承担此功能有MindSpore的Cell、PyTorch的Module。Cell和Module是模型抽象方法也是所有网络的基类。现有模型抽象方案有两种,一种是抽象出两个方法分别为Layer(负责单个神经网络层的参数构建和前向计算),Model(负责对神经网络层进行连接组合和神经网络层参数管理);另一种是将Layer和Model抽象成一个方法,该方法既能表示单层神经网络层也能表示包含多个神经网络层堆叠的模型,Cell和Module就是这样实现的。

图2.3.7 神经网络模型构建细节
图2.3.8展示了设计神经网络层抽象方法的通用表示。通常在构造器会选择使用Python中collections模块的OrderedDict来初始化神经网络层和神经网络层参数的存储;它的输出是一个有序的,相比与Dict更适合深度学习这种模型堆叠的模式。参数和神经网络层的管理是在__setattr__中实现的,当检测到属性是属于神经网络层及神经网络层参数时就记录起来。神经网络模型比较重要的是计算连接过程,可以在__call__里重载,实现神经网络层时在这里定义计算过程。训练参数的返回接口给优化器传所有训练参数,这些参数是基类遍历了所有网络层后得到的。这里只列出了一些重要的方法,在自定义方法中,通常需要实现参数插入删除、神经网络层插入删除、神经网络模型信息返回等方法。

图2.3.8 神经网络基类抽象方法
神经网络接口层基类实现,仅做了简化的描述,在实际实现时,执行计算的__call__方法并不会让用户直接重载,它往往在__call__之外定义一个执行操作的方法(对于神经网络模型该方法是实现网络结构的连接,对于神经网络层则是实现计算过程)后再__call__调用;如MindSpore的Cell因为动态图和静态图的执行是不一样的,因此在__call__里定义动态图和计算图的计算执行,在construct方法里定义层或者模型的操作过程。
自定义神经网络层
3.3.1中使用伪代码定义机器学习库中低级API,有了实现的神经网络基类抽象方法,那么就可以设计更高层次的接口解决手动管理参数的繁琐。假设已经有了神经网络模型抽象方法Cell,构建Conv2D将继承Cell,并重构__init__和__call__方法,在__init__里初始化训练参数和输入参数,在__call__里调用低级API实现计算逻辑。同样使用伪代码描述自定义卷积层的过程。
# 接口定义:
卷积层的接口:convolution(input, filters, stride, padding)
变量:Variable(value, trainable=True)
高斯分布初始化方法:random_normal(shape)
神经网络模型抽象方法:Cell
# 定义卷积层
class Conv2D(Cell):
def __init__(self, in_channels, out_channels, ksize, stride, padding):
# 卷积核大小为 ksize x ksize x inchannels x out_channels
filters_shape = (out_channels, in_channels, ksize, ksize)
self.stride = stride
self.padding = padding
self.filters = Variable(random_normal(filters_shape))
def __call__(self, inputs):
outputs = convolution(inputs, self.filters, self.stride, self.padding)
有了上述定义在使用卷积层时,就不需要创建训练变量了。 如我们需要对\(30 \times 30\)大小10个通道的输入使用\(3 \times 3\)的卷积核做卷积,卷积后输出通道为20。 调用方式如下:
conv = Conv2D(in_channel=10, out_channel=20, filter_size=3, stride=2, padding=0)
output = conv(input)
在执行过程中,初始化Conv2D时,__setattr__会判断属性,属于Cell把神经网络层Conv2D记录到self._cells,属于parameter的filters记录到self._params。查看神经网络层参数使用conv.parameters_and_names;查看神经网络层列表使用conv.cells_and_names;执行操作使用conv(input)。
自定义神经网络模型
神经网络层是Cell的子类(SubClass)实现,同样的神经网络模型也可以采用SubClass的方法自定义神经网络模型;构建时需要在__init__里将要使用的神经网络组件实例化,在__call__里定义神经网络的计算逻辑。同样的以3.3.1的卷积神经网络模型为例,定义接口和伪代码描述如下:
# 使用Cell子类构建的神经网络层接口定义:
# 构建卷积神经网络的组件接口定义:
全连接层接口:Dense(in_channel, out_channel)
卷积层的接口:Conv2D(in_channel, out_channel, filter_size, stride, padding)
最大池化接口:MaxPool2D(pool_size, stride, padding)
张量平铺:Flatten()
# 使用SubClass方式构建卷积模型
class CNN(Cell):
def __init__(self):
self.conv1 = Conv2D(in_channel=3, out_channel=16, filter_size=3, stride=1, padding=0)
self.maxpool1 = MaxPool2D(pool_size=3, stride=1, padding=0)
self.conv2 = Conv2D(in_channel=16, out_channel=32, filter_size=3, stride=1, padding=0)
self.maxpool2 = MaxPool2D(pool_size=3, stride=1, padding=0)
self.flatten = Flatten()
self.dense1 = Dense(in_channels=768, out_channel=128)
self.dense2 = Dense(in_channels=128, out_channel=64)
self.dense3 = Dense(in_channels=64, out_channel=10)
def __call__(self, inputs):
z = self.conv1(inputs)
z = self.maxpool1(z)
z = self.conv2(z)
z = self.maxpool2(z)
z = self.flatten(z)
z = self.dense1(z)
z = self.dense2(z)
z = self.dense3(z)
return z
net = CNN()
上述卷积模型进行实例化,其执行将从__init__开始,第一个是Conv2D,Conv2D也是Cell的子类,会进入到Conv2D的__init__,此时会将第一个Conv2D的卷积参数收集到self._params,之后回到Conv2D,将第一个Conv2D收集到self._cells;第二个的组件是MaxPool2D,因为其没有训练参数,因此将MaxPool2D收集到self._cells;依次类推,分别收集第二个卷积层的参数和层信息以及三个全连接层的参数和层信息。实例化之后可以调用net.parameters_and_names来返回训练参数;调用net.cells_and_names查看神经网络层列表。
C/C++编程接口
C/C++编程接口
在3.2和3.3节中,分别讨论了开发者如何利用Python来定义机器学习的整个工作流,以及如何定义复杂的深度神经网络。然而,在很多时候,开发者也需要添加自定义的算子来帮助实现新的模型,优化器,数据处理函数等。这些自定义算子需要通过C和C++实现,从而获得最优性能。但是为了帮助这些算子被开发者使用,他们也需要暴露为Python函数,从而方便开发者整合入已有的Python为核心编写的工作流和模型。在这一小节中,我们讨论这一过程是如何实现的。
在Python中调用C/C++函数的原理
由于Python的解释器是由C实现的,因此在Python中可以实现对于C和C++函数的调用。现代机器学习框架(包括TensorFlow,PyTorch和MindSpore)主要依赖Pybind11来将底层的大量C和C++函数自动生成对应的Python函数,这一过程一般被称为Python绑定( Binding)。在Pybind11出现以前,将C和C++函数进行Python绑定的手段主要包括:
-
Python的C-API。这种方式要求在一个C++程序中包含Python.h,并使用Python的C-API对Python语言进行操作。使用这套API需要对Python的底层实现有一定了解,比如如何管理引用计数等,具有较高的使用门槛。
-
简单包装界面产生器(Simplified Wrapper and Interface Generator,SWIG)。SWIG可以将C和C++代码暴露给Python。SWIG是TensorFlow早期使用的方式。这种方式需要用户编写一个复杂的SWIG接口声明文件,并使用SWIG自动生成使用Python C-API的C代码。自动生成的代码可读性很低,因此具有很大代码维护开销。
-
Python的ctypes模块,提供了C语言中的类型,以及直接调用动态链接库的能力。缺点是依赖于C的原生的类型,对自定义类型支持不好。
-
Cython是结合了Python和C语言的一种语言,可以简单的认为就是给Python加上了静态类型后的语法,使用者可以维持大部分的Python语法。Cython编写的函数会被自动转译为C和C++代码,因此在Cython中可以插入对于C/C++函数的调用。
-
Boost::Python是一个C++库。它可以将C++函数暴露为Python函数。其原理和Python C-API类似,但是使用方法更简单。然而,由于引入了Boost库,因此有沉重的第三方依赖。
相对于上述的提供Python绑定的手段,Pybind11提供了类似于Boost::Python的简洁性和易用性,但是其通过专注支持C++ 11,并且去除Boost依赖,因此成为了轻量级的Python库,从而特别适合在一个复杂的C++项目(例如本书讨论的机器学习系统)中暴露大量的Python函数。
添加C++编写的自定义算子
算子是构建神经网络的基础,在前面也称为低级API;通过算子的封装可以实现各类神经网络层,当开发神经网络层遇到内置算子无法满足时,可以通过自定义算子来实现。以MindSpore为例,实现一个GPU算子需要如下步骤:
-
Primitive注册:算子原语是构建网络模型的基础单元,用户可以直接或者间接调用算子原语搭建一个神经网络模型。
-
GPU Kernel实现:GPU Kernel用于调用GPU实现加速计算。
-
GPU Kernel注册:算子注册用于将GPU Kernel及必要信息注册给框架,由框架完成对GPU Kernel的调用。
1.注册算子原语 算子原语通常包括算子名、算子输入、算子属性(初始化时需要填的参数,如卷积的stride、padding)、输入数据合法性校验、输出数据类型推导和维度推导。假设需要编写加法算子,主要内容如下:
-
算子名:TensorAdd
-
算子属性:构造函数__init__中初始化属性,因加法没有属性,因此__init__不需要额外输入。
-
算子输入输出及合法性校验:infer_shape方法中约束两个输入维度必须相同,输出的维度和输入维度相同。infer_dtype方法中约束两个输入数据必须是float32类型,输出的数据类型和输入数据类型相同。
-
算子输出
MindSpore中实现注册TensorAdd代码如下:
# mindspore/ops/operations/math_ops.py
class TensorAdd(PrimitiveWithInfer):
"""
Adds two input tensors element-wise.
"""
@prim_attr_register
def __init__(self):
self.init_prim_io_names(inputs=['x1', 'x2'], outputs=['y'])
def infer_shape(self, x1_shape, x2_shape):
validator.check_integer('input dims', len(x1_shape), len(x2_shape), Rel.EQ, self.name)
for i in range(len(x1_shape)):
validator.check_integer('input_shape', x1_shape[i], x2_shape[i], Rel.EQ, self.name)
return x1_shape
def infer_dtype(self, x1_dtype, x2_type):
validator.check_tensor_type_same({'x1_dtype': x1_dtype}, [mstype.float32], self.name)
validator.check_tensor_type_same({'x2_dtype': x2_dtype}, [mstype.float32], self.name)
return x1_dtype
在mindspore/ops/operations/math_ops.py文件内注册加法算子原语后,需要在mindspore/ops/operations/__init__中导出,方便python导入模块时候调用。
# mindspore/ops/operations/__init__.py
from .math_ops import (Abs, ACos, ..., TensorAdd)
__all__ = [
'ReverseSequence',
'CropAndResize',
...,
'TensorAdd'
]
2.GPU算子开发继承GPUKernel,实现加法使用类模板定义TensorAddGpuKernel,需要实现以下方法:
-
Init(): 用于完成GPU Kernel的初始化,通常包括记录算子输入/输出维度,完成Launch前的准备工作;因此在此记录Tensor元素个数。
-
GetInputSizeList():向框架反馈输入Tensor需要占用的显存字节数;返回了输入Tensor需要占用的字节数,TensorAdd有两个Input,每个Input占用字节数为element_num\(\ast\)sizeof(T)。
-
GetOutputSizeList():向框架反馈输出Tensor需要占用的显存字节数;返回了输出Tensor需要占用的字节数,TensorAdd有一个output,占用element_num\(\ast\)sizeof(T)字节。
-
GetWorkspaceSizeList():向框架反馈Workspace字节数,Workspace是用于计算过程中存放临时数据的空间;由于TensorAdd不需要Workspace,因此GetWorkspaceSizeList()返回空的std::vector<size_t>。
-
Launch(): 通常调用CUDA kernel(CUDA kernel是基于Nvidia GPU的并行计算架构开发的核函数),或者cuDNN接口等方式,完成算子在GPU上加速;Launch()接收input、output在显存的地址,接着调用TensorAdd完成加速。
// mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.h
template <typename T>
class TensorAddGpuKernel : public GpuKernel {
public:
TensorAddGpuKernel() : element_num_(1) {}
~TensorAddGpuKernel() override = default;
bool Init(const CNodePtr &kernel_node) override {
auto shape = AnfAlgo::GetPrevNodeOutputInferShape(kernel_node, 0);
for (size_t i = 0; i < shape.size(); i++) {
element_num_ *= shape[i];
}
InitSizeLists();
return true;
}
const std::vector<size_t> &GetInputSizeList() const override { return input_size_list_; }
const std::vector<size_t> &GetOutputSizeList() const override { return output_size_list_; }
const std::vector<size_t> &GetWorkspaceSizeList() const override { return workspace_size_list_; }
bool Launch(const std::vector<AddressPtr> &inputs, const std::vector<AddressPtr> &,
const std::vector<AddressPtr> &outputs, void *stream_ptr) override {
T *x1 = GetDeviceAddress<T>(inputs, 0);
T *x2 = GetDeviceAddress<T>(inputs, 1);
T *y = GetDeviceAddress<T>(outputs, 0);
TensorAdd(element_num_, x1, x2, y, reinterpret_cast<cudaStream_t>(stream_ptr));
return true;
}
protected:
void InitSizeLists() override {
input_size_list_.push_back(element_num_ * sizeof(T));
input_size_list_.push_back(element_num_ * sizeof(T));
output_size_list_.push_back(element_num_ * sizeof(T));
}
private:
size_t element_num_;
std::vector<size_t> input_size_list_;
std::vector<size_t> output_size_list_;
std::vector<size_t> workspace_size_list_;
};
TensorAdd中调用了CUDA kernelTensorAddKernel来实现element_num个元素的并行相加:
// mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.h
template <typename T>
__global__ void TensorAddKernel(const size_t element_num, const T* x1, const T* x2, T* y) {
for (size_t i = blockIdx.x * blockDim.x + threadIdx.x; i < element_num; i += blockDim.x * gridDim.x) {
y[i] = x1[i] + x2[i];
}
}
template <typename T>
void TensorAdd(const size_t &element_num, const T* x1, const T* x2, T* y, cudaStream_t stream){
size_t thread_per_block = 256;
size_t block_per_grid = (element_num + thread_per_block - 1 ) / thread_per_block;
TensorAddKernel<<<block_per_grid, thread_per_block, 0, stream>>>(element_num, x1, x2, y);
return;
}
template void TensorAdd(const size_t &element_num, const float* x1, const float* x2, float* y, cudaStream_t stream);
3.GPU算子注册算子信息包含1.Primive;2.Input dtype, output dtype;3.GPU Kernel class; 4.CUDA内置数据类型。框架会根据Primive和Input dtype, output dtype,调用以CUDA内置数据类型实例化GPU Kernel class模板类。如下代码中分别注册了支持float和int的TensorAdd算子。
// mindspore/ccsrc/backend/kernel_compiler/gpu/math/tensor_add_v2_gpu_kernel.cc
MS_REG_GPU_KERNEL_ONE(TensorAddV2, KernelAttr()
.AddInputAttr(kNumberTypeFloat32)
.AddInputAttr(kNumberTypeFloat32)
.AddOutputAttr(kNumberTypeFloat32),
TensorAddV2GpuKernel, float)
MS_REG_GPU_KERNEL_ONE(TensorAddV2, KernelAttr()
.AddInputAttr(kNumberTypeInt32)
.AddInputAttr(kNumberTypeInt32)
.AddOutputAttr(kNumberTypeInt32),
TensorAddV2GpuKernel, int)
完成上述三步工作后,需要把MindSpore重新编译,在源码的根目录执行bash build.sh -e gpu,最后使用算子进行验证。
机器学习框架的编程范式
机器学习框架的编程范式
机器学习框架编程需求
机器学习的训练是其任务中最为关键的一步,训练依赖于优化器算法来描述。目前大部分机器学习任务都使用一阶优化器,因为一阶方法简单易用。随着机器学习的高速发展,软硬件也随之升级,越来越多的研究者开始探索收敛性能更好的高阶优化器。常见的二阶优化器如牛顿法、拟牛顿法、AdaHessians,均需要计算含有二阶导数信息的Hessian矩阵,Hessian矩阵的计算带来两方面的问题,一方面是计算量巨大如何才能高效计算,另一方面是高阶导数的编程表达。
同时,近年来,工业界发布了非常多的大模型,从2020年OpenAI GTP-3 175B参数开始,到2021年盘古大模型100B、鹏程盘古-\(\alpha\) 200B、谷歌switch transformer 1.6T、智源悟道 1.75T参数,再到2022年百度ERNIE3.0 280M、Facebook NLLB-200 54B,越来越多的超大规模模型训练需求使得单纯的数据并行难以满足,而模型并行需要靠人工来模型切分耗时耗力,如何自动并行成为未来机器学习框架所面临的挑战。最后,构建机器学习模型本质上是数学模型的表示,如何简洁表示机器学习模型也成为机器学习框架编程范式的设计的重点。
为了解决机器学习框架在实际应用中的一些困难,研究人员发现函数式编程能很好地提供解决方案。在计算机科学中,函数式编程是一种编程范式,它将计算视为数学函数的求值,并避免状态变化和数据可变,这是一种更接近于数学思维的编程模式。神经网络由连接的节点组成,每个节点执行简单的数学运算。通过使用函数式编程语言,开发人员能够用一种更接近运算本身的语言来描述这些数学运算,使得程序的读取和维护更加容易。同时,函数式语言的函数都是相互隔离的,使得并发性和并行性更容易管理。
因此,机器学习框架使用函数式编程设计具有以下优势:
- 支持高效的科学计算和机器学习场景。
- 易于开发并行。
- 简洁的代码表示能力。
机器学习框架编程范式现状
本小节将从目前主流机器学习框架发展历程来看机器学习框架对函数式编程的支持现状。谷歌在2015年发布了TensorFlow1.0其代表的编程特点包括计算图(Computational Graphs)、会话(Session)、张量(Tensor)它是一种声明式编程风格。2017年Facebook发布了PyTorch其编程特点为即时执行,它是一种命令式编程风格。2018年谷歌发布了JAX它不是存粹为了机器学习而编写的框架,而是针对GPU和TPU做高性能数据并行计算的框架;与传统的机器学习框架相比其核心能力是神经网络计算和数值计算的融合,在接口上兼容了NumPy、Scipy等Python原生的数据科学接口,而且在此基础上扩展分布式、向量化、高阶求导、硬件加速,其编程风格是函数式,主要体现在无副作用、Lambda闭包等。2020年华为发布了MindSpore,其函数式可微分编程架构可以让用户聚焦机器学习模型数学的原生表达。2022年PyTorch推出functorch,受到谷歌JAX的极大启发,functorch是一个向PyTorch添加可组合函数转换的库,包括可组合的vmap(向量化)和autodiff转换,可与PyTorch模块和PyTorch autograd一起使用,并具有良好的渴望模式(Eager-Mode)性能,functorch可以说是弥补了PyTorch静态图的分布式并行需求。
从主流的机器学习框架发展历程来看,未来机器学习框架函数式编程风格将会日益得到应用,因为函数式编程能更直观地表达机器学习模型,同时对于自动微分、高阶求导、分布式实现也更加方便。另一方面,未来的机器学习框架在前端接口层次也趋向于分层解耦,其设计不直接为了机器学习场景,而是只提供高性能的科学计算和自动微分算子,更高层次的应用如机器学习模型开发则是通过封装这些高性能算子实现。
函数式编程案例
在上一小节介绍了机器学习框架编程范式的现状,不管是JAX、MindSpore还是functorch都提到了函数式编程,其在科学计算、分布式方面有着独特的优势。然而在实际应用中纯函数式编程几乎没有能够成为主流开发范式,而现代编程语言几乎不约而同的选择了接纳函数式编程特性。以MindSpore为例,MindSpore选择将函数式和面向对象编程融合,兼顾用户习惯,提供易用性最好,编程体验最佳的混合编程范式。MindSpore采用混合编程范式道理也很简单,纯函数式会让学习曲线陡增,易用性变差;面向对象构造神经网络的编程范式深入人心。
下面中提供了使用MindSpore编写机器学习模型训练的全流程。其网络构造,满足面向对象编程习惯,函数式编程主要体现在模型训练的反向传播部分;MindSpore使用函数式,将前向计算构造成function,然后通过函数变换,获得grad function,最后通过执行grad function获得权重对应的梯度。
# Class definition
class Net(nn.Cell):
def __init__(self):
......
def construct(self, inputs):
......
# Object instantiation
net = Net() # network
loss_fn = nn.CrossEntropyLoss() # loss function
optimizer = nn.Adam(net.trainable_params(), lr) # optimizer
# define forward function
def forword_fn(inputs, targets):
logits = net(inputs)
loss = loss_fn(logits, targets)
return loss, logits
# get grad function
grad_fn = value_and_grad(forward_fn, None, optim.parameters, has_aux=True)
# define train step function
def train_step(inputs, targets):
(loss, logits), grads = grad_fn(inputs, targets) # get values and gradients
optimizer(grads) # update gradient
return loss, logits
for i in range(epochs):
for inputs, targets in dataset():
loss = train_step(inputs, targets)
总结
总结
-
现代机器学习系统需要兼有易用性和高性能,因此其一般选择Python作为前端编程语言,而使用C和C++作为后端编程语言。
-
一个机器学习框架需要对一个完整的机器学习应用工作流进行编程支持。这些编程支持一般通过提供高层次Python API来实现。
-
数据处理编程接口允许用户下载,导入和预处理数据集。
-
模型定义编程接口允许用户定义和导入机器学习模型。
-
损失函数接口允许用户定义损失函数来评估当前模型性能。同时,优化器接口允许用户定义和导入优化算法来基于损失函数计算梯度。
-
机器学习框架同时兼有高层次Python API来对训练过程,模型测试和调试进行支持。
-
复杂的深度神经网络可以通过叠加神经网络层来完成。
-
用户可以通过Python API定义神经网络层,并指定神经网络层之间的拓扑来定义深度神经网络。
-
Python和C之间的互操作性一般通过CType等技术实现。
-
机器学习框架一般具有多种C和C++接口允许用户定义和注册C++实现的算子。这些算子使得用户可以开发高性能模型,数据处理函数,优化器等一系列框架拓展。
扩展阅读
计算图
上一章节展示了如何高效编写机器学习程序,那么下一个问题就是:机器学习系统如何高效地在硬件上执行这些程序呢?这一核心问题又能被进一步拆解为:如何对机器学习程序描述的模型调度执行?如何使得模型调度执行更加高效?如何自动计算更新模型所需的梯度?解决这些问题的关键是计算图(Computational Graph)技术。为了讲解这一技术,本章将详细讨论计算图的基本组成、自动生成和高效执行中所涉及的方法。
本章的学习目标包括:
-
掌握计算图的基本构成。
-
掌握计算图静态生成和动态生成方法。
-
掌握计算图的常用执行方法。
计算图的设计背景和作用
计算图的设计背景和作用
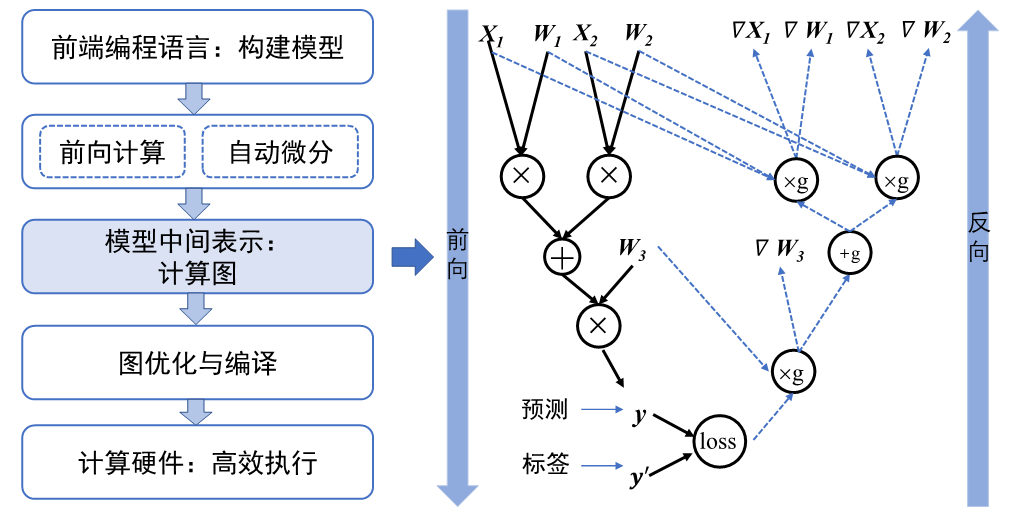
图3.1.1 基于计算图的架构
早期机器学习框架主要针对全连接和卷积神经网络设计,这些神经网络的拓扑结构简单,神经网络层之间通过串行连接。因此,它们的拓扑结构可以用简易的配置文件表达(例如Caffe基于Protocol Buffer格式的模型定义)。
现代机器学习模型的拓扑结构日益复杂,显著的例子包括混合专家模型、生成对抗网络、注意力模型等。复杂的模型结构(例如带有分支的循环结构等)需要机器学习框架能够对模型算子的执行依赖关系、梯度计算以及训练参数进行快速高效的分析,便于优化模型结构、制定调度执行策略以及实现自动化梯度计算,从而提高机器学习框架训练复杂模型的效率。因此,机器学习系统设计者需要一个通用的数据结构来理解、表达和执行机器学习模型。为了应对这个需求,如 图3.1.1所示基于计算图的机器学习框架应运而生,框架延续前端语言与后端语言分离的设计。从高层次来看,计算图实现了以下关键功能:
-
统一的计算过程表达。 在编写机器学习模型程序的过程中,用户希望使用高层次编程语言(如Python、Julia和C++)。然而,硬件加速器等设备往往只提供了C和C++编程接口,因此机器学习系统的实现通常需要基于C和C++。用不同的高层次语言编写的程序因此需要被表达为一个统一的数据结构,从而被底层共享的C和C++系统模块执行。这个数据结构(即计算图)可以表述用户的输入数据、模型中的计算逻辑(通常称为算子)以及算子之间的执行顺序。
-
自动化计算梯度。 用户的模型训练程序接收训练数据集的数据样本,通过神经网络前向计算,最终计算出损失值。根据损失值,机器学习系统为每个模型参数计算出梯度来更新模型参数。考虑到用户可以写出任意的模型拓扑和损失值计算方法,计算梯度的方法必须通用并且能实现自动运行。计算图可以辅助机器学习系统快速分析参数之间的梯度传递关系,实现自动化计算梯度的目标。
-
分析模型变量生命周期。 在用户训练模型的过程中,系统会通过计算产生临时的中间变量,如前向计算中的激活值和反向计算中的梯度。前向计算的中间变量可能与梯度共同参与到模型的参数更新过程中。通过计算图,系统可以准确分析出中间变量的生命周期(一个中间变量生成以及销毁时机),从而帮助框架优化内存管理。
-
优化程序执行。 用户给定的模型程序具备不同的网络拓扑结构。机器学习框架利用计算图来分析模型结构和算子执行依赖关系,并自动寻找算子并行计算的策略,从而提高模型的执行效率。
计算图的基本构成
计算图的基本构成
计算图由基本数据结构张量(Tensor)和基本运算单元算子构成。在计算图中通常使用节点来表示算子,节点间的有向边(Directed Edge)来表示张量状态,同时也描述了计算间的依赖关系。如 图3.2.1所示,将\(\boldsymbol{Z}=ReLU(\boldsymbol{X}\times\boldsymbol{Y})\)转化为计算图表示。
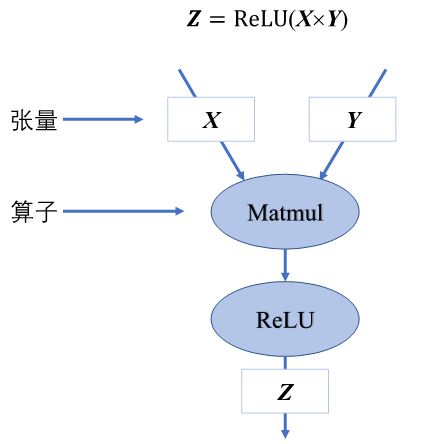
图3.2.1 简单计算图
张量和算子
在数学中定义张量是基于标量与向量的推广。在机器学习领域内将多维数据称为张量,使用秩来表示张量的轴数或维度。如 图3.2.2所示,标量为零秩张量,包含单个数值,没有轴;向量为一秩张量,拥有一个轴;拥有RGB三个通道的彩色图像即为三秩张量,包含三个轴。
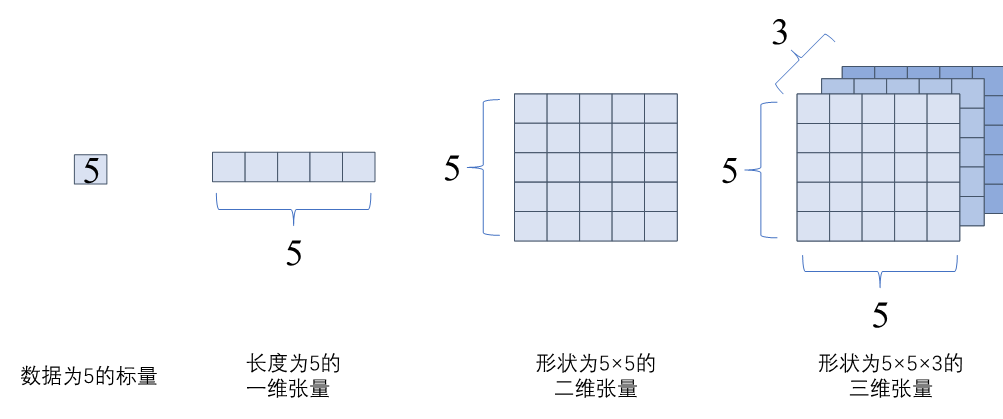
图3.2.2 张量
- 在机器学习框架中张量不仅存储数据,还需要存储张量的数据类型、数据形状、秩以及梯度传递状态等多个属性,如 tensor_attr所示,列举了主要的属性和功能。
-
张量属性
| 张量属性 | 功能 |
|---|---|
| 形状(shape) | 存储张量的每个维度的长度,如[3,3,3] |
| 秩或维数(dim) | 表示张量的轴数或者维数,标量为0,向量为1。 |
| 数据类型(dtype) | 表示存储的数据类型,如bool、uint8、int16、float32、float64等 |
| 存储位置(device) | 创建张量时可以指定存储的设备位置,如CPU、GPU等 |
| 名字(name) | 张量的标识符 |
以图像数据为例来具体说明张量属性的作用。当机器学习框架读取一张高为96像素、宽为96像素的RGB三通道图像,并将图像数据转换为张量存储时。该张量的形状属性则为[96,96,3]分别代表高、宽、通道的数量,秩即为3。原始RGB图像每个像素上的数据以0-255的无符号整数来表示色彩,因此图像张量存储时会将数据类型属性设置为uint8格式。将图像数据传输给卷积网络模型进行网络训练前,会对图像数据进行归一化处理,此时数据类型属性会重新设置为float32格式,因为通常机器学习框架在训练模型时默认采用float32格式。
机器学习框架在训练时需要确定在CPU、GPU或其他硬件上执行计算,数据和权重参数也应当存放在对应的硬件内存中才能正确被调用,张量存储位置属性则用来指明存储的设备位置。存储位置属性通常由机器学习框架根据硬件环境自动赋予张量。在模型训练过程中,张量数据的存储状态可以分为可变和不可变两种,可变张量存储神经网络模型权重参数,根据梯度信息更新自身数据,如参与卷积运算的卷积核张量;不可变张量用于用户初始化的数据或者输入模型的数据,如上文提到的图像数据张量。
那么在机器学习场景下的张量一般长什么样子呢?上文提到的图像数据张量以及卷积核张量,形状一般是“整齐”的。即每个轴上的具有相同的元素个数,就像一个“矩形”或者“立方体”。在特定的环境中,也会使用特殊类型的张量,比如不规则张量和稀疏张量。如 图3.2.3中所示,不规则张量在某个轴上可能具有不同的元素个数,它们支持存储和处理包含非均匀形状的数据,如在自然语言处理领域中不同长度文本的信息;稀疏张量则通常应用于图数据与图神经网络中,采用特殊的存储格式如坐标表格式(Coordinate List,COO),可以高效存储稀疏数据节省存储空间。

图3.2.3 张量分类
算子是构成神经网络的基本计算单元,对张量数据进行加工处理,实现了多种机器学习中常用的计算逻辑,包括数据转换、条件控制、数学运算等。为了便于梳理算子类别,按照功能将算子分类为张量操作算子、神经网络算子、数据流算子和控制流算子等。
-
张量操作算子:包括张量的结构操作和数学运算。张量的结构操作通常用于张量的形状、维度调整以及张量合并等,比如在卷积神经网络中可以选择图像数据以通道在前或者通道在后的格式来进行计算,调整图像张量的通道顺序就需要结构操作。张量相关的数学运算算子,例如矩阵乘法、计算范数、行列式和特征值计算,在机器学习模型的梯度计算中经常被使用到。
-
神经网络算子:包括特征提取、激活函数、损失函数、优化算法等,是构建神经网络模型频繁使用的核心算子。常见的卷积操作就是特征提取算子,用来提取比原输入更具代表性的特征张量。激活函数能够增加神经网络模型非线性能力,帮助模型表达更加复杂的数据特征关系。损失函数和优化算法则与模型参数训练更新息息相关。
-
数据流算子:包含数据的预处理与数据载入相关算子,数据预处理算子主要是针对图像数据和文本数据的裁剪填充、归一化、数据增强等操作。数据载入算子通常会对数据集进行随机乱序(Shuffle)、分批次载入(Batch)以及预载入(Pre-fetch)等操作。数据流操作主要功能是对原始数据进行处理后,转换为机器学习框架本身支持的数据格式,并且按照迭代次数输入给网络进行训练或者推理,提升数据载入速度,减少内存占用空间,降低网络训练数据等待时间。
-
控制流算子:可以控制计算图中的数据流向,当表示灵活复杂的模型时需要控制流。使用频率比较高的控制流算子有条件运算符和循环运算符。控制流操作一般分为两类,机器学习框架本身提供的控制流操作符和前端语言控制流操作符。控制流操作不仅会影响神经网络模型前向运算的数据流向,也会影响反向梯度运算的数据流向。
计算依赖
在计算图中,算子之间存在依赖关系,而这种依赖关系影响了算子的执行顺序与并行情况。机器学习算法模型中,计算图是一个有向无环图,即在计算图中造成循环依赖(Circular Dependency)的数据流向是不被允许的。循环依赖会形成计算逻辑上的死循环,模型的训练程序将无法正常结束,而流动在循环依赖闭环上的数据将会趋向于无穷大或者零成为无效数据。为了分析计算执行顺序和模型拓扑设计思路,下面将对计算图中的计算节点依赖关系进行讲解。
如 图3.2.4中所示,在此计算图中,若将Matmul1算子移除则该节点无输出,导致后续的激活函数无法得到输入,从而计算图中的数据流动中断,这表明计算图中的算子间具有依赖关系并且存在传递性。

图3.2.4 计算依赖
将依赖关系进行区分如下:
-
直接依赖:节点ReLU1直接依赖于节点Matmul1,即如果节点ReLU1要执行运算,必须接受直接来自节点Matmul1的输出数据;
-
间接依赖:节点Add间接依赖于节点Matmul1,即节点Matmul1的数据并未直接传输给节点Add,而是经过了某个或者某些中间节点进行处理后再传输给节点Add,而这些中间节点可能是节点Add的直接依赖节点,也可能是间接依赖节点;
-
相互独立:在计算图中节点Matmul1与节点Matmul2之间并无数据输入输出依赖关系,所以这两个节点间相互独立。
掌握依赖关系后,分析 图3.2.5可以得出节点Add间接依赖于节点Matmul,而节点Matmul直接依赖于节点Add,此时两个节点互相等待对方计算完成输出数据,将无法执行计算任务。若我们手动同时给两个节点赋予输入,计算将持续不间断进行,模型训练将无法停止造成死循环。循环依赖产生正反馈数据流,被传递的数值可能在正方向上无限放大,导致数值上溢,或者负方向上放大导致数值下溢,也可能导致数值无限逼近于0,这些情况都会致使模型训练无法得到预期结果。在构建深度学习模型时,应避免算子间产生循环依赖。

图3.2.5 循环依赖
在机器学习框架中,表示循环关系(Loop Iteration)通常是以展开机制(Unrolling)来实现。循环三次的计算图进行展开如 图3.2.6,循环体的计算子图按照迭代次数进行复制3次,将代表相邻迭代轮次的子图进行串联,相邻迭代轮次的计算子图之间是直接依赖关系。在计算图中,每一个张量和运算符都具有独特的标识符,即使是相同的操作运算,在参与循环不同迭代中的计算任务时具有不同的标识符。区分循环关系和循环依赖的关键在于,具有两个独特标识符的计算节点之间是否存在相互依赖关系。循环关系在展开复制计算子图的时候会给复制的所有张量和运算符赋予新的标识符,区分被复制的原始子图,以避免形成循环依赖。
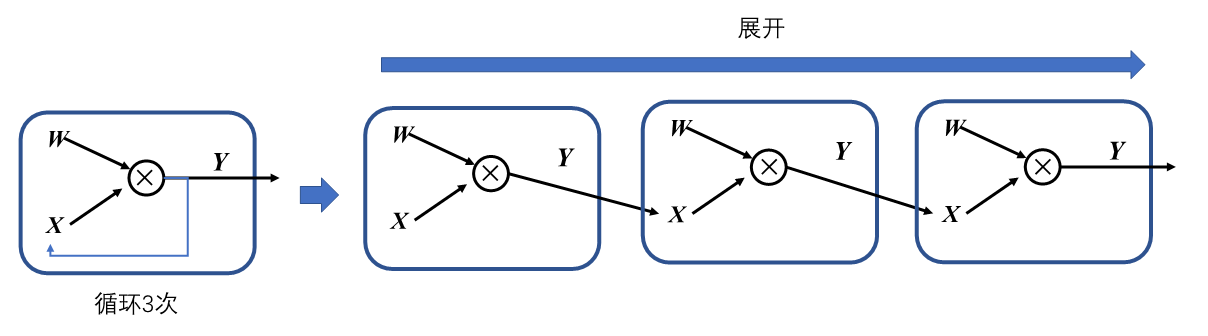
图3.2.6 循环展开
控制流
控制流能够设定特定的顺序执行计算任务,帮助构建更加灵活和复杂的模型。在模型中引入控制流后可以让计算图中某些节点循环执行任意次数,也可以根据条件判断选择某些节点不执行。许多深度学习模型依赖控制流进行训练和推理,基于递归神经网络和强化学习的模型就依赖于循环递归关系和依据输入数据状态条件执行计算。
目前主流的机器学习框架中通常使用两种方式来提供控制流:
-
前端语言控制流:通过Python语言控制流语句来进行计算图中的控制决策。使用前端语言控制流构建模型结构简便快捷,但是由于机器学习框架的数据计算运行在后端硬件,造成控制流和数据流之间的分离,计算图不能完整运行在后端计算硬件上。因此这类实现方式也被称为图外方法(Out-of-Graph Approach)
-
机器学习框架控制原语:机器学习框架在内部设计了低级别细粒度的控制原语运算符。低级别控制原语运算符能够执行在计算硬件上,与模型结构结合使用可将整体计算图在后端运算,这种实现方式也被称为图内方法(In-Graph Approach)。
为什么机器学习框架会采用两种不同的原理来实现控制流呢?为了解决这个疑问,首先了解两种方法在实现上的区别。
使用Python语言编程的用户对于图外方法较为熟悉。图外方法允许用户直接使用if-else、while和for这些Python命令来构建控制流。该方法使用时灵活易用便捷直观。
而图内方法相比于图外方法则较为烦琐。TensorFlow中可以使用图内方法控制流算子(如tf.cond条件控制、tf.while_loop循环控制和tf.case分支控制等)来构建模型控制流,这些算子是使用更加低级别的原语运算符组合而成。图内方法的控制流表达与用户常用的编程习惯并不一致,牺牲部分易用性换取的是计算性能提升。
图外方法虽然易用,但后端计算硬件可能无法支持前端语言的运行环境,导致无法直接执行前端语言控制流。而图内方法虽然编写烦琐,但可以不依赖前端语言环境直接在计算硬件上执行。在进行模型编译、优化与运行时都具备优势,提高运行效率。
因此两种控制流的实现方式其实对应着不同的使用场景。当需要在计算硬件上脱离前端语言环境执行模型训练、推理和部署等任务,需要采用图内方法来构建控制流。用户使用图外方法方便快速将算法转化为模型代码,方便验证模型构造的合理性。
目前在主流的机器学习框架中,均提供图外方法和图内方法支持。鉴于前端语言控制流使用频繁为人熟知,为了便于理解控制流对前向计算与反向计算的影响,后续的讲解均使用图外方法实现控制流。常见的控制流包括条件分支与循环两种。当模型包含控制流操作时,梯度在反向传播经过控制流时,需要在反向梯度计算图中也构造生成相应的控制流,才能够正确计算参与运算的张量梯度。
下面这段代码描述了简单的条件控制,matmul表示矩阵乘法算子:
def control(A, B, C, conditional = True):
if conditional:
y = matmul(A, B)
else:
y = matmul(A, C)
return y
图3.2.7描述上述代码的前向计算图和反向计算图。对于具有if条件的模型,梯度计算需要知道采用了条件的哪个分支,然后将梯度计算逻辑应用于该分支。在前向计算图中张量\(\boldsymbol{C}\)经过条件控制不参与计算,在反向计算时同样遵守控制流决策,不会计算关于张量\(\boldsymbol{C}\)的梯度。
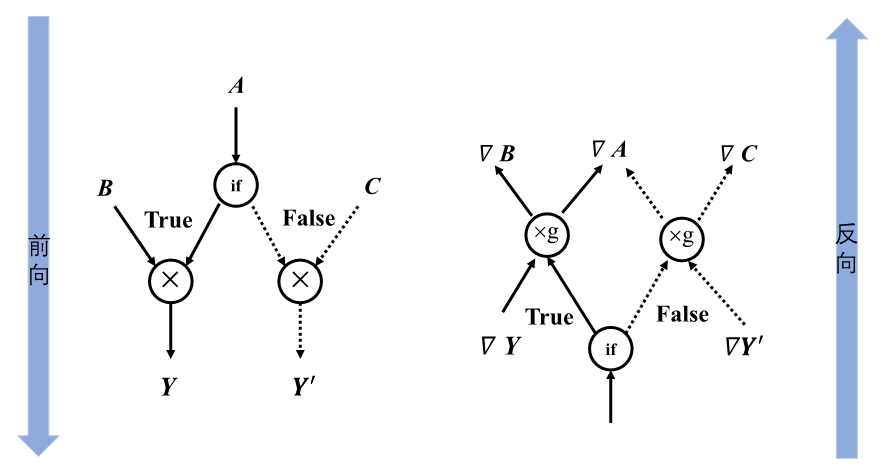
图3.2.7 条件控制计算图
当模型中有循环控制时,循环中的操作可以执行零次或者多次。此时采用展开机制,对每一次操作都赋予独特的运算标识符,以此来区分相同运算操作的多次调用。每一次循环都直接依赖于前一次循环的计算结果,所以在循环控制中需要维护一个张量列表,将循环迭代的中间结果缓存起来,这些中间结果将参与前向计算和梯度计算。下面这段代码描述了简单的循环控制,将其展开得到等价代码后,可以清楚的理解需要维护张量\(\boldsymbol{X_i}\)和\(\boldsymbol{W_i}\)的列表。
def recurrent_control(X : Tensor, W : Sequence[Tensor], cur_num = 3):
for i in range(cur_num):
X = matmul(X, W[i])
return X
#利用展开机制将上述代码展开,可得到等价表示
def recurrent_control(X : Tensor, W : Sequence[Tensor]):
X1 = matmul(X, W) #为便于表示与后续说明,此处W = W[0], W1 = W[1], W2 = W[2]
X2 = matmul(X1, W1)
Y = matmul(X2, W2)
return Y
如 图3.2.8描述了上述代码的前向计算图和反向计算图,循环控制的梯度同样也是一个循环,它与前向循环的迭代次数相同。执行循环体的梯度计算中,循环体当前迭代计算输出的梯度值作为下一次迭代中梯度计算的输入值,直至循环结束。
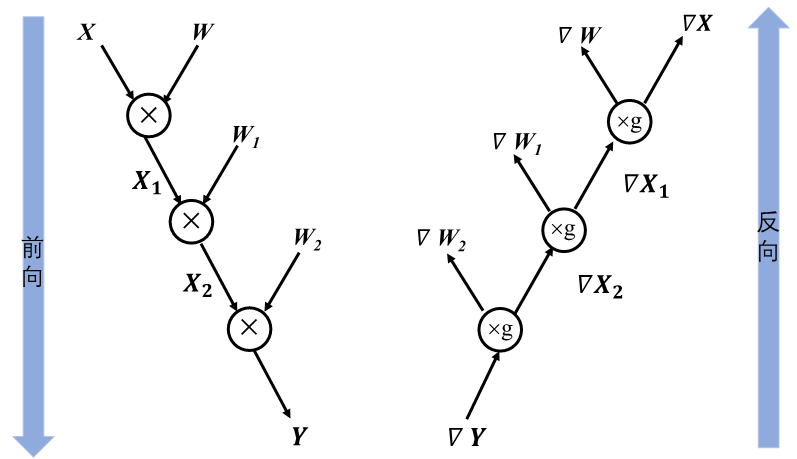
图3.2.8 循环控制计算图
基于链式法则计算梯度
在上一小节循环展开的例子中,当神经网络接收输入张量\(\boldsymbol{Y}\)后,输入数据根据计算图逐层进行计算并保存中间结果变量,直至经过多层的计算后最终产生输出\(\boldsymbol{Y_3}\),这个过程我们称之为前向传播(Forward propagation)。在深度神经网络模型训练过程中,前向传播的输出结果与标签值通过计算产生一个损失函数结果。模型将来自损失函数的数据信息通过计算图反向传播,执行梯度计算来更新训练参数。在神经网络模型中,反向传播通常使用损失函数关于参数的梯度来进行更新,也可以使用其他信息进行反向传播,在这里仅讨论一般情况。
反向传播过程中,使用链式法则来计算参数的梯度信息。链式法则是微积分中的求导法则,用于求解复合函数中的导数。复合函数的导数是构成复合有限个函数在相应点的导数乘积。假设f和g是关于实数x的映射函数,设\(y=g(x)\)并且\(z=f(y)=f(g(x))\),则z对x的导数即为:
\[\frac{dz}{dx}=\frac{dz}{dy}\frac{dy}{dx}\tag{1}\label{ch04-1}\]
神经网络的反向传播是根据反向计算图的特定运算顺序来执行链式法则的算法。由于神经网络的输入通常为三维张量,输出为一维向量。因此将上述复合函数关于标量的梯度法则进行推广和扩展。假设\(\boldsymbol{X}\)是m维张量,\(\boldsymbol{Y}\)为n维张量,\(\boldsymbol{z}\)为一维向量,\(\boldsymbol{Y}=g(\boldsymbol{X})\)并且\(\boldsymbol{z}=f(\boldsymbol{Y})\),则\(\boldsymbol{z}\)关于\(\boldsymbol{X}\)每一个元素的偏导数即为:
\[\frac{\partial z}{\partial x_i}=\sum_j\frac{\partial z}{\partial y_j}\frac{\partial y_j}{\partial x_i}\tag{2}\label{ch04-2}\]
上述公式可以等价的表示为:
\[\nabla_{\boldsymbol{X}}\boldsymbol{z} = (\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{X}})^{\top}\nabla_{\boldsymbol{Y}}\boldsymbol{z}\tag{3}\label{ch04-3}\]
其中\(\nabla_{\boldsymbol{X}}\boldsymbol{z}\)表示\(\boldsymbol{z}\)关于\(\boldsymbol{X}\)的梯度矩阵。
为了便于理解链式法则在神经网络模型中的运用,给出如 图3.2.9所示前向和反向结合的简单计算图。这个神经网络模型经过两次矩阵相乘得到预测值\(\boldsymbol{Y}\),然后根据输出与标签值之间的误差值进行反向梯度传播,以最小化误差值的目的来更新参数权重,模型中需要更新的参数权重包含\(\boldsymbol{W}\)和\(\boldsymbol{W_1}\)。
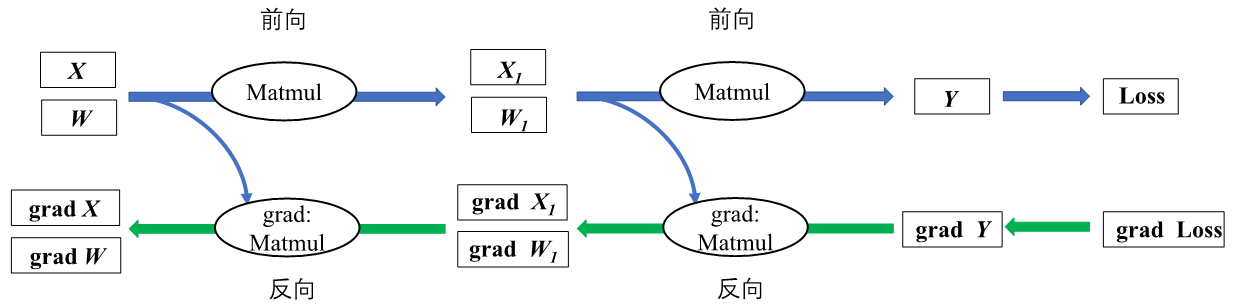
图3.2.9 反向传播局部计算图
假设选取均方误差为损失函数,那么损失值是怎样通过链式法则将梯度信息传递给图中的\(\boldsymbol{W}\)和\(\boldsymbol{W_1}\)呢?又为什么要计算非参数数据\(\boldsymbol{X}\)和\(\boldsymbol{X_1}\)的梯度呢?为了解决上述两个疑问,要详细思考前向传播和反向传播的计算过程。首先通过前向传播来计算损失值三个步骤:(1)\(\boldsymbol{X_1}=\boldsymbol{XW}\);(2)\(\boldsymbol{Y}=\boldsymbol{X_1W_1}\);(3)Loss=\(\frac{1}{2}\)(\(\boldsymbol{Y}\)-Label)\(^2\), 此处Label即为标签值。
得到损失函数之后,目的是最小化预测值和标签值间的差异。为此根据链式法则利用公式 (4)和公式 (5)来进行反向传播,来求解损失函数关于参数\(\boldsymbol{W}\)和\(\boldsymbol{W_1}\)的梯度值:
\[\frac{\partial {\rm Loss}}{\partial \boldsymbol{W_1}}=\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{W_1}}\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}\tag{4}\label{ch04-4}\]
\[\frac{\partial {\rm Loss}}{\partial \boldsymbol{W}}=\frac{\partial \boldsymbol{X_1}}{\partial \boldsymbol{W}}\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{X_1}}\tag{5}\label{ch04-5}\]
可以看出公式 (4)和公式 (5)都计算了\(\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}\)对应 图3.2.9中的grad \(\boldsymbol{Y}\)。公式 (5)中的\(\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{X_1}}\)对应 图3.2.9中的grad \(\boldsymbol{X_1}\),为了便于计算模型参数\(\boldsymbol{W}\)的梯度信息,需要计算中间结果\(\boldsymbol{X_1}\)的梯度信息。这也就解决了前面提出的第二个疑问,计算非参数的中间结果梯度是为了便于计算前序参数的梯度值。
接着将\(\boldsymbol{X_1}=\boldsymbol{XW}\)、\(\boldsymbol{Y}=\boldsymbol{X_1W_1}\)和Loss=\(\frac{1}{2}\)(\(\boldsymbol{Y}\)-Label)\(^2\)代入公式 (4)和公式 (5)展开为公式 (6)和公式 (7),可以分析机器学习框架在利用链式法则构建反向计算图时,变量是如何具体参与到梯度计算中的。
\[\frac{\partial {\rm Loss}}{\partial \boldsymbol{W_1}}=\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{W_1}}\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}=\boldsymbol{X_1}^\top(\boldsymbol{Y}-{\rm Label})\tag{6}\label{ch04-6}\]
\[\frac{\partial {\rm Loss}}{\partial \boldsymbol{W}}=\frac{\partial \boldsymbol{X_1}}{\partial \boldsymbol{W}}\frac{\partial {\rm Loss}}{\partial \boldsymbol{Y}}\frac{\partial \boldsymbol{Y}}{\partial \boldsymbol{X_1}}=\boldsymbol{X}^\top(\boldsymbol{Y}-{\rm Label})\boldsymbol{W_1}^\top\tag{7}\label{ch04-7}\]
公式 (6)在计算\(\boldsymbol{W_1}\)的梯度值时使用到了前向图中的中间结果\(\boldsymbol{X_1}\)。公式 (7)中不仅使用输入数据\(\boldsymbol{X}\)来进行梯度计算,参数\(\boldsymbol{W_1}\)也参与了参数\(\boldsymbol{W}\)的梯度值计算。因此可以回答第一个疑问,参与计算图中参数的梯度信息计算过程的不仅有后序网络层传递而来的梯度信息,还包含有前向计算中的中间结果和参数数值。
通过分析 图3.2.9和公式 (4)、(5)、(6)、(7)解决了两个疑问后,可以发现计算图在利用链式法则构建反向计算图时,会对计算过程进行分析保存模型中的中间结果和梯度传递状态,通过占用部分内存复用计算结果达到提高反向传播计算效率的目的。
将上述的链式法则推导推广到更加一般的情况,结合控制流的灵活构造,机器学习框架均可以利用计算图快速分析出前向数据流和反向梯度流的计算过程,正确的管理中间结果内存周期,更加高效的完成计算任务。
计算图的生成
计算图的生成
在了解计算图的基本构成后,那么下一个问题就是:计算图要如何自动化生成呢?在机器学习框架中可以生成静态图和动态图两种计算图。静态生成可以根据前端语言描述的神经网络拓扑结构以及参数变量等信息构建一份固定的计算图。因此静态图在执行期间可以不依赖前端语言描述,常用于神经网络模型的部署,比如移动端人脸识别场景中的应用等。
动态图则需要在每一次执行神经网络模型依据前端语言描述动态生成一份临时的计算图,这意味着计算图的动态生成过程灵活可变,该特性有助于在神经网络结构调整阶段提高效率。主流机器学习框架TensorFlow、MindSpore均支持动态图和静态图模式;PyTorch则可以通过工具将构建的动态图神经网络模型转化为静态结构,以获得高效的计算执行效率。了解两种计算图生成方式的优缺点及构建执行特点,可以针对待解决的任务需求,选择合适的生成方式调用执行神经网络模型。
静态生成
静态图的生成与执行原理如 图3.3.1所示,采用先编译后执行的方式,该模式将计算图的定义和执行进行分离。
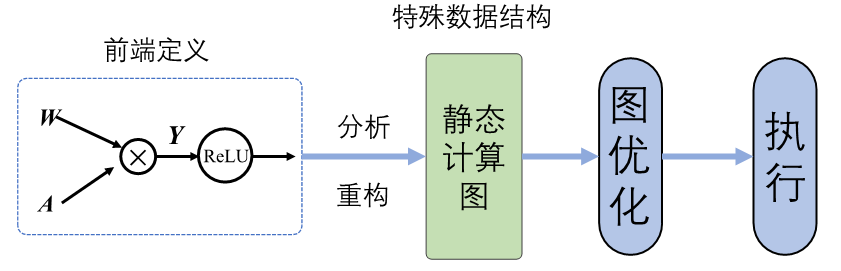
图3.3.1 静态图生成与执行
使用前端语言定义模型形成完整的程序表达后,机器学习框架首先对神经网络模型进行分析,获取网络层之间的连接拓扑关系以及参数变量设置、损失函数等信息。然后机器学习框架会将完整的模型描述编译为可被后端计算硬件调用执行的固定代码文本,这种固定代码文本通常被称为静态计算图。当使用静态计算图进行模型训练或者推理过程时,无需编译前端语言模型。静态计算图直接接收数据并通过相应硬件调度执行图中的算子来完成任务。静态计算图可以通过优化策略转换成等价的更加高效的结构,提高后端硬件的计算效率。
以构建并执行下列伪代码,来详细讲解静态图的生成与执行。在部分机器学习框架中进行前端定义时,需要声明并编写包含数据占位符、损失函数、优化函数、网络编译和执行环境以及网络执行器等在内的预定义配置项,此外还需要使用图内控制流算子编写控制语句。随着机器学习框架设计的改进与发展,框架趋向于提供的友好的编程接口和统一的模型构建模式,比如MindSpore提供动静态统一的前端编程表达。因此为了便于理解静态生成的过程与原理,此处使用更加简洁的语言逻辑描述模型。
def model(X, flag):
if flag>0:
Y = matmul(W1, X)
else:
Y = matmul(W2, X)
Y = Y + b
Y = relu(Y)
return Y
机器学习框架在进行静态生成编译时并不读取输入数据,此时需要一种特殊的张量来表示输入数据辅助构建完整的计算图,这种特殊张量就被称为:数据占位符(Placeholder )。在代码第1行中输入数据\(\boldsymbol{X}\)需要使用占位符在静态图中表示。由于静态生成时模型无数据输入,因此代码第2行中的条件控制,也无法进行逻辑计算,条件控制在编译阶段并不会完成判断,因此需要将条件控制算子以及所有的分支计算子图加入计算图中。在静态计算图执行计算阶段网络接收数据流入,调度条件控制算子根据输入数据进行逻辑判断,控制数据流入不同的分支计算子图中进行后续计算。在部分机器学习框架中前端语言Python的控制流不能够被正确编译为等价的静态图结构,因此需要机器学习框架的控制原语来实现控制流。
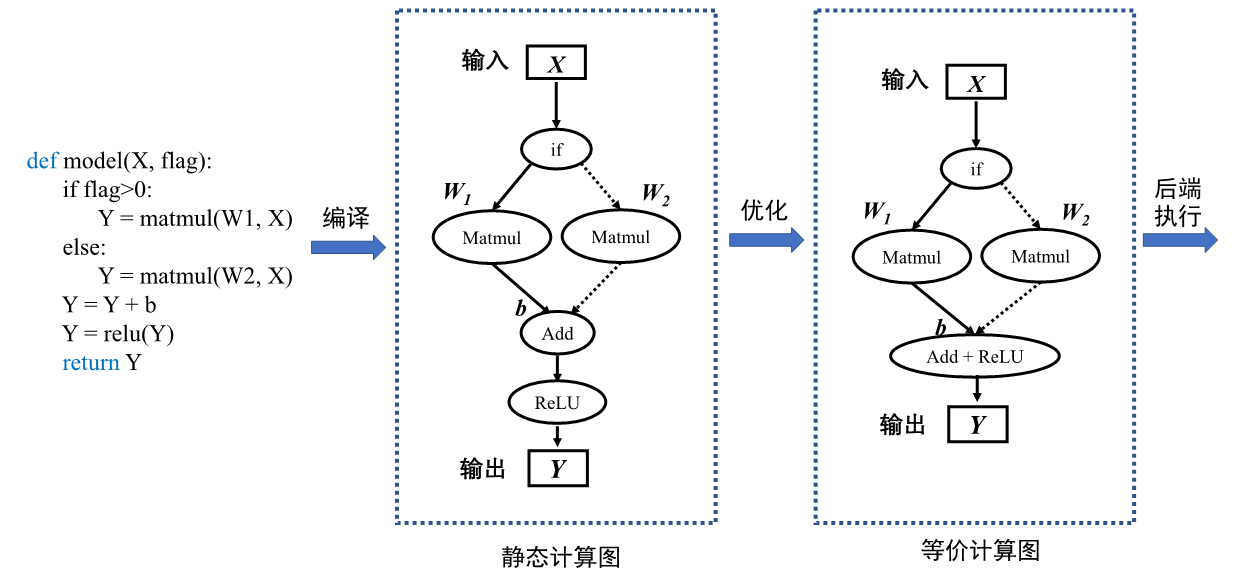
图3.3.2 静态生成
静态计算图具有两大优势:计算性能与直接部署。静态图经过机器学习框架编译时能够获取模型完整的图拓扑关系。机器学习框架掌控全局信息便更容易制定计算图的优化策略,比如算子融合将网络中的两个或多个细粒度的算子融合为一个粗粒度算子,比如 图3.3.2中将Add算子与ReLU合并为一个操作,可节省中间计算结果的存储、读取等过程,降低框架底层算子调度的开销,从而提升执行性能和效率,降低内存开销。因此使用静态图模型运行往往能够获取更好的性能和更少的内存占用。在后续章节中将详细介绍更多关于机器学习框架在编译方面的优化策略。
在部署模型进行应用时,可以将静态计算图序列化保存。在模型推理阶段,执行序列化的模型即可,无需重新编译前端语言源代码。机器学习框架可以将静态计算图转换为支持不同计算硬件直接调用的代码。结合计算图序列化和计算图转硬件代码两种特性,静态图模型可以直接部署在不同的硬件上面,提供高效的推理服务。
尽管静态图具备强大的执行计算性能与直接部署能力,但是在部分机器学习框架中静态图模式下,编写神经网络模型以及定义模型训练过程代码较为烦琐。如下面代码所示,将本小节前面的代码改写为以TensorFlow机器学习框架静态图模式要求的代码, 代码第10行使用图内控制流算子来实现条件控制。静态图模式下的代码编写和阅读对于机器学习入门者都有一定门槛。
import tensorflow as tf
import numpy as np
x = tf.placeholder(dtype=tf.float32, shape=(5,5)) #数据占位符
w1 = tf.Variable(tf.ones([5,5]),name='w1')
w2 = tf.Variable(tf.zeros([5,5]),name='w2')
b = tf.Variable(tf.zeros([5,]),name='b')
def f1(): return tf.matmul(w1,x)
def f2(): return tf.matmul(w2,x)
y1 = tf.cond(flag > 0, f1, f2) #图内条件控制算子
y2 = tf.add(y1, b)
output = tf.relu(y2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #静态图变量初始化
random_array = np.random.rand(5,5)
sess.run(output, feed_dict = {x:random_array, flag: [1.0]}) #静态图执行
前端语言构建的神经网络模型经过编译后,计算图结构便固定执行阶段不再改变,并且经过优化用于执行的静态图代码与原始代码有较大的差距。代码执行过程中发生错误时,机器学习框架会返回错误在优化后的静态图代码位置。用户难以直接查看优化后的代码,因此无法定位原始代码错误位置,增加了代码调试难度。比如在代码中,若add算子和relu算子经给优化合并为一个算子,执行时合并算子报错,用户可能并不知道错误指向的是add算子错误 还是relu算子错误。
此外在神经网络模型开发迭代环节,不能即时打印中间结果。若在源码中添加输出中间结果的代码,则需要将源码重新编译后,再调用执行器才能获取相关信息,降低了代码调试效率。对比之下,动态图模式则相比较灵活,接下来讲解动态生成机制。
动态生成
动态图原理如 图3.3.3所示,采用解析式的执行方式,其核心特点是编译与执行同时发生。动态图采用前端语言自身的解释器对代码进行解析,利用机器学习框架本身的算子分发功能,算子会即刻执行并输出结果。动态图模式采用用户友好的命令式编程范式,使用前端语言构建神经网络模型更加简洁,深受广大深度学习研究者青睐。
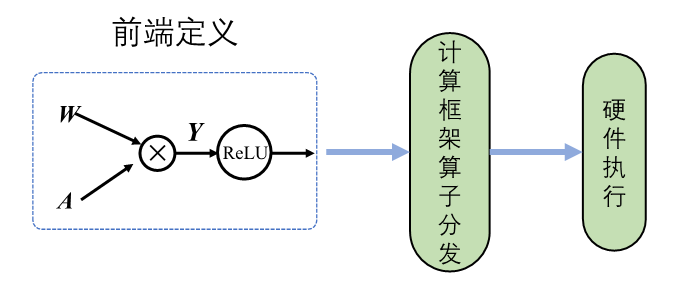
图3.3.3 动态图原理
接下来使用上一小节的伪代码来讲解动态生成和静态生成的区别。
静态图和动态图除了在前端语言表达上略有差异,本质的区别在于编译执行过程。使用前端语言构建完成模型表达后,动态生成并不采用机器学习框架编译器生成完整的静态计算图,而是采用前端语言的解释器Python API调用机器学习框架,框架利用自身的算子分发功能,将Python调用的算子在相应的硬件如CPU、GPU、NPU等上进行加速计算,然后再将计算结果返回给前端。该过程并不产生静态的计算图,而是按照前端语言描述模型结构,按照计算依赖关系进行调度执行,动态生成临时的图拓扑结构。
如图3.3.4中所示动态生成流程。
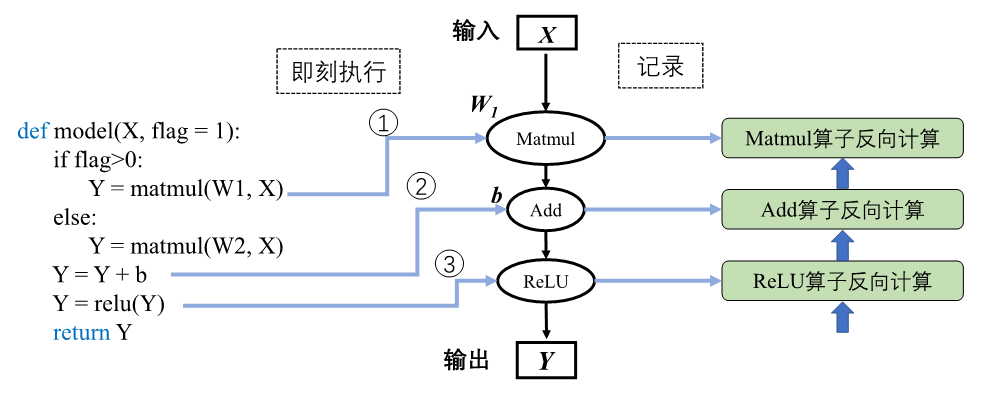
图3.3.4 动态生成
神经网络前向计算按照模型声明定义的顺序进行执行。当模型接收输入数据\(\boldsymbol{X}\)后,机器学习框架开始动态生成图拓扑结构,添加输入节点并准备将数据传输给后续节点。模型中存在条件控制时,动态图模式下会即刻得到逻辑判断结果并确定数据流向,因此在图中假设判断结果为真的情况下,图结构中仅会添加关于张量\(\boldsymbol{W1}\)的Matmul算子节点。按照代码制定的模型计算顺序与算子依赖关系,机器学习框架会依次添加Add算子节点和ReLU算子节点。机器学习框架会在添加节点的同时完成算子分发计算并返回计算结果,同时做好准备向后续添加的节点传输数据。当模型再次进行前向计算时,动态生成的图结构则失效,并再次根据输入和控制条件生成新的图结构。相比于静态生成,可以发现动态生成的图结构并不能完整表示前端语言描述的模型结构,需要即时根据控制条件和数据流向产生图结构。由于机器学习框架无法通过动态生成获取完整的模型结构,因此动态图模式下难以进行模型优化以提高计算效率。
在静态生成方式下,由于已经获取完整的神经网络模型定义,因此可以同时构建出完整的前向计算图和反向计算图。而在动态生成中,由于边解析边执行的特性,反向梯度计算的构建随着前向计算调用而进行。在执行前向过程中,机器学习框架根据前向算子的调用信息,记录对应的反向算子信息以及参与梯度计算的张量信息。前向计算完毕之后,反向算子与张量信息随之完成记录,机器学习框架会根据前向动态图拓扑结构,将所有反向过程串联起来形成整体反向计算图。最终,将反向图在计算硬件上执行计算得到梯度用于参数更新。
对应于 图3.3.4中,当调用到关于张量\(\boldsymbol{W1}\)的Matmul算子节点时,框架会执行两个操作:调用Matmul算子,计算关于输入\(\boldsymbol{X}\)和\(\boldsymbol{W1}\)的乘积结果,同时根据反向计算过程Grad_\(\boldsymbol{W1}\)=Grad_\(\boldsymbol{Y}*\boldsymbol{X}\),记录下需要参与反向计算的算子和张量\(\boldsymbol{X}\),机器学习框架依据收集的信息完成前向计算和反向图构建。
尽管动态生成中完整的网络结构在执行前是未知的,不能使用静态图中的图优化技术来提高计算执行性能。但其即刻算子调用与计算的能力,使得模型代码在运行的时候,每执行一句就会立即进行运算并会返回具体的值,方便开发者在模型构建优化过程中进行错误分析、结果查看等调试工作,为研究和实验提供了高效的助力。
此外得益于动态图模式灵活的计算执行特性,动态生成可以使用前端语言的原生控制流,充分发挥前端语言的编程友好性特性。解决了静态图中代码难调试、代码编写烦琐以及控制流复杂等问题,对于初学者更加友好,提高了算法开发迭代效率和神经网络模型改进速率。
动态和静态生成的比较
| 特性 | 静态图 | 动态图 |
|---|---|---|
| 即时获取中间结果 | 否 | 是 |
| 代码调试难易 | 难 | 易 |
| 控制流实现方式 | 特定的语法 | 前端语言语法 |
| 性能 | 优化策略多,性能更佳 | 图优化受限,性能较差 |
| 内存占用 | 内存占用少 | 内存占用相对较多 |
| 内存占用 | 可直接部署 | 不可直接部署 |
从使用者的角度可以直观的感受到静态图不能实时获取中间结果、代码调试困难以及控制流编写复杂,而动态图可以实时获取结果、调试简单、控制流符合编程习惯。虽然静态图的编写、生成过程复杂,但是相应的执行性能却超过动态图,下面用一个简单的代码来说明在性能和内存占用方面静态图的优势。
def model(X1, X2):
Y1 = matmul(X1, W1)
Y2 = matmul(X2, W2)
Y = Y1 + Y2
output = relu(Y)
return output
若对代码进行静态生成,机器学习框架可以构建完整的计算图。分析可知,计算\(\boldsymbol{Y_1}\)和\(\boldsymbol{Y_2}\)的过程相对独立,可以将其进行自动并行计算,加快计算效率。在静态生成过程中还可以利用计算图优化策略中的算子融合方法,将Add和ReLU两个算子融合为一个算子执行,这样减少了中间变量\(\boldsymbol{Y}\)的存储与读取过程,加快了计算效率,减少了内存占用。而动态生成的过程中,若无手动配置并行策略,机器学习框架无法获取图结构不能分析出算子之间的独立性,则只能按照代码顺序执行Add和ReLU两步操作,且需要存储变量\(\boldsymbol{Y}\)。除此之外,由于静态生成能够同时分析重构出前向计算图和反向计算图,可以提前确定反向计算中需要保存的前向中间变量信息。而动态生成则在完成前向计算后才能构建出反向计算图,为了保证反向计算效率需要保存更多的前向计算中间变量信息,相比之下静态生成的过程更加节省内存占用。
针对两种模式的特性,结合任务需求选择合适的模式可以事半功倍,学术科研以及模型开发调试阶段,为了快速验证思想和迭代更新模型结构可以选择动态图模式进行构建算法;网络模型确定,为了加速训练过程或者为硬件部署模型,可以选择静态图模式。
动态图与静态图的转换和融合
动态图便于调试,适用于模型构建实验阶段;静态图执行高效,节省模型训练时间,那么有没有办法可以让机器学习框架结合两种模式的优势呢?事实上,目前TensorFlow、MindSpore、PyTorch、PaddlePaddle等主流机器学习框架为了兼顾动态图易用性和静态图执行性能高效两方面优势,均具备动态图转静态图的功能,支持使用动态图编写代码,框架自动转换为静态图网络结构执行计算。
- 将各框架中支持源码转换和追踪转换技术的接口梳理如 dynamic_static_switch所示。
-
主流框架动态图转换静态图支持
| 框架 | 动态图转静态图 |
|---|---|
| TensorFlow | @tf_function追踪算子调度构建静态图, 其中AutoGraph机制可以自动转换控制流为静态表达 |
| MindSpore | context.set_context(mode=context.PYNATIVE_MODE)动态图模式, context.set_context(mode=context.GRAPH_MODE) 静态图模式, @ms_function支持基于源码转换 |
| PyTorch | torch.jit.script()支持基于源码转换, torch.jit.trace()支持基于追踪转换 |
| PaddlePaddle | paddle.jit.to_static()支持基于源码转换, paddle.jit.TracedLayer.trace()支持基于追踪转换 |
动态图转换为静态图的实现方式有两种:
-
基于追踪转换:以动态图模式执行并记录调度的算子,构建和保存为静态图模型。
-
基于源码转换:分析前端代码来将动态图代码自动转写为静态图代码,并在底层自动帮用户使用静态图执行器运行。
基于追踪转换的原理相对简单,当使用动态图模式构建好网络后,使用追踪进行转换将分为两个阶段。第一个阶段与动态生成原理相同,机器学习框架创建并运行动态图代码,自动追踪数据流的流动以及算子的调度,将所有的算子捕获并根据调度顺序构建静态图模型。与动态生成不同的地方在于机器学习框架并不会销毁构建好的图,而是将其保存为静态图留待后续执行计算。第二个阶段,当执行完一次动态图后,机器学习框架已生成静态图,当再次调用相同的模型时,机器学习框架会自动指向静态图模型执行计算。追踪技术只是记录第一次执行动态图时调度的算子,但若是模型中存在依赖于中间结果的条件分支控制流,只能追踪到根据第一次执行时触发的分支。此时构建的静态图模型并不是完整的,缺失了数据未流向的其他分支。在后续的调用中,因为静态模型已无法再改变,若计算过程中数据流向缺失分支会导致模型运行错误。同样的,依赖于中间数据结果的循环控制也无法追踪到全部的迭代状态。
动态图基于前端语言的解释器进行模型代码的解析执行,而静态图模式下需要经过机器学习框架自带的图编译器对模型进行建图后,再执行静态计算图。由于图编译器所支持编译的静态图代码与动态图代码之间存在差异,因此需要基于源码转换的方法将动态图代码转换为静态图代码描述,然后经过图编译器生成静态计算图。
基于源码转换的方式则能够改善基于追踪转换的缺陷。如 图3.3.5中所示,基于源码转换的流程经历两个阶段。第一个阶段,对动态图模式下的代码扫描进行词法分析,通过词法分析器分析源代码中的所有字符,对代码进行分割并移除空白符、注释等,将所有的单词或字符都转化成符合规范的词法单元列表。接着进行语法分析即解析器,将得到的词法单元列表转换成树形式,并对语法进行检查避免错误。第二阶段,动态图转静态图的核心部分就是对抽象语法树进行转写,机器学习框架中对每一个需要转换的语法都预设有转换器,每一个转换器对语法树进行扫描改写,将动态图代码语法映射为静态图代码语法。其中最为重要的前端语言控制流,会在这一阶段分析转换为静态图接口进行实现,也就避免了基于追踪转换中控制流缺失的情况。转写完毕之后,即可从新的语法树还原出可执行的静态图代码。

图3.3.5 基于源码转换流程
在使用上述功能的过程中,可以将整体模型动态图代码全部转换为静态图代码,提高计算效率并用于硬件部署。同时也可以将整体模型中的部分函数转化为局部静态子图,静态子图会被机器学习框架视为一个完整的算子并嵌入动态图中。执行整体动态图时,当计算到对应的函数会自动调用静态子图。使用该方式既提高了计算效率,又在一定程度上保留代码调试改进的灵活性。
下面代码中模型整体可以采用动态生成,而@ms_function可以使用基于源码转换的技术将模块add_and_relu的转化为静态图结构。与动态生成中代码执行相同,模型接收输入按照模型定义的计算顺序进行调度执行,并生成临时动态图结构,当执行语句Y=add_and_relu(Y,b)时,机器学习框架会自动调用该模块静态生成的图结构执行计算,通过动态图和静态图的混合执行提高计算能力。此外,动静态转换的技术常用于模型部署阶段。部署动态图模型时除了需要训练完成的参数文件,还须根据前端语言编写的模型代码构建拓扑关系。这使得动态图部署受到局限性,部署硬件中往往难以提供支持前端语言运行的执行环境。因此当使用动态图模式训练完模型参数后,可以将整体网络结构转换为静态图格式,将神经网络模型和参数文件进行序列化保存,与前端代码完全解耦,扩大模型部署的硬件支持范围。
@ms_function #mindspore中基于源码转换的函数装饰器,可以将该函数转换为静态图
def add_and_relu(Y, b):
Y = Y + b
Y = relu(Y)
return Y
def model(X, flag):
if flag>0:
Y = matmul(W1, X)
else:
Y = matmul(W2, X)
Y = add_and_relu(Y, b)
return Y
计算图的调度
计算图的调度
模型训练就是计算图调度图中算子的执行过程。宏观来看训练任务是由设定好的训练迭代次数来循环执行计算图,此时需要优化迭代训练计算图过程中数据流载入和训练(推理)执行等多个任务之间的调度策略。微观上单次迭代需要考虑计算图内部的调度执行问题,根据计算图结构、计算依赖关系、计算控制分析算子的执行调度。优化计算图的调度和执行性能,目的是尽可能充分利用计算资源,提高计算效率,缩短模型训练和推理时间。接下来会详细介绍计算图的调度和执行。
算子调度执行
算子的执行调度包含两个步骤,第一步,根据拓扑排序算法,将计算图进行拓扑排序得到线性的算子调度序列;第二步,将序列中的算子分配到指令流进行运算,尽可能将序列中的算子并行执行,提高计算资源的利用率。
计算图是一种由依赖边和算子构成的有向无环图,机器学习框架后端需要将包含这种依赖关系的算子准确地发送到计算资源,比如GPU、NPU上执行。针对有向无环图,通常使用拓扑排序来得到一串线性的序列。
如 图3.4.1所示,左边是一张有向无环图。图中包含了a、b、c、d、e五个节点和a->d、b->c、c->d、d->e四条边(a->d表示d依赖于a,称为依赖边)。将图的依赖边表达成节点的入度(图论中通常指有向图中某点作为图中边的终点的次数之和),可以得到各个节点的入度信息(a:0、 b:0、 c:1、 d:2、 e:1)。拓扑排序就是不断循环将入度为0的节点取出放入队列中,直至有向无环图中的全部节点都加入到队列中,循环结束。例如,第一步将入度为0的a、b节点放入到队列中,此时有向无环图中c、d的入度需要减1,得到新的入度信息(c:0、d:1、e:1)。以此类推,将所有的节点都放入到队列中并结束排序。

图3.4.1 算子调度执行
生成调度序列之后,需要将序列中的算子与数据分发到指定的GPU/NPU上执行运算。根据算子依赖关系和计算设备数量,可以将无相互依赖关系的算子分发到不同的计算设备,同时执行运算,这一过程称之为并行计算,与之相对应的按照序贯顺序在同一设备执行运算被称为串行计算。在深度学习中,当数据集和参数量的规模越来越大在分发数据与算子时通信消耗会随之而增加,计算设备会在数据传输的过程中处于闲置状态。此时采用同步与异步的任务调度机制可以更好的协调通信与训练任务,提高通信模块与计算设备的使用率,在后续的小节中将详细介绍串行与并行、同步与异步的概念。
串行与并行
根据任务队列的执行顺序,我们可以将计算图的任务调度队列分为以下两种:
-
串行:队列中的任务必须按照顺序进行调度执行直至队列结束;
-
并行:队列中的任务可以同时进行调度执行,加快执行效率。
首先从微观上来分析计算图内部的串行调度。计算图中大多数算子之间存在直接依赖或者间接依赖关系,具有依赖关系的算子间任务调度则必定存在执行前后的时间顺序。如 图3.4.2,计算图接受输入数据进行前向计算得到预测值,计算损失函数进行反向梯度计算,整体代码流程后序算子的计算有赖于前序算子的输出。此时算子的执行队列只能以串行的方式进行调度,保证算子都能正确接受到输入数据,才能完成计算图的一次完整执行。
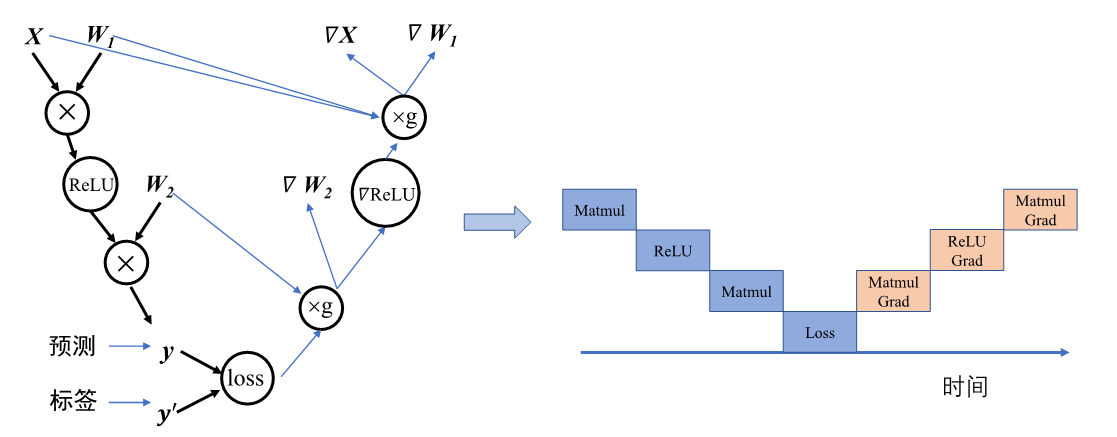
图3.4.2 算子的串行
宏观上来看迭代训练之间,每一轮迭代中计算图必须读取训练数据,执行完整的前向计算和反向梯度计算,将图中所有参数值更新完毕后,才能开始下一轮的计算图迭代计算更新。所以“数据载入-数据预处理-模型训练”的计算图整体任务调度是以串行方式进行的。
在分析计算图内部算子依赖关系时,除了直接依赖和间接依赖之外,存在算子间相互独立的情况。如 图3.4.3中op1和op2之间相互独立,此时可以将两个算子分配到两个硬件上进行并行计算。对比串行执行,并行计算可以同时利用更多的计算资源来缩短执行时间。

图3.4.3 算子的并行
并行包括算子并行、模型并行以及数据并行。算子并行不仅可以在相互独立的算子间实现,同时也可以将单个算子合理的切分为相互独立的多个子操作,进一步提高并行性。模型并行就是将整体计算图进行合理的切分,分配到不同设备上进行并行计算,缩短单次计算图迭代训练时间。数据并行则同时以不同的数据训练多个相同结构的计算图,减少训练迭代次数,加快训练效率。这三种并行方式将在后续章节中进行详细讲解。
数据载入同步与异步机制
一次完整计算图的训练执行过程包含:数据载入、数据预处理、网络训练三个环节。三个环节之间的任务调度是以串行方式进行,每一个环节都有赖于前一个环节的输出。但计算图的训练是多轮迭代的过程,多轮训练之间的三个环节可以用同步与异步两种机制来进行调度执行。
-
同步:顺序执行任务,当前任务执行完后会等待后续任务执行情况,任务之间需要等待、协调运行;
-
异步:当前任务完成后,不需要等待后续任务的执行情况,可继续执行当前任务下一轮迭代。
以同步机制来执行计算图训练时,如 图3.4.4所示,每一轮迭代中,数据载入后进行数据预处理操作,然后传输给计算图进行训练。每一个环节执行完当前迭代中的任务后,会一直等待后续环节的处理,直至计算图完成一次迭代训练更新参数值后,才会进行下一轮迭代的数据载入、数据预处理以及网络训练。当进行数据载入时,数据预处理、模型训练处于等待的状态;同样的,模型处于训练时,数据载入的I/O通道处于空闲,同步机制造成计算资源和通信资源的浪费。

图3.4.4 同步机制
以异步机制来执行计算图训练时,如 图3.4.5所示,在迭代训练中,当数据通道载入数据后交给后续的数据预处理环节后,不需要等待计算图训练迭代完成,直接读取下一批次的数据。对比同步机制,异步机制的引入减少了数据载入、数据预处理、网络训练三个环节的空闲等待时间,能够大幅度缩短迭代训练的整体时间,提高任务执行效率。

图3.4.5 异步机制
将异步机制与并行计算结合在一起,如 图3.4.6所示,一方面异步机制减少模型等待数据载入和预处理的时间,另一方面并行计算增加了单轮模型训练接受的数据量。相比于不采用异步机制和同步计算,机器学习框架可以利用丰富的计算资源更快速的遍历训练完数据集,缩短训练时间提高计算效率。

图3.4.6 异步并行
总结
总结
-
为了兼顾编程的灵活性和计算的高效性,设计了基于计算图的机器学习框架。
-
计算图的基本数据结构是张量,基本运算单元是算子。
-
计算图可以表示机器学习模型的计算逻辑和状态,利用计算图分析图结构并进行优化。
-
计算图是一个有向无环图,图中算子间可以存在直接依赖和间接依赖关系,或者相互关系独立,但不可以出现循环依赖关系。
-
可以利用控制流来改变数据在计算图中的流向,常用的控制流包括条件控制和循环控制。
-
计算图的生成可以分为静态生成和动态生成两种方式。
-
静态图计算效率高,内存使用效率高,但调试性能较差,可以直接用于模型部署。
-
动态图提供灵活的可编程性和可调试性,可实时得到计算结果,在模型调优与算法改进迭代方面具有优势。
-
利用计算图和算子间依赖关系可以解决模型中的算子执行调度问题。
-
根据计算图可以找到相互独立的算子进行并发调度,提高计算的并行性。而存在依赖关系的算子则必须依次调度执行。
-
计算图的训练任务可以使用同步或者异步机制,异步能够有效提高硬件使用率,缩短训练时间。
扩展阅读
- 计算图是机器学习框架的核心理念之一,了解主流机器学习框架的设计思想,有助于深入掌握这一概念,建议阅读 TensorFlow 设计白皮书、 PyTorch计算框架设计论文。
- 图外控制流直接使用前端语言控制流,熟悉编程语言即可掌握这一方法,而图内控制流则相对较为复杂,建议阅读TensorFlow控制流论文。
- 动态图和静态图设计理念与实践,建议阅读TensorFlow Eager 论文、TensorFlow Eager Execution示例、TensorFlow Graph理念与实践、MindSpore动静态图概念。
第二部分:进阶篇
下面本书将重点讲解 AI 编译器的基本构成,以及 AI 编译器前端、后端和运行时中的关键技术。本书也将对于硬件加速器、数据处理、模型部署和分布式训练分别进行深入解读,从而为开发者提供从 0 到 1 构建机器学习框架所需的核心知识和实践经验。
AI编译器和前端技术
编译器作为计算机系统的核心组件,在机器学习框架设计中也扮演着重要的角色,并衍生出了一个专门的编译器种类:AI编译器。AI编译器既要对上承接模型算法的变化,满足算法开发者不断探索的研究诉求,又要对下在最终的二进制输出上满足多样性硬件的诉求,满足不同部署环境的资源要求。既要满足框架的通用普适性,又要满足易用性的灵活性要求,还要满足性能的不断优化诉求。AI编译器保证了机器学习算法的便捷表达和高效执行,日渐成为了机器学习框架设计的重要一环。
本章将先从AI编译器的整体框架入手, 介绍AI编译器的基础结构。接下来,本章会详细讨论编译器前端的设计,并将重点放在中间表示以及自动微分两个部分。有关AI编译器后端的详细知识, 将会在后续的第五章进行讨论。
本章的学习目标包括:
-
理解AI编译器的基本设计原理
-
理解中间表示的基础概念,特点和实现方法
-
理解自动微分的基础概念,特点和实现方法
-
了解类型系统和静态推导的基本原理
-
了解编译器优化的主要手段和常见优化方法
AI编译器设计原理
AI编译器设计原理
无论是传统编译器还是AI编译器,它们的输入均为用户的编程代码,输出也机器执行的高效代码。进阶篇将用两个章节详细介绍AI编译器,里面的很多概念借用了通用编译器中的概念,如AOT(Ahead of Time提前编译)、JIT(Just in time 即时)、IR(Intermediate Representation中间表示)、PASS优化、AST(Abstract Trees)、副作用、闭包等概念,和编译器教材中对应概念的定义相同,对编译器相关概念感兴趣的读者可以翻阅相关的编译原理教材,本书会将讨论重点放在机器学习编译器相较于传统编译器的独特设计与功能上。
AI编译器的设计受到了主流编译器(如LLVM)的影响。为了方便理解AI编译器,首先通过 图5.1.1展示LLVM编译器的架构。
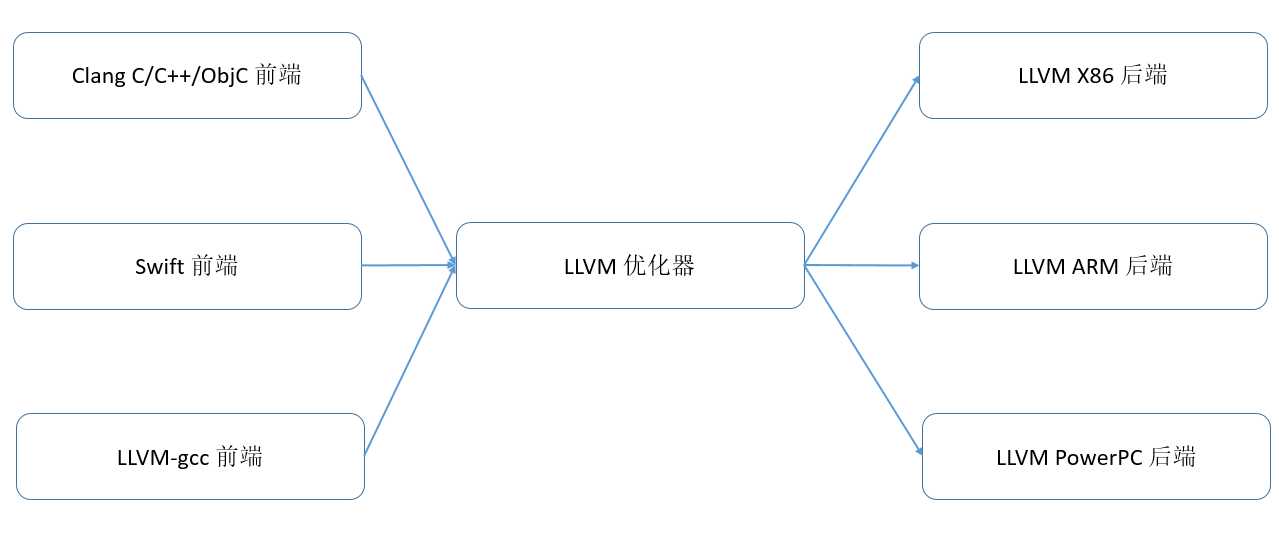
图5.1.1 LLVM编译器基础架构
LLVM包含了前端、IR和后端三个部分。前端将高级语言转换成IR,后端将IR转换成目标硬件上的机器指令,IR作为桥梁在前后端之间进行基于IR的各种优化。这样无论是新增硬件的支持,还是新增前端的支持,都可以尽可能地复用IR相关的部分。IR可以是单层的,也可以是多层的, LLVM IR是典型的单层IR,其前后端优化都基于相同的LLVM IR进行。
AI编译器一般采用多层级IR设计。 图5.1.2展示了TensorFlow利用MLIR实现多层IR设计的例子(被称为TensorFlow-MLIR)。其包含了三个层次的IR,即TensorFlow Graph IR, XLA(Accelerated Linear Algebra,加速线性代数)、HLO(High Level Operations,高级运算)以及特定硬件的LLVM IR 或者TPU IR,下面就不同的层级IR和其上的编译优化做一个简要介绍。
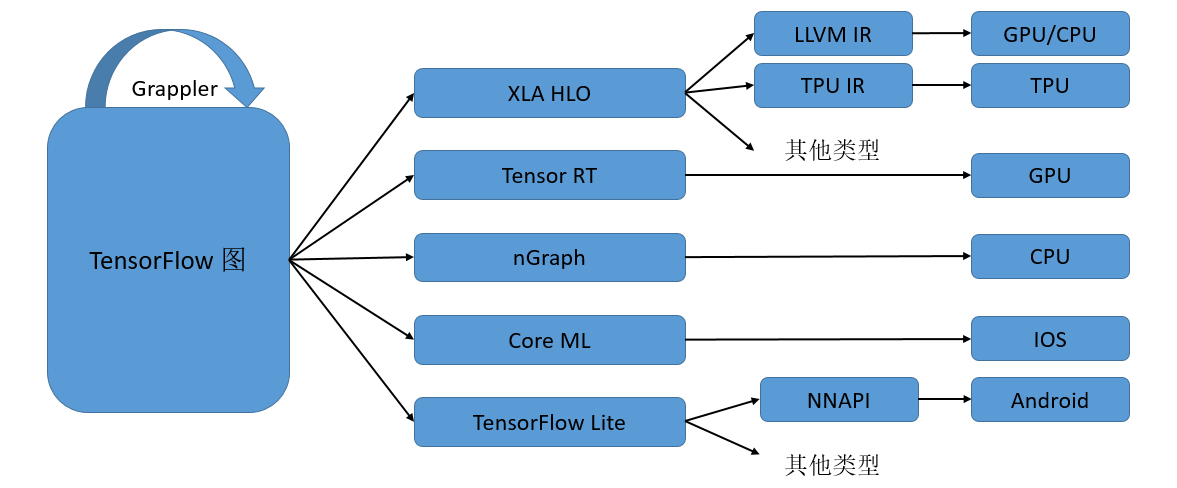
图5.1.2 TensorFlow的多层IR设计
计算图中涉及的编译优化一般称为图编译优化。Graph IR主要实现整图级别的优化和操作,如图优化、图切分等,比较适合静态图的执行模式。由于整图级别的IR缺少相应的硬件信息,难以进行硬件相关的优化,所以在中间层次就出现了硬件相关的通用编译优化,比如XLA、Tensor RT、MindSpore的图算融合等,它们能够针对不同的硬件进行算子融合等优化,提升不同网络在特定硬件上的执行性能。 本书“编译器后端”章节的硬件通用优化中有一个小节专门介绍图算融合编译器的相关设计。 最后一个层次的IR是特定硬件加速器专有的IR,一般由硬件厂商自带的编译器提供,如Ascend硬件自带的TBE编译器就是基于TVM的Halide IR生成高效的执行算子。
多层级IR的优势是IR表达上更加地灵活,可以在不同层级的IR上进行合适的PASS优化,更加便捷和高效。 但是多层级IR也存在一些劣势。首先,多层级IR需要进行不同IR之间的转换,而IR转换要做到完全兼容是非常困难的,工程工作量很大,还可能带来信息的损失。上一层IR优化掉某些信息之后,下一层需要考虑其影响,因此IR转换对优化执行的顺序有着更强的约束。其次,多层级IR有些优化既可以在上一层IR进行,也可以在下一层IR进行,让框架开发者很难选择。最后,不同层级IR定义的算子粒度大小不同,可能会给精度带来一定的影响。为了解决这一问题,机器学习框架如MindSpore采用统一的IR设计(MindIR)。 图5.1.3展示了MindSpore的AI编译器内部的运行流程。其中,编译器前端主要指图编译和硬件无关的优化,编译器后端主要指硬件相关优化、算子选择等。
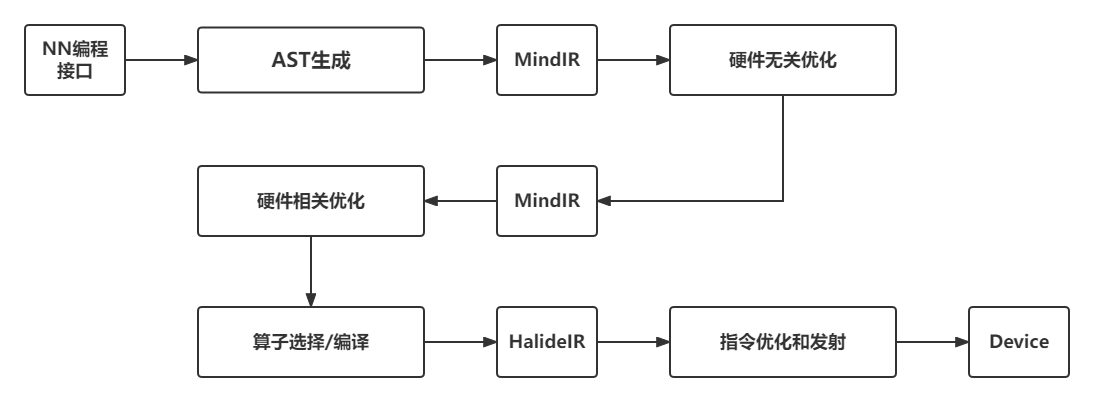
图5.1.3 MindSpore编译器处理流程
AI编译器前端技术概述
AI编译器前端技术概述
图5.2.1展示了机器学习编译器前端的基础结构。其中,对源程序的解析过程与传统编译器是大致相同的,本章节不对这部分进行更细致的讨论。机器学习框架的编译器前端的独特之处主要在于对自动微分功能的支持。为了满足自动微分功能带来的新需求,机器学习框架需要在传统中间表示的基础上设计新的中间表示结构。因此,本章节的介绍重点会放在中间表示和自动微分这两个部分,随后会简要探讨类型系统、静态分析和前端优化等编译器的基础概念。

图5.2.1 译器前端基础结构
中间表示
中间表示是编译器用于表示源代码的数据结构或代码,是程序编译过程中介于源语言和目标语言之间的程序表示。传统机器学习框架的中间表示分为三大类,分别是线性中间表示,图中间表示以及混合中间表示。然而,传统编译器的中间表示难以完全满足机器学习框架对于中间表示的一系列需求。因此,机器学习框架的开发者在传统中间表示的设计基础上不断扩展,提出了很多适用于机器学习框架的中间表示。
自动微分
自动微分(Automatic Differentiation, AD)是一种介于符号微分和数值微分之间的针对计算图进行符号解析的求导方法,用于计算函数梯度值。深度学习等现代AI算法通过使用大量数据来学习拟合出一个优化后带参模型,其中使用的学习算法多是基于现实数据在模型中的经验误差,通过梯度下降的方法来更新模型的参数。因此,自动微分在深度学习中处于非常重要的地位,是整个训练算法的核心组件之一。自动微分通常在编译器前端优化中实现,通过对中间表示的符号解析来生成带有梯度函数的中间表示。
类型系统与静态分析
为了有效减少程序在运行时可能出现的错误,编译器的前端引入了类型系统(Type System)和静态分析(Static Analysis)系统。类型系统可以防止程序在运行时发生类型错误,而静态分析能够为编译优化提供线索和信息,有效减少代码中存在的结构性错误、安全漏洞等问题。
前端编译优化
编译优化意在解决代码的低效性,无论是在传统编译器还是在机器学习框架中都起着很重要的作用。前端的编译优化与硬件无关。
中间表示
中间表示
中间表示作为编译器的核心数据结构之一,无论是在传统编译器中,还是在机器学习框架中, 都有着极其重要的地位。本章节我们会先介绍中间表示的基本概念以及传统编译器的中间表示类型。在此基础上,我们会探讨针对机器学习框架,中间表示的设计所面临的新的需求和挑战。最后,我们会介绍现有机器学习框架的中间表示的种类及其实现。
中间表示的基本概念
中间表示(IR),是编译器用于表示源代码的数据结构或代码,是程序编译过程中介于源语言和目标语言之间的程序表示。几乎所有的编译器都需要某种形式的中间表示,来对被分析、转换和优化的代码进行建模。在编译过程中,中间表示必须具备足够的表达力,在不丢失信息的情况下准确表达源代码,并且充分考虑从源代码到目标代码编译的完备性、编译优化的易用性和性能。
引入中间表示后,中间表示既能面向多个前端,表达多种源程序语言,又能对接多个后端,连接不同目标机器,如 图5.3.1所示。在此基础上,编译流程就可以在前后端直接增加更多的优化流程,这些优化流程以现有IR为输入,又以新生成的IR为输出,被称为优化器。优化器负责分析并改进中间表示,极大程度的提高了编译流程的可拓展性,也降低了优化流程对前端和后端的破坏。
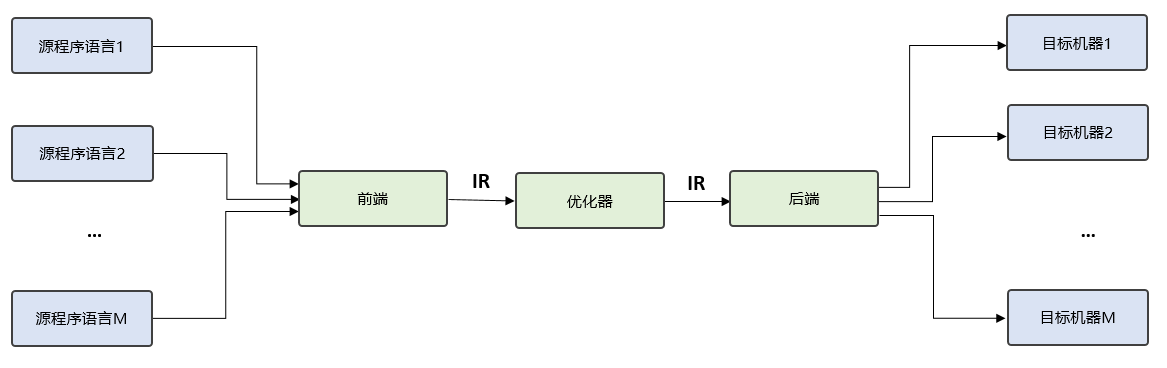
图5.3.1 中间表示
随着编译器技术的不断演进,中间表示主要经历了三个发展阶段。在早期阶段,中间表示是封闭在编译器内部的,供编译器编写者使用。在中期阶段,随着编译器的开源,中间表示逐步开源公开,主要供编译器设计者、分析工具设计者使用。现阶段,中间表示朝着软件生态构建的方向发展,旨在构建统一的中间表示。
中间表示的种类
上一节介绍了中间表示的基本概念,初步阐述了中间表示的重要作用和发展历程。接下来从组织结构的角度出发,介绍通用编译器的中间表示的类型以及各自特点 [1],如下表所示。中间表示组织结构的设计,对编译阶段的分析优化、代码生成等有着重要影响。编译器的设计需求不同,采用的中间表示组织结构也有所不同。
| 组织结构 | 特点 | 举例 |
|---|---|---|
| Linear IR | 基于线性代码 | 堆栈机代码、三地址代码 |
| Graphical IR | 基于图 | 抽象语法树、有向无环图、控制流图 |
| Hybrid IR | 基于图与线性代码混合 | LLVM IR |
1) 线性中间表示
线性中间表示类似抽象机的汇编代码,将被编译代码表示为操作的有序序列,对操作序列规定了一种清晰且实用的顺序。由于大多数处理器采用线性的汇编语言,线性中间表示广泛应用于编译器设计。
常用线性中间表示有堆栈机代码(Stack-Machine Code)和三地址代码(Three Address Code) [2] 。堆栈机代码是一种单地址代码,提供了简单紧凑的表示。堆栈机代码的指令通常只有一个操作码,其操作数存在一个栈中。大多数操作指令从栈获得操作数,并将其结果推入栈中。三地址代码,简称为3AC,模拟了现代RISC机器的指令格式。它通过一组四元组实现,每个四元组包括一个运算符和三个地址(两个操作数、一个目标)。对于表达式a-b*5,堆栈机代码和三地址代码如 图5.3.2所示。
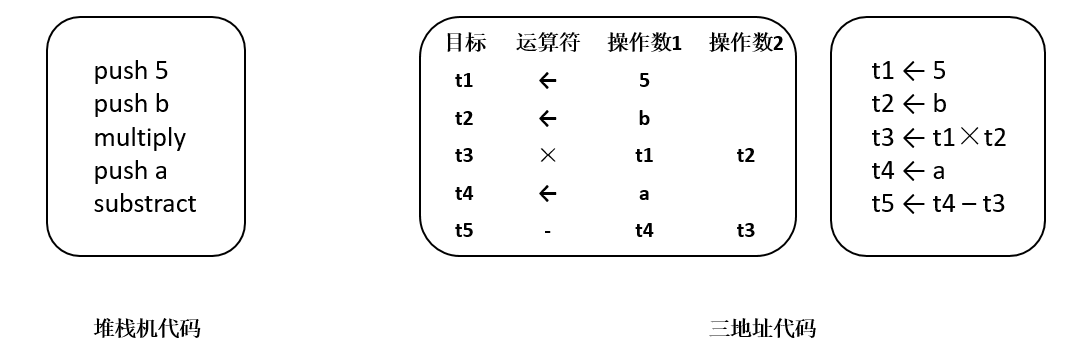
图5.3.2 堆栈机代码和三地址代码
2、图中间表示
图中间表示将编译过程的信息保存在图中,算法通过图中的对象如节点、边、列表、树等来表述。虽然所有的图中间表示都包含节点和边,但在抽象层次、图结构等方面各有不同。常见的图中间表示包括抽象语法树(Abstract Syntax Tree,AST)、有向无环图(Directed Acyclic Graph,DAG)、控制流图(Control-Flow Graph,CFG)等。
AST抽象语法树采用树型中间表示的形式,是一种接近源代码层次的表示。对于表达式\(a*5+a*5*b\),其AST表示如 图5.3.3所示。可以看到,AST形式包含\(a*5\)的两个不同副本,存在冗余。在AST的基础上,DAG提供了简化的表达形式,一个节点可以有多个父节点,相同子树可以重用。如果编译器能够证明\(a\)的值没有改变,则DAG可以重用子树,降低求值过程的代价。

图5.3.3 AST图和DAG图
3、混合中间表示
混合中间表示是线性中间表示和图中间表示的结合,这里以LLVM IR [3] 为例进行说明。LLVM(Low Level Virtual Machine)是2000年提出的开源编译器框架项目,旨在为不同的前端后端提供统一的中间表示。LLVM IR使用线性中间表示表示基本块,使用图中间表示表示这些块之间的控制流,如 图5.3.4所示。基本块中,每条指令以静态单赋值(Static Single Assignment, SSA) [4] 形式呈现,这些指令构成一个指令线性列表。SSA形式要求每个变量只赋值一次,并且每个变量在使用之前定义。控制流图中,每个节点为一个基本块,基本块之间通过边实现控制转移。
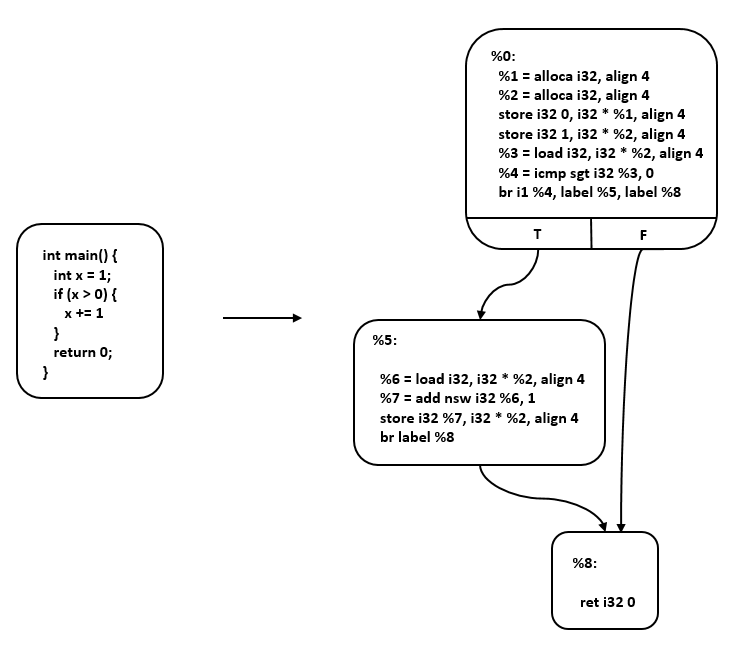
图5.3.4 LLVM IR
机器学习框架的中间表示
上一节介绍了中间表示的类型,并举例说明了常见的中间表示形式。传统中间表示如LLVM IR,能够很好地满足通用编译器的基本功能需求,包括类型系统、控制流和数据流分析等。然而,它们偏向机器语言,难以满足机器学习框架编译器的中间表示的需求。
在设计机器学习框架的中间表示时,需要充分考虑以下因素:
1) 张量表达。机器学习框架主要处理张量数据,因此正确处理张量数据类型是机器学习框架中间表示的基本要求。
2) 自动微分。自动微分是指对网络模型的自动求导,通过梯度指导对网络权重的优化。主流机器学习框架都提供了自动微分的功能,在设计中间表示时需要考虑自动微分实现的简洁性、性能以及高阶微分的扩展能力。
3) 计算图模式。主流机器学习框架如TensorFlow、PyTorch、MindSpore等都提供了静态图和动态图两种计算图模式,静态计算图模式先创建定义计算图,再显式执行,有利于对计算图进行优化,高效但不灵活。动态计算图模式则是每使用一个算子后,该算子会在计算图中立即执行得到结果,使用灵活、便于调试,但运行速度较低。机器学习框架的中间表示设计同时支持静态图和动态图,可以针对待解决的任务需求,选择合适的模式构建算法模型。
4) 支持高阶函数和闭包 [5]。高阶函数和闭包是函数式编程的重要特性,高阶函数是指使用其它函数作为参数、或者返回一个函数作为结果的函数,闭包是指代码块和作用域环境的结合,可以在另一个作用域中调用一个函数的内部函数,并访问到该函数作用域中的成员。支持高阶函数和闭包,可以抽象通用问题、减少重复代码、提升框架表达的灵活性和简洁性。
5) 编译优化。机器学习框架的编译优化主要包括硬件无关的优化、硬件相关的优化、部署推理相关的优化等,这些优化都依赖于中间表示的实现。
6) JIT(Just In Time)能力。机器学习框架进行编译执行加速时,经常用到JIT即时编译。JIT编译优化将会对中间表示中的数据流图的可优化部分实施优化,包括循环展开、融合、内联等。中间表示设计是否合理,将会影响机器学习框架的JIT编译性能和程序的运行能力。
针对上述需求,机器学习框架的开发者在传统中间表示的设计基础上不断扩展,提出了很多适用于机器学习框架的中间表示。接下来介绍一些主流机器学习框架的中间表示。
1、PyTorch
PyTorch框架是一个基于动态计算图机制的机器学习框架,以Python优先,具有很强的易用性和灵活性,方便用户编写和调试网络代码。为了保存和加载网络模型,PyTorch框架提供了TorchScript方法,用于创建可序列化和可优化模型。TorchScript IR作为PyTorch模型的中间表示,通过JIT即时编译的形式,将Python代码转换成目标模型文件。任何TorchScript程序都可以在Python进程中保存,并加载到没有Python依赖的进程中。
PyTorch框架采用命令式编程方式,其TorchScript IR以基于SSA的线性IR为基本组成形式,并通过JIT即时编译的Tracing和Scripting两种方法将Python代码转换成TorchScript IR。如下Python代码使用了Scripting方法并打印其对应的中间表示图:
import torch
@torch.jit.script
def test_func(input):
rv = 10.0
for i in range(5):
rv = rv + input
rv = rv/2
return rv
print(test_func.graph)
该中间表示图的结构为:
graph(%input.1 : Tensor):
%9 : int = prim::Constant[value=1]()
%5 : bool = prim::Constant[value=1]() # test.py:6:1
%rv.1 : float = prim::Constant[value=10.]() # test.py:5:6
%2 : int = prim::Constant[value=5]() # test.py:6:16
%14 : int = prim::Constant[value=2]() # test.py:8:10
%rv : float = prim::Loop(%2, %5, %rv.1) # test.py:6:1
block0(%i : int, %rv.9 : float):
%rv.3 : Tensor = aten::add(%input.1, %rv.9, %9) # <string>:5:9
%12 : float = aten::FloatImplicit(%rv.3) # test.py:7:2
%rv.6 : float = aten::div(%12, %14) # test.py:8:7
-> (%5, %rv.6)
return (%rv)
TorchScript是PyTorch的JIT实现,支持使用Python训练模型,然后通过JIT转换为语言无关的模块,从而提升模型部署能力,提高编译性能。同时,TorchScript IR显著改善了Pytorch框架的模型可视化效果。
2、Jax
Jax机器学习框架同时支持静态图和动态图,其中间表示采用Jaxpr(JAX Program Representation) IR。Jaxpr IR是一种强类型、纯函数的中间表示,其输入、输出都带有类型信息,函数输出只依赖输入,不依赖全局变量。
Jaxpr IR的表达采用ANF(A-norm Form)函数式表达形式,ANF文法如下所示:
<aexp> ::= NUMBER | STRING | VAR | BOOLEAN | PRIMOP
| (lambda (VAR ...) <exp>)
<cexp> ::= (<aexp> <aexp> ...)
| (if <aexp> <exp> <exp>)
<exp> ::= (let ([VAR <cexp>]) <exp>) | <cexp> | <aexp>
ANF形式将表达式划分为两类:原子表达式(aexp)和复合表达式(cexp)。原子表达式用于表示常数、变量、原语、匿名函数,复合表达式由多个原子表达式组成,可看作一个匿名函数或原语函数调用,组合的第一个输入是调用的函数,其余输入是调用的参数。如下代码打印了一个函数对应的JaxPr:
from jax import make_jaxpr
import jax.numpy as jnp
def test_func(x, y):
ret = x + jnp.sin(y) * 3
return jnp.sum(ret)
print(make_jaxpr(test_func)(jnp.zeros(8), jnp.ones(8)))
其对应的JaxPr为:
{ lambda ; a:f32[8] b:f32[8]. let
c:f32[8] = sin b
d:f32[8] = mul c 3.0
e:f32[8] = add a d
f:f32[] = reduce_sum[axes=(0,)] e
in (f,) }
Jax框架结合了Autograd 和 JIT,基于Jaxpr IR,支持循环、分支、递归、闭包函数求导以及三阶求导,并且支持自动微分的反向传播和前向传播。
3、TensorFlow
TensorFlow框架同时支持静态图和动态图,是一个基于数据流编程的机器学习框架,使用数据流图作为数据结构进行各种数值计算。TensorFlow机器学习框架的静态图机制更为人所熟知。在静态图机制中,运行TensorFlow的程序会经历一系列的抽象以及分析,程序会逐步从高层的中间表示向底层的中间表示进行转换,我们把这种变换成为lowering。
为了适配不同的硬件平台,基于静态计算图,TensorFlow采用了多种IR设计,其编译生态系统如 图5.3.5所示。蓝色部分是基于图的中间表示,绿色部分是基于SSA的中间表示。在中间表示的转换过程中,各个层级的中间表示各自为政,无法互相有效地沟通信息,也不清楚其他层级的中间表示做了哪些优化,因此每个中间表示只能尽力将当前的优化做到最好,造成了很多优化在每个层级的中间表示中重复进行, 从而导致优化效率的低下。尤其是从图中间表示到SSA中间表示的变化过大,转换开销极大。此外,各个层级的相同优化的代码无法复用,也降低了开发效率。
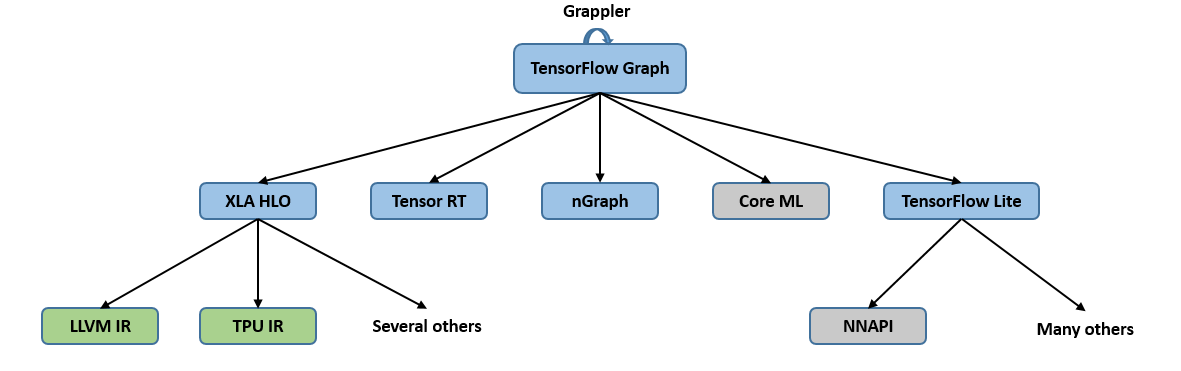
图5.3.5 TensorFlow
4、MLIR
针对这个问题,TensorFlow团队提出了MLIR(Multi-Level Intermediate Represent,多级中间表示) [1]。MLIR不是一种具体的中间表示定义,而是为中间表示提供一个统一的抽象表达和概念。 开发者可以使用MLIR开发的一系列基础设施,来定义符合自己需求的中间表示, 因此我们可以把MLIR理解为“编译器的编译器”。MLIR不局限于TensorFlow框架, 还可以用于构建连接其他语言与后端(如LLVM)的中间表示。 MLIR深受LLVM设计理念的影响,但与LLVM不同的是, MLIR是一个更开放的生态系统。 在MLIR中, 没有预设的操作与抽象类型, 这使得开发者可以更自由地定义中间表示,并更有针对性地解决其领域的问题。MLIR通过Dialect的概念来支持这种可拓展性, Dialect在特定的命名空间下为抽象提供了分组机制,分别为每种中间表示定义对应的产生式并绑定相应的Operation, 从而生成一个MLIR类型的中间表示。Operation是MLIR中抽象和计算的核心单元,其具有特定的语意,可以用于表示LLVM中所有核心的IR结构, 例如指令, 函数以及模块等。 如下就是一个MLIR定义下的Operation:
%tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
- % tensor: Operation定义的结果的名字, \(%\)是为了避免冲突统一加入的。一个Operation可以定义0或者多个结果,它们是SSA值。
- “toy.transpose”: Operation的名字。它是一个唯一的字符串,其中Dialect为Toy。因此它可以理解为Toy Dialect 中的transpose Operation。
- (%tensor):输入操作数(或参数)的列表,它们是由其它操作定义或引用块参数的 SSA 值。
- {inplace = true}:零个或多个属性的字典,这些属性是始终为常量的特殊操作数。在这里,我们定义了一个名为“inplace”的布尔属性,它的常量值为 true。
- (tensor<2x3xf64>)->tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。尖括号内代表输入与输出的数据类型以及形状, 例如\(<2x3xf64>\)代表一个形状位2X3, 数据类型为float64的张量。
- loc(“example/file/path”:12:1):此操作的源代码中的位置。
由于各层中间表示都遵循如上的样式进行定义,所以各个层级的中间表示之间可以更加方便的进行转换, 提高了中间表示转换的效率。各个不同层级的中间表示还可以协同进行优化。 此外,由于中间表示之间不再相互独立, 各层级的优化不必做到极致,而是可以将优化放到最适合的层级。 其他的中间表示只需要先转换为该层级的中间表示,就可以进行相关的优化,提高了优化的效率与开发效率。TensorFlow从图中间表示到SSA中间表示的转换也可以通过使用MLIR来进行多层转换, 使转换更加平滑, 降低了转化的难度。 针对MLIR的更多内容将会在第六章进行介绍。
5、MindSpore
与PyTorch、Jax、TensorFlow框架相同,MindSpore机器学习框架同时支持静态图和动态图。MindSpore框架采用的是一种基于图表示的函数式中间表示,即MindIR,全称MindSpore IR。MindIR没有采用多层中间表示的结构,而是通过统一的中间表示,定义了网络的逻辑结构和算子的属性,能够消除不同后端的模型差异,连接不同的目标机器。
MindIR最核心的目的是服务于自动微分变换,而自动微分采用的是基于函数式编程框架的变换方法,因此MindIR采用了接近于ANF函数式的语义。MindIR具有以下特点:
(1)基于图的(Graph based)。与TensorFlow类似,程序使用图来表示,使其容易去做优化。但跟TensorFlow不一样的是,在MindSpore中,函数是“一等公民“。函数可以被递归调用,也可以被当做参数传到其他的函数中,或者从其他函数中返回,使得MindSpore可以表达一系列的控制流结构。
(2)纯函数的(Purely functional)。
纯函数是指函数的结果只依赖函数的参数。若函数依赖或影响外部的状态,比如,函数会修改外部全局变量,或者函数的结果依赖全局变量的值,则称函数具有副作用 [6]。若使用了带有副作用的函数,代码的执行顺序必须得到严格的保证,否则可能会得到错误的结果,比如对全局变量的先写后读变成了先读后写。同时,副作用的存在也会影响自动微分,因为反向部分需要从前向部分获取中间变量,需要确保该中间变量的正确。因此需要保证自动微分的函数是纯函数。
由于Python语言具有高度动态性的特点,纯函数式编程对用户使用上有一些编程限制。有些机器学习框架的自动微分功能只支持对纯函数求导,且要求用户自行保证这一点。如果用户代码中写了带有副作用的函数,那么求导的结果可能会不符合预期。MindIR支持副作用的表达,能够将副作用的表达转换为纯函数的表达,从而在保持ANF函数式语义不变的同时,确保执行顺序的正确性,从而实现自由度更高的自动微分。
(3)支持闭包表示的(Closure representation)。反向模式的自动微分,需要存储基本操作的中间结果到闭包中,然后再去进行组合连接。所以有一个自然的闭包表示尤为重要。闭包是指代码块和作用域环境的结合,在MindIR中,代码块是以函数图呈现的,而作用域环境可以理解为该函数被调用时的上下文环境。
(4)强类型的(Strongly typed)。每个节点需要有一个具体的类型,这个对于性能最大化很重要。在机器学习应用中,因为算子可能很耗费时间,所以越早捕获错误越好。因为需要支持函数调用和高阶函数,相比于TensorFlow的数据流图,MindIR的类型和形状推导更加复杂且强大。
在结合MindSpore框架的自身特点后,MindIR的定义如 图5.3.6所示。
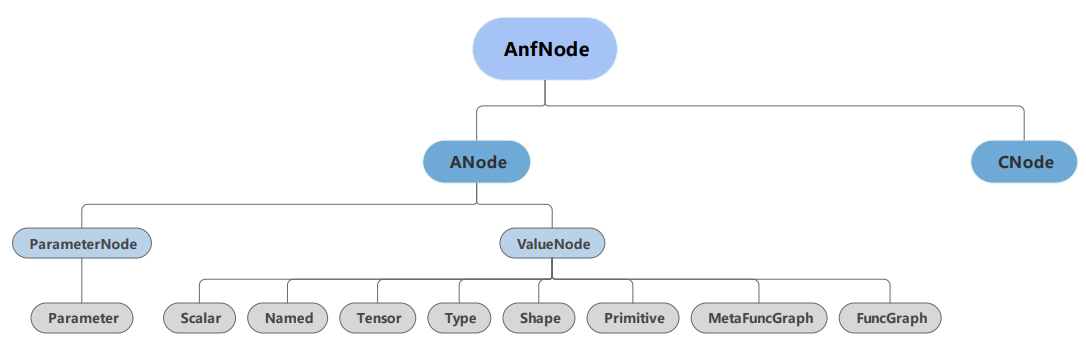
图5.3.6 MindIR文法。MindIR中的ANode对应于ANF的原子表达式,ValueNode用于表示常数值,ParameterNode用于表示函数的形参,CNode则对应于ANF的复合表达式,表示函数调用
接下来我们通过如下的一段程序作为示例,来进一步分析MindIR。
def func(x, y):
return x / y
@ms_function
def test_f(x, y):
a = x - 1
b = a + y
c = b * func(a, b)
return c
该函数对应的ANF表达式为:
lambda (x, y)
let a = x - 1 in
let b = a + y in
let func = lambda (x, y)
let ret = x / y in
ret end in
let %1 = func(a, b) in
let c = b * %1 in
c end
在ANF中,每个表达式都用let表达式绑定为一个变量,通过对变量的引用来表示对表达式输出的依赖,而在MindIR中,每个表达式都绑定为一个节点,通过节点与节点之间的有向边表示依赖关系。该函数对应的MindIR的可视化表示如 图5.3.7所示。
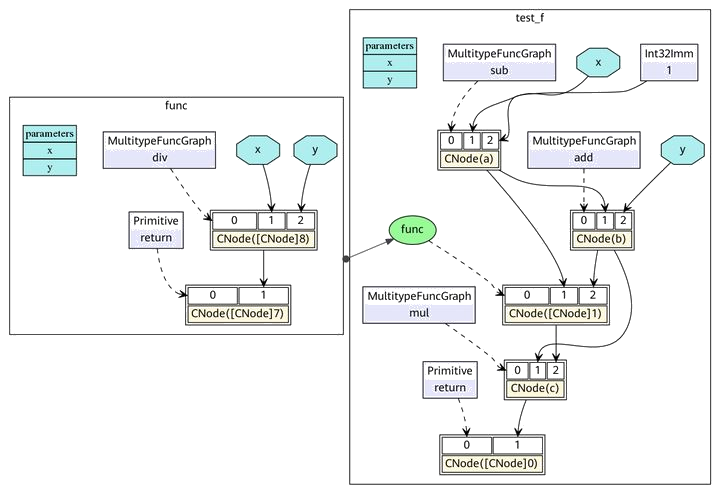
图5.3.7 MindIR的函数图表示
MindIR同时支持静态计算图和动态计算图的构建方式,更好地兼顾了灵活性与高性能。相比传统计算图,MindIR不仅可以表达算子之间的数据依赖,还可以表达丰富的函数式语义,具备更自然的自动微分实现方式。MindIR原生支持闭包,并且支持高阶函数的表达。在处理控制流时,MindIR将控制流转换为高阶函数的数据流,不仅支持数据流的自动微分,还支持条件跳转、循环和递归等控制流的自动微分,从而提升MindSpore的自动微分能力。
在JIT即时编译方面,MindIR采用了基于图表示的形式,将控制流和数据流合一,支持更高效的JIT优化。在编译优化方面,MindIR引入优化器对计算图进行优化,采用前端-优化器-后端的三段式表达形式,支持硬件无关的优化(如类型推导、表达式化简等)、硬件相关的优化(如自动并行、内存优化、图算融合、流水线执行等)以及部署推理相关的优化(如量化、剪枝等),显著提升了MindSpore的编译执行能力。
参考文献
- Lattner, C. and Amini, M. and Bondhugula, U. and Cohen, A. and Davis, A. and Pienaar, J. and Riddle, R. and Shpeisman, T. and Vasilache, N. and Zinenko, O.. MLIR: A Compiler Infrastructure for the End of Moore's Law. 2020. ↩
- Aho, A. V. and Lam, M. S. and Ullman, J. D. and Sethi, R.. Compilers: Principles, Techniques, and Tools (Rental), 2nd Edition. 2007. ↩
- Lattner, C. and Adve, V.. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. Code Generation and Optimization, 2004. CGO 2004. International Symposium on. 2004. ↩
- Richard and A. and Kelsey. A correspondence between continuation passing style and static single assignment form. Acm Sigplan Notices. 1995. ↩
- Jaervi, Jaakko and Freeman, J.. C++ lambda expressions and closures. Science of Computer Programming. 2010. ↩
- Spuler, David A and Sajeev, A Sayed Muhammed. Compiler detection of function call side effects. Informatica. 1994. ↩
自动微分
自动微分
上一节,我们介绍了机器学习框架的中间表示,设计这些中间表示的最核心的目的之一便是服务于自动微分变换。那么什么是自动微分?我们在这一节来详细介绍。
自动微分的基本概念
自动微分(Automatic Differentiation,AD)是一种对计算机程序进行高效且准确求导的技术,在上个世纪六七十年代就已经被广泛应用于流体力学、天文学、数学金融等领域 [1]。时至今日,自动微分的实现及其理论仍然是一个活跃的研究领域。随着近些年深度学习在越来越多的机器学习任务上取得领先成果,自动微分被广泛的应用于机器学习领域。许多机器学习模型使用的优化算法都需要获取模型的导数,因此自动微分技术成为了一些热门的机器学习框架(例如TensorFlow和PyTorch)的核心特性。
常见的计算机程序求导的方法可以归纳为以下四种 [2]:手工微分(Manual Differentiation)、数值微分(Numerical Differentiation)、符号微分(Symbolic Differentiation)和自动微分(Automatic Differentiation)。
(1)手工微分:需手工求解函数导数的表达式,并在程序运行时根据输入的数值直接计算结果。手工微分需根据函数的变化重新推导表达式,工作量大且容易出错。
(2)数值微分 [3]:数值微分通过差分近似方法完成,其本质是根据导数的定义推导而来。
\[f^{’}(x)=\lim_{h \to 0}\frac{f(x+h)-f(x)}{h}\]
当\(h\)充分小时,可以用差分\(\frac{f(x+h)-f(x)}{h}\)来近似导数结果。而近似的一部分误差,称为截断误差(Truncation error)。理论上,数值微分中的截断误差与步长\(h\)有关,\(h\)越小则截断误差越小,近似程度越高。但实际情况下数值微分的精确度并不会随着\(h\)的减小而一直减小。这是因为计算机系统对于浮点数运算的精度有限导致另外一种误差的存在,这种误差称为舍入误差(Round-off Error)。舍入误差会随着\(h\)变小而逐渐增大。当h较大时,截断误差占主导。而当h较小时,舍入误差占主导。 在截断误差和舍入误差的共同作用下,数值微分的精度将会在某一个\(h\)值处达到最小值,并不会无限的减小。因此,虽然数值微分容易实现,但是存在精度误差问题。
(3)符号微分 [4]:利用计算机程序自动地通过如下的数学规则对函数表达式进行递归变换来完成求导。 \[\frac{d}{dx}(f(x)+g(x))\rightsquigarrow\frac{d}{dx}f(x)+\frac{d}{dx}g(x)\]
\[\frac{d}{dx}(f(x)g(x))\rightsquigarrow(\frac{d}{dx}f(x))g(x)+f(x)(\frac{d}{dx}g(x))\] 符号微分常被应用于现代代数系统工具中,例如Mathematica、Maxima和Maple,以及机器学习框架,如Theano。符号微分虽然消除了手工微分硬编码的缺陷。但因为对表达式进行严格的递归变换和展开,不复用产生的变换结果,很容易产生表达式膨胀(expression swell [5] )问题。如 图5.4.1 所示,用符号微分计算递归表达式\(l_{n+1}=4l_n(1-l_n)\),\(l_1=x\)的导数表达式,其结果随着迭代次数增加快速膨胀。

图5.4.1 符号微分的表达式膨胀问题
并且符号微分需要表达式被定义成闭合式的(closed-form),不能带有或者严格限制控制流的语句表达,使用符号微分会很大程度上地限制了机器学习框架网络的设计与表达。
(4)自动微分 [6]:自动微分的思想是将计算机程序中的运算操作分解为一个有限的基本操作集合,且集合中基本操作的求导规则均为已知,在完成每一个基本操作的求导后,使用链式法则将结果组合得到整体程序的求导结果。自动微分是一种介于数值微分和符号微分之间的求导方法,结合了数值微分和符号微分的思想。相比于数值微分,自动微分可以精确地计算函数的导数;相比符号微分,自动微分将程序分解为基本表达式的组合,仅对基本表达式应用符号微分规则,并复用每一个基本表达式的求导结果,从而避免了符号微分中的表达式膨胀问题。而且自动微分可以处理分支、循环和递归等控制流语句。目前的深度学习框架基本都采用自动微分机制进行求导运算,下面我们将重点介绍自动微分机制以及自动微分的实现。
前向与反向自动微分
自动微分根据链式法则的不同组合顺序,可以分为前向模式(Forward Mode)和反向模式(Reverse Mode)。对于一个复合函数\(y=a(b(c(x)))\),其梯度值\(\frac{dy}{dx}\)的计算公式为: \[\frac{dy}{dx}=\frac{dy}{da}\frac{da}{db}\frac{db}{dc}\frac{dc}{dx}\] 前向模式的自动微分是从输入方向开始计算梯度值的,其计算公式为: \[\frac{dy}{dx}=(\frac{dy}{da}(\frac{da}{db}(\frac{db}{dc}\frac{dc}{dx})))\] 反向模式的自动微分是从输出方向开始计算梯度值的,其计算公式为: \[\frac{dy}{dx}=(((\frac{dy}{da}\frac{da}{db})\frac{db}{dc})\frac{dc}{dx})\] 我们以下面的函数为例介绍两种模式的计算方式,我们希望计算函数在\((x_1, x_2)=(2,5)\)处的导数\(\frac{\partial y}{\partial x_1}\): \[y=f(x_1,x_2)=ln(x_1)+{x_1}{x_2}-sin(x_2)\]
该函数对应的计算图如 图5.4.2:

图5.4.2 示例计算图
(1)前向模式

图5.4.3 前向模式自动微分示例
前向模式的计算过程如 图5.4.3所示,左侧是源程序分解后得到的基本操作集合,右侧展示了运用链式法则和已知的求导规则,从上至下计算每一个中间变量\({\dot{v}_i}=\frac{\partial v_i}{\partial x_1}\),从而计算出最后的变量\({\dot{v}_5}=\frac{\partial y}{\partial x_1}\)。
当我们想要对一个函数求导时,我们想要得到的是该函数的任意一个输出对任意一个输入的偏微分的集合。对于一个带有\(n\)个独立输入\(x_i\)和\(m\)个独立输出\(y_i\)的函数\(f:{\mathbf{R}^n}\to \mathbf{R}^m\),该函数的求导结果可以构成如下的雅克比矩阵(Jacobian Matrix): \[\mathbf{J}_{f}= \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n} \end{bmatrix}\]
前向模式中每次计算函数\(f\)的所有输出对某一个输入的偏微分,也就是雅克比矩阵的某一列,如下面的向量所示。因此,通过n次前向模式的自动微分就可以得到整个雅克比矩阵。 \[\begin{bmatrix} \frac{\partial y_1}{\partial x_i} \\ \vdots \\ \frac{\partial y_m}{\partial x_i} \end{bmatrix}\]
前向模式通过计算雅克比向量积(Jacobian-vector products)的方式来计算这一列的结果。我们初始化\(\dot{\mathbf{x}}=\mathbf{r}\)。基本操作的求导规则是已经定义好的,代表着基本操作的雅可比矩阵是已知量。在此基础上,我们应用链式法则从\(f\)的输入到输出传播求导结果,从而得到输入网络的雅克比矩阵中的一列。 \[\mathbf{J}_{f}\mathbf{r}= \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n} \end{bmatrix} \begin{bmatrix} r_1 \\ \vdots \\ r_n \end{bmatrix}\]
(2)反向模式

图5.4.4 反向模式自动微分示例
反向模式的计算过程如上 图5.4.4所示,左侧是源程序分解后得到的基本操作集合,右侧展示了运用链式法则和已知的求导规则,从\(\bar{v}_5=\bar{y}=\frac{\partial y}{\partial y}=1\)开始, 由下至上地计算每一个中间变量\({\bar{v}_i}=\frac{\partial y_j}{\partial v_i}\),从而计算出最后的变量\({\bar{x}_1}=\frac{\partial y}{\partial x_1}\)和\({\bar{x}_2}=\frac{\partial y}{\partial x_2}\)。
反向模式每次计算的是函数\(f\)的某一个输出对任一输入的偏微分,也就是雅克比矩阵的某一行,如下面的向量所示。因此通过运行m次反向模式自动微分,我们就可以得到整个雅克比矩阵。 \[\begin{bmatrix} \frac{\partial y_j}{\partial x_1} & \cdots & \frac{\partial y_j}{\partial x_n} \end{bmatrix}\]
类似地,我们可以通过计算向量雅克比积(Vector-jacobian products)的方式来计算雅克比矩阵的一行。我们初始化\(\bar{\mathbf{y}}=\mathbf{r}\),在已知基本操作的求导规则的前提下,应用链式法则从\(f\)的输出到输入传播求导结果,从而最后得到雅克比矩阵中的一行。 \[\mathbf{r}^{T}\mathbf{J}_{f}= \begin{bmatrix} r_1 & \cdots & r_m \end{bmatrix} \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n} \end{bmatrix}\]
在求解函数\(f\)的雅克比矩阵时,前向模式的迭代次数与雅克比矩阵的列数相关,而反向模式的迭代次数则与雅克比矩阵的行数相关。因此,在函数输出个数远远大于输入个数时\((f:{\mathbf{R}^n}\to \mathbf{R}^m, n << m)\),前向模式效率更高;反之,在函数输入个数远远大于输出个数时\((f:{\mathbf{R}^n}\to \mathbf{R}^m, n >> m)\),反向模式效率更高。在极端情况下的函数\(f:{\mathbf{R}^n}\to \mathbf{R}\),只需要应用一次反向模式就已经能够把所有输出对输入的导数\((\frac{\partial y}{\partial x_1},\cdots,\frac{\partial y}{\partial x_n})\)都计算出来,而前向模式则需要执行n次。这种计算一个标量值的输出关于大量参数输入的梯度的场景恰好是机器学习实践中最常见的一种计算场景,这使得反向模式的自动微分成为反向传播算法使用的核心技术之一。
但是反向模式也存在一定的缺陷。在源程序分解为一系列基本操作后,前向模式由于求导顺序与基本操作的执行顺序一致,输入值可以在执行基本操作的过程中同步获得。而在反向模式中,由于求导顺序与源程序的执行顺序是相反的,计算过程需要分为两个阶段,第一个阶段先执行源程序,且将源程序的中间结果保存起来,在第二阶段才把中间结果取出来去计算导数。因此反向模式会有额外的内存消耗。业界也一直在研究反向模式的内存占用优化方法,例如检查点策略(checkpointing strategies)和数据流分析(data-flow analysis) [7][8] 。
自动微分的实现
上一节我们介绍了自动微分的基本概念,可以总结为将程序分解为一系列微分规则已知的基本操作,然后运用链式法则将它们的微分结果组合起来得到程序的微分结果。而在机器学习的应用中,因为输入的数量远远大于输出的数量,所以反向模式的自动微分更受青睐。虽然自动微分的基本思想是明确的,但是具体的实现方法也分为几类 [2] ,大体可以划分为基本表达式法(Elemental Libraries)、操作符重载法(Operator Overloading,OO)和代码变换法(Source Code Transformation,ST)。
(1)基本表达式法:封装大多数的基本表达式及对应的微分表达式,通过库函数的方式提供给用户,用户在写代码时,需要手工分解程序为一系列的基本表达式,然后使用这些库函数去替换这些基本表达式。以程序\(a=(x+y)/z\)为例,用户需要手工地把这个程序分解为:
t = x + y
a = t / z
然后使用自动微分的库函数去替换分解出来的基本表达式:
// 参数为变量x, y, t和对应的导数变量dx, dy, dt
call ADAdd(x, dx, y, dy, t, dt)
// 参数为变量t, z, a和对应的导数变量dt, dz, da
call ADDiv(t, dt, z, dz, a, da)
库函数ADAdd和ADDiv运用链式法则,分别定义了Add和Div的微分表达式。
def ADAdd(x, dx, y, dy, z, dz):
z = x + y
dz = dy + dx
def ADDiv(x, dx, y, dy, z, dz):
z = x / y
dz = dx / y + (x / (y * y)) * dy
基本表达式法的优缺点显而易见,优点是实现简单直接,可为任意语言快速实现微分的库函数;而缺点是增加了用户的工作量,用户必须先手工分解程序为一些基本表达式,才能使用这些库函数进行编程,无法方便地使用语言原生的表达式。
(2)操作符重载法(Operator Overloading, OO):依赖于现代编程语言的多态特性,使用操作符重载对编程语言中的基本操作语义进行重定义,封装其微分规则。每个基本操作类型及其输入关系,在程序运行时会被记录在一个所谓的“tape“的数据结构里面,最后,这些“tape“会形成一个跟踪轨迹(trace),我们就可以使用链式法则沿着轨迹正向或者反向地将基本操作组成起来进行微分。以自动微分库AutoDiff为例,对编程语言的基本运算操作符进行了重载:
namespace AutoDiff
{
public abstract class Term
{
// 重载操作符 `+`,`*` 和 `/`,调用这些操作符时,会通过其中的
// TermBuilder 将操作的类型、输入输出信息等记录至 tape 中
public static Term operator+(Term left, Term right)
{
return TermBuilder.Sum(left, right);
}
public static Term operator*(Term left, Term right)
{
return TermBuilder.Product(left, right);
}
public static Term operator/(Term numerator, Term denominator)
{
return TermBuilder.Product(numerator, TermBuilder.Power(denominator, -1));
}
}
// Tape 数据结构中的基本元素,主要包含:
// 1) 操作的运算结果
// 2) 操作的运算结果对应的导数结果
// 3) 操作的输入
// 除此外还通过函数 Eval 和 Diff 定义了该运算操作的计算规则和微分规则
internal abstract class TapeElement
{
public double Value;
public double Adjoint;
public InputEdges Inputs;
public abstract void Eval();
public abstract void Diff();
}
}
OO对程序的运行跟踪经过了函数调用和控制流,因此实现起来也是简单直接。而缺点是需要在程序运行时进行跟踪,特别在反向模式上还需要沿着轨迹反向地执行微分,所以会造成性能上的损耗,尤其对于本来运行就很快的基本操作。并且因为其运行时跟踪程序的特性,该方法不允许在运行前做编译时刻的图优化,控制流也需要根据运行时的信息来展开。Pytorch的自动微分框架使用了该方法。
(3)代码变换法(Source Transformation,ST):提供对编程语言的扩展,分析程序的源码或抽象语法树(AST),将程序自动地分解为一系列可微分的基本操作,而这些基本操作的微分规则已预定义好,最后使用链式法则对基本操作的微分表达式进行组合生成新的程序表达来完成微分。TensorFlow,MindSpore等机器学习框架都采用了该方式。
不同于OO在编程语言内部操作,ST需要语法分析器(parser)和操作中间表示的工具。除此以外,ST需要定义对函数调用和控制流语句(如循环和条件等)的转换规则。其优势在于对每一个程序,自动微分的转换只做一次,因此不会造成运行时的额外性能损耗。而且,因为整个微分程序在编译时就能获得,编译器可以对微分程序进行进一步的编译优化。但ST实现起来更加复杂,需要扩展语言的预处理器、编译器或解释器,且需要支持更多的数据类型和操作,需要更强的类型检查系统。另外,虽然ST不需要在运行时做自动微分的转换,但是对于反向模式,在反向部分执行时,仍然需要确保前向执行的一部分中间变量可以被获取到,有两种方式可以解决该问题 [9] :
(1)基于Tape的方式。该方式使用一个全局的“tape“去确保中间变量可以被获取到。原始函数被扩展为在前向部分执行时把中间变量写入到tape中的函数,在程序执行反向部分时会从tape中读取这些中间变量。除了存储中间变量外,OO中的tape还会存储执行的操作类型。然而因为tape是一个在运行时构造的数据结构,所以需要添加一些定制化的编译器优化方法。且为了支持高阶微分,对于tape的读写都需要是可微分的。而大多数基于tape的工具都没有实现对tape的读写操作的微分,因此它们都不支持多次嵌套执行反向模式的自动微分(reverse-over-reverse)。机器学习框架Tangent采用了该方式。
(2)基于闭包(closure)的方式。基于闭包的方式可以解决基于tape方式的缺陷。在函数式编程里,闭包可以捕获到语句的执行环境并识别到中间变量的非局部使用。因为这些它们是闭包里的自由变量,所以不需要再去定制化编译器优化方法。
MindSpore是使用基于闭包的代码变换法来实现的自动微分的。这需要一个定制的中间表示。MindIR的具体设计,在上一节中已经介绍过,这里不再赘述。
MindSpore的自动微分,使用基于闭包的代码变换法实现,转换程序根据正向部分的计算,构造了一个闭包的调用链。这些闭包包含了计算导数的代码以及从正向部分拿到的中间变量。程序中的每个函数调用,都会得到转换并且额外返回一个叫做“bprop“的函数,\(bprop\)根据给定的关于输出的导数,计算出关于输入的导数。由于每个基本操作的\(bprop\)是已知的,我们可以容易地反向构造出用户定义的整个函数的\(bprop\)。为了支持reverse-over-reverse调用去计算高阶导数,我们需要确保可以在已转换好的程序中再进行转换,这需要有处理函数自由变量(函数外定义的变量)的能力。为了达到这个目的,每个\(bprop\)除了关于原始函数输入的偏导数以外,还会返回一系列关于自由变量的偏导数,闭包里面的\(bprop\)负责把每个偏导数解开,将其分别累加贡献到各自的自由变量上。且闭包也是一种函数,可以作为其他闭包的输入。因此,MindSpore自动微分的算法设计可以总结为:
(1)应用链式求导法则,对每个函数(算子或子图)定义一个反向传播函数\(bprop: dout->(df, dinputs)\),这里\(df\)表示函数对自由变量的导数,\(dinputs\)表示函数对输入的导数。
(2)应用全微分法则,将(\(df\), \(dinputs\))累加到对应的变量上。
涉及控制流语句时,因为MindIR实现了分支、循环和闭包等操作的函数式表达,我们对这些操作应用上述法则进行组合,即可完成微分。定义运算符K求解导数,MindSpore的自动微分算法可以简单表达如下:
// func和inputs分别表示函数及其输入,dout为关于输出的梯度
v = (func, inputs)
F(v): {
(result, bprop) = K(func)(inputs)
df, dinputs = bprop(dout)
v.df += df
v.dinputs += dinputs
}
MindSpore解析器模块首先根据Python的AST生成MindIR,再经过特化模块使得中间表示中的算子可识别,然后调用自动微分模块。自动微分模块的入口函数如下所示:
function Grad {
Init();
MapObject(); // 实现Parameter/Primitive/FuncGraph/FreeVariable对象的映射
MapMorphism(); // 实现CNode的映射
Finish();
Return GetKGraph(); // 获取梯度函数计算图
}
Grad函数先通过MapObject实现图上自由变量、Parameter和ValueNode(Primitive或FuncGraph)等节点到\(fprop\)的映射。\(fprop\)是\((forward\_result, bprop)\)形式的梯度函数对象。\(forward\_result\)是前向计算图的输出节点,\(bprop\)是以\(fprop\)的闭包对象形式生成的梯度函数,它只有\(dout\)一个入参,其余的输入则是引用的\(fprop\)的输入和输出。其中对于ValueNode<Primitive>类型的\(bprop\),通过解析Python层预先注册的\(get\_bprop\)函数的得到,如下所示。对于ValueNode<FuncGraph>类型的节点,则递归求出它的梯度函数对象。
@bprop_getters.register(P.ReLU)
def get_bprop_relu(self):
"""Grad definition for `ReLU` operation."""
input_grad = G.ReluGrad()
def bprop(x, out, dout):
dx = input_grad(dout, out)
return (dx,)
return bprop
随后,MapMorphism函数从原函数的输出节点开始实现对CNode的映射,并建立起节点间的反向传播连接,实现梯度累加,最后返回原函数的梯度函数计算图。
参考文献
- Griewank, Andreas and Walther, Andrea. Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation. 2008. ↩
- Pearlmutter, B. A.. Automatic Differentiation in Machine Learning: a Survey. computer science. 2015. ↩
- Burden, R. L. and Faires, Jdd. Numerical Analysis. Journal of the Royal Statistical Society. 2015. ↩
- Grabmeier, J. and Kaltofen, E. and Weispfenning, V.. Computer Algebra Handbook: Foundations * Applications * Systems. 2003. ↩
- Corliss, George F.. Applications of Differentiation Arithmetic. Reliability in Computing: The Role of Interval Methods in Scientific Computing. 1988. ↩
- Verma, A.. An introduction to automatic differentiation. Siam Computational Differentiation Techniques Applications & Tools. 2000. ↩
- Dauvergne, B. and L Hascoët. The Data-Flow Equations of Checkpointing in Reverse Automatic Differentiation. Computational Science-iccs, International Conference, Reading, Uk, May. 2006. ↩
- Siskind, Jeffrey Mark and Pearlmutter, Barak A.. Divide-and-Conquer Checkpointing for Arbitrary Programs with No User Annotation. Optimization Methods and Software. 2017. ↩
- van Merriënboer, Bart and Breuleux, Olivier and Bergeron, Arnaud and Lamblin, Pascal. Automatic differentiation in ML: Where we are and where we should be going. 2018. ↩
类型系统和静态分析
类型系统和静态分析
上一章节介绍了自动微分的基本概念和实现方法,自动微分是机器学习框架中不可或缺的核心功能。在编译器前端的设计中,为了提高编译器的抽象能力和程序运行的正确性,有效减少程序在运行时可能出现的错误,编译器引入了类型系统和静态分析系统,接下来将对它们的基本概念、主要功能、常见系统进行介绍。
类型系统概述
程序设计语言中,类型是指数值、表达式、函数等属性内容。类型系统是指类型的集合以及使用类型来规定程序行为的规则。类型系统用于定义不同的类型,指定类型的操作和类型之间的相互作用,广泛应用于编译器、解释器和静态检查工具中。类型系统提供的主要功能有:
1)正确性。编译器的类型系统引入了类型检查技术,用于检测和避免运行时错误,确保程序运行时的安全性。通过类型推导与检查,编译器能够捕获大多数类型相关的异常报错,避免执行病态程序导致运行时错误,保证内存安全,避免类型间的无效计算和语义上的逻辑错误。
2)优化。静态类型检查可以提供有用的信息给编译器,从而使得编译器可以应用更有效的指令,节省运行时的时间。
3)抽象。在安全的前提下,一个强大的类型系统的标准是抽象能力。通过合理设计抽象,开发者可以更关注更高层次的设计。
4)可读性。阅读代码时,明确的类型声明有助于理解程序代码。
机器学习框架一般使用Python语言作为描述网络模型结构的前端语言。Python语言是一门动态强类型的语言,入门简单易学习,开发代码简洁高效,但由于其解释执行的方式,运行速度往往较慢。Python前端语言给用户带来了动态灵活的语义和高效的开发效率,但是若想要生成运行高效的后端代码,后端框架需要优化友好的静态强类型中间表示。因此,需要一种高效可靠的静态分析方法作为桥梁,将Python前端表示转换成等价的静态强类型中间表示,以此给用户同时带来高效的开发效率和运行效率,例如Hindley–Milner(HM)类型系统。这是一种具有参数多态性的简单类型lambda演算的类型系统。它最初由J. Roger Hindley 提出 [1],并由Robin Milner 进行扩展和验证 [2] 。后来,路易斯·达马斯(Luis Damas)对HM类型推导方法进行了详尽的分析和证明 [3],并将其扩展到支持具有多态引用的系统。Hindley–Milner类型系统的目标是在没有给定类型注解的情况下,自动推导出任意表达式的类型。其算法具有抽象性和通用性,采用简洁的符号表示,能够根据表达式形式推导出明确直观的定义,常用于类型推导和类型检查。因此,Hindley–Milner类型系统广泛应用于编程语言设计中,比如Haskell和Ocaml。
静态分析概述
在设计好类型系统后,编译器需要使用静态分析系统来对中间表示进行静态检查与分析。语法解析模块(parser)将程序代码解析为抽象语法树(AST)并生成中间表示。此时的中间表示缺少类型系统中定义的抽象信息,因此引入静态分析模块,对中间表示进行处理分析,并且生成一个静态强类型的中间表示,用于后续的编译优化、自动并行以及自动微分等。在编译器前端的编译过程中,静态分析可能会被执行多次,有些框架还会通过静态分析的结果判断是否终止编译优化。
静态分析模块基于抽象释义对中间表示进行类型推导、常量传播、泛型特化等操作,这些专业术语的含义分别为:
抽象释义:通过抽象解释器将语言的实际语义近似为抽象语义,只获取后续优化需要的属性,进行不确定性的解释执行。抽象值一般包括变量的类型和维度。
类型推导:在抽象释义的基础上,编译器推断出程序中变量或表达式的抽象类型,方便后续利用类型信息进行编译优化。
泛型特化:泛型特化的前提是编译器在编译期间可以进行类型推导,提供类型的上下文。在编译期间,编译器通过类型推导确定调用函数时的类型,然后,编译器会通过泛型特化,进行类型取代,为每个类型生成一个对应的函数方法。
接下来以MindSpore框架为例,简要介绍一下静态分析模块的具体实现。MindSpore采用抽象释义的方法,对抽象值做不确定的抽象语义的解释执行,函数图中每个节点的抽象值是所期望得到的程序静态信息。基本的抽象释义方法流程可以理解为,从MindIR的顶层函数图入口开始解释执行,将函数图中所有节点进行拓扑排序,根据节点的语义递归推导各节点的抽象值。当遇到函数子图时,递归进入函数子图进行解释执行,最后返回顶层函数输出节点的抽象值。根据抽象释义方法流程,MindSpore的静态分析模块主要分为抽象域模块、缓存模块、语义推导模块和控制流处理模块。
图5.5.1 静态分析模块
参考文献
- Hindley, R.. The Principal Type-Scheme of an Object in Combinatory Logic. Transactions of the American Mathematical Society. 1969. ↩
- Milner, R.. A theory of type polymorphism in programming. Journal of Computer and System Sciences. 1978. ↩
- Damas, L. and Milner, R.. Principal Type Schemes for Functional Programming Languages. 1982. ↩
常见前端编译优化方法
常见前端编译优化方法
和传统编译器相同,机器学习编译器也会进行编译优化。编译优化意在解决编译生成的中间表示的低效性,使得代码的长度变短,编译与运行的时间减少,执行期间处理器的能耗变低。编译优化可以分为与硬件无关的优化和与硬件相关的编译优化。因为前端是不感知具体后端硬件的,因此前端执行的全部都是与硬件无关的编译优化。
前端编译优化简介
大多数编译优化器会由一系列的“趟“(Pass)来组成。每个“趟“以中间表示为输入,又以新生成的中间表示为输出。一个“趟“还可以由几个小的“趟“所组成。一个“趟“可以运行一次,也可以运行多次。
在编译优化中,优化操作的选择以及顺序对于编译的整体具有非常关键的作用。优化操作的选择决定了优化器能够感知中间表示中的哪些低效性,也决定了编译器将要如何去重写中间表示以消除这种低效性。优化操作的顺序决定了各趟操作的执行顺序。编译器可以根据具体需要运行不同的编译优化操作。也可以根据编译优化级别来调整优化的次数,种类以及顺序。

图5.6.1 编译优化的"趟"结构
常见编译优化方法介绍及实现
前端编译优化的方法有很多,机器学习框架也有很多不同于传统编译器的优化方式。在本小节当中,我们会介绍三种常见且通用的前端编译优化方法。
1. 无用与不可达代码消除
如 图5.6.2所示。无用代码是指输出结果没有被任何其他代码所使用的代码。不可达代码是指没有有效的控制流路径包含该代码。删除无用或不可达的代码可以使得中间表示更小,提高程序的编译与执行速度。无用与不可达代码一方面有可能来自于程序编写者的编写失误,也有可能是其他编译优化所产生的结果。

图5.6.2 无用代码消除
2. 常量传播、常量折叠
常量传播:如 图5.6.3所示,如果某些量为已知值的常量,那么可以在编译时刻将使用这些量的地方进行替换。
常量折叠:如 图5.6.3所示,多个量进行计算时,如果能够在编译时刻直接计算出其结果,那么变量将由常量替换。

图5.6.3 常量传播与常量折叠
3. 公共子表达式消除
如 图5.6.4所示,如果一个表达式E已经计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E就成为了公共子表达式。对于这种表达式,没有必要花时间再对它进行计算,只需要直接用前面计算过的表达式结果代替E就可以了。

图5.6.4 公共子表达式消除
总结
总结
-
中间表示是编译器的核心数据结构之一,是程序编译过程中介于源语言和目标语言之间的程序表示。
-
传统编译器的中间表示从组织结构出发,可以分为线性中间表示,图中间表示以及混合中间表示。
-
机器学习框架对中间表示有一系列新的需求,这些新的需求是传统中间表示所不能完美支持的。因此需要在传统中间表示的基础上扩展新的,更适用于机器学习框架的中间表示。
-
自动微分的基本思想是将计算机程序中的运算操作分解为一个有限的基本操作集合,且集合中基本操作的求导规则均为已知,在完成每一个基本操作的求导后,使用链式法则将结果组合得到整体程序的求导结果。
-
自动微分根据链式法则的组合顺序,可以分为前向自动微分与反向自动微分。
-
前向自动微分更适用于对输入维度小于输出维度的网络求导,反向自动微分则更适用于对输出维度小于输入维度的网络求导。
-
自动微分的实现方法大体上可以划分为基本表达式法、操作符重载法以及代码变化法。
-
类型系统是指类型的集合以及使用类型来规定程序行为的规则,用于定义不同的类型,指定类型的操作和类型之间的相互作用,广泛应用于编译器、解释器和静态检查工具中。
-
静态分析,是指在不实际运行程序的情况下,通过词法分析、语法分析、控制流、数据流分析等技术对代码进行分析验证的技术
-
编译优化意在解决编译生成的中间表示的低效性,前端执行的均为与硬件无关的编译优化。
扩展阅读
编译器后端和运行时
在上一章节,详细讲述了一个AI编译器前端的主要功能,重点介绍了中间表示以及自动微分。在得到中间表示后,如何充分利用硬件资源高效地执行,是编译器后端和运行时要解决的问题。
在本章节中, 将会介绍AI编译器后端的一些基本概念,详细描述后端的计算图优化、算子选择等流程。通过对编译器前端提供的中间表示进行优化,充分发挥硬件能力,从而提高程序的执行效率。在此基础上,介绍运行时是如何对计算任务进行内存分配以及高效地调度执行。
本章的学习目标包括:
-
了解编译器后端和运行时的作用
-
掌握计算图优化的常用方法
-
掌握算子选择的常用方法
-
掌握内存分配的常用方法
-
掌握计算图调度和执行的常用方法
-
了解目前算子编译器的基本特点以及其尚未收敛的几个问题
概述
概述
编译器前端主要将用户代码进行解析翻译得到计算图IR,并对其进行设备信息无关的优化,此时的优化并不考虑程序执行的底层硬件信息。编译器后端的主要职责是对前端下发的IR做进一步的计算图优化,让其更加贴合硬件,并为IR中的计算节点选择在硬件上执行的算子,然后为每个算子的输入输出分配硬件内存,最终生成一个可以在硬件上执行的任务序列。
如 图6.1.1所示,编译器后端处于前端和硬件驱动层中间,主要负责计算图优化、算子选择和内存分配的任务。首先,需要根据硬件设备的特性将IR图进行等价图变换,以便在硬件上能够找到对应的执行算子,该过程是计算图优化的重要步骤之一。前端IR是通过解析用户代码生成的,属于一个较高的抽象层次,隐藏一些底层运行的细节信息,此时无法直接对应硬件上的算子(算子是设备上的基本计算序列,例如MatMul、Convolution、ReLU等),需要将细节信息进行展开后,才能映射到目标硬件上的算子。对于某些前端IR的子集来说,一个算子便能够执行对应的功能,此时可以将这些IR节点合并成为一个计算节点,该过程称之为算子融合;对于一些复杂计算,后端并没有直接与之对应的算子,但是可以通过几个基本运算的算子组合达到同样的计算效果,此时可以将前端IR节点拆分成多个小算子。在完成计算图优化之后,就要进行算子选择过程,为每个计算节点选择执行算子。算子选择是在得到优化的IR图后选取最合适的目标设备算子的过程。针对用户代码所产生的IR往往可以映射成多种不同的硬件算子,但是这些不同硬件算子的执行效率往往有很大差别,如何根据前端IR选择出最高效的算子,是算子选择的核心问题。算子选择本质上是一个模式匹配问题。其最简单的方法就是每一个IR节点对应一个目标硬件的算子,但是这种方法往往对目标硬件的资源利用比较差。现有的编译器一般都对每一个IR节点提供了多个候选的算子,算子选择目标就是从中选择最优的一个算子作为最终执行在设备上的算子。总的来说,在机器学习系统中,对前端生成的IR图上的各个节点进行拆分和融合,让前端所表示的高层次IR逐步转换为可以在硬件设备上执行的低层次IR。得到了这种更加贴合硬件的IR后,对于每个单节点的IR可能仍然有很多种不同的选择,例如可以选择不同的输入输出格式和数据类型,需要对IR图上每个节点选择出最为合适的算子,算子选择过程可以认为是针对IR图的细粒度优化过程,最终生成完整的算子序列。最后,遍历算子序列,为每个算子分配相应的输入输出内存,然后将算子加载到设备上执行计算。
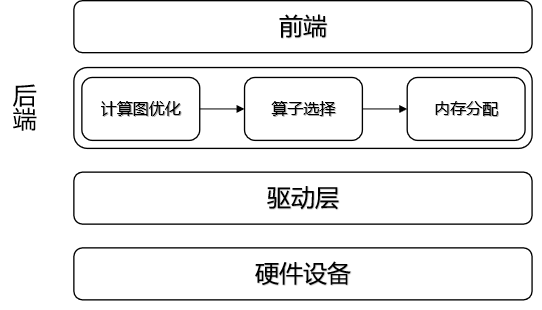
图6.1.1 编译器后端总体架构简图
计算图优化
计算图优化是在不影响模型的数值特性的基础上,通过图变换达到简化计算、减少资源开销、适配硬件的执行能力、提升执行性能的目的。
算子选择
算子选择是将IR图上的每个计算节点映射到设备上可执行算子的过程,一个IR图上的计算节点往往可以对应多个设备上的算子,这个过程中需要考虑算子的规格,算子的执行效率等问题,算子选择目标就是从中选择最优的一个算子。
内存分配
经过计算图优化和算子选择之后,我们可以得到IR图中每个算子的输入输出的形状(Shape)、数据类型、存储格式。根据这些信息,计算输入输出数据的大小,并为输入输出分配设备上的内存,然后将算子加载到设备上才能真正执行计算。此外,为了更充分地例用设备内存资源,可以对内存进行复用,提高内存利用率。
计算调度与执行
经过算子选择与内存分配之后,计算任务可以通过运行时完成计算的调度与在硬件上的执行。根据是否将算子编译为计算图,计算的调度可以分为单算子调度与计算图调度两种方式。而根据硬件提供的能力差异,计算图的执行方式又可以分为逐算子下发执行的交互式执行以及将整个计算图或者部分子图一次性下发到硬件的下沉式执行两种模式。
算子编译器
作为AI编译器中一个重要组成部分,算子编译器把单个简单或复杂的算子经过表达和优化后编译为一个单独的可执行文件。目前业界面对算子编译器仍有许多有趣的问题尚未得出明确结论,相关的处理逻辑与方法也尚未收敛。本小节希望将这些问题简单抛出,并给出业界比较典型的几种处理方式。若能对业界朋友们和同学们有所启发甚至若能对这些问题起到促进收敛的作用,那真是再好不过!目前尚待收敛的问题包括而不限于:如何通过算子编译器进行性能优化?算子编译器如何兼容不同体系结构特点的芯片?面对输入Python代码的灵活性以及神经网络训练时动态性的情况,该如何充分将这些完美表达出来?
计算图优化
计算图优化
后端的计算图优化主要是针对硬件的优化,根据优化适用于所有硬件还是只适合特定硬件,可以分为通用硬件优化和特定硬件优化,例如为了适配硬件指令限制而做的子图变换和与特定硬件无关的算子内存IO优化。
通用硬件优化
通用硬件优化主要指与特定硬件类型无关的计算图优化,优化的核心是子图的等价变换:在计算图中尝试匹配特定的子图结构,找到目标子图结构后,通过等价替换方式,将其替换成对硬件更友好的子图结构。
以优化内存IO为例。深度学习算子按其对资源的需求可以分为两类: 计算密集型算子,这些算子的时间绝大部分花在计算上,如卷积、全连接等; 访存密集型算子,这些算子的时间绝大部分花在访存上,他们大部分是Element-Wise算子,例如 ReLU、Element-Wise Sum等。 在典型的深度学习模型中,一般计算密集型和访存密集型算子是相伴出现的,最简单的例子是“Conv + ReLU”。Conv卷积算子是计算密集型,ReLU算子是访存密集型算子,ReLU算子可以直接取Conv算子的计算结果进行计算,因此可以将二者融合成一个算子来进行计算,从而减少内存访问延时和带宽压力,提高执行效率。
例如:“Conv + Conv + Sum + ReLU”的融合,从 图6.2.1中可以看到融合后的算子减少了两个内存的读和写的操作,优化了Conv的输出和Sum的输出的读和写的操作。
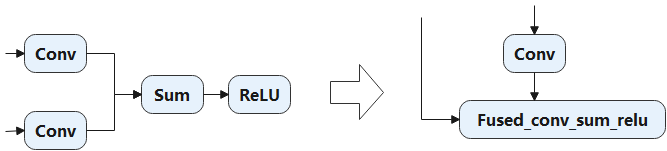
图6.2.1 Elementwise算子融合
除了上述针对特定算子类型结构的融合优化外,基于自动算子生成技术,还可以实现更灵活、更极致的通用优化。以 MindSpore 的图算融合技术为例,图算融合通过“算子拆解、算子聚合、算子重建”三个主要阶段让计算图中的计算更密集,并进一步减少低效的内存访问。
图6.2.2 图算融合
图6.2.2中,算子拆解阶段(Expander)将计算图中一些复杂算子(composite op,图中Op1、Op3、Op4)展开为计算等价的基本算子组合( 图中虚线正方形框包围着的部分);在算子聚合阶段(Aggregation),将计算图中将基本算子(basic op,如图中Op2)、拆解后的算子(expanded op)组合融合,形成一个更大范围的算子组合;在算子重建阶段(Reconstruction)中,按照输入tensor到输出tensor的仿射关系将基本算子进行分类:elemwise、 broadcast、reduce、transform等,并在这基础上归纳出不同的通用计算规则(如 elemwise + reduce 规则:elemwise + reduce在满足一定条件后可以高效执行),根据这些计算规则不断地从这个大的算子组合上进行分析、筛选,最终重新构建成新的算子(如图中虚线正方形包围的两个算子 New Op1 和 New Op2)。图算融合通过对计算图结构的拆解和聚合,可以实现跨算子边界的联合优化;并在算子重建中,通过通用的计算规则,以必要的访存作为代价,生成对硬件更友好、执行更高效的新算子。
特定硬件优化
特定硬件优化是指该计算图的优化是在特定硬件上才能做的优化,常见的基于硬件的优化包括由于硬件指令的限制而做的优化,特定硬件存储格式导致的优化等。
1、硬件指令限制
在一些特定的硬件上,IR中计算节点没有直接对应的硬件算子,只能通过子图的变换来达到子图中所有算子在对应的硬件上的存在。例如在MindSpore中,昇腾芯片上的Concat算子,只支持有限的输入个数(63个),因此当前端IR上的输入个数大于限制输入的时候,需要将该计算节点拆分成等价的多个Concat节点,如 图6.2.3所示: 当Concat有100个输入时,单个算子只支持最多63个输入,此时会将该计算节点拆分成两个Concat节点,分别为63个输入和37个输入的两个算子。
图6.2.3 Concat算子拆分
2、数据排布格式的限制
针对不同特点的计算平台和不同的算子,为了追求最好的性能,一般都需要选择不同的数据排布格式(Format),而这些排布格式可能跟框架缺省的排布格式是不一样的。在这种情况下,一般的做法是算子在执行完成后对输出插入一个格式转换操作,把排布格式转换回框架的缺省排布格式,这就引入了额外的内存操作。以 图6.2.4为例,在昇腾平台上Conv算子在输入和输出的内存排布为5HD时是性能最优的,所以可以看到Conv算子输出结果的格式是5HD,然后通过一个转换操作转回了框架缺省的NCHW,紧接着,后面又是一个Conv算子,它需要5HD的输入,所以又做了一个NCHW到5HD的转换。我们很容易看出,虚线框内的两个转换操作互为逆操作,可以相互抵消。通过对计算图的模式匹配,可以将该类型的操作消除。
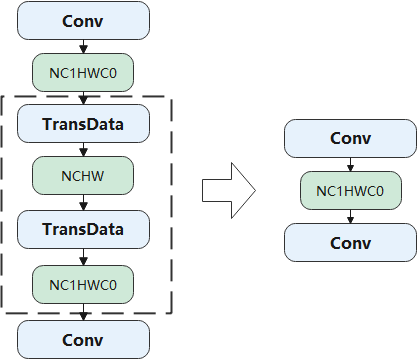
图6.2.4 数据排布格式转换消除
算子选择
算子选择
过计算图优化后,需要对IR图上的每个节点进行算子选择,才能生成真正在设备上执行的算子序列。由于IR图上的节点可能有后端的很多算子与其对应,不同规格的算子在不同的情况下执行效率各不相同,在算子选择阶段的主要任务就是如何根据IR图中的信息在众多算子中选择出最合适的一个算子去目标设备上执行。
算子选择的基础概念
经历了后端的图优化后,IR图中的每一个节点都有一组算子与之对应。此时的IR图中的每一个节点可以认为是用户可见的最小硬件执行单元,代表了用户代码的一个操作,对于这个操作还没有具体生成有关设备信息的细节描述。这些信息是算子选择所选择的内容信息,称之为算子信息。算子信息主要包括以下内容:
-
针对不同特点的计算平台和不同的算子,为了追求最好的性能,一般都需要选择不同的数据排布格式。机器学习系统常见的数据排布格式有NCHW和NHWC等。
-
对于不同的硬件支持不同的计算精度,例如float32、float16和int32等。算子选择需要在所支持各种数据类型的算子中选择出用户所设定的数据类型最为相符的算子。
数据排布格式
机器学习系统中很多运算都会转换成为矩阵的乘法,例如卷积运算。我们知道矩阵乘法\(A\times B = C\) 是以A的一行乘以B的一列求和后得到C的一个元素。以 图6.3.1为例,在 图6.3.1的上方,矩阵数据的存储是按照行优先来进行存储,虽然B在存储时是按照行存储,但是读取数据时却按照列进行读取,假如我们能把B的格式进行转换转换为列存储,例如 图6.3.1下方所示,这样就可以通过访问连续内存的方式加快数据访问速度进而提升运算速度。由此可见不同的数据排布方式对性能有很大影响。
图6.3.1 矩阵乘法数据排布示意图
在机器学习系统中常见的数据格式一般有两种,分别为NCHW类型和NHWC类型。其中N代表了数据输入的批大小,C代表了图像的通道,H和W分别代表图像输入的高和宽。图6.3.2展示了BatchSize为2,通道数16和大小为5*4的数据逻辑示意图。
图6.3.2 常见数据格式
但是计算机的存储并不能够直接将这样的矩阵放到内存中,需要将其展平成1维后存储,这样就涉及逻辑上的索引如何映射成为内存中的索引,即如何根据逻辑数据索引来映射到内存中的1维数据索引。
对于NCHW的数据是先取W轴方向数据,再取H轴方向数据,再取C轴方向,最后取N轴方向。其中物理存储与逻辑存储的之间的映射关系为
\[offsetnchw(n,c,h,w) = n*CHW + c*HW + h*W +w\]
如 图6.3.3所示,这种格式中,是按照最低维度W轴方向进行展开,W轴相邻的元素在内存排布中同样是相邻的。如果需要取下一个图片上的相同位置的元素,就必须跳过整个图像的尺寸 \(C*H*W\)。比如有8张32*32的RGB图像,此时\(N=8,C=3,H=32,W=32\)。在内存中存储它们需要先按照W轴方向进行展开,然后按照H轴排列,这样之后便完成了一个通道的处理,之后按照同样的方式处理下一个通道。处理完全部通道后,处理下一张图片。PyTorch和MindSpore框架默认使用NCHW格式。
图6.3.3 RGB图片下的NHWC数据格式
类似的NHWC数据格式是先取C方向数据,再取W方向,然后是H方向,最后取N方向。NHWC是Tensorflow默认的数据格式。这种格式在PyTorch中称为Channel-Last。
\[offsetnhwc(n,h,w,c) = n*HWC + h*WC + w*C +c\]
图6.3.4展示了不同数据格式下逻辑排布到内存物理侧数据排布的映射。[x:1]代表从最内侧维度到最下一维度的索引变换。比如[a:1]表示当前行W轴结束后,下一个H轴排布。[b:1]表示最内侧C轴排布完成后进行按照W轴进行排列。
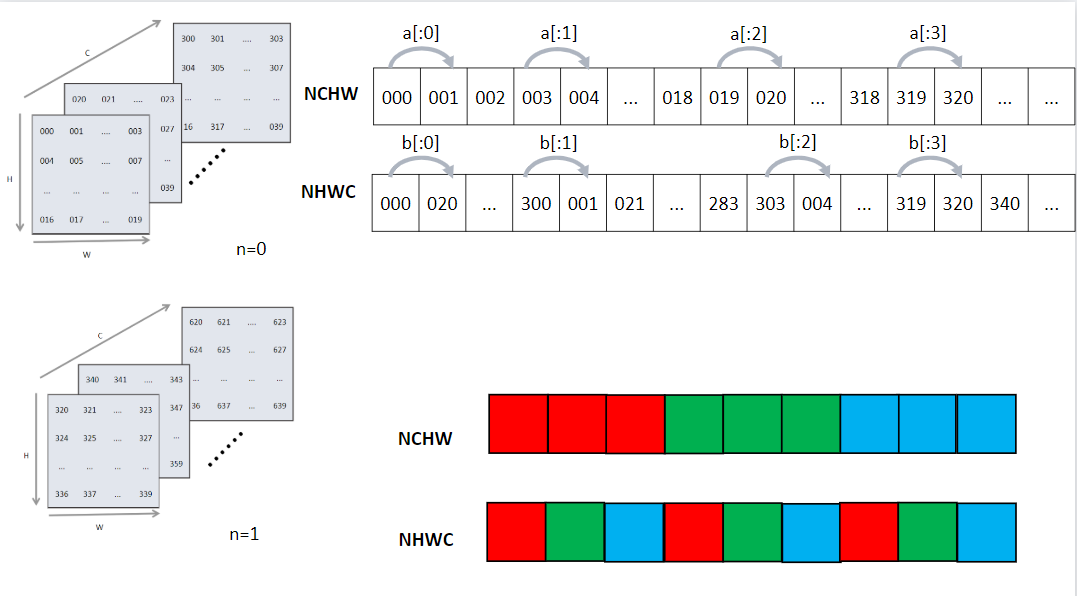
图6.3.4 NCHW与NHWC数据存储格式
上述的数据存储格式具有很大的灵活性,很多框架都采用上述的两种格式作为默认的数据排布格式。但是在硬件上对数据操作时,此时的数据排布可能还不是最优的。在机器学习系统中,用户输入的数据往往会远远大于计算部件一次性计算所能容纳的最大范围,所以此时必须将输入的数据进行切片分批送到运算部件中进行运算。为了加速运算很多框架又引入了一些块布局格式来进行进一步的优化,这种优化可以使用一些硬件的加速指令,对数据进行搬移和运算。比如oneDNN上的nChw16c 和nChw8c 格式,以及Ascend芯片的5HD等格式。这种特殊的数据格式与硬件更为贴合,可以快速的将矩阵向量化,并且极大的利用片内缓存。
数据精度
通常深度学习的系统,使用的是单精度(float32)表示。这种数据类型占用32位内存。还有一种精度较低的数据类型为半精度(float16),其内部占用了16位的内存。由于很多硬件会对半精度数据类型进行优化,半精度的计算吞吐量可以是单精度的\(2\sim 8\)倍,且半精度占用的内存更小,这样可以输入更大的批大小(BatchSize),进而减少总体训练时间。接下来详细看一下半精度浮点数与精度浮点数的区别。

图6.3.5 浮点数的二进制表示
如 图6.3.5中Sig代表符号位,占1位,表示了机器数的正负,Exponent表示指数位,Mantissa为尾数位。其中float16类型的数据采用二进制的科学计数法转换为十进制的计算方式如式\[(-1)^{sign}\times 2^{exponent-15}\times (\frac{mantissa}{1024}+1)\]所示。 其中如果指数位全为0时,且尾数位全为0时表示数字0。 如果指数位全为0,尾数位不全为0则表示一个非常小的数值。 当指数全为1,尾数位全为0表示根据符号位正无穷大,或者负无穷大。 若指数全为1,但是尾数位不为0,则表示NAN。 其中bfloat16并不属于一个通用的数据类型,是Google提出的一种特殊的类型,现在一般只在一些TPU上训练使用,其指数位数与float32位数保持一致,可以较快的与float32进行数据转换。由于bfloat16并不是一种通用类型,IEEE中也并没有提出该类型的标准。
算子信息库
前面讲述了数据格式和数据精度的概念,基于这两个概念,在不同硬件下会有不同的算子支持,一个硬件上支持的所有算子的集合定义为该硬件的算子信息库。算子选择过程就是从算子信息库中选择最合适算子的过程。
算子选择的过程
前文介绍了算子选择主要是针对IR图中的每一个操作节点选择出最为合适的算子。其中算子信息主要包括了支持设备类型、数据类型和数据排布格式三个方面。经过编译器前端类型推导与静态分析的阶段后,IR图中已经推导出了用户代码侧的数据类型。下面介绍算子选择的基本过程。
如图 :numref:select_kernel所示,展示了算子选择过程。首先,选择算子执行的硬件设备。不同的硬件设备上,算子的实现、支持数据类型、执行效率通常会有所差别。这一步往往是用户自己指定的,若用户未指定,则编译器后端会为用户匹配一个默认的设备。
然后,后端会根据IR图中推导出的数据类型和内存排布格式选择对应的算子。
图6.3.6 算子选择过程
理想情况下算子选择所选择出的算子类型,应该与用户预期的类型保持一致。但是由于软硬件的限制,很可能算子的数据类型不能满足用户所期待的数据类型,此时需要对该节点进行升精度或者降精度处理才能匹配到合适的算子。比如在MindSpore 的Ascend后端由于硬件限制导致Conv2D算子只存在float16一种数据类型。如果用户设置的整网使用的数据类型为float32数据,那么只能对Conv2D算子的输入数据进行降精度处理,即将输入数据类型从float32转换成float16。
算子的数据排布格式转换是一个比较耗时的操作,为了避免频繁的格式转换所带来的内存搬运开销,数据应该尽可能地以同样的格式在算子之间传递,算子和算子的衔接要尽可能少的出现数据排布格式不一致的现象。另外,数据类型不同导致的降精度可能会使得误差变大,收敛速度变慢甚至不收敛,所以数据类型的选择也要结合具体算子分析。
总的来说,一个好的算子选择算法应该尽可能的保持数据类型与用户设置的数据类型一致,且尽可能少的出现数据格式转换。
内存分配
内存分配
内存在传统计算机存储器层次结构中有着重要的地位,它是连接高速缓存和磁盘之间的桥梁,有着比高速缓存更大的空间,比磁盘更快的访问速度。随着深度学习的发展,深度神经网络的模型越来越复杂,AI芯片上的内存很可能无法容纳一个大型网络模型。因此,对内存进行复用是一个重要的优化手段。此外,通过连续内存分配和 In-Place内存分配还可以提高某些算子的执行效率。
Device内存概念
在深度学习体系结构中,通常将与硬件加速器(如GPU、AI芯片等)相邻的内存称之为设备(Device)内存,而与CPU相邻的内存称之为主机(Host)内存。如 图6.4.1所示,CPU可以合法地访问主机上的内存,而无法直接访问设备上的内存;同理,AI芯片可以访问设备上的内存,却无法访问主机上的内存。因此,在网络训练过程中,往往需要从磁盘加载数据到主机内存中,然后在主机内存中做数据处理,再从主机内存拷贝到设备内存中,最后设备才能合法地访问数据。算子全部计算完成后,用户要获取训练结果,又需要把数据从设备内存拷贝到主机内存中。
图6.4.1 主机内存和设备内存
内存分配
内存分配模块主要负责给图中算子的输入、输出分配Device内存。用户的前端脚本经过编译器前端处理后得到中间表达,后端根据中间表达进行算子选择和相关优化,可以得到算子最终的输入输出张量的形状、数据类型(Data Type)、格式(Format)等信息,根据这些信息可以计算出算子输入、输出张量的尺寸大小。基本的计算方法如式\[size=\left (\prod_{i=0}^{dimension}shape_i\right ) * sizeof\left ( data type \right )\]所示。得到张量的尺寸大小后,往往还需要对内存大小进行对齐操作。内存通常以4字节、8字节或16字节为一组进行访问,如果被搬运的内存大小不是这些值的倍数,内存后面会填充相应数量的空数据以使得内存长度达到这些值的倍数。因此,访问非对齐的内存可能会更加耗时。
图6.4.2 内存分配示例
下面以 图6.4.2为例介绍内存分配的大致流程。首先给输入张量、Conv2D的权重和Conv2D的输出分配内存地址。然后为BatchNorm的输入分配地址时,发现BatchNorm的输入就是Conv2D算子的输出,而该张量的地址已经在之前分配过了,因此只需要将Conv2D算子的输出地址共享给BatchNorm的输入,就可以避免内存的重复申请以及内存的冗余拷贝。以此类推,可以发现整个过程中可以将待分配的内存分成三种类型:一是整张图的输入张量,二是算子的权重或者属性,三是算子的输出张量,三种类型在训练过程中的生命周期有所不同。
在CPU上常常使用malloc函数直接申请内存,这种方式申请内存好处是随时申请随时释放,简单易用。然而在许多对性能要求严苛的计算场景中,由于所申请内存块的大小不定,频繁申请释放会降低性能。通常会使用内存池的方式去管理内存,先申请一定数量的内存块留作备用,当程序有内存申请需求时,直接从内存池中的内存块中申请。当程序释放该内存块时,内存池会进行回收并用作后续程序内存申请时使用。 在深度学习框架中,设备内存的申请也是非常频繁的,往往也是通过内存池的方式去管理设备内存,并让设备内存的生命周期与张量的生命周期保持一致。不同的深度学习框架在内存池的设计上大同小异,以图6.4.3的MindSpore框架内存申请为例,进程会从设备上申请足够大的内存,然后通过双游标从两端偏移为张量分配内存。首先从申请的首地址开始进行偏移,为算子权重的张量分配内存,这部分张量生命周期较长,往往持续整个训练过程。然后从申请设备地址的末尾开始偏移,为算子的输出张量分配内存,这部分内存的生命周期较短,往往在该算子计算结束并且后续计算过程中无需再次使用该算子的输出的情况下,其生命周期就可以结束。通过这种方式,只需要从设备上申请一次足够大的内存,后续算子的内存分配都是通过指针偏移进行分配,减少了直接从设备申请内存的耗时。
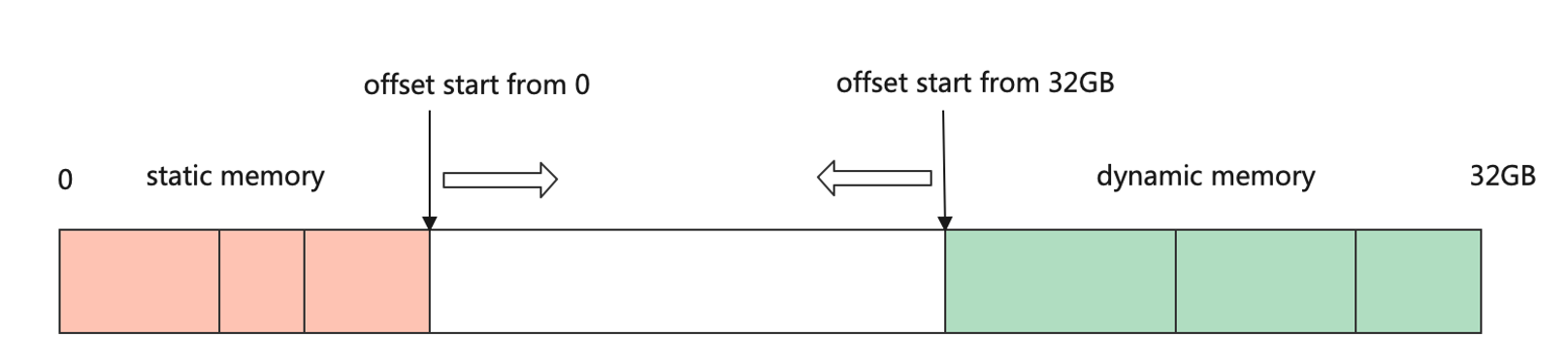
图6.4.3 双游标法分配内存
内存复用
在机器学习系统中,内存复用是指分析张量的生命周期,将生命周期结束的张量的设备内存释放回内存池并用于后续张量的内存分配。内存复用的目的是提高内存的利用率,让有限的设备内存容纳更大的模型。 以 图6.4.2为例,当BatchNorm算子计算结束后,输出1不再被任何算子使用,则该张量的设备内存可以被回收,并且如果输出1的内存尺寸大于等于输出3的内存尺寸,则从输出1回收的地址可以用于输出3的内存分配,从而达到复用输出1地址的目的。
图6.4.4 内存生命周期图
为了更好地描述内存复用问题,通过内存生命周期图来辅助理解。如 图6.4.4所示,图中横坐标表示张量的生命周期,图中纵坐标表示内存大小。在生命周期内,某一个张量将一直占用某块设备内存,直至生命周期结束才会释放相应内存块。通过张量生命周期和内存大小可以构造出矩形块,而内存分配要求解的目标是在内存生命周期图中容纳更多的矩形块,问题的约束是矩形块之间无碰撞。 图6.4.4左边是在未使用任何内存复用策略的情况下的内存生命周期图,此时内存同时只能容纳T0、T1、T2、T3四个张量。
内存复用策略的求解是一个NP完全的问题。许多深度学习框架通常采用贪心的策略去分配内存,例如采用BestFit算法,每次直接从内存池中选取可以满足条件的最小内存块,然而这种贪心的策略往往会陷入局部最优解,而无法求得全局最优解。为了更好地逼近内存分配策略全局最优解,MindSpore框架提出了一种新的内存分配算法 SOMAS(Safe Optimized Memory Allocation Solver,安全优化的内存分配求解器)。SOMAS将计算图并行流与数据依赖进行聚合分析,得到算子间祖先关系,构建张量全局生命周期互斥约束,使用多种启发式算法求解最优的内存静态规划,实现逼近理论极限的内存复用,从而提升支持的内存大小。
由 图6.4.4右边所示,经过SOMAS求解之后,同样的内存大小,可支持的Tensor数量达到了7个。
常见的内存分配优化手段
内存融合
上述内存分配的方式,都是以单个张量的维度去分配的,每个张量分配到的设备地址往往是离散的。但是对于某些特殊的算子,如AllReduce通信算子,需要为它们分配连续的内存。通信算子的执行包含通信等待、数据搬移、计算等步骤,而在大规模分布式集群的场景下,通信的耗时往往是性能瓶颈。针对这种场景,如 图6.4.5所示,可以将多个通信算子融合成一个,为通信算子的输入分配连续的内存,从而减少通信的次数。 又比如分布式训练中的神经网络权重初始化,通常将一个训练进程中的权重初始化,然后将该权重广播到其他进程中。当一个网络有较多权重的时候,需要多次进行广播。通常可以为所有权重分配连续的内存地址,然后广播一次,节省大量通信的耗时。
图6.4.5 通信算子内存融合
In-Place算子
在内存分配流程中,会为每个算子的输入和输出都分配不同的内存。然而对很多算子而言,为其分配不同的输入和输出地址,会浪费内存并且影响计算性能。例如优化器算子,其计算的目的就是更新神经网络的权重;例如Python语法中的 += 和 *= 操作符,将计算结果更新到符号左边的变量中;例如 a[0]=b 语法,将 a[0] 的值更新为 b。诸如此类计算有一个特点,都是为了更新输入的值。下面以张量的 a[0]=b 操作为例介绍In-Place的优点。 图6.4.6左边是非In-Place操作的实现,step1将张量a拷贝到张量a’,step2将张量b赋值给张量a’,step3将张量a’拷贝到张量a。 图6.4.6右边是算子In-Place操作的实现,仅用一个步骤将张量b拷贝到张量a对应的位置上。对比两种实现,可以发现In-Place操作节省了两次拷贝的耗时,并且省去了张量a’内存的申请。
图6.4.6 In-Place算子内存分配
这节简单介绍了设备内存的概念,内存分配的流程,和一些优化内存分配的方法。内存分配是编译器后端的最重要部分之一,内存的合理分配,不仅关系到相同内存容量下能否支持更大的网络模型,也关系到模型在硬件上的执行效率。
计算调度与执行
计算调度与执行
经过算子选择与内存分配之后,计算任务可以通过运行时完成计算的调度与在硬件上的执行。根据是否将算子编译为计算图,计算的调度可以分为单算子调度与计算图调度两种方式,例如在MindSpore中分别提供了PyNative模式和Graph模式。而根据硬件提供的能力差异,计算图的执行方式又可以分为逐算子下发执行的交互式执行以及将整个计算图或者部分子图一次性下发到硬件的下沉式执行两种模式。
单算子调度
单算子调度是相对于计算图而言,算法或者模型中包含的算子通过Python语言的运行时被逐个调度执行。例如PyTorch的默认执行方式,TensorFlow的eager模式,以及MindSpore的PyNative模式。以MindSpore为例,如代码所示。
import mindspore.nn as nn
from mindspore import context
class Computation(nn.Cell):
def construct(self, x, y):
m = x * y
n = x - y
print(m)
z = m + n
return z
compute = Computation()
c = compute(1, 2)
print(c)
上述脚本将所有的计算逻辑定义在Computation类的construct方法中,由于在脚本开头的context中预先设置了单算子执行模式,construct中的计算将被Python的运行时逐行调用执行,同时可以在代码中的任意位置添加print命令以便打印中间的计算结果。
单算子执行的调用链路如 图6.5.1所示,算子在Python侧被触发执行后,会经过机器学习框架初始化,其中需要确定包括算子的精度,输入与输出的类型和大小以及对应的硬件设备等信息,接着框架会为该算子分配计算所需的内存,最后交给具体的硬件计算设备完成计算的执行。
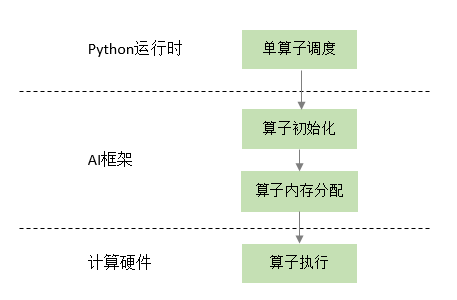
图6.5.1 单算子执行
单算子调度方式的好处在于其灵活性,由于算子直接通过Python运行时调度,一方面可以表达任意复杂的计算逻辑,尤其是在需要复杂控制流以及需要Python原生数据结构支持来实现复杂算法的场景;另一方面单算子调度对于程序正确性的调试非常便利,开发人员可以在代码执行过程中打印任意需要调试的变量;最后一点是通过Python运行时驱动算子的方式,可以在计算中与Python庞大而丰富的生态库协同完成计算任务。
计算图调度
虽然单算子调度具有如上所述的优点,其缺点也很明显。一方面是难于进行计算性能的优化,原因是由于缺乏计算图的全局信息,单算子执行时无法根据上下文完成算子融合,代数化简等优化;另一方面由于缺乏计算的拓扑关系,整个计算只能串行调度执行,即无法通过运行时完成并行计算。例如上述示例代码的计算逻辑可以表达为 图6.5.2所示。由该计算图可以看出,其中乘法和减法之间并没有依赖关系,因此这两个计算可以并行执行,而这样的并行执行信息只有将计算表达为计算图后才能完成分析,这也是计算图调度相对于单算子调度的优势之一。
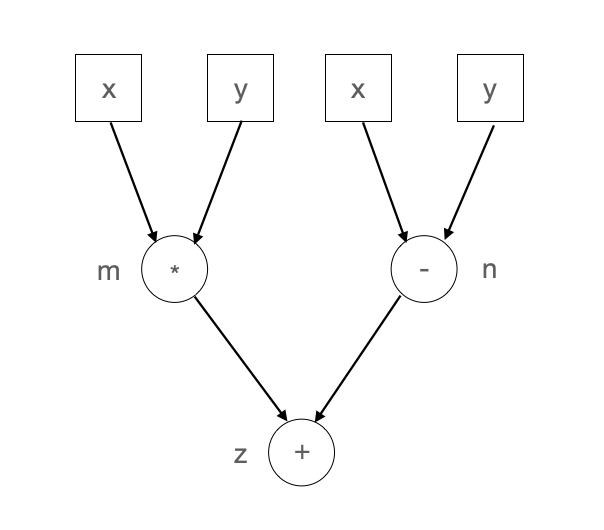
图6.5.2 计算图
下面我们开始介绍计算图的调度方式,在一个典型的异构计算环境中,主要存在CPU、GPU以及NPU等多种计算设备,因此一张计算图可以由运行在不同设备上的算子组成为异构计算图。 图6.5.3展示了一个典型的由异构硬件共同参与的计算图。
图6.5.3 异构硬件计算图
所述计算图由如下几类异构硬件对应的算子组成:
-
CPU算子:由C++语言编写实现并在主机上通过CPU执行的算子,CPU计算的性能取决于是否能够充分利用CPU多核心的计算能力。
-
GPU算子:以英伟达GPU芯片为例,通过在主机侧将GPU Kernel逐个下发到GPU设备上,由GPU芯片执行算子的计算逻辑,由于芯片上具备大量的并行执行单元,可以为高度并行的算法提供强大的加速能力。
-
NPU算子:以华为Ascend芯片为例, Ascend是一个高度集成的SoC芯片,NPU的优势是支持将部分或整个计算图下沉到芯片中完成计算,计算过程中不与Host发生交互,因此具备较高的计算性能。
-
Python算子:在执行模式上与CPU算子类似,都是由主机上的CPU执行计算,区别在于计算逻辑是由Python语言的运行时通过Python解释器解释执行。
异构计算图能够被正确表达的首要条件是准确标识算子执行所在的设备,例如异构计算图 图6.5.3中所标识的CPU、GPU和Ascend Kernel,以及被标记为被Python语言运行时执行的Python Kernel。主流框架均提供了指定算子所在运行设备的能力,以MindSpore为例,一段简单的异构计算代码如下所示。
import numpy as np
from mindspore import Tensor
import mindspore.ops.operations as ops
from mindspore.common.api import jit
# 创建算子并指定执行算子的硬件设备
add = ops.Add().add_prim_attr('primitive_target', 'CPU')
sub = ops.Sub().add_prim_attr('primitive_target', 'GPU')
# 指定按照静态计算图模式执行函数
@jit
def compute(x, y, z):
r = add(x, y)
return sub(r, z)
# 创建实参
x = Tensor(np.ones([2, 2]).astype(np.float32))
y = Tensor(np.ones([2, 2]).astype(np.float32))
z = Tensor(np.ones([2, 2]).astype(np.float32))
# 执行计算
output = compute(x, y, z)
上述代码片段完成了x + y - z的计算逻辑,其中Add算子被设置为在CPU上执行,Sub算子被设置为在GPU上执行,从而形成了CPU与GPU协同的异构计算,通过类似的标签机制,可以实现任意复杂的多硬件协同的异构计算表达。 另外一类较为特殊的异构是Python算子,Python语言的优势在于表达的灵活性和开发效率,以及丰富的周边生态,因此将Python算子引入到计算图中和其他异构硬件的算子协同计算,对计算的灵活性会产生非常大的帮助。与CPU、GPU分别执行在不同设备上的异构不同,Python算子和C++实现的CPU算子都是通过主机侧的CPU核执行,差异在于Python算子是通过统一的计算图进行描述,因此也需要在后端运行时中触发执行。为了在计算图中能够表达Python算子,框架需要提供相应的支持。
完成计算图中算子对应设备的标记以后,计算图已经准备好被调度与执行,根据硬件能力的差异,可以将异构计算图的执行分为三种模式,分别是逐算子交互式执行,整图下沉执行与子图下沉执行。交互式执行主要针对CPU和GPU的场景,计算图中的算子按照输入和输出的依赖关系被逐个调度与执行;而整图下沉执行模式主要是针对NPU芯片而言,这类芯片主要的优势是能够将整个神经网络的计算图一次性下发到设备上,无需借助主机的CPU能力而独立完成计算图中所有算子的调度与执行,减少了主机和芯片的交互次数,借助NPU的张量加速能力,提高了计算效率和性能;子图下沉执行模式是前面两种执行模式的结合,由于计算图自身表达的灵活性,对于复杂场景的计算图在NPU芯片上进行整图下沉执行的效率不一定能达到最优,因此可以将对于NPU芯片执行效率低下的部分分离出来,交给CPU或者GPU等执行效率更高的设备处理,而将部分更适合NPU计算的子图下沉到NPU进行计算,这样可以兼顾性能和灵活性两方面。
上述异构计算图可以实现两个目的,一个是异构硬件加速,将特定的计算放置到合适的硬件上执行;第二个是实现算子间的并发执行,从计算图上可以看出,kernel_1和kernel_2之间没有依赖关系,kernel_3和kernel_4之间也没有依赖关系,因此这两组CPU和GPU算子在逻辑上可以被框架并发调用,而kernel_5依赖kernel_3和kernel_4的输出作为输入,因此kernel_5需要等待kernel_3和kernel_4执行完成后再被触发执行。
虽然在计算图上可以充分表达算子间的并发关系,在实际代码中会产生由于并发而引起的一些不预期的副作用场景,例如如下代码所示:
import mindspore as ms
from mindspore import Parameter, Tensor
import mindspore.ops.operations as ops
from mindspore.common.api import jit
# 定义全局变量
x = Parameter(Tensor([1.0], ms.float32), name="x")
y = Tensor([0.2], ms.float32)
z = Tensor([0.3], ms.float32)
# 指定按照静态计算图模式执行函数
@jit
def compute(y, z):
ops.Assign()(x, y)
ops.Assign()(x, z)
r = ops.Sub()(x, y)
return r
compute(y, z)
上述代码表达了如下计算逻辑:
x = y
x = z
x = x - y
这段简单的计算逻辑翻译到计算图上可以表示为 图6.5.4所示。
图6.5.4 并发算子执行
代码中所示三行计算之间并没有依赖关系,因此这三个算子在计算图的逻辑上可以被并发执行,然而根据代码的语义,显而易见是需要确保程序能够被顺序执行,这里引入的问题被称为副作用,副作用是指修改了在函数外部定义的状态变量的行为。由于副作用的引入而导致了错误并发关系的发生,一种解决方案是在计算图编译阶段通过添加算子间的依赖,将并发执行逻辑转换为顺序执行逻辑,转换后的计算图如 图6.5.5所示。
图6.5.5 消除副作用
图中虚线箭头表达了算子之间的依赖关系,添加依赖关系后,算子会按照Assign_1、Assign_2、Sub_1的顺序串行执行,与代码原本的语义保持一致。
交互式执行
如上所述,交互式执行模式下,框架的运行时根据计算图中算子的依赖关系,按照某种执行序(例如广度优先序)逐个将算子下发到硬件上执行。为了助于理解和对比,先引入非异构计算图(计算图中的算子都是在同一类设备上)的执行方式,异构计算图的执行是基于非异构计算图基础之上的。
1、非异构计算图的执行方式
图6.5.6 非异构计算图
如 图6.5.6是一张非异构计算图,计算图上全部Kernel均为GPU算子,执行方式一般分为串行执行和并行执行:
图6.5.7 串行执行
图6.5.8 并行执行
-
串行执行:将计算图展开为执行序列,按照执行序逐个串行执行,如 图6.5.7所示。其特点为执行顺序固定,单线程执行,对系统资源要求相对较低。
-
并行执行:将计算图按照算子之间的依赖关系展开,有依赖关系的算子通过输入依赖保证执行顺序,没有依赖关系的算子则可以并行执行,如 图6.5.8所示,Kernel_1和Kernel_2没有依赖可以并行执行,Kernel_3和Kernel_4没有依赖可以并行执行。其特点为执行顺序不固定,每轮执行的算子顺序大概率不一样,多线程执行,对系统资源要求相对较高。
- 串行执行和并行执行各有优点和缺点,总结对比见 serial_vs_parallel。
-
串行执行和并行执行之对比
2、异构计算图的执行方式
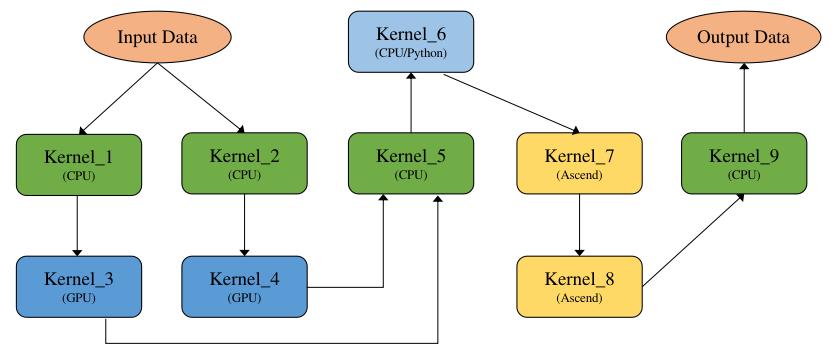
图6.5.9 异构计算图
如 图6.5.9是一张异构计算图,其中Kernel_1、Kernel_2、Kernel_5、Kernel_9为CPU算子,Kernel_6为python算子(执行也是在CPU上),Kernel_3和Kernel_4为GPU算子,Kernel_7和Kernel_8为GPU算子。 一般来说计算图的优化都是基于非异构计算图来实现的,要求计算图中的算子为同一设备上的,方便算子间的融合替换等优化操作,因此需要将一张异构计算图切分为多个非异构计算图,这里切分就比较灵活了,可以定义各种切分规则,一般按照产生尽量少的子图的切分规则来切分,尽量将多的同一设备上的算子放在一张子图中,如 图6.5.10所示,最后产生5张子图:Graph_1_CPU、Graph_2_GPU、Graph_3_CPU、Graph_4_Ascend、Graph_5_CPU。
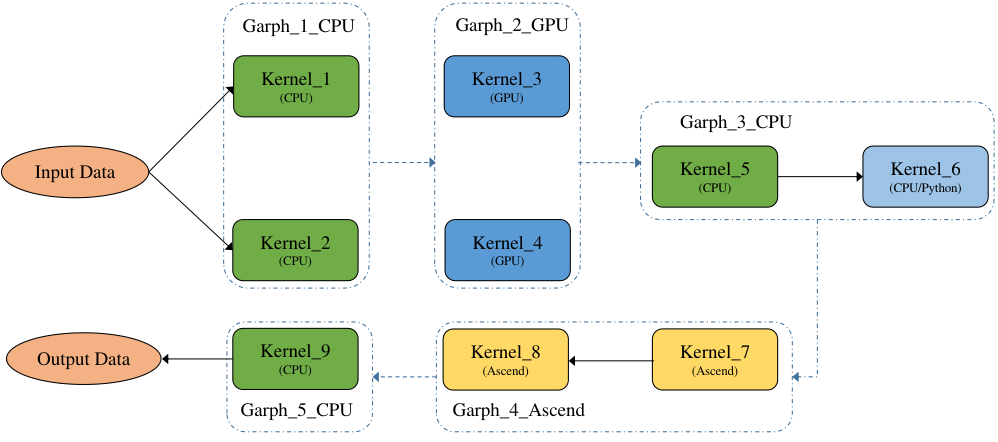
图6.5.10 异构计算图切分
将一张异构计算图切分为多个子计算图后,执行方式一般分为子图拆分执行和子图合并执行:
-
子图拆分执行:将切分后的多个子图分开执行,即一个子图执行完再执行另一个子图,如 图6.5.11所示,上一个子图的输出数据会传输给下一个子图的输入数据,并且下一个子图需要将输入数据拷贝为本图的device数据,如Graph_2_GPU需要将Graph_1_CPU的输出数据从CPU拷贝到GPU,反过来Graph_3_CPU需要将Graph2GPU的输出数据从GPU拷贝到CPU,子图之间互相切换执行有一定的开销。
-
子图合并执行:将切分后的多个子图进行合并,合并为一个整体的DAG执行,如 图6.5.12所示,通过算子的设备属性来插入拷贝算子以实现不同设备上的算子数据传输,并且拷贝算子也是进入整图中的,从而形成一个大的整图执行,减少子图之间的切换执行开销。
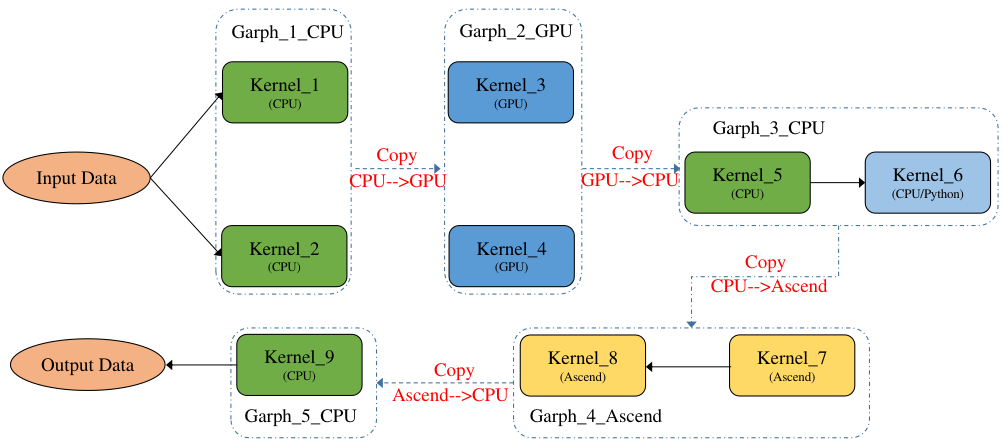
图6.5.11 子图拆分
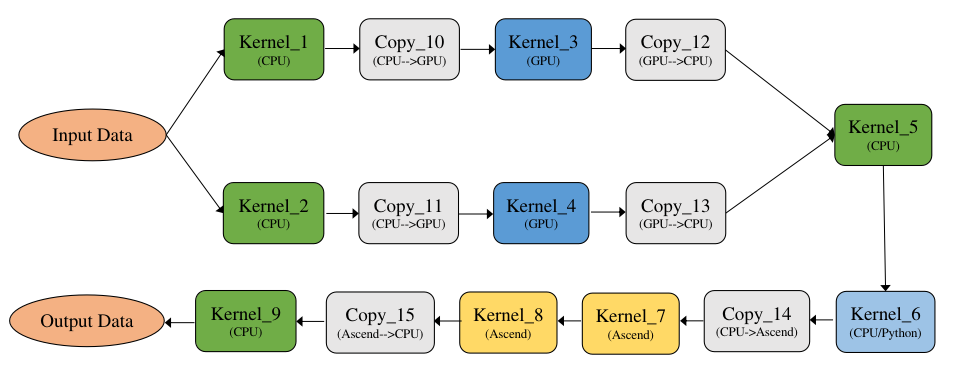
图6.5.12 子图合并
3、异构计算图的执行加速
前面讲述了非异构计算图的两种执行方式和异构计算图的两种执行方式,其中异构计算图又是在非异构计算图的基础之上,因此异构计算图按照两两组合共有四种执行方式,以MindSpore为例,采用的是子图合并并行执行,示例图如 图6.5.10所示,首先是作为一张整图来执行可以避免子图切换的执行开销,然后在整图内并行执行,可以最大粒度的发挥并发执行优势,达到最优的执行性能。
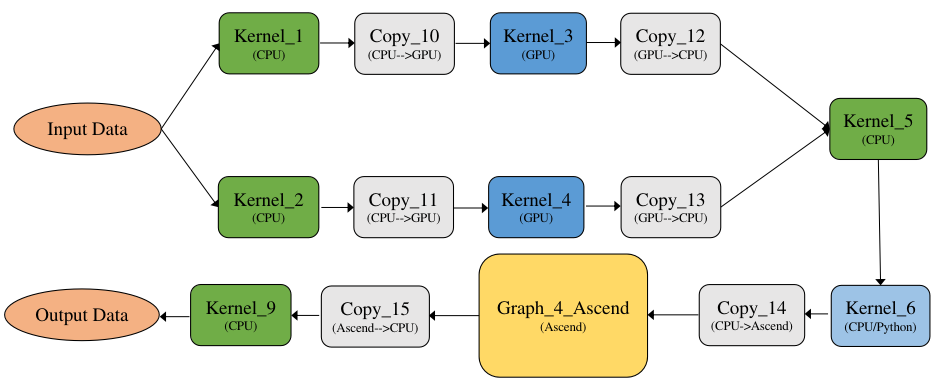
图6.5.13 异构硬件加速
下沉式执行
下沉式执行是通过专用芯片的SoC架构,将整个或部分计算图一次性调度到芯片上以完成全量数据的计算。例如对于Ascend芯片,多个Ascend算子组成的计算图可以在执行前被编译成为一个Task,通过Ascend驱动程序提供的接口,将包含多个算子的Task一次性下发到硬件上调度执行。因此上例中可以将Ascend的算子Kernel_7和Kernel_8优化为一个子图Graph_4_Ascend,再将该子图编译成为一个Task,并下沉到Ascend上执行,如 图6.5.13所示。
下沉式执行由于避免了在计算过程中主机侧和设备侧的交互,因此可以获得更好的整体计算性能。然而下沉式执行也存在一些局限,例如在动态shape算子,复杂控制流等场景下会面临较大的技术挑战。
算子编译器
算子编译器
算子编译器,顾名思义,即对算子进行编译优化的工具。这里所谓的“算子“可以来自于整个神经网络中的一部分,也可以来自于通过领域特定语言(Domain Specific Language, DSL)实现的代码。而所谓编译,通俗来说起到的是针对目标语言进行表达和转换。
从目的上来说,算子编译器致力于提高算子的执行性能。从工程实现上来说,算子编译器的输入一般为Python等动态语言描述的张量计算,而输出一般为特定AI芯片上的可执行文件。
算子调度策略
算子编译器为了实现较好地优化加速,会根据现代计算机体系结构特点,将程序运行中的每个细小操作抽象为“调度策略“。
如果不考虑优化和实际中芯片的体系结构特点,只需要按照算子表达式的计算逻辑,把输入进来的张量全部加载进计算核心里完成计算,之后再把计算结果从计算核心里面取出并保存下来即可。这里的计算逻辑指的就是基本数学运算(如加、减、乘、除)以及其他函数表达式(如卷积、转置、损失函数)等。
但是 图6.6.1向我们展示的现代计算机存储结构表明:越靠近金字塔顶尖的存储器造价越高但是访问速度越快。
图6.6.1 代计算机存储层次图
基于这一硬件设计的事实,有局部性(Locality)概念:
(1)时间局部性,相对较短时间内重复访问特定内存位置。如多次访问L1高速缓存的同一位置的效率会高于多次访问L1中不同位置的效率。
(2)空间局部性,在相对较近的存储位置进行访问。如,多次访问L1中相邻位置的效率会高于来回在L1和主存跳跃访问的效率。
满足这两者任一都会有较好的性能提升。基于局部性概念,希望尽量把需要重复处理的数据放在固定的内存位置,且这一内存位置离处理器越近越好,以通过提升访存速度而进行性能提升。
另外,把传统的串行计算任务按逻辑和数据依赖关系进行分割后,有机会得到多组互不相关的数据,并把他们同时计算,如 图6.6.2所示。
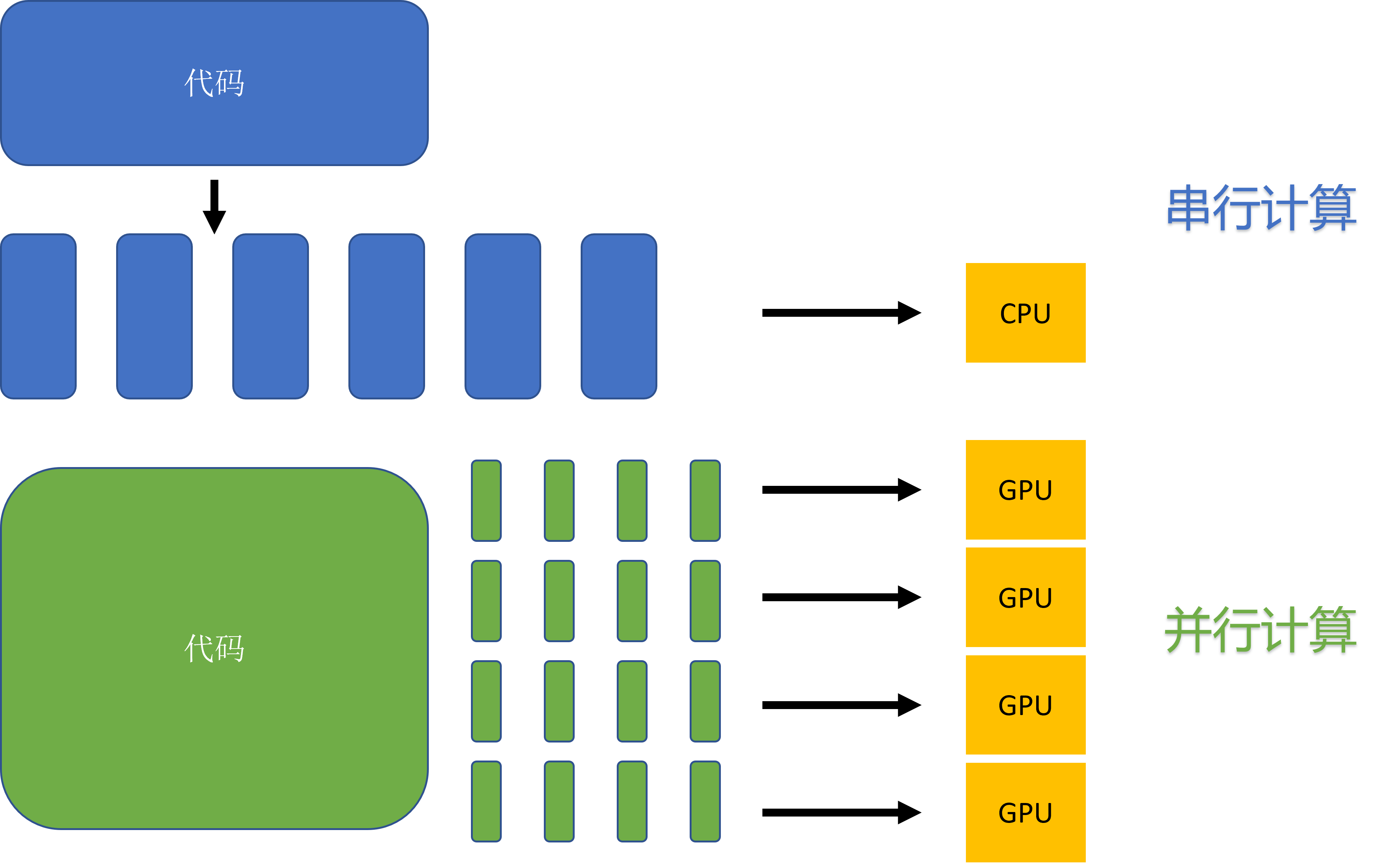
图6.6.2 串行计算和并行计算区别图
以上种种在程序实际运行的时候针对数据做出的特殊操作,统称为调度(Schedule)。调度定义了:
(1)应该在何时何处计算函数中的每个值?
(2)数据应该储存在哪里?
(3)每个值在多个消费者(Consumer)之间访存需要花费多长时间?另外在何时由每个消费者独立重新计算?这里的消费者指使用前序结构进行计算的值。
通俗理解,调度策略指的是:在编译阶段根据目标硬件体系结构的特点而设计出的一整套通过提升局部性和并行性而使得编译出的可执行文件在运行时性能最优的算法。这些算法并不会影响计算结果,只是干预计算过程,以达到提升运算速度的效果。
子策略组合优化
算子编译器的一种优化思路是:将抽象出来的调度策略进行组合,拼接排布出一个复杂而高效的调度集合。子策略组合优化,本质上还是基于人工手动模板匹配的优化方式,依赖于开发人员对于硬件架构有较深的理解。这种方式较为直接,但组合出的优化策略无法调优,同时对各类算子精细化的优化也带来较多的人力耗费。本文以TVM为例,通过在CPU上加速优化一段实际代码,简要介绍其中几种基本调度策略组成的优化算法。
我们以形式为乘累加计算的代码为例简要分析描述这一算法。该代码的核心计算逻辑为:首先对张量C进行初始化,之后将张量A与张量B相乘后,结果累加到张量C中。
for (m: int32, 0, 1024) {
for (n: int32, 0, 1024) {
C[((m*1024) + n)] = 0f32
for (k: int32, 0, 1024) {
let cse_var_2: int32 = (m*1024)
let cse_var_1: int32 = (cse_var_2 + n)
C[cse_var_1] = (C[cse_var_1] + (A[(cse_var_2 + k)]*B[((k*1024) + n)]))
}
}
}
假定数据类型为浮点型(Float),此时张量A、B、C的大小均为1024 \(\times\) 1024,三者占用的空间共为1024 \(\times\) 1024 \(\times\) 3 \(\times\) sizeof(float) = 12MB。这远远超出了常见缓存的大小(如L1 Cache为32KB)。因此按照此代码形式,要将整块张量A、B、C一起计算,只能放入离计算核更远的内存进行计算。其访存效率远低于缓存。
为了提升性能,提出使用平铺(Tile),循环移序(Reorder)和切分(Split)的调度策略。由于L1缓存大小为32KB,为了保证每次计算都能够放入缓存中,我们选取因子(Factor)为32进行平铺,使得平铺后的每次计算时只需要关注m.inner \(\times\) n.inner构成的小块(Block)即可,而其他的外层循环不会影响最内层小块的访存。其占用内存大小为32 \(\times\) 32 \(\times\) 3 \(\times\) sizeof(float) = 12KB,足够放入缓存中。以下代码展示了经过该策略优化优化后的变化。
// 由for (m: int32, 0, 1024)以32为因子平铺得到外层循环
for (m.outer: int32, 0, 32) {
// 由for (n: int32, 0, 1024)以32为因子平铺得到外层循环
for (n.outer: int32, 0, 32) {
// 由for (m: int32, 0, 1024)以32为因子平铺得到内层循环
for (m.inner.init: int32, 0, 32) {
// 由for (n: int32, 0, 1024)以32为因子平铺得到内层循环
for (n.inner.init: int32, 0, 32) {
// 对应地得到相应系数
C[((((m.outer*32768) + (m.inner.init*1024)) + (n.outer*32)) + n.inner.init)] = 0f32
}
}
// 由for (k: int32, 0, 1024)以4为因子切分得到外层循环,并进行了循环移序
for (k.outer: int32, 0, 256) {
// 由for (k: int32, 0, 1024)以4为因子切分得到外层循环,并进行了循环移序
for (k.inner: int32, 0, 4) {
// 由for (m: int32, 0, 1024)以32为因子平铺得到内层循环
for (m.inner: int32, 0, 32) {
// 由for (n: int32, 0, 1024)以32为因子平铺得到内层循环
for (n.inner: int32, 0, 32) {
// 由n轴平铺得到的外轴系数
let cse_var_3: int32 = (n.outer*32)
// 由m轴平铺得到的外轴和内轴系数
let cse_var_2: int32 = ((m.outer*32768) + (m.inner*1024))
// 由m轴和n轴得到的外轴和内轴系数
let cse_var_1: int32 = ((cse_var_2 + cse_var_3) + n.inner)
// 这里是核心计算逻辑,划分成不同层次使得每次循环计算的数据能够放入cache中
C[cse_var_1] = (C[cse_var_1] + (A[((cse_var_2 + (k.outer*4)) + n.inner)] * B[((((k.outer*4096) + (k.inner*1024)) + cse_var_3) + n.inner)]))
}
}
}
}
}
}
本示例参照TVM提供的“在CPU上优化矩阵乘运算的实例教程“中的第一项优化,读者可深入阅读后续优化内容。
调度空间算法优化
算子编译器的另外一种优化思路是:通过对调度空间搜索/求解,自动生成对应算子调度。此类方案包括多面体模型编译(Polyhedral Compilation)(基于约束对调度空间求解)和Ansor(调度空间搜索)等。这类方法的好处是提升了算子编译的泛化能力,缺点是搜索空间过程会导致编译时间过长。 以多面体模型编译技术将代码的多层循环抽象为多维空间,将每个计算实例抽象为空间中的点,实例间的依赖关系抽象为空间中的线,主要对循环进行优化。该算法的主要思想是针对输入代码的访存特点进行建模,调整循环语句中的每一个实例的执行顺序,使得新调度下的循环代码有更好的局部性和并行性。
我们以如下代码为例介绍该算法。
for (int i = 0; i < N; i++)
for (int j = 1; j < N; j++)
a[i+1][j] = a[i][j+1] - a[i][j] + a[i][j-1];
如 图6.6.3所示,通过多面体模型算法先对此代码的访存结构进行建模,然后分析实例(即 图6.6.3中节点)间的依赖关系(即 图6.6.3中箭头)。
图6.6.3 示例代码的多面体模型
再进行复杂的依赖分析和调度变换之后得到一个符合内存模型的最优解。如下代码显示了经过多面体模型优化后得到的结果。
for (int i_new = 0; i_new < N; i_new++)
for (int j_new = i+1; j_new < i+N; j_new++)
a[i_new+1][j_new-i_new] = a[i_new][j_new-i_new+1] - a[i_new][j_new-i_new] + a[i_new][j_new-i_new-1];
观察得到的代码,发现优化后的代码较为复杂。但是仅凭肉眼很难发现其性能优势之处。仍需对此优化后的代码进行如算法描述那样建模,并分析依赖关系后得出结论,如 图6.6.4所示:经过算法优化后解除了原代码中的循环间的依赖关系,从而提高了并行计算的机会。即沿着 图6.6.4中虚线方向分割并以绿色块划分后,可以实现并行计算。 该算法较为复杂,限于篇幅,在这里不再详细展开。读者可移步到笔者专门为此例写的文章-《深度学习编译之多面体模型编译——以优化简单的两层循环代码为例》详读。
图6.6.4 多面体模型优化结果
芯片指令集适配
前文讲述了算子编译器的优化方法,本小节将阐述算子编译器适配不同芯片上指令集的情况。一般意义上来说,通用编译器的设计会尽量适配多种后端。如此一来,在面临不同体系结构特点和不同编程模型的多种后端时,算子编译器承受了相当大的压力。
当下的AI芯片中,常见的编程模型分为:单指令多数据(Single Instruction, Multiple Data, SIMD),即单条指令一次性处理大量数据,如 图6.6.5所示;单指令多线程(Single Instruction, Multiple Threads, SIMT),即单条指令一次性处理多个线程的数据,如 图6.6.6所示。前者对应的是带有向量计算指令的芯片;后者对应的是带有明显的线程分级的芯片。另外,也有一些芯片开始结合这两种编程模型的特点,既有类似线程并行计算的概念,又有向量指令的支持。针对不同的编程模型,算子编译器在进行优化(如向量化等)时的策略也会有所不同。
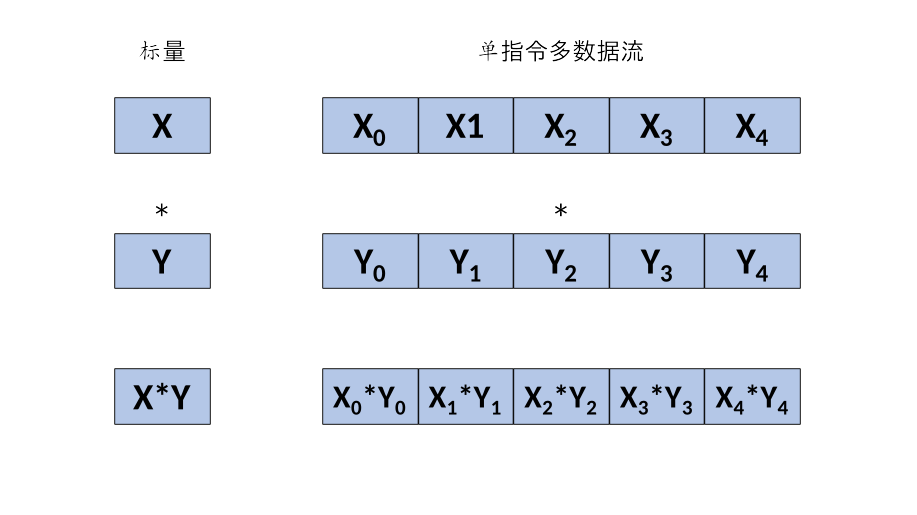
图6.6.5 单指令多数据流示意图
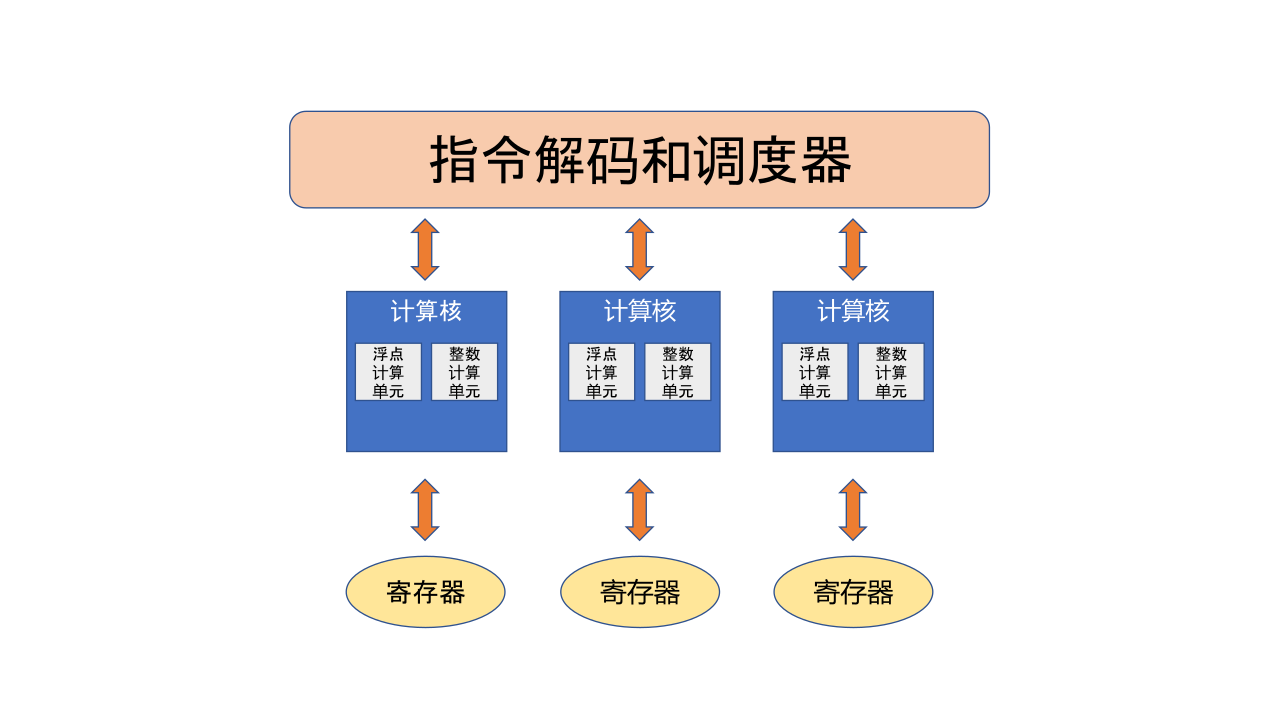
图6.6.6 单指令多线程示意图
一般来说,算子编译器在具体的代码中会按照:前端、中端、后端,逐渐差异化的思路进行实现。即在前端设计中兼容多种不同芯片后端的指令集,以帮助编译器用户(即AI程序员)不需要在乎芯片差异,而只需要专注在AI算法逻辑上即可;在中间表示(IR)设计中对不同芯片的体系结构进行区分,从而可以实现对不同芯片进行不同的优化方法;在后端的目标代码生成部分对各个芯片的不同指令集详细区分,以保证生成出的目标代码能够顺利运行在目标芯片上。
算子表达能力
算子表达能力指的是:算子编译器的前端识别输入代码,并在不损失语义信息的情况下转换为中间表示的能力。算子编译器承接的前端输入往往是PyTorch等的Python形式的代码,而Python中各种灵活的表达方式(包括而不限于索引、View语义等)对算子编译器的前端表达能力提出了较高要求。另外在检测网络中,输入算子往往还有大量的控制流语句。此外,还经常可以看到神经网络中存在许多的动态形状问题,即网络中的算子形状会受网络迭代次数和控制流等条件的影响。这些都对算子编译器前端的表达能力提出了很高的要求。
在实际工程实践中,发现大量的长尾分布般不常见但性能很差的算子(后文简称为长尾算子)往往是整体网络训练或推理的瓶颈点。而这些长尾算子大都是由于其出现频次低而不至于实现在计算库中。同时其语法过于灵活或存在大量的控制流语句以及动态形状问题而难以被目前的算子编译器前端充分表达出来,因此也难以通过算子编译器进行优化加速。于是,这些长尾算子只好以运行速度较慢的Python解释器或者虚拟机的方式执行,从而成为整个网络中的性能瓶颈。此时,提高算子编译器前端的表达能力就成为了重中之重。
相关编译优化技术
算子编译器与传统编译器在优化技术方面根出同源,但由于面对的问题不同,所以在优化思路上也有差别。两者都以前中后端的思路进行设计,都是以增强局部性和并行性为优化的理论依据。 但是前者面向的问题是AI领域中的计算问题,往往在优化过程中会大量参考和借鉴高性能计算(High-Performance Computing, HPC)的优化思路,这种情况称为借助专家经验进行优化。另外算子编译器面对的后端AI芯片的体系结构的不同,如重点的单指令多数据和单指令多线程为代表的两种后端体系结构,决定了优化过程中更多偏向于生成对单指令多数据友好的加速指令,或者生成对单指令多线程友好的多线程并行计算模型。 而后者面向的问题是更加通用的标量计算行为和计算机控制命令,往往在优化中围绕寄存器的使用和分支预测准确性等进行优化。 总之,由于需要解决的问题不同,算子编译器和传统编译器在优化算法的具体实现上有着一定的区别,但是在算法设计时也有互相借鉴的机会。
总结
总结
-
编译器后端主要负责计算图优化、算子选择、内存分配这三个任务。
-
计算图优化是在不影响模型的数值特性的基础上,通过图变换达到减少资源开销、适配硬件的执行能力、提升执行性能的目的。
-
计算图优化主要分为硬件通用优化和特定硬件优化,例如与硬件无关的算子内存IO优化和为了适配特定硬件指令限制而做的子图变换。
-
算子选择是为IR图中的每个计算节点选择一个最适合在设备上执行的算子。
-
数据存在多种存储格式和计算精度,不同的存储格式和计算精度在不同场景下对算子计算性能有较大的影响,所以算子选择需要综合考虑各方面影响选择最优的算子。
-
经过计算图优化和算子选择之后,得到了最终的IR。基于最终的IR,需要为算子的输入输出Tensor分配内存,然后加载算子到硬件上执行。
-
内存复用是一个重要的内存分配优化手段,可以让设备上容纳更大的网络模型。
-
将通信算子的内存进行融合,可以提高通信的效率;合理分配In-Place算子的内存,可以节省内存使用并且提高计算效率。
-
运行时对于算子的执行可以分为单算子调度和计算图调度两种模式,而在计算图调度模式中,根据具体硬件的能力又可以分为交互式执行和下沉式执行两种方式,交互式执行具备更多的灵活性,下沉执行可以获得更好的计算性能。
-
算子编译器是优化硬件性能的关键组件。其中,调度策略的优化和基于多面体模型算法的优化是两个关键技术。
扩展阅读
- 内存分配作为机器学习后端的重要部分,建议阅读 Sublinear Memory Cost、 Dynamic Tensor Rematerialization。
- 对于运行时的调度以及执行,建议阅读 A Lightweight Parallel and Heterogeneous Task Graph Computing System、 Dynamic Control Flow in Large-Scale Machine Learning、DEEP LEARNING WITH DYNAMIC COMPUTATION GRAPHS。
- 算子编译器是本书的扩展部分,建议阅读提出计算与调度分离的论文: Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines,以及介绍调度空间优化的论文 Ansor: Generating High-Performance Tensor Programs for Deep Learning和 olly - Polyhedral optimization in LLVM
硬件加速器
上一章节详细讨论了后端的计算图优化、算子选择以及内存分配。当前主流深度学习模型大多基于神经网络实现,无论是训练还是推理,都会产生海量的计算任务,尤其是涉及矩阵乘法这种高计算任务的算子。然而,通用处理器芯片如CPU在执行这类算子时通常耗时较大,难以满足训练和推理任务的需求。因此工业界和学术界都将目光投向特定领域的加速器芯片设计,希望以此来解决算力资源不足的问题。
本章将会着重介绍加速器的基本组成原理,并且以矩阵乘法为例,介绍在加速器上的编程方式及优化方法。
本章的学习目标包括:
概述
概述
硬件加速器设计的意义
未来人工智能发展的三大核心要素是数据、算法和算力。目前,人工智能系统算力大都构建在CPU和GPU之上且主体多是GPU。随着神经网络的层增多,模型体量增大,算法趋于复杂,CPU和GPU很难再满足新型网络对于算力的需求。例如,2015年谷歌的AlphaGo用了1202个CPU和176个GPU打败了人类职业选手,每盘棋需要消耗上千美元的电费,而与之对应的是人类选手的功耗仅为20瓦。
虽然GPU在面向向量、矩阵以及张量的计算上,引入许多新颖的优化设计,但由于GPU需要支持的计算类型复杂,芯片规模大、能耗高,人们开始将更多的精力转移到深度学习硬件加速器的设计上来。和传统CPU和GPU芯片相比,深度学习硬件加速器有更高的性能和更低的能耗。未来随着人们真正进入智能时代,智能应用的普及会越来越广泛,到那时每台服务器、每台智能手机和每个智能摄像头,都需要使用深度学习加速器。
硬件加速器设计的思路
近些年来,计算机体系结构的研究热点之一是深度学习硬件加速器的设计。在体系结构的研究中,能效和通用性是两个重要的衡量指标。其中能效关注单位能耗下基本计算的次数,通用性主要指芯片能够覆盖的任务种类。以两类特殊的芯片为例:一种是较为通用的通用处理器(如CPU),该类芯片理论上可以完成各种计算任务,但是其能效较低大约只有0.1TOPS/W。另一种是专用集成电路(Application Specific Integrated Circuit, ASIC),其能效更高,但是支持的任务相对而言就比较单一。对于通用的处理器而言,为了提升能效,在芯片设计上引入了许多加速技术,例如:超标量技术、单指令多数据(Single Instruction Multiple Data,SIMD)技术以及单指令多线程(Single Instruction Multiple Threads,SIMT)技术等。
对于不同的加速器设计方向,业界也有不同的硬件实现。针对架构的通用性,NVIDIA持续在GPU芯片上发力,先后推出了Volta、 Turing、 Ampere等架构,并推出用于加速矩阵计算的张量计算核心(Tensor Core),以满足深度学习海量算力的需求。
对于偏定制化的硬件架构,面向深度学习计算任务,业界提出了特定领域架构(Domain Specific Architecture, DSA)。Google公司推出了TPU芯片,专门用于加速深度学习计算任务,其使用脉动阵列(Systolic Array)来优化矩阵乘法和卷积运算,可以充分地利用数据局部性,降低对内存的访问次数。华为也推出了自研昇腾AI处理器,旨在为用户提供更高能效的算力和易用的开发、部署体验,其中的CUBE运算单元,就用于加速矩阵乘法的计算。
加速器基本组成原理
加速器基本组成原理
上节主要介绍了加速器的意义以及设计思路,讲述了加速器与通用处理器在设计上的区别,可以看到加速器的硬件结构与CPU的硬件结构有着根本的不同,通常都是由多种片上缓存以及多种运算单元组成。本章节主要以GPU的Volta架构作为样例进行介绍。
硬件加速器的架构
现代GPU在十分有限的面积上实现了极强的计算能力和极高的储存器以及IO带宽。在一块高端的GPU中,晶体管数量已经达到主流CPU的两倍,而且显存已经达到了16GB以上,工作频率也达到了1GHz。GPU的体系架构由两部分组成,分别是流处理阵列和存储器系统,两部分通过一个片上互联网络连接。流处理器阵列和存储器系统都可以单独扩展,规格可以根据产品的市场定位单独裁剪。如GV100的组成 [1]如 图7.2.1所示:

图7.2.1 Volta GV100
- 6个GPU处理集群(GPU Processing Cluster,GPC), 每个GPC含有:
- 7个纹理处理集群(Texture Processing Cluster, TPC) (每个TPC含有两个流多处理器(Streaming Multiprocessor, SM))
- 14个SM
- 84个SM, 每个流多处理器含有:
- 64个32位浮点运算单元
- 64个32位整数运算单元
- 32个64位浮点运算单元
- 8个张量计算核心
- 4个纹理单元
- 8个512位内存控制器
一个完整的GV100 GPU含有84个SM,5376个32位浮点运算单元,5376个32位整型运算单元,2688个64位浮点运算单元,672个张量运算单元和336个纹理单元。一对内存控制器控制一个HBM2 DRAM堆栈。 图7.2.1中展示的为带有84个SM的GV100 GPU(不同的厂商可以使用不同的配置),Tesla V100则含有80个SM。
硬件加速器的存储单元
与传统的CPU模型相似,从一个计算机系统主内存DRAM中获取数据的速度相对于处理器的运算速度较慢。对于加速器而言,如果没有缓存进行快速存取,DRAM的带宽非常不足。如果无法快速地在DRAM上获取程序和数据,加速器将因空置而降低利用率。为了缓解DRAM的带宽问题,GPU提供了不同层次的若干区域供程序员存放数据,每块区域的内存都有自己的最大带宽以及延迟。开发者需根据不同存储器之间的存储速度的数量级的变化规律,选用适当类型的内存以及最大化地利用它们,从而发挥硬件的最大算力,减少计算时间。
-
寄存器文件(Register File):片上最快的存储器,但与CPU不同,GPU的每个SM(流多处理器)有上万个寄存器。尽管如此当每个线程使用过多的寄存器时,SM中能够调度的线程块数量就会受到限制,可执行的线程总数量会因此受到限制,可执行的线程数量过少会造成硬件无法充分的利用,性能急剧下降。所以要根据算法的需求合理使用寄存器。
-
共享内存(Shared Memory):共享内存实际上是用户可控的一级缓存,每个SM(流多处理器)中有128KB的一级缓存, 开发者可根据应用程序需要配置最大96KB的一级缓存作为共享内存。共享内存的访存延迟极低,只有几十个时钟周期。共享内存具有高达1.5TB/s的带宽,远远高于全局内存的峰值带宽900GB/s。共享内存的使用对于高性能计算工程师来说是一个必须要掌握的概念。
-
全局内存(Global Memory):全局内存之所以称为全局,是因为GPU与CPU都可以对它进行读写操作。全局内存对于GPU中的每个线程都是可见的,都可以直接对全局内存进行读写操作。CPU等其他设备可以通过PCI-E总线对其进行读写操作。全局内存也是GPU中容量最大的一块内存,可达16GB之多。同时也是延迟最大的内存,通常有高达上百个时钟周期的访存延迟。
-
常量内存(Constant Memory):常量内存其实只是全局内存的一种虚拟地址形式,并没有真正的物理硬件内存块。常量内存有两个特性,一个是高速缓存,另一个更重要的特性是它支持将某个单个值广播到线程束中的每个线程中。
-
纹理内存(Texture Memory):纹理内存是全局内存的一个特殊形态。当全局内存被绑定为纹理内存时,执行读写操作将通过专用的纹理缓存来加速。在早期的GPU上没有缓存,因此每个SM上的纹理内存为设备提供了唯一真正缓存数据的方法。然而随着硬件的升级,一级缓存和二级缓存的出现使得纹理缓存的这项优势已经荡然无存。纹理内存的另外一个特性,也是最有用的特性就是当访问存储单元时,允许GPU实现硬件相关的操作。比如说使用纹理内存,可以通过归一化的地址对数组进行访问,获取的数据可以通过硬件进行自动插值,从而达到快速处理数据的目的。此外对于二维数组和三维数组,支持硬件级的双线性插值与三线性插值。纹理内存另一个实用的特性是可以根据数组的索引自动处理边界条件,不需要对特殊边缘进行处理即可完成数组内元素操作,从而防止线程中分支的产生。
硬件加速器的计算单元
为了支持不同的神经网络模型,加速器会提供以下几种计算单元,不同的网络层可以根据需要选择使用合适的计算单元,如 图7.2.2所示
-
标量计算单元:与标准的精简指令运算集(Reduced Instruction Set Computer,RISC)相似,一次计算一个标量元素。
-
一维向量计算单元:一次可以完成多个元素的计算,与传统的CPU和GPU架构中单指令多数据(SIMD)相似,已广泛应用于高性能计算(High Performance Computing,HPC)和信号处理中。
-
二维向量计算单元:一次运算可以完成一个矩阵与向量的内积,或向量的外积。利用数据重复使用这一特性,降低数据通信成本与存储空间,更高效的提高矩阵乘法性能。
-
三维向量计算单元:一次完成一个矩阵的乘法,专为神经网络应用设计的计算单元,更充分利用数据重复特性,隐藏数据通信带宽与数据计算的差距。
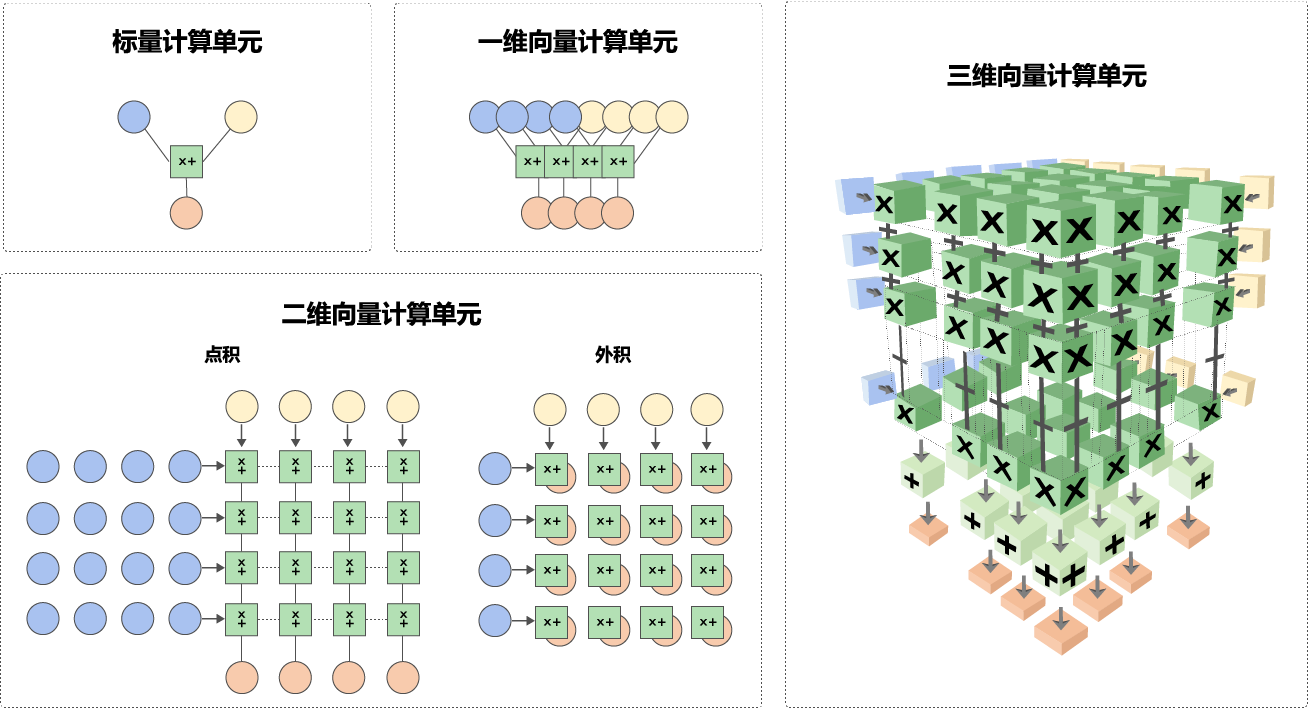
图7.2.2 多种计算单元
GPU计算单元主要由标量计算单元和三维向量计算单元组成。如 图7.2.3所示,对于每个SM,其中64个32位浮点运算单元、64个32位整数运算单元、32个64位浮点运算单元均为标量计算单元。而8个张量计算核心则是专为神经网络应用设计的三维向量计算单元。
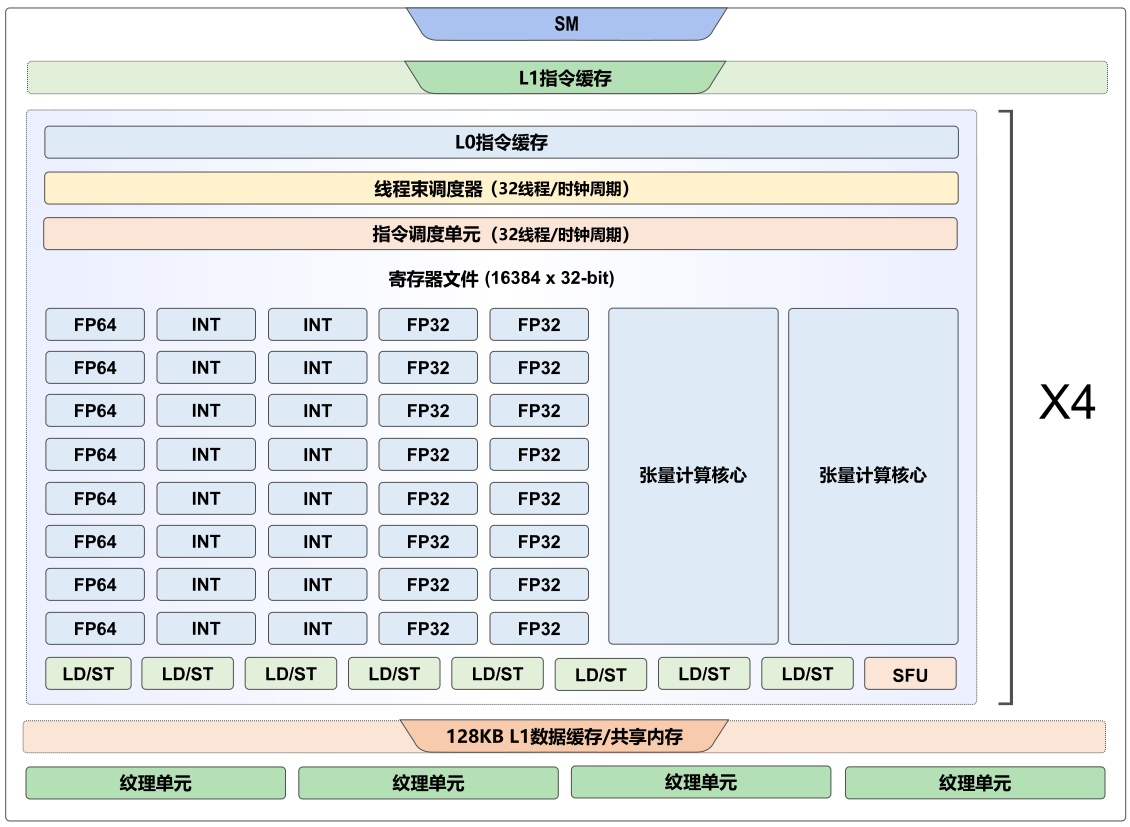
图7.2.3 Volta GV100 流多处理器(SM)
张量计算核心每个时钟周期完成一次\(4\times4\)的矩阵乘累加计算,如 图7.2.4所示:
D = A * B + C

图7.2.4 张量计算核心\\(4\times4\\)矩阵乘累加计算
其中A,B,C和D都是\(4\times4\)的矩阵,矩阵乘累加的输入矩阵A和B是FP16的矩阵,累加矩阵C和D可以是FP16也可以是FP32。 V100的张量计算核心是可编程的矩阵乘法和累加计算单元,可以提供多达125 Tensor TFLOPS(Tera Floating-point Operations Per Second)的训练和推理应用。相比于普通的FP32计算单元可以提速10倍以上。
DSA芯片架构
为了满足飞速发展的深度神经网络对芯片算力的需求,业界也纷纷推出了特定领域架构DSA芯片设计。以华为公司昇腾系列AI处理器为例,本质上是一个片上系统(System on Chip,SoC),主要应用在图像、视频、语音、文字处理相关的场景。主要的架构组成部件包括特制的计算单元、大容量的存储单元和相应的控制单元。该芯片由以下几个部分构成:芯片系统控制CPU(Control CPU)、AI计算引擎(包括AI Core和AI CPU)、多层级的片上系统缓存(Cache)或缓冲区(Buffer)、数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等。
昇腾AI芯片的计算核心主要由AI Core构成,负责执行标量、向量和张量相关的计算密集型算子。AI Core采用了达芬奇架构 [2],基本结构如 图7.2.5所示,从控制上可以看成是一个相对简化的现代微处理器基本架构。它包括了三种基础计算单元:矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit)。这三种计算单元分别对应了张量、向量和标量三种常见的计算模式,在实际的计算过程中各司其职,形成了三条独立的执行流水线,在系统软件的统一调度下互相配合达到优化计算效率的目的。 同GPU类似,在矩阵乘加速设计上,在AICore中也提供了矩阵计算单元作为昇腾AI芯片的核心计算模块,意图高效解决矩阵计算的瓶颈问题。矩阵计算单元提供强大的并行乘加计算能力,可以用一条指令完成两个\(16\times16\)矩阵的相乘运算,等同于在极短时间内进行了\(16\times16\times16=4096\)个乘加运算,并且可以实现FP16的运算精度。

图7.2.5 达芬奇架构设计
参考文献
- NVIDIA. NVIDIA Tesla V100 GPU Architecture: The World's Most Advanced Datacenter GPU. 2017. ↩
- Liao, Heng and Tu, Jiajin and Xia, Jing and Liu, Hu and Zhou, Xiping and Yuan, Honghui and Hu, Yuxing. Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing : Industry Track Paper. 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 2021. ↩
加速器基本编程原理
加速器基本编程原理
本章前两节主要介绍了这些硬件加速器设计的意义、思路以及基本组成原理。软硬件协同优化作为构建高效AI系统的一个重要指导思想,需要软件算法/软件栈和硬件架构在神经网络应用中互相影响、紧密耦合。为了最大限度地发挥加速器的优势,要求能够基于硬件系统架构设计出一套较为匹配的指令或编程方法。因此,本节将着重介绍加速器的可编程性,以及如何通过编程使能加速器,提升神经网络算子的计算效率。
硬件加速器的可编程性
accelerator-design-title中列出的硬件加速器均具有一定的可编程性,程序员可以通过软件编程,有效的使能上述加速器进行计算加速。现有硬件加速器常见的两类编程方式主要有编程接口调用以及算子编译器优化。
编程接口使能加速器
硬件加速器出于计算效率和易用性等方面考虑,将编程使能方式分为不同等级,一般包括:算子库层级,编程原语层级,以及指令层级。为了更具象的解释上述层级的区别,仍以Volta架构的张量计算核心为例,由高层至底层对比介绍这三种不同编程方式:
-
算子库层级:如cuBLAS基本矩阵与向量运算库,cuDNN深度学习加速库,均通过Host端调用算子库提供的核函数使能张量计算核心;
-
编程原语层级:如基于CUDA的WMMA API编程接口。同算子库相比,需要用户显式调用计算各流程,如矩阵存取至寄存器、张量计算核心执行矩阵乘累加运算、张量计算核心累加矩阵数据初始化操作等;
-
指令层级:如PTX ISA MMA指令集,提供更细粒度的mma指令,便于用户组成更多种形状的接口,通过CUDA Device端内联编程使能张量计算核心。
算子编译器使能加速器
DSA架构的多维度AI加速器通常提供了更多的指令选择(三维向量计算指令、二维向量计算指令、一维向量计算指令),以及更加复杂的数据流处理,通过提供接口调用的方式对程序开发人员带来较大的挑战。此外,由于调度、切分的复杂度增加,直接提供算子库的方式由于缺少根据目标形状(Shape)调优的能力,往往无法在所有形状下均得到最优的性能。因此,对于DSA加速器,业界通常采用算子编译器的解决方案。
随着深度学习模型的迭代更新及各类AI芯片的层出不穷,基于人工优化算子的方式给算子开发团队带来沉重的负担。因此,开发一种能够将High-level的算子表示编译成目标硬件可执行代码的算子编译器,逐渐成为学术界及工业界的共识。算子编译器前端通常提供了特定领域描述语言(DSL),用于定义算子的计算范式;类似于传统编译器,算子编译器也会将算子计算表示转换为中间表示,如HalideIR [1]、TVM [2]的TIR、Schedule Tree [3]等,基于模板(手动)、搜索算法或优化求解算法(自动)等方式完成循环变换、循环切分等调度相关优化,以及硬件指令映射、内存分配、指令流水等后端pass优化,最后通过代码生成模块将IR转换为DSA加速器可执行的设备端核函数。
当前业界的算子编译器/编译框架主要有TVM/Ansor [4]、MLIR [5]、以及华为昇腾芯片上的TBE/AKG [6]等。
- TVM/Ansor
TVM是陈天奇博士等人开发的开源深度学习编译框架,提供了端到端的编译优化(图优化/算子优化)能力,在工业界应用较广。在架构上,主要包括Relay和TIR两层。通过Relay导入推理模型,进行算子融合等图层优化,通过TIR生成融合算子。在算子编译方面,TVM采用了计算和调度分离的技术,为不同的算子提供了不同的模板,同时支持自定义模板,优化特定算子类型调度。为了更进一步优化算子性能,TVM支持对算子进行自动调优,来生成较优的切分参数。此外,为了简化用户开发模板的工作,TVM在0.8版本后提供了自动调度能力Ansor,通过搜索的方式,为目标算子生成调度及切分参数。如 图7.3.1所示:
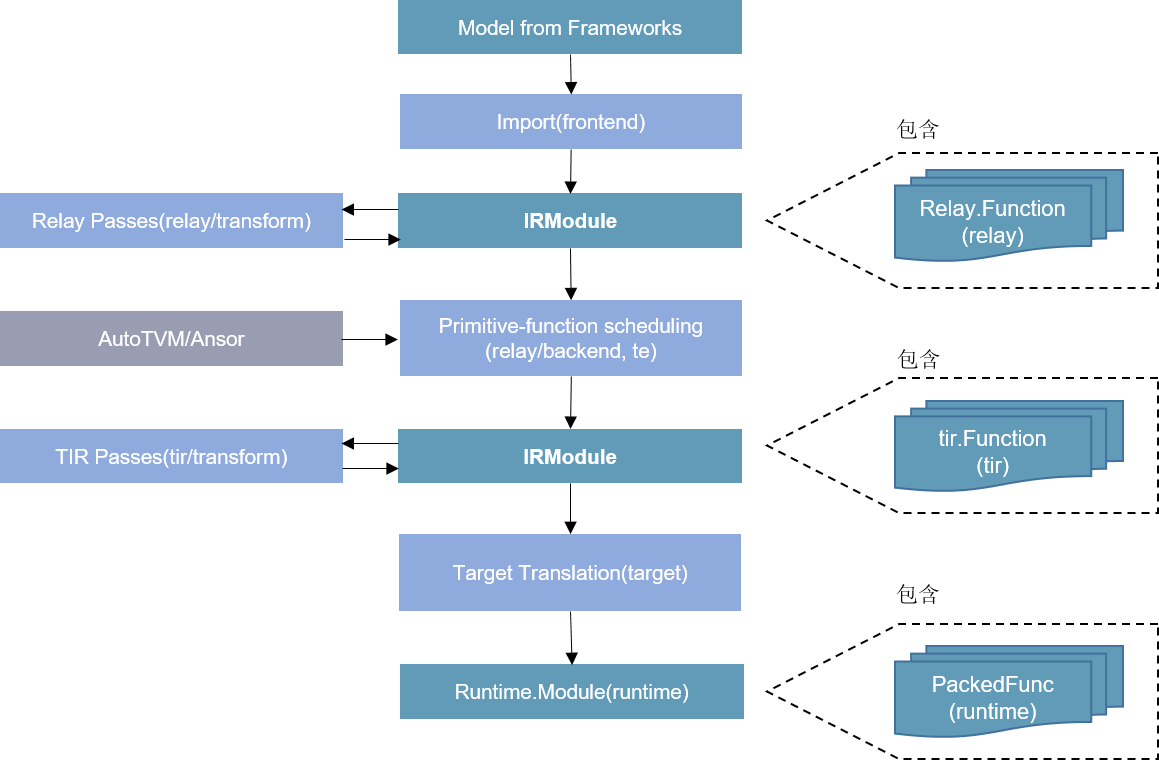
图7.3.1 TVM
- MLIR
前面的章节介绍过,Google开发的MLIR并不是一个单一的算子编译器,而是一套编译器基础设施,提供了工具链的组合与复用能力。基于MLIR,DSA加速器厂商可以快速的搭建其定制化算子编译器。如Google论文 [7]中所述,当前的算子编译器大多提供了一整套自顶向下的编译优化pass,包括调度优化、切分优化、窥孔优化、后端优化、指令生成等,彼此之间大多无法复用,导致新的场景中通常又得从头开发。而在MLIR中,将功能相近的IR优化pass封装为方言(Dialect),并且提供了多个代码生成相关的基础方言,如vector、memref、tensor、scf、affine、linalg等。硬件厂商可以基于这些方言,快速构建一整套lower优化及codegen流程。如 图7.3.2所示,利用scf、affine、linalg等方言,对结构化的计算IR完成循环并行优化、切分、向量化等,最后基于LLVM完成指令映射。
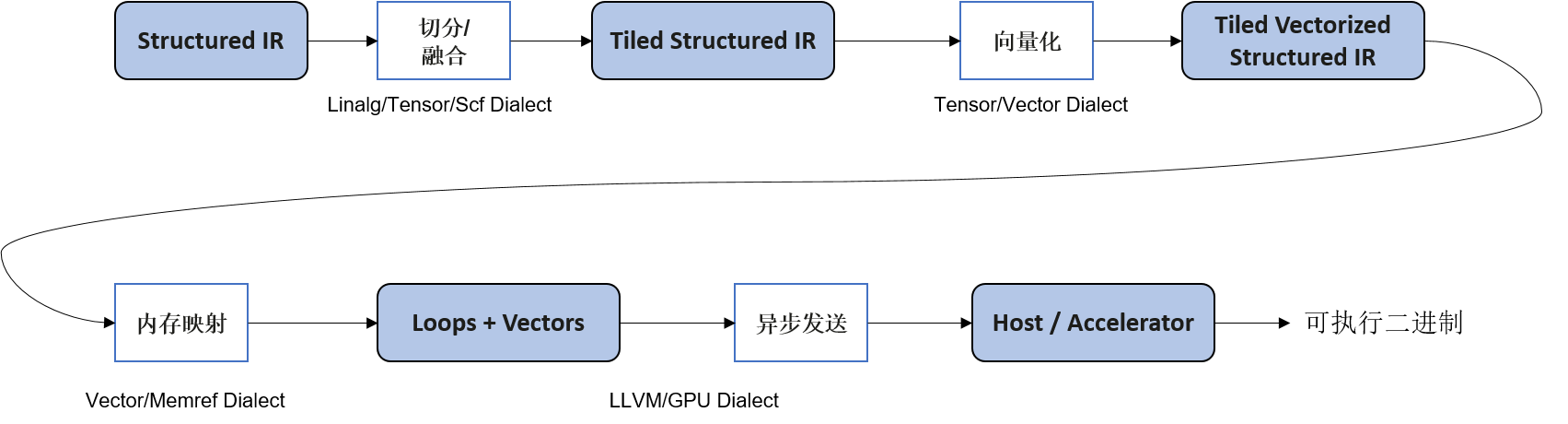
图7.3.2 MLIR_Lowing
- 华为TBE/AKG
张量加速引擎(Tensor Boost Engine,TBE)是华为的Ascend芯片及其CANN软件栈基于TVM 开发的一套算子编译优化工具,用于对Ascend芯片进行调度优化、指令映射、及后端pass优化等。如 图7.3.3所示。不仅提供了一个优化过的神经网络标准算子库,同时还提供了算子开发能力及融合能力。通过TBE提供的API和自定义算子编程开发界面可以完成相应神经网络算子的开发,帮助用户较容易的去使能硬件加速器上的AI Core指令,以实现高性能的神经网络计算。为了简化算子开发流程,TBE还实现了一个Auto Schedule工具,开放了自定义算子编程DSL,用于自动完成复杂算子的调度生成。此外,TBE还实现了端到端的动态形状算子编译能力。
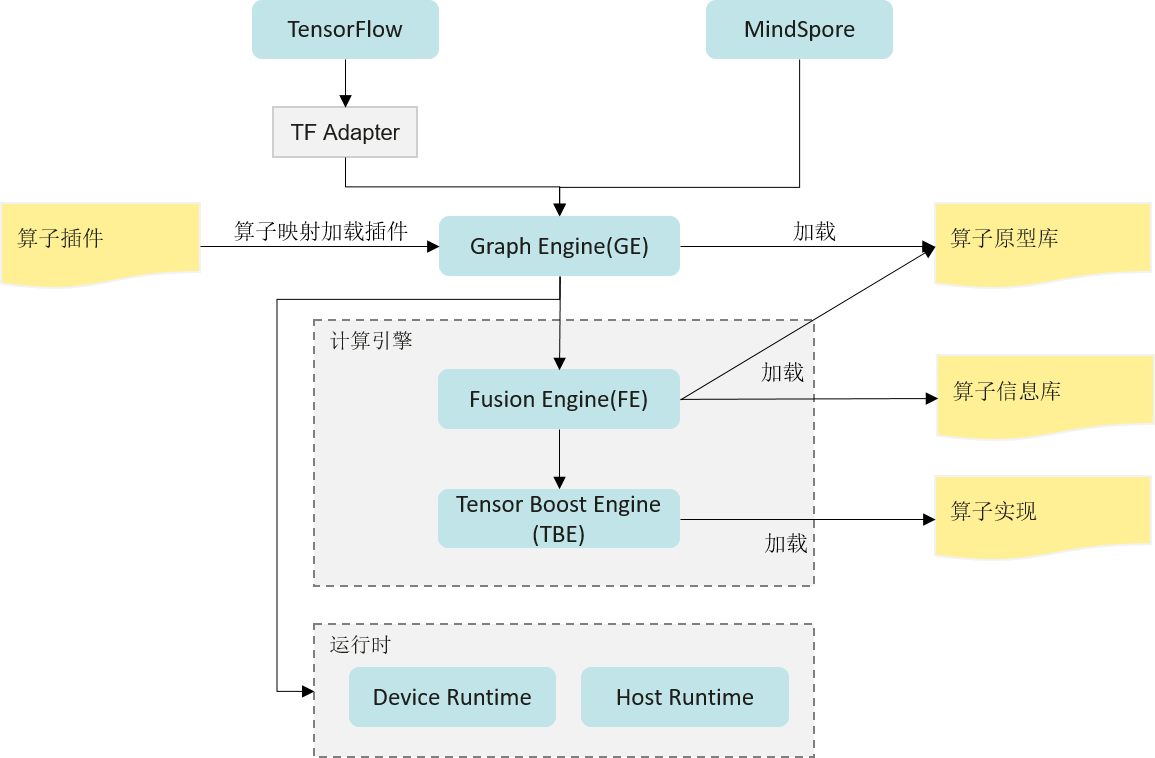
图7.3.3 张量加速引擎
AKG则是MindSpore社区的开源算子编译工具。与上述介绍的算子编译器不同,AKG基于Polyhedral多面体编译技术 [8],支持在CPU、GPU和Ascend多种硬件上自动生成满足并行性与数据局部性的调度。Polyhedral编译技术的核心思想是将程序中循环的迭代空间映射为高维空间多面体,通过分析语句读写依赖关系,将循环调度优化问题转换为整数规划求解问题。 AKG的编译流程如 图7.3.4所示,主要包含规范化、自动调度优化、指令映射、后端优化几个模块。AKG同样基于TVM实现,支持TVM compute/Hybrid DSL编写的算子表示,以及MindSpore图算融合模块优化后的融合子图。通过IR规范化,将DSL/子图IR转换为Polyhedral编译的调度树。在Poly模块中,利用其提供的调度算法,实现循环的自动融合、自动重排等变换,为融合算子自动生成满足并行性、数据局部性的初始调度。为了能够快速适配不同的硬件后端,在Poly模块内将优化pass识别为硬件无关的通用优化与硬件相关的特定优化,编译时按照硬件特征拼接组合,实现异构硬件后端的快速适配。
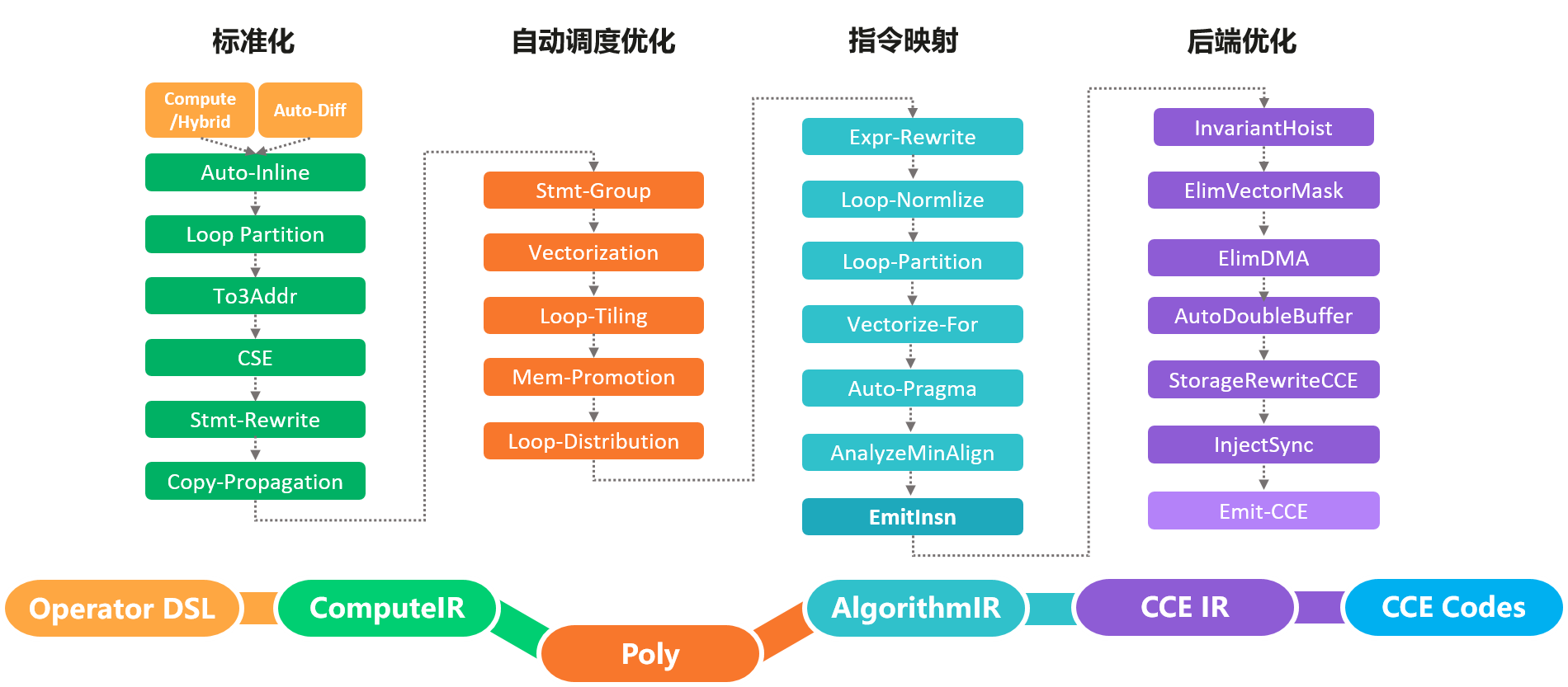
图7.3.4 AKG
在Poly模块中,实现了算子的自动调度生成、自动切分以及自动数据搬移。为了进一步提升算子的性能,针对不同硬件后端开发了相应的优化pass,如Ascend后端中实现数据对齐、指令映射,GPU后端中实现向量化存取,插入同步指令等,最终生成相应平台代码。
硬件加速器的多样化编程方法
矩阵乘法运算作为深度学习网络中占比最大的计算,对其进行优化是十分必要的。因此本节将统一以广义矩阵乘法为实例,对比介绍如何通过不同编程方式使能加速器。广义矩阵乘法指GEMM(General Matrix Multiplication),即\({C} = \alpha {A}\times {B} + \beta {C}\),其中\({A}\in\mathbb{R}^{M\times K}, {B}\in\mathbb{R}^{K\times N}, {C}\in\mathbb{R}^{M\times N}\)。

图7.3.5 矩阵乘法GEMM运算
编程接口使能加速器
- 算子库层级
在上述不同层级的编程方式中,直接调用算子加速库使能加速器无疑是最快捷高效的方式。NVIDIA提供了cuBLAS/cuDNN两类算子计算库,cuBLAS提供了使能张量计算核心的接口,用以加速矩阵乘法(GEMM)运算,cuDNN提供了对应接口加速卷积(CONV)运算等。 以 accelerator-programable-title的GEMM运算为例,与常规CUDA调用cuBLAS算子库相似,通过cuBLAS加速库使能张量计算核心步骤包括:
- 创建cuBLAS对象句柄且设置对应数学计算模式
cublasHandle_t handle;
cublasStatus_t cublasStat = cublasCreate(&handle);
cublasStat = cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);
- 分配和初始化矩阵内存空间及内容元素
size_t matrixSizeA = (size_t)M * K;
cublasStat = cudaMalloc(&devPtrA[0], matrixSizeA * sizeof(devPtrA[0][0]));
cublasStat = cublasSetMatrix(M, K, sizeof(A[0]), A, M, devPtrA[i], M);
- 调用对应计算函数接口
cublasStat = cublasGemmEx(handle, transa, transb, m, n, k, alpha,
A, CUDA_R_16F, lda,
B, CUDA_R_16F, ldb,
beta, C, CUDA_R_16F, ldc, CUDA_R_32F, algo);
- 传回结果数据
cublasStat = cublasGetMatrix(M, N, sizeof(D[0]), devPtrD[i], M, D, M);
- 释放内存和对象句柄
cudaFree(devPtrA);
cudaDestroy(handle);
当然,由于加速器一般会受到矩阵形状、数据类型、排布方式等限制,因此在调用句柄和函数接口时要多加注意。如本例中,cuBLAS计算模式必须设置为\(CUBLAS\_TENSOR\_OP\_MATH\),步长必须设置为8的倍数,输入数据类型必须为\(CUDA\_R\_16F\)等。按照如上方式即可通过cuBLAS算子库对 accelerator-programable-title实例使能张量计算核心,通过NVIDIA官方数据可知,该方式对于不同矩阵乘法计算规模,平均有4~10倍的提升,且矩阵规模越大,加速器提升效果越明显。
该方式由于能够隐藏体系结构细节,易用性较好,且一般官方提供的算子库吞吐量较高。但与此同时,这种算子颗粒度的库也存在一些问题,如不足以应对复杂多变的网络模型导致的算子长尾问题(虽然常规形式算子占据绝大多数样本,但仍有源源不断的新增算子,因其出现机会较少,算子库未对其进行有效优化。),以及错失了较多神经网络框架优化(如算子融合)的机会。
- 编程原语层级
第二种加速器编程方式为编程原语使能加速器,如通过在Device端调用CUDA WMMA (Warp Matrix Multiply Accumulate) API接口。以线程束(即{Warp},是调度的基本单位)为操纵对象,使能多个张量计算核心。该方式在CUDA 9.0中被公开,程序员可通过添加API头文件的引用和命名空间定义来使用上述API接口。基于软硬件协同设计的基本思想,该层级编程API的设计多与架构绑定,如在Volta架构中WMMA操纵的总是\(16\times16\)大小的矩阵块,并且操作一次跨两张量计算核心进行处理,本质是与张量计算核心如何集成进SM中强相关的。在Volta架构下,针对FP16输入数据类型,NVIDIA官方提供了三种不同矩阵规模的WMMA乘累加计算接口,分别为\(16\times16\times16\),\(32\times8\times16\),\(8\times32\times16\)。 该API接口操纵的基本单位为Fragment,是一种指明了矩阵含义(乘法器/累加器)、矩阵形状(\(WMMA\_M, WMMA\_N, WMMA\_K\))、数据类型(FP16/FP32)、排布方式(\(row\_major/ col\_major\))等信息的模板类型,包括如下:
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
使用时,需要将待执行乘法操作矩阵块的数据加载到寄存器,作为Fragment,在将累加Fragment初始化/清零操作后,通过张量计算核心执行乘累加运算,最后将运算结果的Fragment存回到内存。与上述操作对应的,NVIDIA提供了\(wmma.load\_matrix\_sync(), wmma.store\_matrix\_sync()\)接口用于将参与计算的子矩阵块写入/载出Fragment片段;\(wmma.fill\_fragment()\)接口用于初始化对应Fragment的数据;\(wmma.mma\_sync()\)接口用于对Fragment进行乘累加运算。
- 指令层级
在NVIDIA PTX ISA (Instruction Set Architecture)中提供了另一个编程接口,如Volta架构中的\(mma.sync.m8n8k4\)指令,它使用\(M=8, N=8, K=4\)的形状配置执行乘累加操作。该API接口操纵的基本单位为数据元素,除了需要指明矩阵尺寸(即修饰符\(.m8n8k4\)),还需要指明数据的排布类型(用修饰符\(.row\)或\(.col\))以及输入累加器D、矩阵A、矩阵B及输出累加器C的数据格式(使用修饰符\(.f32\)或\(.f16\)等)。如要使用PTX指令集,还需要参考官方文档按照相应的语法规则编写,如代码所示。
half_t *a, *b;
float *C, *D;
unsigned const* A = reinterpret_cast<unsigned const*>(a);
unsigned const* B = reinterpret_cast<unsigned const*>(b);
asm volatile(
"mma.sync.aligned.m8n8k4.row.row.f32.f16.f16.f32 "
"{%0,%1,%2,%3,%4,%5,%6,%7}, {%8,%9}, {%10,%11}, "
"{%12,%13,%14,%15,%16,%17,%18,%19};\n"
: "=f"(D[0]), "=f"(D[1]), "=f"(D[2]), "=f"(D[3]), "=f"(D[4]),
"=f"(D[5]), "=f"(D[6]), "=f"(D[7])
: "r"(A[0]), "r"(A[1]), "r"(B[0]), "r"(B[1]), "f"(C[0]),
"f"(C[1]), "f"(C[2]), "f"(C[3]), "f"(C[4]), "f"(C[5]),
"f"(C[6]), "f"(C[7]));
);
使用时,直接将数据元素作为输入传入(对于FP16的数据元素作为\(unsigned\)类型传入),与上述操作对应的,NVIDIA提供了\(ldmatrix\)指令用于从共享内存中加载数据到Fragment。
作为一个更细粒度的指令,mma指令可以组成更加多样化形状的Warp范围的WMMA API接口,可以控制线程束内线程与数据的映射关系,并允许AI编译器自动/手动显式地管理内存层次结构之间的矩阵分解,因此相比于直接应用NVCUDA::WMMA API具有更好的灵活性。
算子编译器编程使能加速器
基于算子编译器使能加速器实现矩阵乘的流程则对用户更加友好。以在Ascend中使用TBE为例,用户只需基于python定义矩阵乘的tensor信息(数据类型及形状等),调用对应TBE接口即可。如代码所示:
a_shape = (1024, 256)
b_shape = (256, 512)
bias_shape = (512, )
in_dtype = "float16"
dst_dtype = "float32"
tensor_a = tvm.placeholder(a_shape, name='tensor_a', dtype=in_dtype)
tensor_b = tvm.placeholder(b_shape, name='tensor_b', dtype=in_dtype)
tensor_bias = tvm.placeholder(bias_shape, name='tensor_bias', dtype=dst_dtype)
res = te.lang.cce.matmul(tensor_a, tensor_b, False, False, False, dst_dtype=dst_dtype, tensor_bias=tensor_bias)
参考文献
- Ragan-Kelley, Jonathan and Barnes, Connelly and Adams, Andrew and Paris, Sylvain and Durand, Fredo and Amarasinghe, Saman. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. Acm Sigplan Notices. 2013. ↩
- Chen, Tianqi and Moreau, Thierry and Jiang, Ziheng and Shen, Haichen and Yan, Eddie Q and Wang, Leyuan and Hu, Yuwei and Ceze, Luis and Guestrin, Carlos and Krishnamurthy, Arvind. TVM: end-to-end optimization stack for deep learning. arXiv preprint arXiv:1802.04799. 2018. ↩
- Verdoolaege, Sven. isl: An integer set library for the polyhedral model. International Congress on Mathematical Software. 2010. ↩
- Zheng, Lianmin and Jia, Chengfan and Sun, Minmin and Wu, Zhao and Yu, Cody Hao and Haj-Ali, Ameer and Wang, Yida and Yang, Jun and Zhuo, Danyang and Sen, Koushik and others. Ansor: Generating \\(\\\)High-Performance\\(\\\) Tensor Programs for Deep Learning. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 2020. ↩
- Lattner, Chris and Amini, Mehdi and Bondhugula, Uday and Cohen, Albert and Davis, Andy and Pienaar, Jacques and Riddle, River and Shpeisman, Tatiana and Vasilache, Nicolas and Zinenko, Oleksandr. MLIR: A compiler infrastructure for the end of Moore's law. arXiv preprint arXiv:2002.11054. 2020. ↩
- Zhao, Jie and Li, Bojie and Nie, Wang and Geng, Zhen and Zhang, Renwei and Gao, Xiong and Cheng, Bin and Wu, Chen and Cheng, Yun and Li, Zheng and others. AKG: automatic kernel generation for neural processing units using polyhedral transformations. Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. 2021. ↩
- Vasilache, Nicolas and Zinenko, Oleksandr and Bik, Aart JC and Ravishankar, Mahesh and Raoux, Thomas and Belyaev, Alexander and Springer, Matthias and Gysi, Tobias and Caballero, Diego and Herhut, Stephan and others. Composable and Modular Code Generation in MLIR: A Structured and Retargetable Approach to Tensor Compiler Construction. arXiv preprint arXiv:2202.03293. 2022. ↩
- Bastoul, Cedric. Code generation in the polyhedral model is easier than you think. Proceedings. 13th International Conference on Parallel Architecture and Compilation Techniques, 2004. PACT 2004.. 2004. ↩
加速器实践
加速器实践
在本节中会通过具体的CUDA代码向读者介绍如何编写一个并行计算的广义矩阵乘法程序,通过提高计算强度、使用共享内存、优化内存读取流水线等方法最终取得接近硬件加速器性能峰值的实现。虽然在以上章节介绍了张量计算核心相关的内容,但由于篇幅限制,在本节中不使用此硬件结构。而是通过使用更为基本的CUDA代码实现FP32的广义矩阵乘法,来讲解若干实用优化策略。
环境
本节的实践有以下的软件环境依赖:
- Eigen:Eigen是一个线性代数C++模板库,用户可以只使用几条语句完成多线程线性代数运算。
- OpenMP(可选):OpenMP是用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案,可以使用OpenMP对Eigen的计算进行加速。
- CUDA Toolkit:CUDA Toolkit是英伟达发布的CUDA工具包,其包含了CUDA编译器(NVCC),CUDA线性代数库(cuBLAS)等组件。 本节的实践都是在CPU Intex Xeon E5-2650 v3,GPU Nvidia Geforce RTX 3080;系统Ubuntu 18.04版本,CUDA Toolkit 11.1进行的。
安装相关依赖如下:
- Eigen:Eigen的安装可以通过使用包管理器安装(如使用指令
apt install libeigen3-dev),也可以从官网下载。 - OpenMP(可选):通常会被大多数编译器默认支持,如果没有被支持的话可以使用包管理器安装(如使用指令
apt install libomp-dev)。 - CUDA Toolkit:CUDA Toolkit的安装建议按照官方的提示安装,也可以通过使用包管理器安装(如使用指令
apt install cuda)。
广义矩阵乘法的朴素实现
依照算法如 图7.3.5所示,编写CPU代码如下所示:
float A[M][K];
float B[K][N];
float C[M][N];
float alpha, beta;
for (unsigned m = 0; m < M; ++m) {
for (unsigned n = 0; n < N; ++n) {
float c = 0;
for (unsigned k = 0; k < K; ++k) {
c += A[m][k] * B[k][n];
}
C[m][n] = alpha * c + beta * C[m][n];
}
}
可以看到,矩阵\(C\) 中各个元素的计算是独立的。可以利用GPU的大量线程去分别计算矩阵\(C\) 中相应的元素,以达到并行计算的目的,GPU核函数将如下所示:
__global__ void gemmKernel(const float * A,
const float * B, float * C,
float alpha, float beta, unsigned M, unsigned N,
unsigned K) {
unsigned int m = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int n = threadIdx.y + blockDim.y * blockIdx.y;
if (m >= M || n >= N)
return;
float c = 0;
for (unsigned k = 0; k < K; ++k) {
c += A[m * K + k] * B[k * N + n];
}
c = c * alpha;
float result = c;
if (beta != 0) {
result = result + C[m * N + n] * beta;
}
C[m * N + n] = result;
}
其可视化结构如 图7.4.1所示,矩阵\(C\)中每一个元素由一个线程计算,在GPU Kernel的第5和6行计算该线程对应矩阵\(C\)中的元素行号\(m\)及列号\(n\),然后在第9到11行该线程利用行号与列号读取矩阵\(A\)和矩阵\(B\)中相应的行列向量元素并计算向量内积,最后在第17行将结果写回\(C\)矩阵。
图7.4.1 矩阵乘法的朴素实现
使用以下代码启动核函数:
void gemmNaive(const float *A, const float *B, float *C,
float alpha, float beta, unsigned M,
unsigned N, unsigned K) {
dim3 block(16, 16);
dim3 grid((M - 1) / block.x + 1, (N - 1) / block.y + 1);
gemmKernel<<<grid, block>>>(A, B, C, alpha, beta, M, N, K);
}
在这里令每个线程块处理矩阵\(C\)中\(16\times16\)个元素,因此开启\((M - 1) / 16 + 1 \times (N - 1) / 16 + 1\)个线程块用于计算整个矩阵\(C\)。
使用Eigen生成数据并计算得到CPU端的广义矩阵乘法结果,同时实现了GPU端计算结果的误差计算、时间测试的代码,详情见first_attempt.cu,编译及执行得到输出结果为:
Average Time: 48.961 ms
Max Error: 0.000092
可以使用以下公式粗略的计算GPU的峰值吞吐量:2\(\times\)频率\(\times\)单精度计算单元数量 ,其中单精度计算单元数量等于GPU中流多处理器(SM)数量乘每个流多处理器中单精度计算单元数量,计算可以得到以下结果:
FP32 peak throughput 29767.680 GFLOPS
Average Throughput: 185.313 GFLOPS
可以发现目前的代码距离设备峰值性能仍有较大的差距。在整个计算过程中计算密集最大的过程为矩阵乘法\(A\times B\),其时间复杂度为\(O(M*N*K)\),而整个计算过程时间复杂度为\(O(M*N*K+2*M*N)\),因此对矩阵乘法的优化是提升性能的关键。
提高计算强度
计算强度(Compute Intensity)指计算指令数量与访存指令数量的比值,在现代GPU中往往有大量计算单元但只有有限的访存带宽,程序很容易出现计算单元等待数据读取的问题,因此提高计算强度是提升程序性能的一条切实有效的指导思路。对于之前实现的GPU核函数,可以粗略计算其计算强度:在\(K\)次循环的内积计算中,对矩阵\(A\)与矩阵\(B\)的每次读取会计算一次浮点乘法与浮点加法,因此计算强度为1——两次浮点运算除以两次数据读取。之前的版本是每个线程负责处理矩阵\(C\)的一个元素——计算矩阵\(A\)的一行与矩阵\(B\)的一列的内积,可以通过使每个线程计算\(C\)更多的元素——计算矩阵\(A\)的多行与矩阵\(B\)的多列的内积——从而提升计算强度。具体地,如果在\(K\)次循环的内积计算中一次读取矩阵\(A\)中的\(m\)个元素和矩阵\(B\)中的\(n\)个元素,那么访存指令为\(m+n\)条,而计算指令为\(2mn\)条,所以计算强度为\(\frac{2mn}{m+n}\),因此可以很容易发现提高\(m\)和\(n\)会带来计算强度的提升。
在上一小节中对全局内存的访问与存储都是借助 float 指针完成的,具体到硬件指令集上实际是使用指令 LDG.E 与 STG.E 完成的。可以使用128位宽指令LDG.E.128 与 STG.E.128 一次读取多个 float 数。使用宽指令的好处是一方面简化了指令序列,使用一个宽指令代替四个标准指令可以节省十几个指令的发射周期,这可以为计算指令的发射争取到额外的时间;另一方面128比特正好等于一个cache line的长度,使用宽指令也有助于提高cache line的命中率。但并不提倡在一切代码中过度追求宽指令的使用,开发者应当将更多的时间关注并行性设计和局部数据复用等更直接的优化手段。
具体的实现如下,由于每个 float 类型大小为32个比特,可以将4个 float 堆叠在一起构成一个128比特的 float4 类,对 float4 的访存将会是使用宽指令完成。其具体代码实现见util.cuh中。
在实现GPU核函数过程中要注意,每个线程需要从原本各读取矩阵\(A\)和矩阵\(B\)中一个 float 数据变为各读取4个 float 数据,这就要求现在每个线程负责处理矩阵\(C\)中\(4\times 4\)的矩阵块,称之为 thread tile 。如 图7.4.2所示,每个线程从左到右、从上到下分别读取矩阵\(A\)和矩阵\(B\)的数据并运算,最后写入到矩阵\(C\)中。
图7.4.2 提高计算强度
完整代码见gemm_use_128.cu。我们可以进一步让每个线程处理更多的数据,从而进一步提升计算强度,如 图7.4.3所示。完整代码见gemm_use_tile.cu。
图7.4.3 通过提高线程所处理矩阵块的数量来进一步提高计算强度
测试得到以下结果:
Max Error: 0.000092
Average Time: 6.232 ms, Average Throughput: 1378.317 GFLOPS
使用分析工具Nsight Compute分析取得性能提升的具体原因。Nsight Compute是英伟达发布的主要针对GPU核函数的性能分析工具,它通过劫持驱动的方式对GPU底层数据采样和输出。可以使用以下指令进行性能分析:
bash
ncu --set full -o <profile_output_file> <profile_process>
--set full 代表采样所有数据, -o 代表以文件的形式输出结果; <profile_output_file> 填输出文件名但注意不要加后缀名, <profile_process> 填待分析的可执行文件及其参数。
比如需要分析 first_attempt ,将输出结果命名为 first_attepmt_prof_result 可以使用以下指令:
ncu --set full -o first_attepmt_prof_result ./first_attempt
如果提示权限不足可以使在指令前加sudo 。
在得到输出文件之后,可以使用 nv-nsight-cu 查看文件。对改动的GPU核函数与上一版本的GPU核函数进行对比分析,发现:
首先 LDG 指令数量下降了84%,且指标 Stall LG Throttle 下降33%,说明使用宽指令增加计算密度确实可以通过减少全局内存访问的指令数目而减少发射等待时间。最后指标 Arithmetic Intensity 的提升也和之前的关于计算强度的分析相吻合。
我们对gemm_use_tile.cu测试得到以下结果:
Max Error: 0.000092
Average Time: 3.188 ms, Average Throughput: 2694.440 GFLOPS
使用Nsight Compute分析发现:类似地,本次优化在 Stall LG Throttle 等指标上取得了进一步的提升。
使用共享内存缓存复用数据
虽然令一个线程一次读取更多的数据能取得计算强度的提升进而带来性能的提升,但是这种令单个线程处理数据增多的设计会导致开启总的线程数量减少,进而导致并行度下降,因此需要使用其他硬件特性在尽可能不影响并行度的前提下取得性能提升。在之前的代码中,开启若干个线程块,每个线程块处理矩阵\(C\)中的一个或多个矩阵块。在 图7.4.4 中,可以观察到,处理矩阵\(C\)同一行的线程\(x, y\)会读取矩阵\(A\)中相同的数据,可以借助共享内存让同一个线程块中不同的线程读取不重复的数据而提升程序吞吐量。
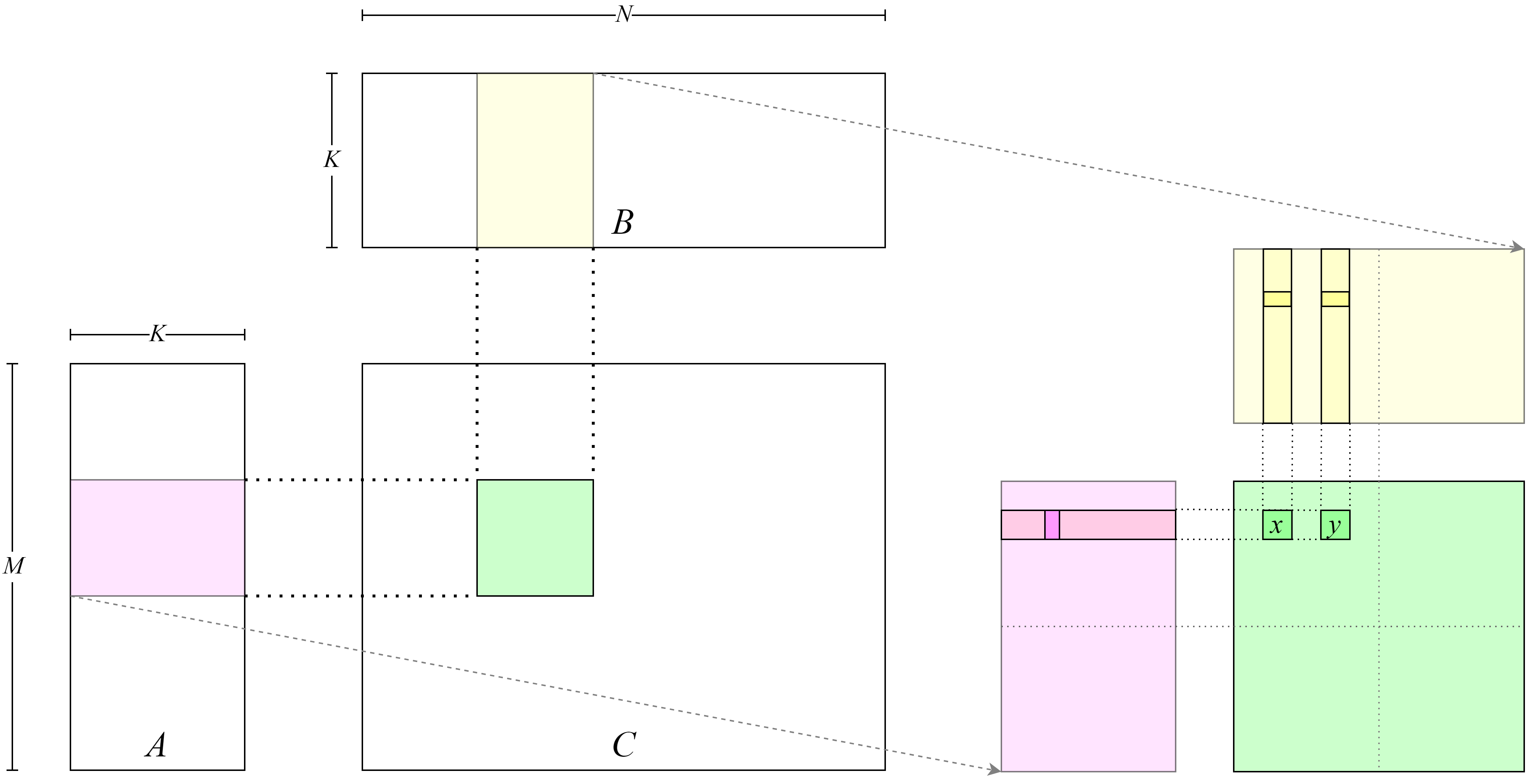
图7.4.4 线程间重复读取数据
具体地,需要对代码进行如下改造:首先此前代码在计算内积过程是进行\(K\)次循环读取数据并累加计算,在此设定下每次循环中处理矩阵\(C\)中相同行的线程会读取相同的矩阵\(A\)的数据,处理矩阵\(C\)中相同列的线程会读取相同的矩阵\(B\)的数据。可以通过将此\(K\)次循环拆解成两层循环,外层循环\(\frac{K}{tileK}\)次,每次外层循环的迭代读取一整块数据,内层循环\(tileK\)次进行累加数据。数据从全局内存向共享内存的搬运过程如图 图7.4.5 所示,每次内层循环开始前将矩阵\(A\)和矩阵\(B\)中一整个 tile 读取到共享内存中;数据从共享内存到寄存器的搬运如图 图7.4.6 所示,每次内层循环循环从共享内存读取数据并计算。这种设计带来的好处是,可以让每个线程不必独自从全局内存读取所有需要的数据,整个线程块将共同需要的数据从全局内存中读取并写入到共享内存中,此后每个线程在计算过程中只需要从共享内存中读取所需要的数据即可。
图7.4.5 向共享内存中写入数据
图7.4.6 从共享内存中读取数据
完整代码见gemm_use_smem.cu。
测试得到以下结果:
Max Error: 0.000092
Average Time: 0.617 ms, Average Throughput: 13925.168 GFLOPS
通过使用Nsight Compute对核函数分析并与上一个核函数进行对比,可以观察到一些主要的变化:首先 LDG 指令数量下降了97%,与此前设计相吻合。同时观察到 SM Utilization 提升了218%也可以侧面证实使用共享内存减少了内存访问延迟从而提升了利用率,此外还可以观察到各项指标如 Pipe Fma Cycles Active 等都有显著提升,这都能充分解释了使用共享内存的改进是合理且有效的。
减少寄存器使用
可以注意到在向共享内存中存储矩阵\(A\)的数据块是按照行优先的数据排布进行的,而对此共享内存的读取是逐行读取的。可以将矩阵\(A\)的数据块在共享内存中数据按照列优先的形式排布,这样可以减少循环及循环变量从而带来寄存器使用数量减少进而带来性能提升。
完整代码见gemm_transpose_smem.cu。
测试得到以下结果:
Max Error: 0.000092
Average Time: 0.610 ms, Average Throughput: 14083.116 GFLOPS
使用Nsight Compute分析有以下观察发现主要的变化:Occupancy 提升1.3%,而带来此提升的原因是寄存器使用111个,相比上一个GPU核函数使用128个寄存器减少了17个,从而带来了性能提升。但这个变化会因为GPU架构不同导致有不同的变化,同时可以观察到 STS 指令数量提升且带来一些 bank confilct ,因此在其他GPU架构上此改动可能不会带来正面影响。
隐藏共享内存读取延迟
在GPU中使用指令 LDS 读取共享内存中的数据,在这条指令发出后并不会等待数据读取到寄存器后再执行下一条语句,只有执行到依赖 LDS 指令读取的数据的指令时才会等待读取的完成。而在上一小节中,在内层\(tileK\)次循环中,每次发射完读取共享内存的指令之后就会立即执行依赖于读取数据的数学运算,这样就会导致计算单元等待数据从共享内存的读取,如 图7.4.7 所示。事实上,对共享内存的访问周期能多达几十个时钟周期,而计算指令的执行往往只有几个时钟周期,因此通过一定方式隐藏对共享内存的访问会取得不小的收益。可以通过重新优化流水线隐藏一定的数据读取延迟。如图 图7.4.8 所示,可以在内层的\(tileK\)次循环中每次循环开始时读取发射下一次内层循环数据的读取指令。由于在执行本次运算时计算指令并不依赖于下一次循环的数据,因此计算过程不会等待之前发出的读取下一次内层循环数据的指令。
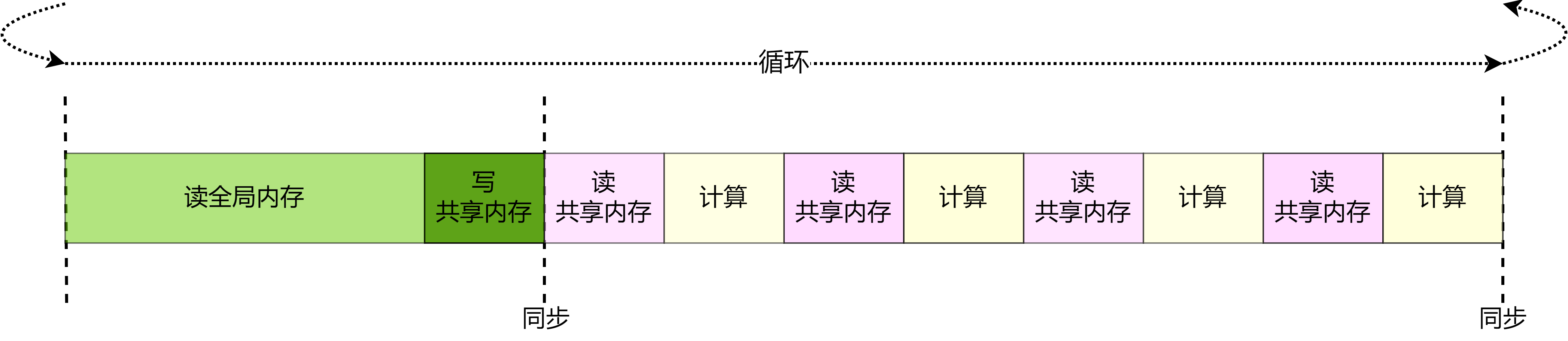
图7.4.7 上一个GPU核函数的流水线
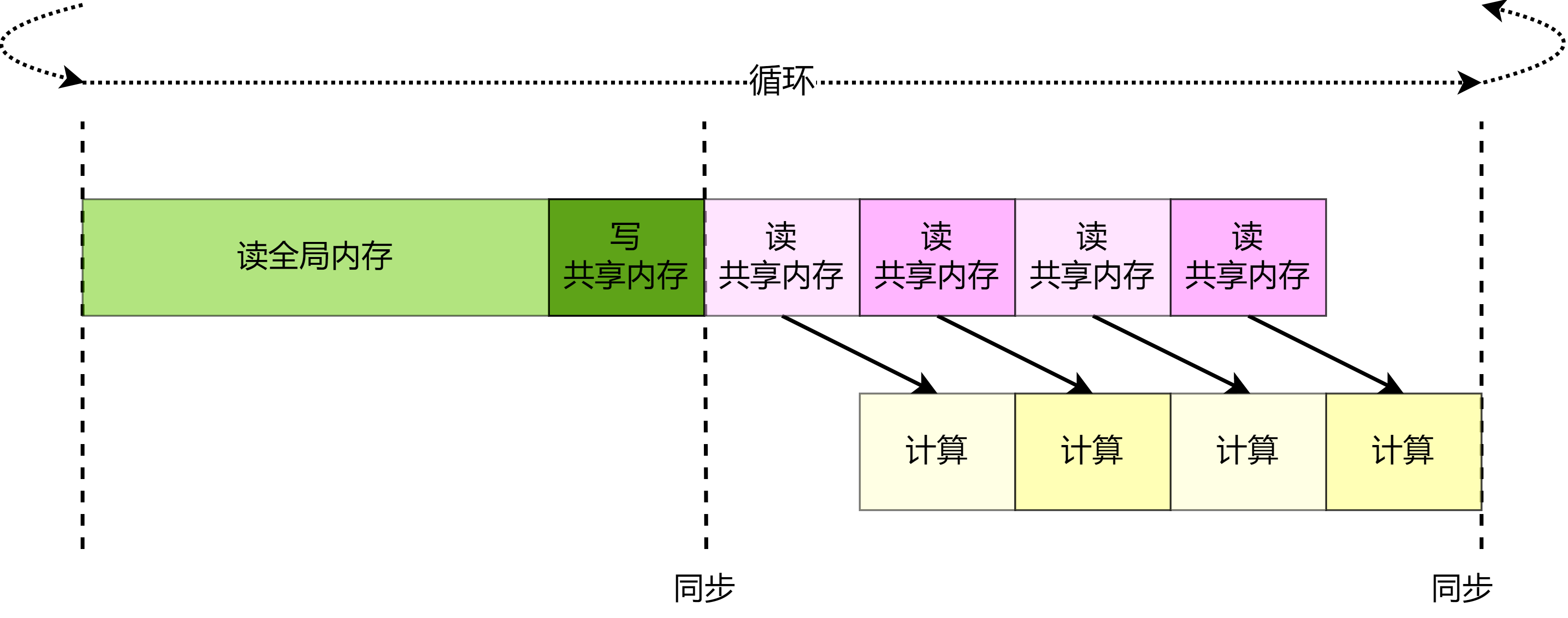
图7.4.8 隐藏共享内存读取延迟的流水线
完整代码见gemm_hide_smem_latency.cu。
测试得到以下结果:
Max Error: 0.000092
Average Time: 0.585 ms, Average Throughput: 14686.179 GFLOPS
使用Nsight Compute观察发现:相比上一个GPU核函数,指标 Stall Short Scoreboard 减少了67%。而此前提过GPU内存读写指令发出后并不会等待数据读取到寄存器后再执行下一条语句,但是会在Scoreboard设置符号并在完成读取后置回符号,等到之后有数据依赖的指令执行前会等待Scoreboard中符号的置回。所以这里 Stall Short Scoreboard 的减少充分说明了内存延迟是有效的。
隐藏全局内存读取延迟
上一小节中介绍了对共享内存读取流水线优化的方法,事实上,GPU再读取全局内存中使用的指令 LDG 也有与共享内存读取指令 LDS 类似的行为特性。因此类似的在\(\frac{K}{tileK}\)次外层循环中每次循环开始时发出下一次外层循环需要的矩阵\(A\)中的数据块的读取指令,而本次外循环的整个内层循环过程中不依赖下一次外循环的数据,因此本次外循环的内循环过程中不会等待对下一次外层循环需要的矩阵\(A\)中的数据块的读取指令完成,从而实现隐藏全局内存读取延迟的目的。具体流水线可视化见 图7.4.9 。
上一小节中介绍了对共享内存读取流水线优化的方法,事实上,GPU在读取全局内存中使用的指令 LDG 也有与共享内存读取指令 LDS 类似的行为特性。因此类似的在\(\frac{K}{tileK}\)次外层循环中每次循环开始时发出下一次外层循环需要的矩阵\(A\)中的数据块的读取指令,而本次外循环的整个内层循环过程中不依赖下一次外循环的数据,因此本次外循环的内循环过程中不会等待对下一次外层循环需要的矩阵\(A\)中的数据块的读取指令完成,从而实现隐藏全局内存读取延迟的目的。此外,可以让内层循环先执行\(tileK - 1\)次,在最后一次执行前将 buffer 中的数据写入 tile ,其后再执行内层循环的最后一次迭代,这样能更进一步隐藏向 tile 写入的内存延迟。具体流水线可视化见图 图7.4.9 。
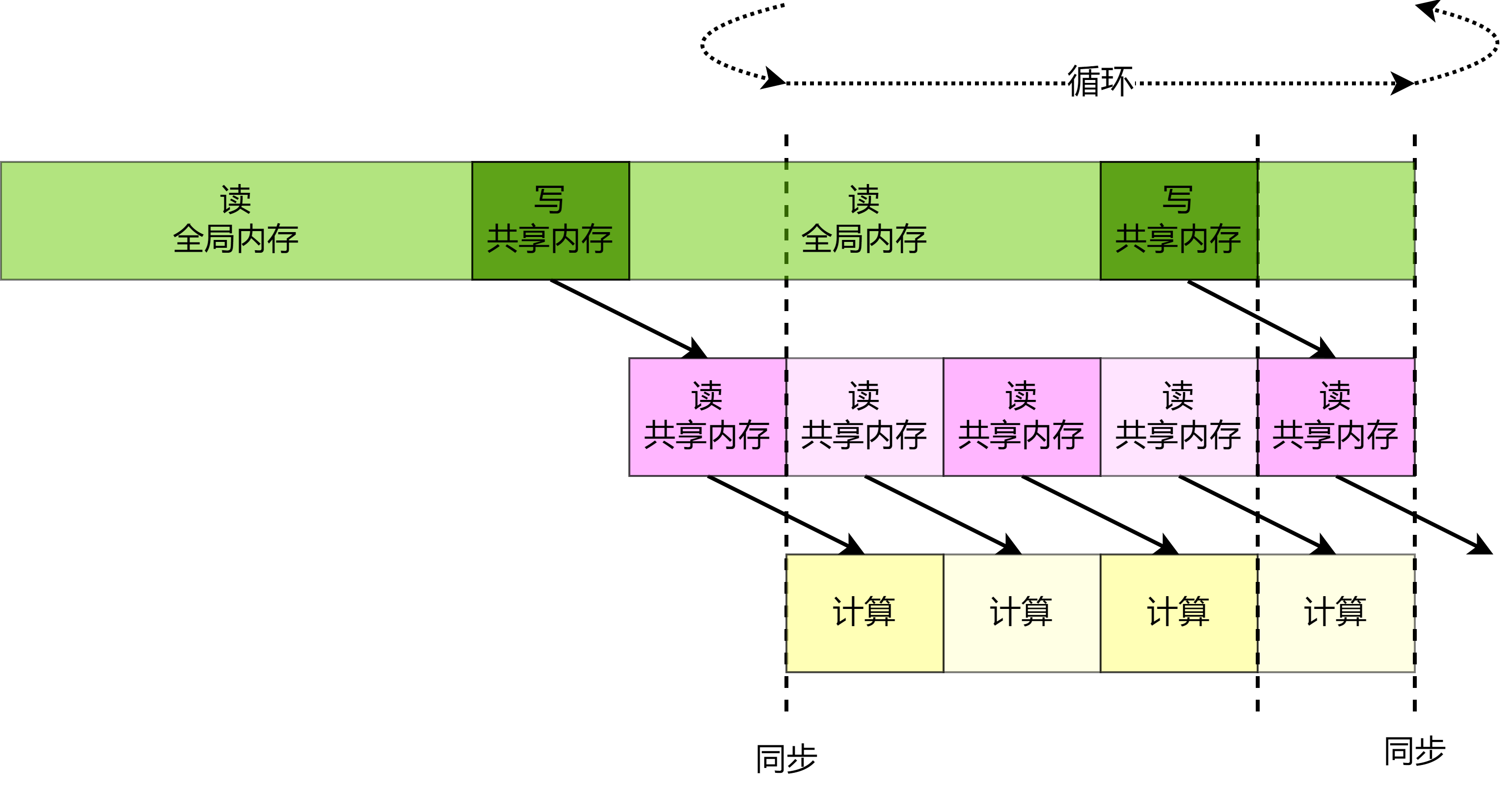
图7.4.9 隐藏全局内存读取延迟的流水线
完整代码见gemm_final.cu。
测试得到以下结果:
Max Error: 0.000092
Average Time: 0.542 ms, Average Throughput: 15838.302 GFLOPS
使用Nsight Compute分析可以观察到指标 Stall Long Scoreboard 减少了67%,与上一小结的 Stall Short Scoreboard 概念相对应,Stall Long Scoreboard 主要是针对全局内存的指标。该指标的显著减少充分说明预取数据可以在一定程度上隐藏全局内存的读取。
与cuBLAS对比
按照节 sec-accelerator-use-cublas 中介绍的cuBLAS的接口使用方法,可以很容易地写出代码使用cuBLAS完成矩阵乘法,如代码 practise-cublas 所示。
void cublasGemm(const float *A, const float *B, float *C, float alf, float bet, int M, int N, int K) {
int lda = N, ldb = K, ldc = N;
const float *alpha = &alf;
const float *beta = &bet;
cublasHandle_t handle;
cublasCreate(&handle);
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, M, K, alpha, B, lda, A, ldb, beta, C, ldc);
cublasDestroy(handle);
}
需要注意的是cuBLAS默认矩阵在GPU中是按列优先存储的,而我们的矩阵是按行优先存储的,而两者可以通过转置相互转换,所以\(A\times B = (B^T\times A^T)^T\),因此在输入时需要调整矩阵的顺序,即可保证输出结果仍是行优先矩阵。
测试得到以下结果:
Max Error: 0.000092
Average Time: 0.613 ms, Throughput: 14002.600 GFLOPS
使用Nsight Compute分析发现 LDG 和 STS 等指令使用较多,导致指令发射压力较大,具体体现在 Stall Wait 与 Stall Dispatch Stall 指标相比较差。但其他指标诸如 Stall Long Scoreboard 等cuBLAS更优,但总体上我们略胜一筹。
尽管我们的代码相比cuBLAS已经取得了一定的性能提升,但是需要强调的是cuBLAS内部为各种不同的矩阵尺寸以及不同的设备实现了若干不同的GPU核函数,我们实现的核函数在其他尺寸或其他设备设备上性能可能无法取得此加速比。
小结
要实现一个高性能算子需要依照硬件特性适应性进行若干优化。本节优化策略可总结为以下几点:
-
并行资源映射——提高并行性:将多层级的并行资源(
block、warp、thread)与对应需要计算和搬移的数据建立映射关系,提高程序并行性。将可并行的计算和数据搬移操作映射到并行资源上,对于广义矩阵乘法实例,在 sec-accelerator-naive朴素实现的例子中,令每个block与矩阵\(C\)中的一个矩阵块建立映射关系,每个thread与矩阵块中的一个元素建立映射关系。 -
优化内存结构——减小访存延迟:观察计算过程中同一个
block中数据复用的情况,将复用的数据被如共享内存、寄存器等高性能体系结构存储下来,以此提高吞吐量。如在 sec-accelerator-naive 中将矩阵\(A\)与矩阵\(B\)中会被同一个block内不同thread共同访问的数据缓存到共享内存中。 -
优化指令执行——减小指令发射开销:使用
#pragma unroll功能进行循环展开来提升指令级并行,减少逻辑判断;使用向量化加载指令以提高带宽等,对于Ampere架构,最大向量化加载指令为LDG.E.128,可以采用float4类型的数据进行读取。 -
优化访存流水线——隐藏访存延迟:在进行内存结构变化(矩阵数据搬移)时,可以优化访存流水线,在数据搬移的间隔执行计算操作以隐藏数据搬移的延迟。
总结
总结
-
面向深度学习计算任务,加速器通常都是由多种片上缓存以及多种运算单元组成来提升性能。
-
未来性能增长需要依赖架构上的改变,即需要利用可编程的硬件加速器来实现性能突破。
-
出于计算效率和易用性等原因,加速器一般会具有多个等级的编程方式,包括:算子库层级,编程原语层级和指令层级。
-
越底层的编程方式越能够灵活地控制加速器,但同时对程序员的能力要求也越高。
扩展阅读
数据处理框架
在前两个章节中,我们介绍了编译器前后端的相关内容,详细地阐述了源程序到目标程序的转换优化过程。除了让芯片在训练/推理过程中高性能地运行,我们还需要将数据高效地发送给芯片,以实现全流程的性能最优。机器学习模型训练和推理需要从存储设备(如本地磁盘和内存、远端的存储系统等)中加载数据集,对数据集进行一系列处理变换,将处理结果发送到GPU或者华为昇腾Ascend等加速器中完成模型计算,该流程的任何一个步骤出现性能问题都会对训练和推理的吞吐率造成负面影响。本章我们将核心介绍如何设计、并实现一个面向机器学习场景的数据系统,以帮助用户轻松构建各种复杂的数据处理流水线(Data Pipeline),同时我们的数据系统要有足够高的执行性能,以确保数据预处理步骤不会成为模型训练和推理的性能瓶颈。
本章主要从易用性、高效性和保序性三个维度展开介绍机器学习系统中的数据模块。在前两个小节中,我们首先讨论如何构建一个易用的数据模块。包括如何设计编程抽象,使得用户通过短短几行代码便可以描述一个复杂的预处理过程;以及如何做到既内置丰富算子提升易用性,又可以灵活支持用户使用自定义算子覆盖长尾需求。用户构建好数据处理流程后,数据模块需要负责高效的调度执行数据流水线,以达到最优的数据处理吞吐率。高效的执行数据流水线是一个具有挑战性的任务,我们既要面临数据读取部分的I/O性能问题,又要解决数据处理部分的计算性能问题。针对上述挑战,我们将分别介绍面向高吞吐率读取性能的数据文件格式设计,以及能够充分发挥多核CPU算力的并行架构设计。不仅如此,和常规数据并行计算任务不同的是,大部分机器学习场景对于数据的输入输出顺序有着特殊的保序性的要求,我们将会使用一节的内容来介绍什么是保序性,以及如何在数据模块的并行架构中设计相应组件计来满足该特性需求。学习了上述的内容后,读者将会对如何构建一个面向机器学习场景高效易用的数据模块有深刻的理解。最后,作为拓展内容,我们将以目前学术界和业界的一些实践经验来介绍当单机处理性能达不到要求时,该如何去扩展我们的数据处理模块以满足训练性能需求。本章学习目标包括:
-
了解机器学习数据模块架构中的关键组件及其功能
-
了解不同数据模块用户编程接口的设计
-
掌握面向高性能数据读取的数据文件格式设计
-
掌握机器学习系统数据模块并行架构
-
掌握机器学习系统数据模块数据保序性含义及其解决方案
-
了解两种单机数据处理性能扩展方案
概述
概述
机器学习场景中的数据处理是一个典型的ETL(Extract, Transform, Load)过程,第一个阶段(Extract)需要从存储设备中加载数据集,第二个阶段(Transform)完成对数据集的变换处理。虽然不同的机器学习系统在构建数据模块时采用了不同的技术方案,但其核心都会包含数据加载、数据混洗、数据变换、数据mini-batch组装以及数据发送等关键组件。其中每个组件的功能介绍如下所示:
-
数据加载组件(Load):负责从存储设备中加载读取数据集,需要同时考虑存储设备的多样性(如本地磁盘/内存,远端磁盘和内存等)和数据集格式的多样性(如csv格式,txt格式等)。根据机器学习任务的特点,AI框架也提出了统一的数据存储格式(如谷歌TFRecord, 华为MindRecord等)以提供更高性能的数据读取。
-
数据混洗组件(Shuffle):负责将输入数据的顺序按照用户指定方式随机打乱,以提升模型的鲁棒性。
-
数据变换组件(Map):负责完成数据的变换处理,内置面向各种数据类型的常见预处理算子,如图像中的尺寸缩放和翻转,音频中的随机加噪和变调、文本处理中的停词去除和随机遮盖(Mask)等。
-
数据组装组件(Batch):负责组装构造一个批次(mini-batch)的数据发送给训练/推理。
-
数据发送组件(Send):负责将处理后的数据发送到GPU/华为昇腾Ascend等加速器中以进行后续的模型计算和更新。高性能的数据模块往往选择将数据向设备的搬运与加速器中的计算异步执行,以提升整个训练的吞吐率。
图8.1.1 数据模块的核心组件
实现上述的组件只是数据模块的基础,我们还要对如下方面进行重点设计:
易用性
AI模型训练/推理过程中涉及到的数据处理非常灵活:一方面,不同的应用场景中数据集类型千差万别,特点各异,在加载数据集时,数据模块要支持图像、文本、音频、视频等多种类型的特定存储格式,还要支持内存、本地磁盘、分布式文件系统以及对象存储系统等多种存储设备类型,模块需要对上述复杂情况下数据加载中的IO差异进行抽象统一,减少用户的学习成本。另一方面,不同的数据类型往往也有着不同的数据处理需求。现有常见机器学习任务中,图像任务常常对图像进行缩放、翻转、模糊化等处理,文本任务需要对文本进行切分、向量化等操作,而语音任务需要对语音进行快速傅立叶变换、混响增强、变频等预处理。为帮助用户解决绝大部分场景下的数据处理需求,数据模块需要支持足够丰富的面向各种类型的数据预处理算子。然而新的算法和数据处理需求在不断快速涌现,我们需要支持用户在数据模块中方便的使用自定义处理算子,以应对数据模块未覆盖到的场景,达到灵活性和高效性的最佳平衡。
高效性
由于GPU/华为昇腾Ascend等常见AI加速器主要面向Tensor数据类型计算,并不具备通用的数据处理能力,现有主流机器学习系统数据模块通常选择使用CPU进行数据流水线的执行。理想情况下,在每个训练迭代步开始之前,数据模块都需要将数据准备好、以减少加速器因为等待数据而阻塞的时间消耗。然而数据流水线中的数据加载和数据预处理常常面临着具有挑战性的I/O性能和CPU计算性能问题,数据模块需要设计具备支持随机读取且具备高读取吞吐率的文件格式来解决数据读取瓶颈问题,同时还需要设计合理的并行架构来高效的执行数据流水线,以解决计算性能问题。为达到高性能的训练吞吐率,主流机器学习系统均采用数据处理与模型计算进行异步执行,以掩盖数据预处理的延迟。
保序性
和常规的数据并行计算任务所不同的是,机器学习模型训练对数据输入顺序敏感。使用随机梯度下降算法训练模型时,通常在每一轮需要按照一种伪随机顺序向模型输入数据,并且在多轮训练(Epoch)中每一轮按照不同的随机顺序向模型输入数据。由于模型最终的参数对输入数据的顺序敏感,为了帮助用户更好的调试和确保不同次实验的可复现性,我们需要在系统中设计相应机制使得数据最终送入模型的顺序由数据混洗组件的数据输出顺序唯一确定,不会由于并行数据变换而带来最终数据模块的数据输出顺序不确定。我们将在后文中对于保序性的要求和具体实现细节展开探讨。
易用性设计
易用性设计
本节我们主要介绍如何设计一个易用的机器学习系统数据模块。正如前文所言,易用性既要求数据模块提供好的编程抽象和接口使得用户可以方便的构建一个数据处理流水,同时还要支持用户灵活地在数据流水中注册使用自定义算子以满足丰富多变的特殊需求,接下来我们将从编程接口抽象和自定义算子注册机制两个方面来展开探讨。
编程抽象与接口
图8.2.1 我们展示的是一个训练图片分类模型的经典数据预处理流水线。我们从存储设备中加载数据集后,对数据集中的图片数据进行解码、缩放、旋转、正规化、通道变换等一系列操作,对数据集的标签也进行特定的预处理操作,最终将处理好的数据发送到芯片上进行模型的计算。我们希望数据模块提供的编程抽象具备足够高的层次,以使得用户可以通过短短几行代码就能描述清楚数据处理的逻辑,不需要陷入过度的、重复的数据处理实现细节当中。同时又要确保这一套高层次的抽象具备足够通用性,以满足多样的数据预处理需求。在我们得到一个好的编程抽象后,我们将会以基于MindSpore的数据模块提供的编程接口实现下图所描述的数据预处理流水线的代码片段为例子来展示一个优秀的编程抽象对用户编程负担的减轻是有多么大的作用。
图8.2.1 数据预处理示例
事实上,面向数据计算的编程抽象早已在通用数据并行计算系统领域中被广泛的研究并取得了相对统一的共识——那就是提供类LINQ式 [1] 的编程抽象,其最大的特点是让用户专注于描述基于数据集的生成与变换,而将这些操作的高效实现与调度执行交由数据系统的运行时负责。一些优秀的系统如Naiad [2], Spark [3], DryadLINQ [4]等都采用了这种编程模型。我们以Spark为例子进行简要介绍。
Spark向用户提供了基于弹性分布式数据集(Resilient Distributed Dataset, RDD)概念的编程模型。一个RDD是一个只读的分布式数据集合,用户通过Spark的编程接口来主要描述RDD的创建及变换过程,我们以一个Spark示例进行展开讨论。下面展示了一段在一个日志文件中统计包含ERROR字段的行数的Spark代码,我们首先通过文件读取创建一个分布式的数据集file(前文提到RDD表示数据的集合,这里的file实际上是日志行的数据集合)。 我们对这个file数据集进行filter(过滤)运算得到新的只保留包含ERROR字段的日志行的数据集errs,接着我们对errs中的每一个数据进行map(映射)操作得到数据集ones,最后我们对ones数据集进行reduce操作得到了我们最终想要的统计结果,即file数据集中包含ERROR字段的日志行数。
val file = spark.textFile("hdfs://...")
val errs = file.filter(_.contains("ERROR"))
val ones = errs.map(_ => 1)
val count = ones.reduce(_+_)
我们发现用户只需要四行代码就完成了在这样一个分布式的数据集中统计特定字段行数的复杂任务,这得益于Spark核心的RDD编程抽象,从 图8.2.2的计算流程可视化中我们也可以清晰的看到用户在创建数据集后,只需要描述在数据集上的作用算子即可,至于算子的执行和实现则由系统的运行时负责。
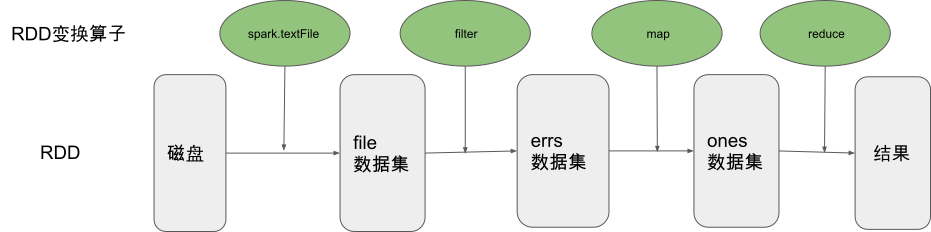
图8.2.2 Spark编程核心------RDD变换
主流机器学习系统中的数据模块同样也采用了类似的编程抽象,如TensorFlow的数据模块tf.data [5], 以及MindSpore的数据模块MindData等。接下来我们以MindData的接口设计为例子来介绍如何面向机器学习这个场景设计好的编程抽象来帮助用户方便的构建模型训练中多种多样的数据处理流水线。MindData是机器学习系统MindSpore的数据模块,主要负责完成机器学习模型训练中的数据预处理任务,MindData向用户提供的核心编程抽象为基于Dataset(数据集)的变换处理。这里的Dataset是一个数据帧的概念(Data Frame),即一个Dataset为一个多行多列,且每一列都有列名的关系数据表。

- 基于这样一个编程模型,结合我们在第一节中介绍的机器学习数据流程中的关键处理流程,MindData为用户提供了对数据集进行shuffle、map、batch等变换操作的数据集操作算子,这些算子接收一个Dataset作为输入,并以一个新处理生成的Dataset作为结果输出,我们列举典型的数据集变换接口如下:
-
MindSpore支持的数据集操作接口
| 数据集操作 | 含义解释 |
|---|---|
| batch | 将数据集中的多行数据项组成一个mini-batch |
| map | 对数据集中的每行数据进行变换操作 |
| shuffle | 随机打乱数据集中的数据行的顺序 |
| filter | 对数据集的数据行进行过滤操作,只保留通过过滤条件的数据行 |
| prefetch | 从存储介质中预取数据集 |
| project | 从Dataset数据表中选择一些列用于接下来的处理 |
| zip | 将多个数据集合并为一个数据集 |
| repeat | 多轮次训练中,重复整个数据流水多次 |
| create_dict_iterator | 对数据集创建一个返回字典类型数据的迭代器 |
| … | … |
上述描述了数据集的接口抽象,而对数据集的具体操作实际上是由具体的数据算子函数定义。为了方便用户使用,MindData对机器学习领域常见的数据类型及其常见数据处理需求都内置实现了丰富的数据算子库。针对视觉领域,MindData提供了常见的如Decode(解码)、Resize(缩放)、RandomRotation(随机旋转)、Normalize(正规化)以及HWC2CHW(通道转置)等算子;针对文本领域,MindData提供了Ngram、NormalizeUTF8、BertTokenizer等算子;针对语音领域,MindData提供了TimeMasking(时域掩盖)、LowpassBiquad(双二阶滤波器)、ComplexNorm(归一化)等算子;这些常用算子能覆盖用户的绝大部分需求。
除了支持灵活的Dataset变换,针对数据集种类繁多、格式与组织各异的难题,MindData还提供了灵活的Dataset创建,主要分为如下三类:
-
通过内置数据集直接创建:MindData内置丰富的经典数据集,如CelebADataset、Cifar10Dataset、CocoDataset、ImageFolderDataset、MnistDataset、VOCDataset等。如果用户需要使用这些常用数据集,可通过一行代码即可实现数据集的开箱使用。同时MindData对这些数据集的加载进行了高效的实现,以确保用户能够享受到最好的读取性能。
-
从MindRecord中加载创建:MindRecord为MindData设计的一种高性能通用数据存储文件格式,用户可将数据集转换为MindRecord后借助MindSpore的相关API进行高效的读取。
-
从Python类创建:如果用户已经有自己数据集的Python读取类,那么可以通过MindData的GeneratorDataset接口调用该Python类实现Dataset的创建,这给用户提供了极大的自由度。
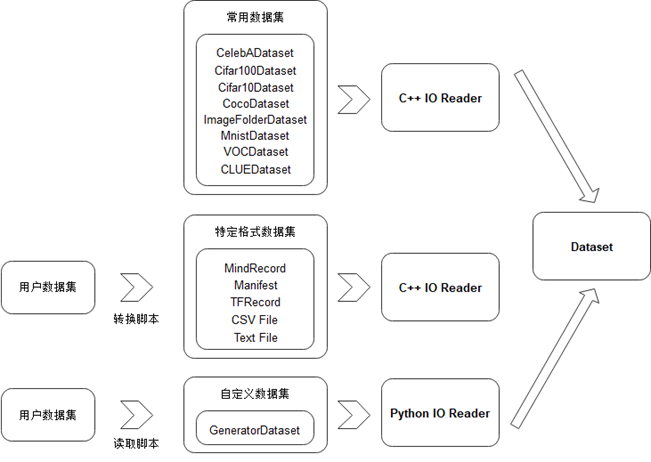
最后我们以一个基于MindData实现我们本节开篇所描述的数据处理流水线为例子来展示以Dataset为核心概念的数据编程抽象是多么的用户友好。我们只需要短短10余行代码即可完成我们所期望的复杂数据处理,同时在整个过程中,我们只专注于逻辑的描述,而将算子的实现和算子执行流程交由数据模块负责,这极大的减轻了用户的编程负担。
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as c_transforms
import mindspore.dataset.transforms.vision.c_transforms as vision
dataset_dir = "path/to/imagefolder_directory"
# create a dataset that reads all files in dataset_dir with 8 threads
dataset = ds.ImageFolderDatasetV2(dataset_dir, num_parallel_workers=8)
#create a list of transformations to be applied to the image data
transforms_list = [vision.Decode(),
vision.Resize((256, 256)),
vision.RandomRotation((0, 15)),
vision.Normalize((100, 115.0, 121.0), (71.0, 68.0, 70.0)),
vision.HWC2CHW()]
onehot_op = c_transforms.OneHot(num_classes)
# apply the transform to the dataset through dataset.map()
dataset = dataset.map(input_columns="image", operations=transforms_list)
dataset = dataset.map(input_columns="label", operations=onehot_op)
自定义算子支持
有了基于数据集变换的编程抽象、以及针对机器学习各种数据类型的丰富变换算子支持,我们可以覆盖用户绝大部分的数据处理需求。然而由于机器学习领域本身进展快速,新的数据处理需求不断涌现,可能会有用户想要使用的数据变换算子没有被数据模块覆盖支持到的情况发生。为此我们需要设计良好的用户自定义算子注册机制,使得用户可以方便在构建数据处理流水线时使用自定义的算子。
机器学习场景中,用户的开发编程语言以Python为主,所以我们可以认为用户的自定义算子更多情况下实际上是一个Python函数或者Python类。数据模块支持自定义算子的难度主要与数据模块对计算的调度实现方式有关系,比如Pytorch的dataloader的计算调度主要在Python层面实现,得益于Python语言的灵活性,在dataloader的数据流水中插入自定义的算子相对来说比较容易;而像TensorFlow的tf.data以及MindSpore的MindData的计算调度主要在C++层面实现,这使得数据模块想要灵活的在数据流中插入用户定义的Python算子变得较为有挑战性。接下来我们以MindData中的自定义算子注册使用实现为例子展开讨论这部分内容。
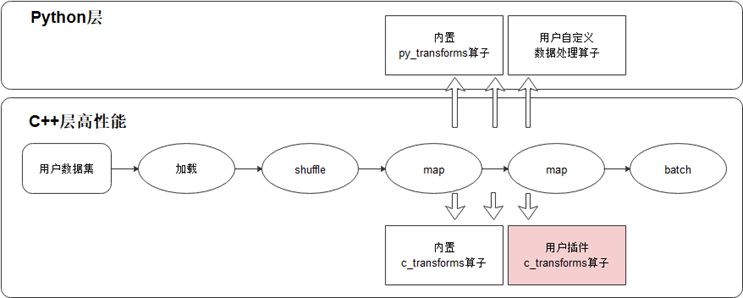
图8.2.3 MindData的C层算子和Python层算子
MindData中的数据预处理算子可以分为C层算子以及Python层算子,C层算子能提供较高的执行性能而Python层算子可以很方便借助丰富的第三方Python包进行开发。为了灵活地覆盖更多场景,MindData支持用户使用Python开发自定义算子,如果用户追求更高的性能,MindData也支持用户将开发的C层算子编译后以插件的形式注册到MindSpore的数据处理中进行调用。
对于用户传入map、filter等数据集变换算子中的自定义数据处理算子,MindData的Pipeline启动后会通过创建的Python运行时来执行。需要指出的是自定义的Python算子需要保证输入、输出均是numpy.ndarray类型。具体执行过程中,当MindData的Pipeline的数据集变换中执行用户自定义的PyFunc算子时,会将输入数据以numpy.ndarray的类型传递给用户的PyFunc,自定义算子执行完毕后再以numpy.ndarray返回给MindData,在此期间,正在执行的数据集变换算子(如map、filter等)负责该PyFunc的运行时生命周期及异常判断。如果用户追求更高的性能,MindData也支持用户自定义C算子。dataset-plugin仓(插件仓) 为MindData的算子插件仓,囊括了为特定领域(遥感,医疗,气象等)量身制作的算子,该仓承载MindData的插件能力扩展,为用户编写MindData的新算子提供了便捷易用的入口,用户通过编写算子、编译、安装插件步骤,然后就可以在MindData Pipeline的map操作中使用新开发的算子。
图8.2.4 MindSpore自定义算子注册
参考文献
- Meijer, Erik and Beckman, Brian and Bierman, Gavin. Linq: reconciling object, relations and xml in the. net framework. Proceedings of the 2006 ACM SIGMOD international conference on Management of data. 2006. ↩
- Murray, Derek G and McSherry, Frank and Isaacs, Rebecca and Isard, Michael and Barham, Paul and Abadi, Mart\'\in. Naiad: a timely dataflow system. Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 2013. ↩
- Zaharia, Matei and Chowdhury, Mosharaf and Franklin, Michael J and Shenker, Scott and Stoica, Ion. Spark: Cluster computing with working sets. 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10). 2010. ↩
- Fetterly, Yuan Yu Michael Isard Dennis and Budiu, Mihai and Erlingsson, Ulfar and Currey, Pradeep Kumar Gunda Jon. DryadLINQ: A system for general-purpose distributed data-parallel computing using a high-level language. Proc. LSDS-IR. 2009. ↩
- Murray, Derek G and Simsa, Jiri and Klimovic, Ana and Indyk, Ihor. tf. data: A machine learning data processing framework. arXiv preprint arXiv:2101.12127. 2021. ↩
高效性设计
高效性设计
在上一节中我们重点介绍了数据模块的编程抽象以及编程接口设计,确保用户可以方便的基于我们提供的API描述数据处理流程而不需要过多关注实现和执行细节。那么本节我们将进一步探究数据加载以及流水线调度执行等数据模块关键部分设计细节以确保用户能够拥有最优的数据处理性能。同时在本节内容中,我们也会贯穿现有主要机器学习系统的实践经验以帮助读者加深对这些关键设计方案的理解。
如 图8.3.1 所示,深度学习模型训练需要借助数据模块首先从存储设备中加载数据集,在内存中进行一系列的预处理变换,最终将处理好的数据集发送到加速器芯片上执行模型的计算,目前有大量的工作都着重于研究如何通过设计新的硬件或者应用算子编译等技术加速芯片上的模型计算,而在数据处理流水的性能问题上鲜有涉及。但事实上很多情况下,数据预处理的执行时间往往在整个训练任务中占据着相当大的比例,导致GPU/华为昇腾Ascend等加速器无法被充分利用。研究数据表明,企业内数据中心的计算任务大约有30%的计算时间花费在数据预处理步骤 [1],也有研究发现在一些公开数据集上的模型训练任务有65%的时间都花费在了数据预处理上 [2],由此可以看出数据模块的性能对于整体训练吞吐率有着决定性的影响。
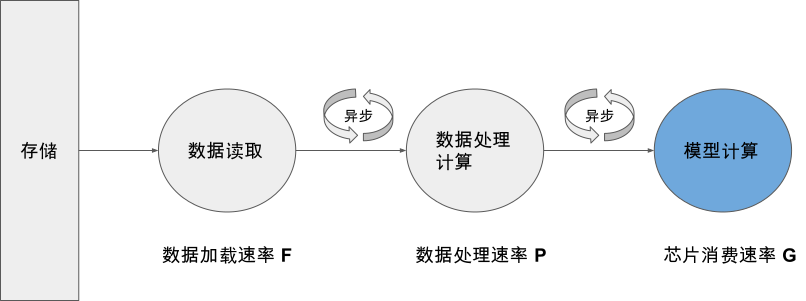
图8.3.1 数据加载、预处理、模型计算异步并行执行
为了追求最高的训练吞吐率,现有系统一般选择将数据读取、数据预处理计算、以及芯片上的模型计算三个步骤异步并行执行。这三步构成了典型的数据生产者和数据消费者的上下游关系,我们将数据从存储设备中的读取速率用F表示,数据预处理速率用P表示,芯片上的数据消费速率用G表示。理想情况下我们希望G < min(F, P),此时加速芯片不会因为等待数据而阻塞。然而现实情况下,我们常常要么因为数据加载速率F过低(称为I/O Bound),要么因为数据预处理速率P过低(称为CPU Bound)导致G>min(F, P)而使得芯片无法被充分利用。针对上述关键性能问题,我们将在本节重点探究两个内容:
-
如何针对机器学习场景的特定I/O需求来设计相应文件格式及加载方式,以优化数据读取速率F。
-
如何设计并行架构来充分发挥现代多核CPU的计算能力,以提升数据处理速率P。
在本节的最后我们还会研究一个具有挑战性的问题,即如何利用我们在前几章学到的计算图的编译技术来优化用户的数据处理计算流图,以进一步达到最优的数据处理吞吐率性能。那么接下来,请读者和我们一起开启本节的头脑风暴旅程。
数据读取的高效性
首先我们来研究如何解决数据读取的性能挑战。我们面临的第一个问题是数据类型繁多,存储格式不统一带来的I/O差异,如文本数据可能存储成txt数据格式,图像数据可能存储成原始格式或者如JPEG等压缩格式。我们显然无法去针对每一种存储情况都设计其最优的数据读取方案。但是我们可以通过提出一种统一的存储格式(我们称之为Unirecord格式)以屏蔽不同数据类型的I/O差异,并基于这种数据格式进行数据加载方案的设计与优化,而实际使用中用户只需要将其原始数据集转换存储为我们的统一数据格式便可以享受到高效的读取效率。

图8.3.2 统一数据格式
那么我们的Unirecord除了统一用户存储格式之外还需要具备哪些特性呢?机器学习模型训练中对数据的访问具有如下特点:
-
每一个Epoch内以一种随机顺序遍历所有的数据且每个数据只被遍历一次
-
所有Epoch需要以不同的随机顺序遍历访问所有数据
上述的访问特性要求我们的Unirecord存储格式能够支持高效的随机读取。当我们的数据集能够全部存储在RAM中时,对Unirecord的随机读取并不会成为大的问题。但是当数据集大到必须存储在本地磁盘或者分布式文件系统中时,我们就需要设计特定的方案。一个直观的想法是将一个Unirecord文件分为索引块和数据块,索引块中记录每个数据在文件中的大小、偏移以及一些校验值等元信息,数据块存储每个数据的主体数据。当我们需要对一个Unirecord格式的文件进行随机读取时,我们首先在内存中加载该文件的索引块(通常远远小于整个文件大小)并在内存中建立文件内数据的索引表,接着当我们需要随机读取数据时,我们首先在索引表中查询该数据在文件中的偏移、大小等信息并基于该信息从磁盘上进行读取。这样的读取方式可以满足我们在磁盘上的随机读取需求。接下来我们以MindSpore提出的MindRecord的实践经验为例子介绍统一文件格式的设计,以帮助大家加深对这部分内容的理解
图8.3.3 支持随机读取的文件格式设计
MindRecord介绍
MindRecord是MindSpore推出的统一数据格式,目标是归一化用户的数据集,优化训练数据的读取过程。该文件格式具备如下特征:
-
实现多变的用户数据统一存储、访问,训练数据读取更加简便。
-
数据聚合存储,高效读取,且方便管理、移动。
-
高效的数据编解码操作,对用户透明、无感知。
-
可以灵活控制分区的大小,实现分布式训练。
和我们前文设计的Unirecord思路相似,一个MindRecord文件也由数据文件和索引文件组成,数据文件包含文件头、标量数据页、块数据页,用于存储用户归一化后的训练数据,索引文件包含基于标量数据(如图像Label、图像文件名等)生成的索引信息,用于方便的检索、统计数据集信息。为确保对一个MindRecord文件的随机读取性能,MindSpore建议单个MindRecord文件小于20G,若数据集超过20G,用户可在MindRecord数据集生成时指定相应参数将原始数据集分片存储为多个MindRecord文件。

图8.3.4 MindRecord文件格式组成
一个MindRecord文件中的数据文件部分具体的关键部分的详细信息如下:
-
文件头 文件头主要用来存储文件头大小、标量数据页大小、块数据页大小、Schema信息、索引字段、统计信息、文件分区信息、标量数据与块数据对应关系等,是MindRecord文件的元信息。
-
标量数据页 标量数据页主要用来存储整型、字符串、浮点型数据,如图像的Label、图像的文件名、图像的长宽等信息,即适合用标量来存储的信息会保存在这里。
-
块数据页 块数据页主要用来存储二进制串、Numpy数组等数据,如二进制图像文件本身、文本转换成的字典等。
用户训练时,MindRecord的读取器能基于索引文件快速的定位找到数据所在的位置,并将其读取解码出来。另外MindRecord具备一定的检索能力,用户可以通过指定查询条件筛选获取符合期望的数据样本。
对于分布式训练场景,MindRecord会基于数据文件中Header及索引文件进行元数据的加载,得到所有样本的ID及样本在数据文件中的偏移信息,然后根据用户输入的num_shards(训练节点数)和shard_id(当前节点号)进行数据的partition,得到当前节点的num_shards分之一的数据,即:分布式训练时,多个节点只读取数据集的num_shards分之一,借由计算侧的AllReduce实现整个数据集训练的效果。进一步,如果用户开启shuffle操作,那么每epoch保证所有节点shuffle seed保持一致,那么对所有样本的ID shuffle结果是一致的,那么数据partition的结果就是正确的。
图8.3.5 MindRecord Partition策略
数据计算的高效性
解决了数据读取性能问题后,我们继续来研究数据计算的性能提升(即最大化上文中的数据处理速率P)。我们以上文提及的数据预处理流水为例子、来研究如何设计数据模块对用户计算图的调度执行以达到最优的性能。
图8.3.6 数据预处理流程串行顺序执行示意图
由于深度学习芯片如GPU/华为昇腾Ascend等并不具备通用数据处理的能力, 我们目前还是主要依赖CPU来完成预处理计算。主流的AI服务器大多具备多个多核CPU,数据模块需要设计合理的并行架构充分发挥多核算力,以提升数据预处理性能达到尽可能减少加速器由于等待数据而阻塞的目的。本节中我们将介绍流水线粒度并行以及算子粒度并行两种常见的并行架构。流水线并行的方式结构清晰,易于理解和实现,主要被Pytorch这样基于Python实现数据模块的机器学习系统所采用。受到经典数据并行系统调度执行架构设计的影响,其他如Google的TensorFlow以及华为的MindSpore等系统主要采用算子粒度并行做精细CPU算力分配以达到充分利用多核算力的目的。然而精细的分配意味着我们需要对所有数据处理流程中涉及的算子设置合理的并行参数,这对用户而言是一个较大的挑战。于是MindSpore等框架又提供数据流图中关键参数自动调优的功能,通过运行时的动态分析自动搜索得到最优的算子并行度等参数,极大的减少了用户的编程负担。接下来我们一一展开讨论。
流水线并行
第一种常见的并行方案为流水线粒度的并行,即我们把用户构建的计算流水在一个线程/进程内顺序串行执行,同时启动多个线程/进程并行执行多个流水线。假设用户总共需要处理N个数据样本,那么当流水线并行度为M时,每个进程/线程只需要执行处理(N/M)个样本。流水线并行架构结构简单,易于实现。整个并行架构中各个执行进程/线程只需要在数据执行的开始和结束进行跨进程/线程的通信即可,数据模块将待处理的数据任务分配给各个流水线进程/线程,并在最终进行结果汇总发送到芯片上进行模型计算。从用户的角度而言使用也相对方便,只需要指定关键的并行度参数即可。接下来我们以Pytorch为例子进行详细展开。

图8.3.7 流水线级别并行执行示意图
在Pytorch中,用户只需要实现一个Dataset的Python类编写数据处理过程,Dataloader通过用户指定的并行度参数num_workers来启动相应个数的Python进程调用用户自定义的Dataset类进行数据预处理。Dataloader中的进程有两类角色:worker进程以及主进程,以及两类进程间通信队列:index_queue以及worker_result_queue。训练过程中,主进程负责将待处理数据任务列表通过index_queue发送给各个worker进程,每个woker进程执行用户编写的Dataset类的数据预处理逻辑并将处理后的结果通过worker_result_queue返回给主进程。
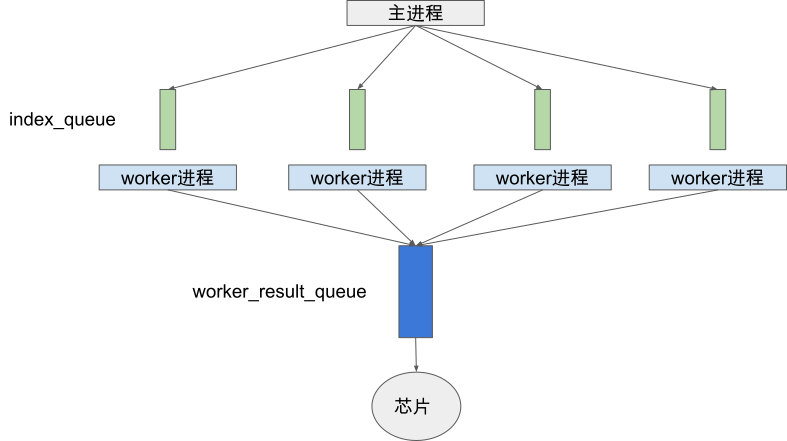
图8.3.8 Pytorch Dataloader并行执行架构
接下来我们展示一段用户使用Pytorch的Dataloader进行并行数据预处理的代码片段,可以发现我们只需要实现Dataset类描述数据预处理逻辑,并指定num_workers即可实现流水线粒度的并行数据预处理。
# 描述数据预处理流程
class TensorDataset:
def __init__(self, inps):
sef.inps = inps
def __getitem__(self, idx):
data = self.inps[idx]
data = data + 1
return data
def __len__(self):
return self.inps.shape[0]
inps = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
dataset = TensorDataset(inps)
# 指定并行度为3
loader = DataLoader(dataset, batch_size=2, num_workers=3)
for batch_idx, sample in enumerate(loader):
print(sample)
最后需要指出的是, Pytorch Dataloader的执行过程中涉及大量进程间通信,虽然为了加速这一步骤,Pytorch对Tensor类数据实现了基于共享内存的进程间通信机制。然而当通信数据量较大时,跨进程通信仍然会较大地影响端到端的数据预处理吞吐率性能。当然,这不是流水线并行自身的架构问题,而是由于CPython的全局解释器锁(Global Interpreter Lock, GIL)导致在Python层面实现流水线并行时只能采用进程并行。为了解决这个问题,目前Pytorch团队也在尝试通过移除CPython中的GIL来达到基于多线程实现流水线并行以提升通信效率的目的 ,感兴趣的读者可以选择继续深入了解。
算子并行
流水线并行中算力(CPU核心)的分配以流水线为粒度,相对而言,以算子为计算资源分配粒度的算子并行是一种追求更精细算力分配的并行方案。我们期望对计算耗时高的算子分配更高的并行度,计算耗时低的算子分配更低的并行度,以达到更加高效合理的CPU算力使用。算子并行想法和经典的数据并行计算系统的并行方式一脉相承,我们以经典的MapReduce计算执行为例子,我们发现这也可以认为是一种算子并行(map算子和reduce算子),其中map算子的并行度和reduce算子的并行度根据各个算子阶段的计算耗时而决定。
图8.3.9 MapReduce经典并行执行架构
下图中我们给出本节开头数据预处理流程的算子并行架构示意图,我们根据各个算子的计算耗时设置图片解码算子并行度为3,图片缩放并行度为2,图片随机旋转算子并行度为4,图片归一化算子并行度为3,以及图像通道转置算子并行度为1。我们期望通过给不同耗时的算子精准的分配算力,以达到算力高效充分的利用。具体实现中算子并行一般采用线程级并行,所有的算子使用线程间队列等方法进行共享内存通信。
图8.3.10 算子并行执行架构
现有机器学习系统的数据模块中,tf.data以及MindData均采用了算子并行的方案。由于对算力的利用更加充分、以及基于C++的高效数据流调度实现,算子并行的方案往往展示出更好的性能,tf.data的性能评测表明其相比较Pytorch的Dataloader有近两倍的性能优势 [1]。 接下来我们以一段基于MindSpore实现本节开篇的数据预处理流程来展示如何在一个算子并行的数据流水线中设置各个算子的并行度。
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as c_transforms
import mindspore.dataset.transforms.vision.c_transforms as vision
# 读取数据
dataset_dir = "path/to/imagefolder_directory"
dataset = ds.ImageFolderDatasetV2(dataset_dir, num_parallel_workers=8)
transforms_list = [vision.Decode(),
vision.Resize((256, 256)),
vision.RandomRotation((0, 15)),
vision.Normalize((100, 115.0, 121.0), (71.0, 68.0, 70.0)),
vision.HWC2CHW()]
onehot_op = c_transforms.OneHot(num_classes)
# 解码算子并行度为3
dataset = dataset.map(input_columns="image", operations=vision.Decode(), num_parallel_workers=3)
# 缩放算子并行度为2
dataset = dataset.map(input_columns="image", operations=vision.Resize((256, 256)), num_parallel_workers=2)
# 随机旋转算子并行度为4
dataset = dataset.map(input_columns="image", operations=vision.RandomRotation((0, 15)), num_parallel_workers=4)
# 正规化算子并行度为3
dataset = dataset.map(input_columns="image", operations=vision.Normalize((100, 115.0, 121.0), (71.0, 68.0, 70.0)), num_parallel_workers=3)
# 通道转置算子并行度为1
dataset = dataset.map(input_columns="image", operations=vision.HWC2CHW(), num_parallel_workers=1)
dataset = dataset.map(input_columns="label", operations=onehot_op)
我们发现,虽然算子并行具备更高的性能潜力,但却需要我们对每一个算子设置合理并行参数。这不仅对用户提出了较高的要求,同时也增加了由于不合理的并行参数设置导致性能反而下降的风险。为了让用户更加轻松的使用算子并行,tf.data和MindData都增加了流水线关键参数动态调优功能,基于对流水线执行时的性能监控计算得到合理的参数以尽可能达到最优的数据预处理吞吐率 [1]。
数据处理计算图优化
在前文中,我们专注于通过并行架构来高效执行用户构建的数据预处理计算图。但我们可以思考如下问题:用户给定的计算图是否是一个高效的计算图? 如果不高效,我们是否能够在保证等价变换的前提下将用户的数据计算图进行优化重写得到执行性能预期更好的计算图?没错,这和我们在前几章中学习的模型计算图编译优化有着相同的思想,即通过分析变换计算图IR得到更优的IR表示来达到更好的执行性能。常用的数据图优化策略有算子融合以及map操作向量化两种。算子融合将map+map、map+batch、map+filter、filter+filter等算子组合融合成一个等价复合算子,将原先需要在两个线程组中执行的计算融合为在一个线程组中执行的复合计算,减少线程间的同步通信开销,达到了更优的性能。而map操作向量化则将常见的dataset.map(f).batch(b)操作组合变换调整为dataset.batch(b).map(parallel_for(f)),借助现代CPU的对并行操作更友好的SIMD指令集来加速数据预处理。
参考文献
- Murray, Derek G and Simsa, Jiri and Klimovic, Ana and Indyk, Ihor. tf. data: A machine learning data processing framework. arXiv preprint arXiv:2101.12127. 2021. ↩
- Mohan, Jayashree and Phanishayee, Amar and Raniwala, Ashish and Chidambaram, Vijay. Analyzing and mitigating data stalls in dnn training. arXiv preprint arXiv:2007.06775. 2020. ↩
保序性设计
保序性设计
和常规数据并行计算任务不同的是,机器学习场景下的数据并行处理为了确保实验的可复现性需要维护保序的性质。在具体实现中,我们需要保证并行数据预处理后的数据输出顺序与输入顺序保持相同(即下图中的SeqB和SeqA相同)。这确保了每一次的数据模块的结果输出顺序由数据混洗模块输出顺序唯一确定,有助于用户在不同的实验之间进行比较和调试。不同的机器学习系统采用了不同的方案来确保保序性,我们以MindSpore的实现为例子进行介绍以加深读者对这部分内容的理解。
图8.4.1 数据的保序性——确保SeqB与SeqA相同
MindSpore通过约束算子线程组间的通信行为来确保对当前算子的下游算子的输入顺序与自己的输入顺序相同,基于这种递归的约束,确保了整个并行数据处理最后一个算子的输出顺序与第一个算子的输入顺序相同。具体实现中,MindSpore以Connector为算子线程组间的通信组件,对Connector的核心操作为上游算子的Push操作以及下游算子的Pop操作,我们重点关注MindSpore对这两个行为的约束。
Connector的使用有如下两个要求:
-
Connector两端的数据生产线程组和数据消费线程组中的线程分别从0开始编号。
-
确保数据生产者的输入数据顺序是在各个生产者线程间为按顺序轮询分布(Round-Robin distribution), 即当生产者线程组大小为M时,生产者线程0拥有第(0 + M * k)个数据,生产者线程1拥有第(1 + M * k),生产者线程2拥有第(2 + M * k)个数据等(其中k=0,1,2,3...)。
Connector中维护与生产者线程数目相同的队列并确保向Connector中放入数据时,每个生产者线程生产的数据只放到对应编号的队列中,这样可以确保Connector中的数据在不同的队列间的分布与在不同生产者线程组之间的分布相同(代码片段中的Push函数)。接着当Connector的消费者线程组从Connector中获取数据时,我们需要确保最终数据在不同的消费者线程间依然为按顺序轮询分布,即当消费者线程组大小为N时,消费者线程0拥有第(0 + N * k)个数据,消费者线程1拥有第(1 + N * k)个数据,消费者线程2拥有第(2 + N * k)个数据等(其中k=0,1,2,3...)。为此当有消费者线程从Connector中请求数据时,Connector在确保当前请求消费者线程编号i与待消费数据标号j符合\(i=j%N\)的关系下(其中N为消费者线程数目)按照轮循的方式从各个队列中获取数据,如果二者标号不符合上述关系,则该请求阻塞等待。通过这种通信的约束方式,MindSpore实现了保序功能。
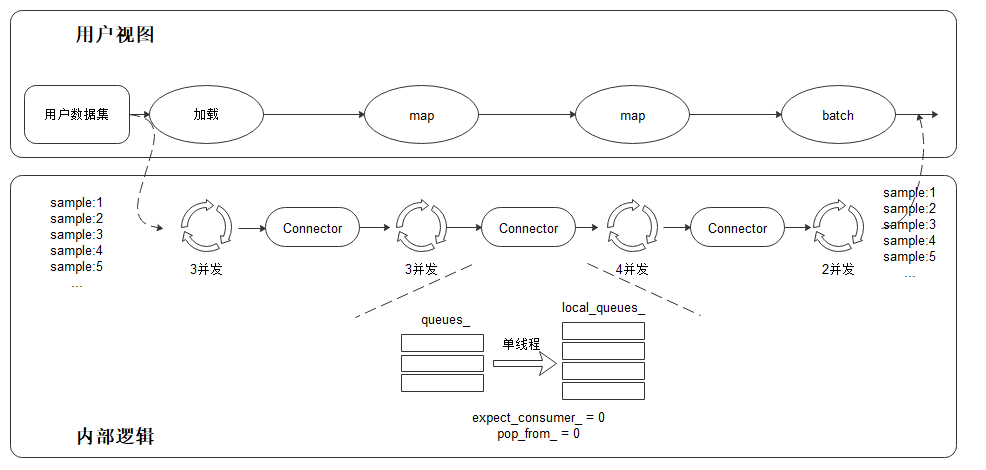
图8.4.2 MindSpore保序性实现
单机数据处理性能的扩展
单机数据处理性能的扩展
上文我们介绍了通过并行架构发挥多核CPU算力来加速数据预处理,以满足芯片上模型计算对于数据消费的吞吐率需求,这在大部分情况下都能解决用户的问题。然而数据消费性能随着AI芯片的发展在逐年快速增长(即模型计算速率在变快),而主要借助CPU算力的数据模块却由于摩尔定律的逐渐终结无法享受到芯片性能提升带来的硬件红利,使得数据生产的性能很难像模型计算性能一样逐年突破。不仅如此,近几年AI服务器上AI芯片数量的增长速度远超CPU数量的增长速度,进一步加剧了芯片的数据消费需求与数据模块的数据生产性能之间的矛盾。我们以英伟达(NVIDIA)公司生产的NVIDIA DGX系列服务器为例子,DGX-1服务器中配置有40个CPU核和8个GPU芯片,而到了下一代的NVIDIA DGX-2服务器时,GPU芯片的数目增长了到了16个,而CPU核的数目仅从40个增加到了48个。由于所有的GPU芯片在训练时共享CPU的算力,故平均而言每个GPU芯片(数据消费者)能够使用的算力从NVIDIA DGX-1时的5CPU核/GPU下降到了 NVIDIA DGX-2的3CPU核/GPU,CPU的算力瓶颈会导致用户使用多卡训练时无法达到预期的扩展性能。针对单机上的CPU算力不足的问题,我们给出两种目前常见的两种解决方案,即基于CPU+AI芯片的异构数据处理的加速方案和基于分布式数据预处理的扩展方案。
基于异构计算的数据预处理
由于AI芯片相比于CPU拥有更丰富的算力资源,故在CPU算力成为数据预处理瓶颈时通过借助AI加速芯片来做数据预处理是一个行之有效的方案。虽然AI芯片不具备通用的数据预处理能力,但是由于大部分高耗时的数据预处理都是Tensor相关的计算,如语音中的快速傅立叶变换(Fast Fourier Transform, FFT),图像中的去噪等,使得部分操作可以被卸载到AI芯片上来加速。如华为昇腾Ascend310芯片上的Dvpp模块为芯片内置的硬件解码器,相较于CPU拥有对图形处理更强劲的性能,Dvpp支持JPEG图片的解码缩放等图像处理基础操作,用户实际数据预处理中可以指定部分图像处理在昇腾Ascend310芯片上完成以提升数据模块性能。
namespace ms = mindspore;
namespace ds = mindspore::dataset;
// 初始化操作
//...
// 构建数据处理算子
// 1. 解码
std::shared_ptr<ds::TensorTransform> decode(new ds::vision::Decode());
// 2. 缩放
std::shared_ptr<ds::TensorTransform> resize(new ds::vision::Resize({256}));
// 3. 归一化
std::shared_ptr<ds::TensorTransform> normalize(new ds::vision::Normalize(
{0.485 * 255, 0.456 * 255, 0.406 * 255}, {0.229 * 255, 0.224 * 255, 0.225 * 255}));
// 4. 剪裁
std::shared_ptr<ds::TensorTransform> center_crop(new ds::vision::CenterCrop({224, 224}));
// 构建流水并指定使用昇腾Ascend进行计算
ds::Execute preprocessor({decode, resize, center_crop, normalize}, MapTargetDevice::kAscend310, 0);
// 执行数据处理流水
ret = preprocessor(image, &image);
相比较Dvpp只支持图像的部分预处理操作,英伟达公司研发的DALI 是一个更加通用的基于GPU的数据预处理加速框架。DALI中包含如下三个核心概念:
-
DataNode:表示一组Tensor的集合
-
Operator:对DataNode进行变换处理的算子,一个Operator的输入和输出均为DataNode。比较特殊的是,DALI中的算子可以被设置为包括cpu,gpu,mixed三种不同执行模式,其中cpu模式下算子的输入输出均为cpu上的DataNode,gpu模式下算子的输入输出均为gpu上的DataNode,而mixed模式下的算子的输入为cpu的DataNode而输出为gpu的DataNode。
-
Pipeline:用户通过Operator描述DataNode的处理变换过程而构建的数据处理流水
实际使用中用户通过设置算子的运行模式(mode)来配置算子的计算是用CPU还是GPU完成计算,同时DALI中有如下限制:当一个算子为mixed模式或者gpu模式时,其所有的下游算子强制要求必须为gpu模式执行。
图8.5.1 NVIDIA DALI概览
下面展示一段使用DALI构建数据处理流水线的示例代码,我们从文件中读取图片数据经过混合模式的解码再经过运算在GPU上的旋转和缩放算子处理后返回给用户处理 结果。由于其展示出的优异性能, DALI被广泛的用于高性能推理服务和多卡训练性能的优化上。
import nvidia.dali as dali
pipe = dali.pipeline.Pipeline(batch_size = 3, num_threads = 2, device_id = 0)
with pipe:
files, labels = dali.fn.readers.file(file_root = "./my_file_root")
images = dali.fn.decoders.image(files, device = "mixed")
images = dali.fn.rotate(images, angle = dali.fn.random.uniform(range=(-45,45)))
images = dali.fn.resize(images, resize_x = 300, resize_y = 300)
pipe.set_outputs(images, labels)
pipe.build()
outputs = pipe.run()
基于分布式的数据预处理
分布式数据预处理是另一种解决CPU算力性能不足的可选方案。一种常见的做法是借助Spark、Dask等现有大数据计算框架进行数据预处理并将结果写入分布式文件系统,而训练的机器只需要读取预处理的结果数据并进行训练即可。

图8.5.2 基于第三方分布式计算框架的分布式数据预处理
该方案虽然在业内被广泛使用,却面临着三个问题:
-
由于数据处理和数据训练采用不同的框架,使得用户为此常常需要在两个不同的框架中编写不同语言的程序,增加了用户的使用负担。
-
由于数据处理系统和机器学习两个系统间无法做零拷贝的数据共享,使得数据的序列化和反序列化常常成为不可忽视的额外开销。
-
由于大数据计算框架并不是完全针对机器学习场景,使得某些分布式预处理操作如全局的数据混洗无法被高效的实现。
为了更适配机器学习场景的数据预处理,分布式机器学习框架Ray借助其自身的任务调度能力实现了简单的分布式的数据预处理—— Ray Dataset [1],由于数据预处理和训练处在同一个框架内,在降低了用户的编程负担的同时也通过数据的零拷贝共享消除了序列化/反序列化带来的额外开销。Ray Dataset支持如map、batch、map、filter等简单并行数据集变换算子、以及如mean等一些基础的聚合操作算子。同时Ray Dataset也支持排序、随机打乱、GroupBy等全局混洗操作,该方案目前处在研究开发中,还未被广泛的采用,感兴趣的读者可以翻阅相关资料进一步的了解。
ray.data.read_parquet("foo.parquet") \
.filter(lambda x: x < 0) \
.map(lambda x: x**2) \
.random_shuffle() \
.write_parquet("bar.parquet")
参考文献
- Moritz, Philipp and Nishihara, Robert and Wang, Stephanie and Tumanov, Alexey and Liaw, Richard and Liang, Eric and Elibol, Melih and Yang, Zongheng and Paul, William and Jordan, Michael I and others. Ray: A distributed framework for emerging \\(\\\)AI\\(\\\) applications. 13th \\(\\\)USENIX\\(\\\) Symposium on Operating Systems Design and Implementation (\\(\\\)OSDI\\(\\\) 18). 2018. ↩
总结
总结
本章我们围绕着易用性、高效性和保序性三个维度展开研究如何设计实现机器学习系统中的数据预处理模块。在易用性维度我们重点探讨了数据模块的编程模型,通过借鉴历史上优秀的并行数据处理系统的设计经验,我们认为基于描述数据集变换的编程抽象较为适合作为数据模块的编程模型,在具体的系统实现中,我们不仅要在上述的编程模型的基础上提供足够多内置算子方便用户的数据预处理编程,同时还要考虑如何支持用户方便的使用自定义算子。在高效性方面,我们从数据读取和计算两个方面分别介绍了特殊文件格式设计和计算并行架构设计。我们也使用我们在前几章中学习到的模型计算图编译优化技术来优化用户的数据预处理计算图,以进一步的达到更高的数据处理吞吐率。机器学习场景中模型对数据输入顺序敏感,于是衍生出来保序性这一特殊性质,我们在本章中对此进行了分析并通过MindSpore中的Connector的特殊约束实现来展示真实系统实现中如何确保保序性。最后,我们也针对部分情况下单机CPU数据预处理性能的问题,介绍了当前基于异构处理加速的纵向扩展方案,和基于分布式数据预处理的横向扩展方案,我们相信读者学习了本章后能够对机器学习系统中的数据模块有深刻的认知,也对数据模块未来面临的挑战有所了解。
扩展阅读
- 流水线粒度并行实现示例建议阅读 Pytorch DataLoader。
- 算子粒度并行实现示例建议阅读 MindData。
模型部署
前面的章节讲述了机器学习模型训练系统的基本组成,这一章节将重点讲述模型部署的相关知识。模型部署是将训练好的模型部署到运行环境中进行推理的过程,模型部署的过程中需要解决训练模型到推理模型的转换,硬件资源对模型的限制,模型推理的时延、功耗、内存占用等指标对整个系统的影响以及模型的安全等一系列的问题。
本章将主要介绍机器学习模型部署的主要流程,包括训练模型到推理模型的转换、适应硬件限制的模型压缩技术、模型推理及性能优化以及模型的安全保护。
本章的学习目标包括:
-
了解训练模型到推理模型转换及优化
-
掌握模型压缩的常用方法:量化、稀疏和知识蒸馏
-
掌握模型推理的流程及常用的性能优化的技术
-
了解模型安全保护的常用方法
概述
概述
模型完成训练后,需要将模型及参数持久化成文件,不同的训练框架导出的模型文件中存储的数据结构不同,这给模型的推理系统带来了不便。推理系统为了支持不同的训练框架的模型,需要将模型文件中的数据转换成统一的数据结构。此外,在训练模型转换成推理模型的过程中,需要进行一些如算子融合、常量折叠等模型的优化以提升推理的性能。
推理模型部署到不同的场景,需要满足不同的硬件设备的限制,例如,在具有强大算力的计算中心或数据中心的服务器上可以部署大规模的模型,而在边缘侧服务器、个人电脑以及智能手机上算力和内存则相对有限,部署的模型的规模就相应地要降低。在超低功耗的微控制器上,则只能部署非常简单的机器学习模型。此外,不同硬件对于不同数据类型(如float32、float16、bfloat16、int8等)的支持程度也不相同。为了满足这些硬件的限制,在有些场景下需要对训练好的模型进行压缩,降低模型的复杂度或者数据的精度,减少模型的参数,以适应硬件的限制。
模型部署到运行环境中执行推理,推理的时延、内存占用、功耗等是影响用户使用的关键因素,优化模型推理的方式有两种,一是设计专有的机器学习的芯片,相对于通用的计算芯片,这些专有芯片一般在能效比上具有很大的优势。二是通过软硬协同最大程度地发挥硬件的能力。对于第二种方式,以CPU为例,如何切分数据块以满足cache大小,如何对数据进行重排以便计算时可以连续访问,如何减少计算时的数据依赖以提升硬件流水线的并行,如何使用扩展指令集以提升计算性能,这些都需要针对不同的CPU架构进行设计和优化。
对于一个企业来讲,模型是属于重要的资产,因此,在模型部署到运行环境以后,保护模型的安全至关重要。本章节会介绍如模型混淆等一些常见的机器学习模型的安全保护手段。
针对上述模型部署时的挑战,业界有一些常见的方法:
- 算子融合
通过表达式简化、属性融合等方式将多个算子合并为一个算子的技术,融合可以降低模型的计算复杂度及模型的体积。
- 常量折叠
将符合条件的算子在离线阶段提前完成前向计算,从而降低模型的计算复杂度和模型的体积。常量折叠的条件是算子的所有输入在离线阶段均为常量。
- 模型压缩
通过量化、剪枝等手段减小模型体积以及计算复杂度的技术,可以分为需要重训的压缩技术和不需要重训的压缩技术两类。
- 数据排布
根据后端算子库支持程度和硬件限制,搜索网络中每层的最优数据排布格式,并进行数据重排或者插入数据重排算子,从而降低部署时的推理时延
- 模型混淆
对训练好的模型进行混淆操作,主要包括新增网络节点和分支、替换算子名的操作,攻击者即使窃取到混淆后的模型也不能理解原模型的结构。此外,混淆后的模型可以直接在部署环境中以混淆态执行,保证了模型在运行过程中的安全性。
训练模型到推理模型的转换及优化
训练模型到推理模型的转换及优化
模型转换
前面章节提到过,不同的训练框架,如Tensorflow、PyTorch、MindSpore、MXNet、CNTK等,都定义了自己的模型的数据结构,推理系统需要将它们转换到统一的一种数据结构上。开发神经网络交换协议(Open Neural Network Exchange,ONNX)正是为此目的而设计的。ONNX支持广泛的机器学习运算符集合,并提供了不同训练框架的转换器,例如TensorFlow模型到ONNX模型的转换器、PyTorch模型到ONNX模型的转换器等。 模型转换本质上是将模型这种结构化的数据,从一种数据结构转换为另一种数据结构的过程。进行模型转换首先要分析两种数据结构的异同点,然后针对结构相同的数据做搬运;对于结构相似的数据做一一映射;对于结构差异较大的数据则需要根据其语义做合理的数据转换;更进一步如果两种数据结构上存在不兼容,则模型转换无法进行。ONNX的一个优势就在于其强大的表达能力,从而大多数业界框架的模型都能够转换到ONNX的模型上来而不存在不兼容的情况。
模型可以抽象为一种图,从而模型的数据结构可以解构为以下两个要点:
-
模型拓扑连接:从图的角度来说,就是图的边;从AI模型的角度来说,就是AI模型中的数据流和控制流等。模型数据流和控制流的定义又可以引申出子图的表达形式、模型输入输出的表达形式、控制流结构的表达形式等。比如Tensorflow1.x中的控制流表达为一种有环图,通过Enter、Exit、Switch、LoopCond、NextIteration等算子来解决成环,而ONNX通过Loop,If等算子来表达控制流,从而避免引入了有环,所以在将Tensorflow1.x的控制流模型转化为ONNX模型时,需要将Tensorflow模型中的控制流图结构融合成ONNX的While或者If算子。
-
算子原型定义:从图的角度来说,就是图的顶点;从AI模型角度来说,就是AI模型中的数据处理节点或者控制流节点。算子原型包括但不限于算子类型、算子输入输出的定义、算子属性的定义等。比如Caffe的slice算子和ONNX的slice算子的语义其实是不一致的,Caffe的slice算子应该映射到ONNX的Split算子,所以在将Caffe模型转换成ONNX模型时,需要将Caffe的Slice算子映射到ONNX的Split算子。比如Tensorflow中的中的FusedBatchNorm算子在Caffe中找不到相同语义的算子,需要将Caffe的BatchNorm算子和Scale算子组合起来才能表达相同的语义。
在完成模型转换之后,通常地,框架会将一些不依赖于输入的工作提前去完成。这些工作包括了如常量折叠、算子融合、算子替换、算子重排等一些优化手段。这些优化手段的概念在前面的章节其实已经提及到,比如在编译器前端阶段,通常也会做常量折叠;在编译器后端阶段,通常会根据后端的硬件支持程度,对算子进行融合和拆分。但是有些优化工作只有在部署阶段才能进行或者彻底进行。
算子融合
算子融合,就是将深度神经网络模型中的多个算子,按照一定的规则,合并成一个新的算子。通过算子融合,可以减少模型在线推理时的计算量、访存开销,从而降低推理时的时延和功耗。
图9.2.1 计算机分层存储架构
算子融合带来的性能上的收益主要来自两个方面,一是通过融合,充分利用寄存器和缓存,避免多个算子运算时,数据在CPU和内存之间的存储和读取的耗时。如 图9.2.1,可以看到计算机的储存系统,从最靠近cpu的寄存器L1(Level1)、L2(Level2)等多级缓存,到内存、硬盘,其存储的容量越来越大,但读取数据的耗时也越来越大。融合后,前一次计算的结果可以先暂存在CPU的寄存器或者缓存中,下一次计算直接从寄存器或者缓存中读取,减少了内存读写的IO次数。二是通过融合,可以将一些计算量提前完成,避免了前向推理时的冗余计算或者循环冗余计算。
图9.2.2 Convolution + Batchnorm算子融合
如 图9.2.2,以Convolution算子和Batchnorm算子的融合为例,阐述算子融合的基本原理,图中蓝色框表示算子,黄色框表示融合后新增或者改变的算子,白色框表示算子中的权重或者常数张量。其融合的过程是一个计算表达式简化的过程,Convolution算子的计算过程可以等效为一个矩阵乘,其公式可以表达为 (1)。
\[\pmb{Y_{conv}}=\pmb{W_{conv}}*\pmb{X_{conv}}+\pmb{B_{conv}}\tag{1}\label{ch08-equ-conv_equation}\]
这里我们不需要理解公式 (1)中每个变量的含义,只需要注意到一点,该公式是\(\pmb{Y_{conv}}\)关于\(\pmb{X_{conv}}\)的,其他符号均表示常量。
Batchnorm算子的计算过程如公式 (2)所示。
\[\pmb{Y_{bn}}=\gamma\frac{\pmb{X_{bn}}-\mu_{\mathcal{B}}}{\sqrt{{\sigma_{\mathcal{B}}}^{2}+\epsilon}}+\beta\tag{2}\label{ch08-equ-bn_equation}\]
同样,这里不需要理解Batchnorm中的所有参数的含义,只需要了解式 (2)是\(\pmb{Y_{bn}}\)关于\(\pmb{X_{bn}}\)的,其他符号均表示常量。
如 图9.2.2,当Convlution算子的输出作为Batchnorm输入时,最终Batchnorm算子的计算公式也就是要求\(\pmb{Y_{bn}}\)关于\(\pmb{X_{conv}}\)的计算公式,我们将\(\pmb{Y_{conv}}\)代入到\(\pmb{X_{bn}}\),然后将常数项合并提取后,可以得到公式 (3)。
\[\pmb{Y_{bn}}=\pmb{A}*\pmb{X_{conv}}+\pmb{B}\tag{3}\label{ch08-equ-conv_bn_equation_3}\]
其中\(\pmb{A}\)和\(\pmb{B}\)为两个矩阵。可以看到,公式 (3)其实就是一个Convolution的计算公式。这个结果表明,在模型部署时,可以将Convolution和Batchnorm两个算子的计算等价为一个Convolution算子。将上述以计算公式的合并和简化为基础的算子融合称为计算公式融合。
在Convolution算子和Batchnorm算子融合的前后,网络结构相当于减少了一个Batchnorm算子,相应的网络中的参数量和网络所需的计算量都减少了;同时由于算子数量的减少,访存次数也相应地减少了。综合来看,该融合Pattern优化了模型部署时的功耗、性能,同时对于模型的体积大小也有少许收益。
在融合过程中,Convolution计算公式和Batchnorm计算公式中被认为是常量的符号在训练时均为参数,并不是常量。训练阶段如果进行该融合会导致模型参数的缺失。从该融合Pattern的结果来看,融合后网络中减少了一个Batchnorm算子,减少了一个Batchnorm算子的参数量,其实就是改变了深度神经网络的算法,会影响到网络的准确率,这是不可接受的。所以Convolution算子与Batchnorm算子的融合一般是在部署阶段特有的一种优化手段,其优化效果以MindSpore Lite为例,构造了包含一个Convolution和一个Batchnorm的sample网络,分别以样例网络和mobilenet-v2网络为例,在华为Mate30手机上,以两线程运行模型推理,取3000轮推理的平均时耗作为模型推理性能的指标,对比融合前后该指标的变化。从表 ch08-tab-conv_bn_fusion可以看到,对于sample网络和mobilenet-v2网络,融合后分别获得了8.5%和11.7%的推理性能提升,这个性能提升非常可观。并且这个性能提升没有带来任何的副作用,也没有对于硬件或算子库的提出额外要求。
算子替换
算子替换,即将模型中某些算子替换计算逻辑一致但对于在线部署更友好的算子。算子替换的原理是通过合并同类项、提取公因式等数学方法,将算子的计算公式加以简化,并将简化后的计算公式映射到某类算子上。算子替换可以达到降低计算量、降低模型大小的效果。。
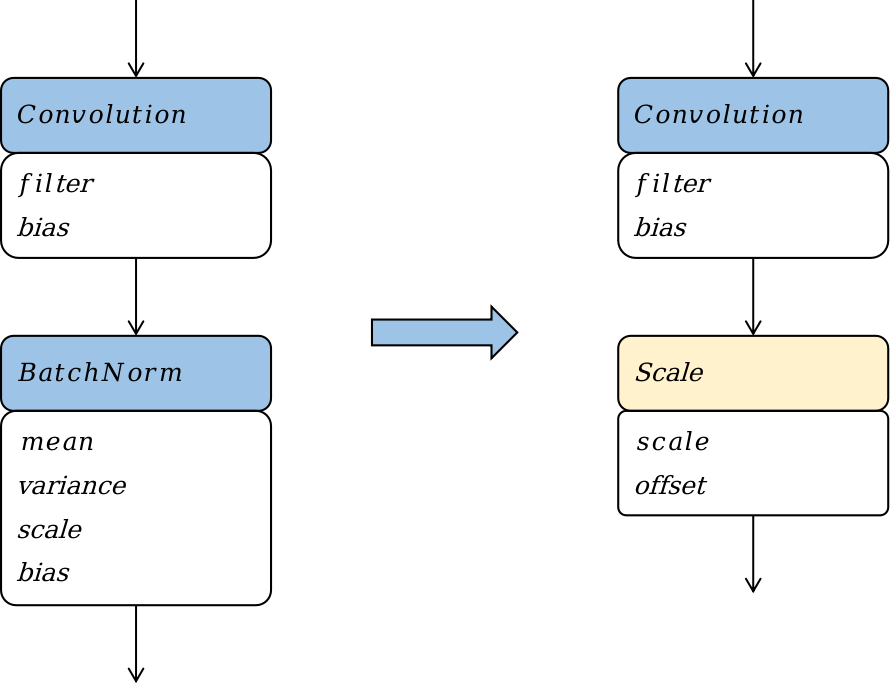
图9.2.3 Batchnorm算子替换
如 图9.2.3,我们以Batchnorm算子替换成Scale算子为例,阐述算子替换的原理。我们直接将Batchnorm的计算公式 (2)进行分解,并将常量合并简化,Batchnorm的计算公式可以写成:
\[\pmb{Y_{bn}}=scale*\pmb{X_{bn}}+offset\tag{4}\label{ch08-equ-replace_scale}\]
其中scale和offset为两个标量。可以看到,计算公式简化后,可以将其映射到一个Scale算子。
在Batchnorm算子被替换为Scale算子的前后,网络中的参数量、计算量都减少了,该算子替换策略可以优化模型部署时的功耗和性能。同理,该算子替换优化策略只能在部署阶段才能进行,因为一方面在部署阶段Batchnorm计算公式中被认为是常量的符号,在训练时是参数并非常量。另一方面该优化策略会降低模型的参数量,改变模型的结构,降低模型的表达能力,影响训练收敛时模型的准确率。
算子重排
算子重排是指将模型中算子的拓扑序按照某些规则进行重新排布,在不降低模型的推理精度的前提下,降低模型推理的计算量。常用的算子重排技术有针对于Slice算子、StrideSlice算子、Crop算子等裁切类算子的前移、Reshape算子和Transpose算子的重排、BinaryOp算子的重排等。
图9.2.4 Crop算子重排
如 图9.2.4,Crop算子是从输入的特征图中裁取一部分作为输出,经过Crop算子后,特征图的大小就降低了。如果将这个裁切的过程前移,提前对特征图进行裁切,那么后续算子的计算量也会相应地减少,从而提高模型部署时的推理性能。Crop算子前移带来的性能提升跟Crop算子的参数有关。但是Crop算子一般只能沿着的element wise类算子前移。
通过前面的实验数据可以看到,通过推理前的模型优化,可以为推理的时延、功耗、内存占用带来极大的收益。
模型压缩
模型压缩
上一小节简要介绍了模型转换的目的,并重点讲述了模型部署时的一些常用的模型优化手段。考虑到不同场景的硬件对模型的要求不同,比如部署在手机上,对于模型的大小比较敏感,一般在兆级别。因此,对于一些较大的模型,往往需要通过一些模型压缩的技术,使其能满足不同计算硬件的要求。
量化
模型量化是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程,如图 图9.3.1,T是量化前的数据范围。通过以更少的位数表示浮点数据,模型量化可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度。
图9.3.1 量化原理
计算机中不同数据类型的占用比特数及其表示的数据范围各不相同。可以根据实际业务需求将原模型量化成不同比特数的模型,一般深度神经网络的模型用单精度浮点数表示,如果能用有符号整数来近似原模型的参数,那么被量化的权重参数存储大小就可以降到原先的四分之一,用来量化的比特数越少,量化后的模型压缩率越高。工业界目前最常用的量化位数是8比特,低于8比特的量化被称为低比特量化。1比特是模型压缩的极限,可以将模型压缩为1/32,在推理时也可以使用高效的XNOR和BitCount位运算来提升推理速度。
另外,根据量化数据表示的原始数据范围是否均匀,还可以将量化方法分为线性量化和非线性量化。实际的深度神经网络的权重和激活值通常是不均匀的,因此理论上使用非线性量化导致的精度损失更小,但在实际推理中非线性量化的计算复杂度较高,通常使用线性量化。下面着重介绍线性量化的原理。
假设r表示量化前的浮点数,量化后的整数q可以表示为:
\[q=clip(round(\frac{r}{s}+z),q_{min},q_{max})\]
\(round(\cdot)\)和\(clip(\cdot)\)分别表示取整和截断操作,\(q_{min}\)和\(q_{max}\)是量化后的最小值和最大值。\(s\)是数据量化的间隔,\(z\)是表示数据偏移的偏置,\(z\)为0的量化被称为对称(Symmetric)量化,不为0的量化称为非对称(Asymmetric)量化。对称量化可以避免量化算子在推理中计算z相关的部分,降低推理时的计算复杂度;非对称量化可以根据实际数据的分布确定最小值和最小值,可以更加充分的利用量化数据信息,使得量化导致的损失更低。
根据量化参数\(s\)和\(z\)的共享范围,量化方法可以分为逐层量化和逐通道量化。逐层量化以一层网络为量化单位,每层网络的一组量化参数;逐通道量化以一层网络的每个量化通道为单位,每个通道单独使用一组量化参数。逐通道量化由于量化粒度更细,能获得更高的量化精度,但计算也更复杂。
根据量化过程中是否需要训练,可以将模型量化分为量化感知训练(Quantization Aware Training, QAT)和训练后量化(Post Training Quantization, PTQ)两种,其中感知量化训练是指在模型训练过程中加入伪量化算子,通过训练时统计输入输出的数据范围可以提升量化后模型的精度,适用于对模型精度要求较高的场景;训练后量化指对训练后的模型直接量化,只需要少量校准数据,适用于追求高易用性和缺乏训练资源的场景。
量化感知训练
量化感知训练是在训练过程中模拟量化,利用伪量化算子将量化带来的精度损失计入训练误差,使得优化器能在训练过程中尽量减少量化误差,得到更高的模型精度。量化感知训练的具体流程如下:
-
初始化:设置权重和激活值的范围\(q_{min}\)和\(q_{max}\)的初始值;
-
构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子;
-
量化训练:重复执行以下步骤直到网络收敛,计算量化网络层的权重和激活值的范围\(q_{min}\)和\(q_{max}\),并根据该范围将量化损失带入到前向推理和后向参数更新的过程中;
-
导出量化网络:获取\(q_{min}\)和\(q_{max}\),并计算量化参数\(s\)和\(z\);将量化参数代入量化公式中,转换网络中的权重为量化整数值;删除伪量化算子,在量化网络层前后分别插入量化和反量化算子。
训练后量化
训练后量化也可以分成两种,权重量化和全量化。权重量化仅量化模型的权重以压缩模型的大小,在推理时将权重反量化为原始的float32数据,后续推理流程与普通的float32模型一致。权重量化的好处是不需要校准数据集,不需要实现量化算子,且模型的精度误差较小,由于实际推理使用的仍然是float32算子,所以推理性能不会提高。全量化不仅会量化模型的权重,还会量化模型的激活值,在模型推理时执行量化算子来加快模型的推理速度。为了量化激活值,需要用户提供一定数量的校准数据集用于统计每一层激活值的分布,并对量化后的算子做校准。校准数据集可以来自训练数据集或者真实场景的输入数据,需要数量通常非常小。在量化激活值时会以校准数据集为输入,执行推理流程然后统计每层激活值的数据分布并得到相应的量化参数,具体的操作流程如下:
-
使用直方图统计的方式得到原始float32数据的统计分布\(P_f\);
-
在给定的搜索空间中选取若干个\(q_{min}\)和\(q_{max}\)分别对激活值量化,得到量化后的数据\(Q_q\);
-
使用直方图统计得到\(Q_q\)的统计分布;
-
计算每个\(Q_q\)与\(P_f\)的统计分布差异,并找到差异性最低的一个对应的\(q_{min}\)和\(q_{max}\)来计算相应的量化参数,常见的用于度量分布差异的指标包括KL散度(Kullback-Leibler Divergence)、对称KL散度(Symmetric Kullback-Leibler Divergence)和JS散度(Jenson-Shannon Divergence)。
除此之外,由于量化存在固有误差,还需要校正量化误差。以矩阵乘为例,\(a=\sum_{i=1}^Nw_ix_i+b\),w表示权重,x表示激活值,b表示偏置。首先需要对量化的均值做校正,对float32算子和量化算子输出的每个通道求平均,假设某个通道i的float32算子输出均值为\(a_i\),量化算子反量化输出均值为\(a_{qi}\),将这个通道两个均值的差\(a_i-a_q\)加到对应的通道上即可使得最终的输出均值和float32一致。另外还需要保证量化后的分布和量化前是一致的,设某个通道权重数据的均值、方差为\(E(w_c)\)、\(||w_c-E(w_c)||\),量化后的均值和方差为\(E(\hat{w_c})\)、\(||\hat{w_c}-E(\hat{w_c})||\),对权重如下校正: \[\hat{w_c}\leftarrow\zeta_c(\hat{w_c}+u_c)\] \[u_c=E(w_c)-E(\hat{w_c})\] \[\zeta_c=\frac{||w_c-E(w_c)||}{||\hat{w_c}-E(\hat{w_c})||}\]
量化方法作为一种通用的模型压缩方法,可以大幅提升神经网络存储和压缩的效率,已经取得了广泛的应用。
模型稀疏
模型稀疏是通过去除神经网络中部分组件(如权重、特征图、卷积核)降低网络的存储和计算代价,它和模型权重量化、权重共享、池化等方法一样,属于一种为达到降低模型计算复杂度的目标而引入的一种强归纳偏置。
模型稀疏的动机
因为卷积神经网络中的卷积计算可以被看作输入数据和卷积核权重的加权线性组合,所以通常绝对值小的权重对输出数据具有相对较小的影响。对模型进行稀疏操作的合理性主要来源于两方面的假设:
-
其一,针对权重参数来说,当前许多神经网络模型存在过参数化(Over-parameterized)的现象,动辄具有几千万甚至数亿规模的参数量。
-
其二,针对模型推理过程中生成的激活值特征图,对于许多检测、分类、分割等视觉任务来说激活值特征图中能利用的有效信息相对于整张图仅占较小的比例。
根据以上描述按照模型稀疏性来源的不同,主要分为权重稀疏和激活值稀疏,它们的目的都是为了减少模型当中的冗余成分来达到降低计算量和模型存储的需求。具体来说,对模型进行稀疏就是根据模型的连接强弱程度(一般根据权重或激活的绝对值大小),对一些强度较弱的连接进行剪枝(将权重参数或激活值置为0)来达到模型稀疏并提高模型推理性能的目的。特别地,将模型权重或激活值张量中0值所占的比例称为模型稀疏度。一般而言,模型稀疏度越高带来的模型准确率下降越大,因此模型稀疏的目标是尽可能在提高模型稀疏度的同时保证模型准确率下降较小。
实际上,如同神经网络本身的发明受到了神经生物学启发一样,神经网络模型稀疏方法同样受到了神经生物学的启发。在一些神经生物学的发现中,人类以及大多数哺乳动物的大脑都会出现一种叫做突触修剪的活动。突触修剪即神经元的轴突和树突发生衰退和完全死亡,这一活动发生在哺乳动物的婴幼儿时期,然后一直持续到成年以后。这种突触修剪机制不断简化和重构哺乳动物大脑的神经元连接,使得哺乳动物的大脑能以更低的能量获得更高效的工作方式。
结构与非结构化稀疏
首先考虑权重稀疏,对于权重稀疏来说,按照稀疏模式的不同,主要分为结构化和非结构化稀疏。简单来讲,结构化稀疏就是在通道或者卷积核层面对模型进行剪枝。这种稀疏方式能够得到规则且规模更小的权重矩阵,因此比较适合CPU和GPU进行加速计算。但与此同时,结构化稀疏是一种粗粒度的稀疏方式,将会对模型的推理准确率造成较大的下降。
而非结构化稀疏,可以对权重张量中任意位置的权重进行裁剪,因此这种稀疏方式属于细粒度的稀疏。这种稀疏方式相对于结构化稀疏,造成的模型准确率下降较小。但是也正是因为这种不规则的稀疏方式,导致稀疏后的模型难以利用硬件获得较高的加速比。其背后原因主要有以下几点:
-
不规则排布的模型权重矩阵会带来大量的控制流指令,比如由于大量0值的存在,会不可避免地引入大量if-else分支判断指令,因此会降低指令层面的并行度。
-
权重矩阵的不规则内存排布会造成线程发散和负载不均衡,而不同卷积核往往是利用多线程进行计算的,因此这也影响了线程层面的并行度。
-
权重矩阵的不规则内存排布造成了较低的访存效率,因为它降低了数据的局部性以及缓存命中率。
为了解决以上非结构化稀疏带来的种种问题,近期出现的研究当中通过引入特定稀疏模式将结构化稀疏和非结构化稀疏结合了起来,从而一定程度上兼具结构化和非结构化稀疏的优点并克服了两者的缺点。
稀疏策略
明确了模型稀疏的对象之后,下一步需要确定模型稀疏的具体策略,具体来说,就是需要决定何时对模型进行稀疏以及如何对模型进行稀疏。目前最常见模型稀疏的一般流程为:预训练、剪枝、微调。具体而言,首先需要训练得到一个收敛的稠密模型,然后在此基础上进行稀疏和微调。选择在预训练之后进行稀疏动作的原因基于这样一个共识,即预训练模型的参数蕴含了学习到的知识,继承这些知识然后进行稀疏要比直接从初始化模型进行稀疏效果更好。除了基于预训练模型进行进一步修剪之外,训练和剪枝交替进行也是一种常用的策略。相比于一步修剪的方法,这种逐步的修剪方式,使得训练和剪枝紧密结合,可以更有效地发现冗余的卷积核,被广泛采用于现代神经网络剪枝方法中。
以下通过一个具体实例(Deep Compression([@han2015deep])) 来说明如何进行网络修剪:如 ch08-fig-deepcomp所示,在去掉大部分的权值之后,深度卷积神经网络的精度将会低于其原始的精度。对剪枝后稀疏的神经网络进行微调,可以进一步提升压缩后网络的精度。剪枝后的模型可以进一步进行量化,使用更低比特的数据来表示权值;此外,结合霍夫曼(Huffman)编码可以进一步地降低深度神经网络的存储。
![Deep Compression([@han2015deep])](img/ch08/deepcomp.png)
除了直接去除冗余的神经元之外,基于字典学习的方法也可以用来去掉深度卷积神经网络中无用的权值。通过学习一系列卷积核的基,可以把原始卷积核变换到系数域上并且它们稀疏。比如,Bagherinezhad等人([@bagherinezhad2017lcnn])将原始卷积核分解成卷积核的基和稀疏系数的加权线性组合。
知识蒸馏
知识蒸馏,也被称为教师-学生神经网络学习算法,已经受到业界越来越多的关注。大型深度网络在实践中往往会获得良好的性能,因为当考虑新数据时,过度参数化会提高泛化性能。在知识蒸馏中,小网络(学生网络)通常是由一个大网络(教师网络)监督,算法的关键问题是如何将教师网络的知识传授给学生网络。通常把一个全新的更深的更窄结构的深度神经网络当作学生神经网络,然后把一个预先训练好的神经网络模型当作教师神经网络。
Hinton等人([@Distill])首先提出了教师神经网络-学生神经网络学习框架,通过最小化两个神经网络之间的差异来学习一个更窄更深的神经网络。记教师神经网络为\(\mathcal{N}_{T}\),它的参数为\(\theta_T\),同时记学生神经网络为\(\mathcal{N}_{S}\),相应的参数为\(\theta_S\)。一般而言,学生神经网络相较于教师神经网络具有更少的参数。
文献([@Distill])提出的知识蒸馏(knowledge distillation,KD)方法,同时令学生神经网络的分类结果接近真实标签并且令学生神经网络的分类结果接近于教师神经网络的分类结果,即, \[\mathcal{L}_{KD}(\theta_S) = \mathcal{H}(o_S,\mathbf{y}) +\lambda\mathcal{H}(\tau(o_S),\tau(o_T))\tag{1}\label{ch08-equ-c2Fcn_distill}\]
其中,\(\mathcal{H}(\cdot,\cdot)\)是交叉熵函数,\(o_S\)和\(o_T\)分别是学生网络和教师网络的输出,\(\mathbf{y}\)是标签。公式 (1)中的第一项使得学生神经网络的分类结果接近预期的真实标签,而第二项的目的是提取教师神经网络中的有用信息并传递给学生神经网络,\(\lambda\)是一个权值参数用来平衡两个目标函数。\(\tau(\cdot)\)是一个软化(soften)函数,将网络输出变得更加平滑。
公式 (1)仅仅从教师神经网络分类器输出的数据中提取有价值的信息,并没有从其他中间层去将教师神经网络的信息进行挖掘。因此,Romero等人[@FitNet])进一步地开发了一种学习轻型学生神经网络的方法,该算法可以从教师神经网络中任意的一层来传递有用的信息给学生神经网络。此外,事实上,并不是所有的输入数据对卷积神经网络的计算和完成后续的任务都是有用的。例如,在一张包含一个动物的图像中,对分类和识别结果比较重要的是动物所在的区域,而不是那些无用的背景信息。所以,有选择性地从教师神经网络的特征图中提取信息是一个更高效的方式。于是,Zagoruyko和Komodakis([@attentionTS])提出了一种基于感知(Attention)损失函数的学习方法来提升学生神经网络的性能,该方法在学习学生神经网络的过程中,引入了感知模块(Attention),选择性地将教师神经网络中的信息传递给学生神经网络,并帮助其进行训练。感知图用来表达输入图像不同位置对最终分类结果的重要性。感知模块从教师网络生成感知图,并迁移到学生网络,如图

图9.3.2 一种基于感知(attention)的教师神经网络-学生神经网络学习算法
知识蒸馏是一种有效的帮助小网络优化的方法,能够进一步和剪枝、量化等其他压缩方法结合,训练得到精度高、计算量小的高效模型。
模型推理
模型推理
训练模型经过前面的转换、压缩等流程后,需要部署在计算硬件上进行推理。执行推理主要包含以下步骤:
- 前处理:将原始数据处理成适合网络输入的数据。
- 执行推理:将离线转换得到的模型部署到设备上执行推理流程,根据输入数据计算得到输出数据。
- 后处理:模型的输出结果做进一步的加工处理,如筛选阈值。
前处理与后处理
前处理
前处理主要完成数据预处理,在现实问题中,原始数据往往非常混乱,机器学习模型无法识别并从中提取信息。数据预处理的目的是将原始数据例如图片、语音、文本等,处理成适合网络输入的tensor数据,并消除其中无关的信息,恢复有用的真实信息,增强有关信息的可检测性,最大限度地简化数据,从而改进模型的特征抽取、图像分割、匹配和识别等可靠性。
常见的数据预处理手段有:
-
特征编码:将描述特征的原始数据编码成数字,输入给机器学习模型,因为它们只能处理数字数据。常见的编码方法有:离散化、序号编码、One-hot编码,二进制编码等;
-
数据归一化:修改数据的值使其达到共同的标度但不改变它们之间的相关性,消除数据指标之间的量纲影响。常用的技术有:Min-Max归一化将数据缩放到给定范围,Z-score归一化使数据符合正态分布;
-
处理离群值: 离群值是与数据中的其他值保持一定距离的数据点,适当地排除离群值可以提升模型的准确性。
后处理
通常,模型推理结束后,需要把推理的输出数据传递给用户完成后处理,常见的数据后处理手段有:
-
连续数据离散化:模型实际用于预测离散数据,例如商品数量时,用回归模型预测得到的是连续值,需要四取五入、取上下限阈值等得到实际结果;
-
数据可视化:将数据图形化、表格化,便于找到数据之间的关系,来决定下一步的分析策略;
-
手动拉宽预测范围:回归模型往往预测不出很大或很小的值,结果都集中在中部区域。例如医院的化验数据,通常是要根据异常值诊断疾病。手动拉宽预测范围,将偏离正常范围的值乘一个系数,可以放大两侧的数据,得到更准确的预测结果。
并行计算
为提升推理的性能,需要重复利用多核的能力,所以一般推理框架会引入多线程机制。主要的思路是将算子的输入数据进行切分,通过多线程去执行不同数据切片,实现算子并行计算,从而成倍提升算子计算性能。
图9.4.1 矩阵乘数据切分
如图所示,对于矩阵乘可以按左矩阵的行进行切分,可以利用三个线程分别计算A1*B,A2*B,A3*B,实现矩阵乘多线程并行计算。
为方便算子并行计算,同时避免频繁创建销毁线程的开销,推理框架一般会使用线程池机制。业界有两种较为通用的做法:
- 使用OpenMP编程接口:OpenMP(Open Multi-Processing,一套支持跨平台共享内存方式的多线程并发的编程API)提供如算子并行最常用的接口"parallel for",实现for循环体的代码被多线程并行执行。
- 推理框架实现针对算子并行计算的线程池,相对OpenMP提供的接口会更有针对性,性能会更高,且更轻量。
算子优化
在部署AI模型时,用户通常期望模型执行训练或推理的时间尽可能地短,以获得更优越的性能。对于深度学习网络,框架调度的时间占比往往很小,性能的瓶颈就在算子的执行。下面从硬件指令和算法角度介绍一些算子优化的方法。
硬件指令优化
绝大多数的设备上都有CPU,因此算子在CPU上的时间尤为重要,下面介绍一下在ARM CPU硬件指令优化的方法。
1. 汇编语言
开发者使用的C++、Java等高级编程语言会通过编译器输出为机器指令码序列,而高级编程语言能做的事通常受编译器所限,汇编语言是靠近机器的语言,可以一对一实现任何指令码序列,编写的程序存储空间占用少、执行速度快、效率优于高级编程语言。
在实际应用中,最好是程序的大部分用高级语言编写,运行性能要求很高的部分用汇编语言来编写,通过混合编程实现优势互补。深度学习的卷积、矩阵乘等算子涉及大量的计算,使用汇编语言能够给模型训练和推理性能带来数十到数百倍量级的提升。
下面以ARMv8系列处理器为例,介绍和硬件指令相关的优化。
2. 寄存器与NEON指令
ARMv8系列的CPU上有32个NEON寄存器v0-v31,如 图9.4.2所示,NEON寄存器v0可存放128bit的数据,即4个float32,8个float16,16个int8等。

图9.4.2 ARMv8处理器NEON寄存器v0的结构
针对该处理器,可以采用SIMD(Single Instruction,Multiple Data,单指令、多数据)提升数据存取计算的速度。相比于单数据操作指令,NEON指令可以一次性操作NEON寄存器的多个数据。例如:对于浮点数的fmla指令,用法为fmla v0.4s, v1.4s, v2.4s,如图 图9.4.3所示,用于将v1和v2两个寄存器中相对应的float值相乘累加到v0的值上。

图9.4.3 fmla指令计算功能
3. 汇编语言优化
对于已知功能的汇编语言程序来说,计算类指令通常是固定的,性能的瓶颈就在非计算指令上。如图 图9.2.1所示,计算机各存储设备类似于一个金字塔结构,最顶层空间最小,但是速度最快,最底层速度最慢,但是空间最大。L1-L3统称为cache(高速缓冲存储器),CPU访问数据时,会首先访问位于CPU内部的cache,没找到再访问CPU之外的主存,此时引入了缓存命中率的概念来描述在cache中完成数据存取的占比。要想提升程序的性能,缓存命中率要尽可能的高。
下面简单列举一些提升缓存命中率、优化汇编性能的手段:
(1)循环展开:尽可能使用更多的寄存器,以代码体积换性能;
(2)指令重排:打乱不同执行单元的指令以提高流水线的利用率,提前有延迟的指令以减轻延迟,减少指令前后的数据依赖等;
(3)寄存器分块:合理分块NEON寄存器,减少寄存器空闲,增加寄存器复用;
(4)计算数据重排:尽量保证读写指令内存连续,提高缓存命中率;
(5)使用预取指令:将要使用到的数据从主存提前载入缓存,减少访问延迟。
算法优化
多数AI模型的推理时间主要耗费在卷积、矩阵乘算子的计算上,占到了整网百分之九十甚至更多的时间。本小节主要介绍卷积算子算法方面的优化手段,可以应用到各种硬件设备上。
卷积的计算可以转换为两个矩阵相乘,在前述 ch08-sec-parallel_inference小节中,已经详细介绍了矩阵乘运算的优化。对于不同的硬件,确定合适的矩阵分块,优化数据访存与指令并行,可以最大限度的发挥硬件的算力,提升推理性能。
1.Img2col
将卷积的计算转换为矩阵乘,一般采用Img2col的方法实现。在常见的神经网络中,卷积的输入通常都是4维的,默认采用的数据排布方式为NHWC,如图 图9.4.4所示,是一个卷积示意图。输入维度为(1,IH,IW,IC),卷积核维度为(OC,KH,KW,IC),输出维度为(1,OH,OW,OC)。
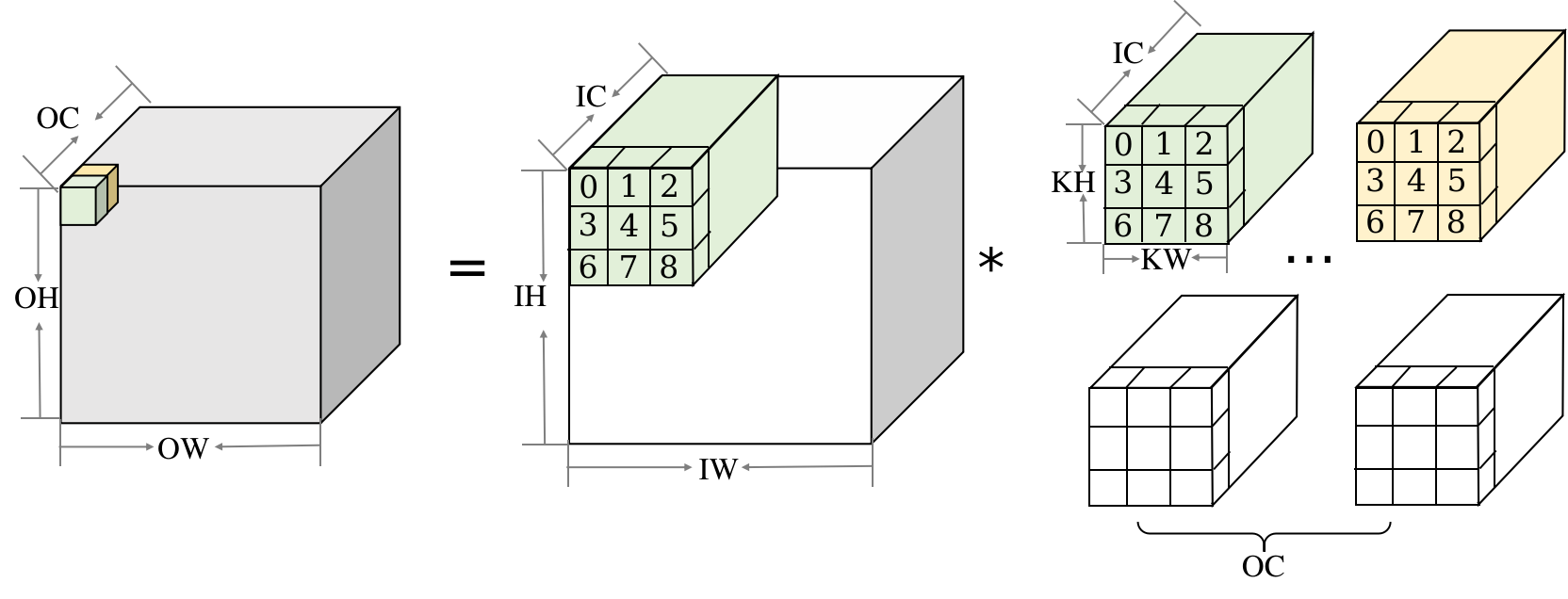
图9.4.4 通用卷积示意图
对卷积的Img2col规则如下。如图 图9.4.5所示,对该输入做重排,得到的矩阵见右侧,行数对应输出的OHOW的个数;对于每个行向量,就对应到一个输出点。计算每个输出点,需要ICKHKW个输入数据,Img2col先排列第一个输入通道的KHKW个输入数据,再排列第二个输入通道的数据,直到第IC个通道。
图9.4.5 输入Img2col的矩阵
如 图9.4.6所示,对权重数据做重排。将1个卷积核展开为权重矩阵的一列,因此共有OC列,每个列向量上先排列第一个输入通道上KH*KW的数据,再依次排列后面的通道直到IC。通过重排,卷积的计算就可以转换为两个矩阵相乘的求解。在实际实现时,Img2col和GEMM的数据重排会同时进行,以节省运行时间。
图9.4.6 卷积核Img2col的矩阵
2.Winograd算法
卷积计算归根到底是矩阵乘法,两个二维矩阵相乘的时间复杂度是\(O(n^3)\)。Winograd算法可以降低矩阵乘法的复杂度。
以一维卷积运算为例,记为\textit{\textbf{F}}(\(m\),\(r\)),其中,\(m\)代表输出的个数,\(r\)为卷积核的个数。输入为\(\textit{\textbf{d}}=[d_0 \ d_1 \ d_2 \ d_3]\),卷积核为\(g=[g_0 \ g_1 \ g_2]^{\rm T}\),该卷积计算可以写成矩阵形式如式 (1)所示,需要6次乘法和4次加法。
\[F(2, 3)=\left[ \begin{matrix} d_0 & d_1 & d_2 \\ d_1 & d_2 & d_3 \end{matrix} \right] \left[ \begin{matrix} g_0 \\ g_1 \\ g_2 \end{matrix} \right]=\left[ \begin{matrix} y_0 \\ y_1 \end{matrix} \right]\tag{1}\label{ch08-equ-conv_matmul_one_dimension}\]
可以观察到,卷积运算转换为矩阵乘法时输入矩阵中存在着重复元素\(d_1\)和\(d_2\),因此,卷积转换的矩阵乘法相对一般的矩阵乘有了优化空间。可以通过计算中间变量\(m_0-m_3\)得到矩阵乘的结果,见式 (2):
\[F(2, 3)=\left[ \begin{matrix} d_0 & d_1 & d_2 \\ d_1 & d_2 & d_3 \end{matrix} \right] \left[ \begin{matrix} g_0 \\ g_1 \\ g_2 \end{matrix} \right]=\left[ \begin{matrix} m_0+m_1+m_2 \\ m_1-m_2-m_3 \end{matrix} \right]\tag{2}\label{ch08-equ-conv-2-winograd}\]
其中,\(m_0-m_3\)的分别见公式 (3):
\[\begin{aligned}m_0=(d_0-d_2)*g_0 \\m_1=(d_1+d_2)*(\frac{g_0+g_1+g_2}{2}) \\m_2=(d_2-d_1)*(\frac{g_0-g_1+g_2}{2}) \\m_3=(d_1-d_3)*g_2\end{aligned}\tag{3}\label{ch08-equ-winograd-param}\]
通过\(m_0-m_3\)间接计算r1,r2,需要的运算次数包括:输入\(d\)的4次加法;输出\(m\)的4次乘法和4次加法。在推理阶段,权重的数值是常量,因此卷积核上的运算可以在图编译阶段计算,不计入在线的run时间。所以总的运算次数为4次乘法和8次加法,与直接运算的6次乘法和4次加法相比,乘法次数减少,加法次数增加。在计算机中,乘法一般比加法慢,通过减少乘法次数,增加少量加法,可以实现加速。
计算过程写成矩阵形式如式 (4)所示,其中,⊙为对应位置相乘,A、B、G都是常量矩阵。这里写成矩阵计算是为了表达清晰,实际使用时,按照公式 (3)手写展开的计算速度更快。
\[\mathbf{Y}=\mathbf{A^T}(\mathbf{G}g)*(\mathbf{B^T}d)\tag{4}\label{ch08-equ-winograd-matrix}\]
\[\mathbf{B^T}=\left[ \begin{matrix} 1 & 0 & -1 & 0 \\ 0 & 1 & 1 & 0 \\ 0 & -1 & 1 & 0 \\ 0 & 1 & 0 & -1 \end{matrix} \right]\tag{5}\label{ch08-equ-winograd-matrix-bt}\]
\[\mathbf{G}=\left[ \begin{matrix} 1 & 0 & 0 \\ 0.5 & 0.5 & 0.5 \\ 0.5 & -0.5 & 0.5 \\ 0 & 0 & 1 \end{matrix} \right]\tag{6}\label{ch08-equ-winograd-matrix-g}\]
\[\mathbf{A^T}=\left[ \begin{matrix} 1 & 1 & -1 & 0 \\ 0 & 1 & -1 & -1 \end{matrix} \right] \\\tag{7}\label{ch08-equ-winograd-matrix-at}\]
通常深度学习领域通常使用的都是2D卷积,将F(2,3)扩展到F(2x2,3x3),可以写成矩阵形式,如公式 (8)所示。此时,Winograd算法的乘法次数为16,而直接卷积的乘法次数为36,降低了2.25倍的乘法计算复杂度。
\[\mathbf{Y}=\mathbf{A^T}(\mathbf{G}g\mathbf{G^T})*(\mathbf{B^T}d\mathbf{B})\mathbf{A}\tag{8}\label{ch08-equ-winograd-two-dimension-matrix}\]
Winograd算法的整个计算过程在逻辑上可以分为4步,如 图9.4.7所示:

图9.4.7 winograd步骤示意图
针对任意的输出大小,要使用\(\textit{\textbf{F}}(2\times2,3\times3)\)的Winograd算法,需要将输出切分成\(2\times2\)的块,找到对应的输入,按照上述的四个步骤,就可以求出对应的输出值。当然,Winograd算法并不局限于求解\(\textit{\textbf{F}}(2\times2,3\times3)\),针对任意的\(\textit{\textbf{F}}(m\times m,r\times r)\),都可以找到适当的常量矩阵\(\textit{\textbf{A}}\)、\(\textit{\textbf{B}}\)、\(\textit{\textbf{G}}\),通过间接计算的方式减少乘法次数。但是随着\(m\)、\(r\)的增大,输入、输出涉及的加法以及常量权重的乘法次数都在增加,那么乘法次数带来的计算量下降会被加法和常量乘法所抵消。因此,在实际使用场景中,还需要根据Winograd的实际收益来选择。
本小节主要介绍了模型推理时的数据处理和性能优化手段。选择合适的数据处理方法,可以更好地提取输入特征,处理输出结果。并行计算以及算子级别的硬件指令与算法优化可以最大限度的发挥硬件的算力。除此之后,内存的占用及访问速率也是影响推理性能的重要因素,因此推理时需要设计合理的内存复用策略,内存复用的策略已经在编译器后端章节已经做了阐述。
模型的安全保护
模型的安全保护
AI服务提供商在本地完成模型训练和调优后,将模型部署到第三方外包平台上(如终端设备、边缘设备和云服务器)来提供推理服务。由于AI模型的设计和训练需要投入大量时间、数据和算力,如何保护模型的知识产权(包括模型结构和参数等信息),防止模型在部署过程中的传输、存储以及运行环节被窃取,已经成为服务/模型提供商最为关心的问题之一。
概述
模型的安全保护可以分为静态保护和动态保护两个方面。静态保护指的是模型在传输和存储时的保护,目前业界普遍采用的是基于文件加密的模型保护方案,AI模型文件以密文形态传输和存储,执行推理前在内存中解密。在整个推理过程中,模型在内存中始终是明文的,存在被敌手从内存中转储的风险。动态保护指的是模型在运行时的保护,目前业界已有的模型运行时保护方案主要有以下三个技术路线:一是基于TEE(Trusted Execution Environment)的模型保护方案,TEE通常指的是通过可信硬件隔离出来的一个“安全区”,AI模型文件在非安全区加密存储和传输,在安全区中解密运行。该方案在CPU上的推理时延较小,但依赖特定可信硬件,有一定的部署难度。此外,受硬件资源约束,难以保护大规模深度模型,且目前仍无法有效支持异构硬件加速。二是基于密态计算的保护方案,该方案基于密码学方法(如同态加密、多方安全计算等),保证模型在传输、存储和运行过程中始终保持密文状态。该方案不依赖特定硬件,但面临非常大的计算或通信开销问题,且无法保护模型结构信息。三是基于混淆的模型保护方案,该方案主要通过对模型的计算逻辑进行加扰,使得敌手即使能获取到模型也无法理解。与前两种技术路线相比,该方案仅带来较小的性能开销,且精度损失很低,同时,不依赖特定硬件,可支持大模型的保护。下面将重点介绍基于混淆的模型保护技术。
模型混淆
模型混淆技术可以自动混淆明文AI模型的计算逻辑,使得攻击者即使在传输和存储时获取到模型也无法理解;且支持模型混淆态执行,保证模型运行时的机密性。同时不影响模型原本的推理结果、仅带来较小的推理性能开销。模型混淆技术主要包含以下几个步骤:
图9.5.1 模型混淆实现步骤图
结合 图9.5.1,详细阐述模型混淆的执行步骤:
(1) 解析模型并获取计算图
对于一个训练好的模型,首先根据模型结构解析模型文件并获取模型计算逻辑的图表达(计算图)用于后续操作。获取的计算图包括节点标识、节点算子类型、节点参数权重以及网络结构等信息。
(2) 对计算图的网络结构加扰
通过图压缩和图增广等技术,对计算图中节点与节点之间的依赖关系进行加扰,达到隐藏模型真实计算逻辑的效果。其中,图压缩通过整图检查来匹配原网络中的关键子图结构,这些子图会压缩并替换为单个新的计算节点。对于压缩后的计算图,图增广通过在网络结构中加入新的输入/输出边,进一步隐藏节点间的真实依赖关系。新增的输入/输出边可以来自/指向图中现已有的节点,也可以来自/指向本步骤新增的混淆节点。
加扰是指在计算图中添加扰动,来达到模型混淆的目的,常用的加扰手段有添加冗余的节点和边、融合部分子图等等。
(3) 对计算图的节点匿名化
遍历步骤(2)处理后的计算图,筛选出需要保护的节点。对于图中的每个需要保护的节点,将节点标识、节点算子类型以及其他能够描述节点计算逻辑的属性替换为无语义信息的符号。对于节点标识匿名化,本步骤保证匿名化后的节点标识仍然是唯一的,以区分不同的节点。对于算子类型匿名化,为了避免大规模计算图匿名化导致的算子类型爆炸问题,可以将计算图中算子类型相同的节点划分为若干不相交的集合,同一个集合中节点的算子类型替换为相同的匿名符号。步骤(5)将保证节点匿名化后,模型仍然是可被识别和执行的。
(4) 对计算图的参数权重加扰
对于每个需要保护的权重,通过一个随机噪声和映射函数对权重进行加扰。每个权重加扰时可以使用不同的随机噪声和映射函数,步骤(6)将保证权重加扰不会影响模型执行结果的正确性。将经过步骤(2)(3)(4)处理后的计算图保存为模型文件供后续使用。
(5) 算子接口变换
步骤(5)(6)将对每个需要保护的算子类型进行算子形态变换,生成若干候选混淆算子。原算子与混淆算子之间是一对多的对应关系,候选混淆算子的数量等于步骤(3)划分的节点集合的数量。 本步骤根据步骤(2)(3)(4)的得到的匿名化算子类型、算子输入/输出关系等信息,对相应算子的接口进行变换。算子接口的变换方式包括但不局限于输入输出变换、接口名称变换。其中,输入输出变换通过修改原算子的输入输出数据,使得生成的混淆算子与原算子的接口形态不同。新增的输入输出数据包括步骤(2)图增广新增的节点间数据依赖和步骤(4)权重混淆引入的随机噪声。接口名称变换将原算子名称替换为步骤(3)生成的匿名化算子名称,保证节点匿名化后的模型仍然是可被识别和执行的,且算子的名称不会泄露其计算逻辑。
(6) 算子实现变换
对算子的代码实现进行变换。代码实现的变换方式包括但不局限于字符串加密、冗余代码等软件代码混淆技术,保证混淆算子与原算子实现语义相同的计算逻辑,但是难以阅读和理解。不同的算子可以采用不同代码混淆技术的组合进行代码变换。除代码等价变形之外,混淆算子还实现了一些额外的计算逻辑,如对于步骤(4)中参数被加扰的算子,混淆算子也实现了权重加扰的逆映射函数,用于在算子执行过程中动态消除噪声扰动,保证混淆后模型的计算结果与原模型一致。将生成的混淆算子保存为库文件供后续使用。
(7) 部署模型和算子库
将混淆态模型文件以及相应的混淆算子库文件部署到目标设备上。
(8) 混淆模型加载
根据模型结构解析混淆态模型文件并获取模型计算逻辑的图表达,即经过步骤(2)(3)(4)处理后得到的混淆计算图。
(9) 计算图初始化
对计算图进行初始化,生成执行任务序列。根据安全配置选项,若需要保护模型运行时安全,则直接对混淆计算图进行初始化,生成执行任务序列,序列中的每个计算单元对应一个混淆算子或原算子的执行。若仅需保护模型传输和存储时安全,则可先将内存中的混淆计算图恢复为原计算图,然后对原计算图进行初始化,生成执行任务序列,序列中的每个单元对应一个原算子的执行,这样可以进一步降低推理时的性能开销。
(10) 推理任务执行
根据AI应用程序输入的推理数据,遍历执行任务序列中的每个计算单元,得到推理结果。若当前计算单元对应的算子是混淆算子时,调用混淆算子库;否则,调用原算子库。
总结
总结
-
不同的模型部署场景下,通常对于模型大小、运行时内存占用、推理时延和推理功耗等指标有限制。
-
针对模型大小指标,通常在离线阶段通过模型压缩技术来优化,比如量化技术、剪枝技术、知识蒸馏技术等,除此之外,一部分模型优化技术,比如融合技术等,也有助于模型轻量化,不过其效果比较微弱。
-
针对运行时内存指标,主要有三方面的优化:优化模型大小、优化部署框架包大小以及优化运行时临时内存。模型大小的优化手段在上一点中已经说明;部署框架包大小主要通过精简框架代码、框架代码模块化等方式来优化。运行时临时内存主要通过内存池实现内存之间的复用来优化。
-
针对模型的推理时延指标,主要有两方面的优化,一方面是离线时通过模型优化技术和模型压缩技术尽可能降低模型推理所需的计算量;另一方面是通过加大推理的并行力度和优化算子实现来充分挖掘硬件的计算潜力。值得注意的是,除了考虑计算量和算力,推理时的访存开销也是一个重要的影响因素。
-
针对模型的推理功耗,主要的优化思路是降低模型的计算量,这与针对模型推理时延的优化手段有重合之处,可以参考离线的模型优化技术和模型压缩技术。
-
本章除了介绍优化模型部署的各方面指标的优化技术以外,还介绍了安全部署相关的技术,如模型混淆、模型加密等。部署安全一方面可以保护企业的重要资产,另一方面可以防止黑客通过篡改模型从而入侵攻击部署环境。
扩展阅读
-
Google量化白皮书 量化
-
诺亚高精度剪枝算法 剪枝
-
针对多核处理器的自动图并行调度框架 性能优化
-
诺亚量子启发的低比特量化算法 量化
-
诺亚GhostNet极简骨干网络 网络结构替换
-
诺亚加法神经网络 [网络结构替换](https://arxiv.org/abs/1912.13200)
分布式训练
随着机器学习的进一步发展,科学家们设计出更大型、更多功能的机器学习模型(例如GPT-3)。这种模型含有大量参数和复杂的结构。他们因此需要海量的计算和内存资源。单个机器上有限的资源无法满足训练大型机器学习模型的需求。因此,需要设计分布式训练系统,从而将一个机器学习模型任务拆分成多个子任务,并将子任务分发给多个计算节点,解决资源瓶颈。
本章引入分布式机器学习系统的相关概念、设计挑战、系统实现和实例研究。首先讨论分布式训练系统的定义、设计动机和好处。然后进一步讨论常见的分布式训练方法:数据并行、模型并行和流水线并行。在实际中,这些分布式训练方法会被集合通信(Collective Communication)或者参数服务器(Parameter Servers)实现。不同的系统实现具有各自的优势和劣势。
本章的学习目标包括:
-
掌握分布式训练相关系统组件的设计。
-
掌握常见的分布式训练方法:数据并行、模型并行和流水线并行。
-
掌握常见的分布式训练框架实现:集合通信和参数服务器。
系统概述
系统概述
设计动机
分布式训练系统主要为了解决单节点的算力和内存不足的问题。
算力不足
单处理器的算力不足是促使人们设计分布式训练系统的一个主要原因。一个处理器的算力可以用每秒钟浮点数操作(Floating Point Operations Per Second,FLOPS)来衡量。图10.1.1分析了机器学习模型对于算力的需求以及同期处理器所提供算力在过去数年中变化。其中,用千万亿运算次数/秒—天(Petaflop/s—day )这一指标来衡量算力。这个指标等价于每秒\(10^{15}\)次神经网络操作执行一天,也就是总共大约\(10^{20}\)次计算操作。如图所示,根据摩尔定律(Moore’s Law),中央处理器的算力每18个月增长2倍。虽然计算加速卡(如GPU和TPU)针对机器学习计算提供了大量的算力。这些加速卡的发展最终也受限于摩尔定律,增长速度停留在每18个月2倍。而与此同时,机器学习模型正在快速发展。短短数年,机器学习模型从仅能识别有限物体的AlexNet,一路发展到在复杂任务中打败人类的AlphaStar。这期间,模型对于算力需求每18个月增长了56倍。解决处理器性能和算力需求之间鸿沟的关键就在于利用分布式计算。通过大型数据中心和云计算设施,可以快速获取大量的处理器。通过分布式训练系统有效管理这些处理器,可以实现算力的快速增长,从而持续满足模型的需求。
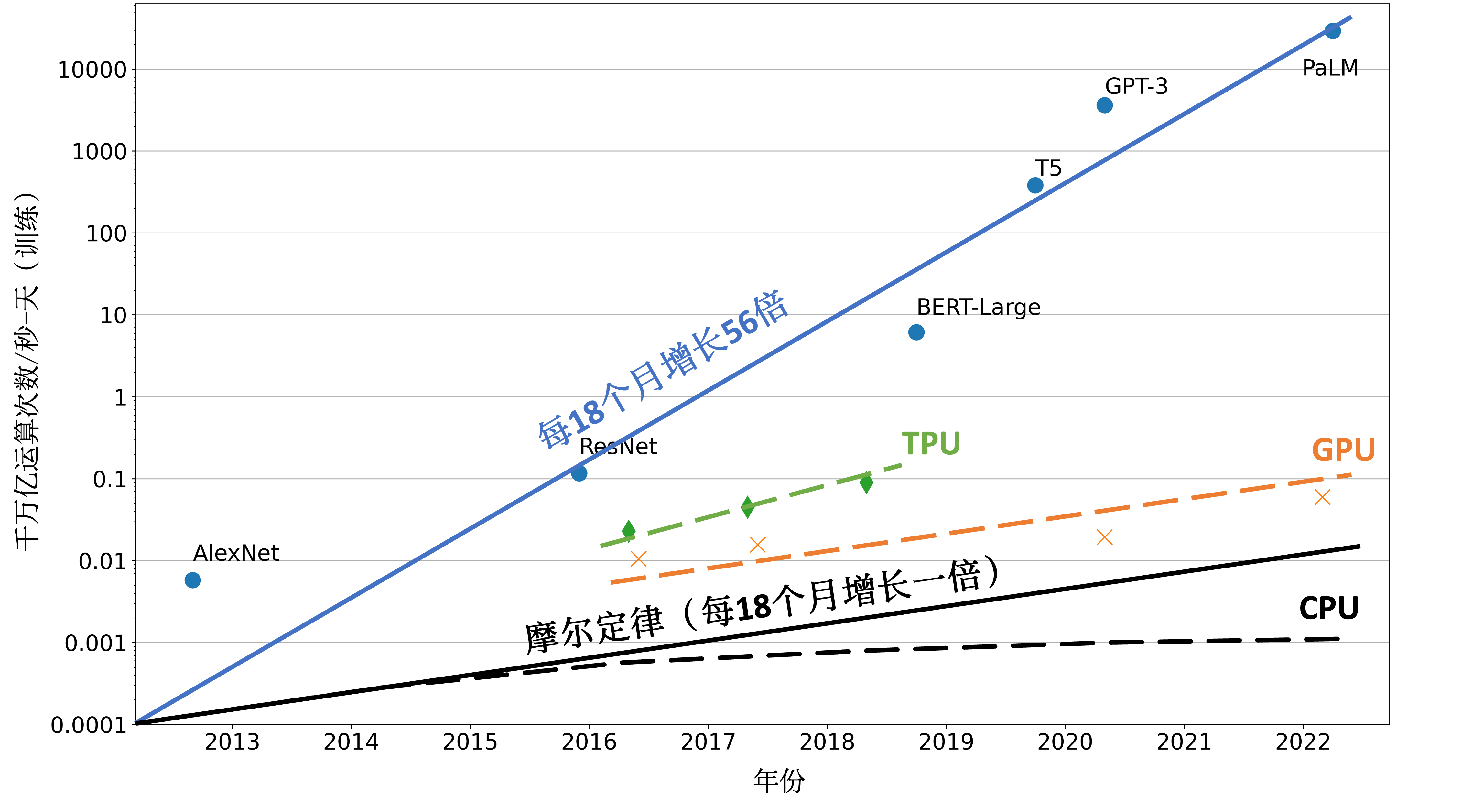
图10.1.1 对比机器学习模型参数量增长和计算硬件的算力增长
内存不足
训练机器学习模型需要大量内存。假设一个大型神经网络模型具有1000亿的参数,每个参数都由一个32位浮点数(4个字节)表达,存储模型参数就需要400GB的内存。在实际中,我们需要更多内存来存储激活值和梯度。假设激活值和梯度也用32位浮点数表达,那么其各自至少需要400GB内存,总的内存需求就会超过1200GB(即1.2TB)。而如今的硬件加速卡(如NVIDIA A100)仅能提供最高80GB的内存。单卡内存空间的增长受到硬件规格、散热和成本等诸多因素的影响,难以进一步快速增长。因此,我们需要分布式训练系统来同时使用数百个训练加速卡,从而为千亿级别的模型提供所需的TB级别的内存。
系统架构
为了方便获得大量用于分布式训练的服务器,人们往往依靠云计算数据中心。一个数据中心管理着数百个集群,每个集群可能有几百到数千个服务器。通过申请其中的数十台服务器,这些服务器进一步通过分布式训练系统进行管理,并行完成机器学习模型的训练任务。
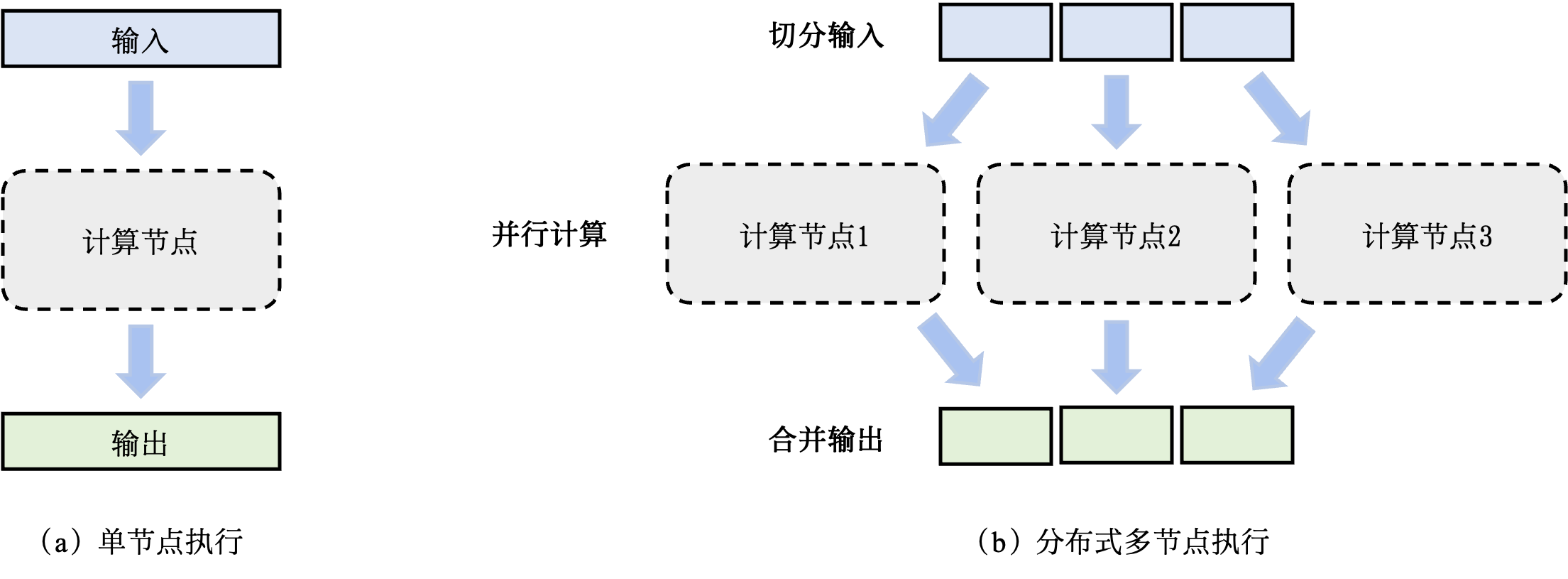
图10.1.2 单节点计算和多节点分布式计算
为了确保分布式训练系统的高效运行,需要首先估计系统计算任务的计算和内存用量。假如某个任务成为了瓶颈,系统会切分输入数据,从而将一个任务拆分成多个子任务。子任务进一步分发给多个计算节点并行完成。图10.1.2描述了这一过程。一个模型训练任务(Model Training Job)往往会有一组数据(如训练样本)或者任务(如算子)作为输入,利用一个计算节点(如GPU)生成一组输出(如梯度)。分布式执行一般具有三个步骤:第一步将输入进行切分;第二步将每个输入部分会分发给不同的计算节点,实现并行计算;第三步将每个计算节点的输出进行合并,最终得到和单节点等价的计算结果。这种首先切分,然后并行,最后合并的模式,本质上实现了分而治之(Divide-and-Conquer)的方法:由于每个计算节点只需要负责更小的子任务,因此其可以更快速地完成计算,最终实现对整个计算过程的加速。
用户益处
通过使用分布式训练系统可以获得以下几个优点:
-
提升系统性能:使用分布式训练,往往可以带来训练性能的巨大提升。一个分布式训练系统一般用“到达目标精度所需的时间”(Time-to-Accuracy)这个指标来衡量系统性能。这个指标由两个参数决定: (1)完成一个数据周期的时间,和(2)完成一个数据周期后模型所提升的精度。通过持续增加并行处理节点,可以将数据周期的完成时间不断变短,最终显著减少到达目标精度所需的时间。
-
减少成本,体现经济性:使用分布式训练也可以进一步减少模型训练的成本。受限于单节点散热的上限,单节点的算力越高,其所需的散热硬件成本也更高。因此,在提供同等算力的条件下,组合多个计算节点是一个更加经济高效的方式。这促使云服务商(如亚马逊和微软等)更加注重给用户提供成本高效的分布式机器学习系统。
-
防范硬件故障:分布式训练系统同时能有效提升防范硬件故障的能力。机器学习训练集群往往由商用硬件(Commodity Hardware)组成,这类硬件(例如磁盘和网卡)运行一定时间就会产生故障。而仅使用单个机器进行训练,一个机器的故障就会造成模型训练任务的失败。通过将该模型训练任务交由多个机器共同完成,即使一个机器出故障,也可以通过将该机器上相应的计算子任务转移给其余机器,继续完成训练,从而避免训练任务的失败。
实现方法
实现方法
下面讨论分布式训练系统实现的常用并行方法。首先给出并行方法的设计目标以及分类。然后详细描述各个并行方法。
概述
分布式训练系统的设计目标是:将单节点训练系统转换成等价的并行训练系统,从而在不影响模型精度的条件下完成训练过程的加速。一个单节点训练系统往往如 图10.2.1所示。一个训练过程会由多个数据小批次(mini-batch)完成。在图中,一个数据小批次被标示为数据。训练系统会利用数据小批次生成梯度,提升模型精度。这个过程由一个训练程序实现。在实际中,这个程序往往实现了一个多层神经网络的执行过程。该神经网络的执行由一个计算图(Computational Graph)表示。这个图有多个相互连接的算子(Operator),每个算子会拥有计算参数。每个算子往往会实现一个神经网络层(Neural Network Layer),而参数则代表了这个层在训练中所更新的的权重(Weights)。
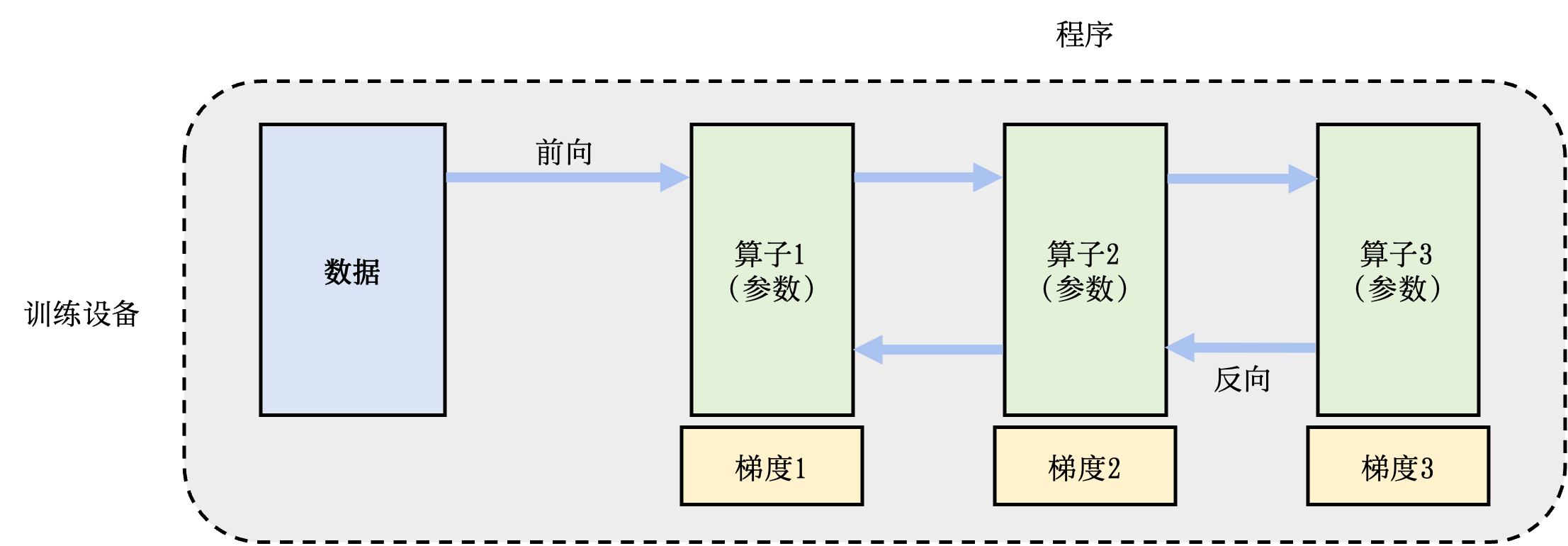
图10.2.1 单节点训练系统
为了更新参数,计算图的执行分为前向计算和反向计算两个阶段。前向计算的第一步会将数据读入第一个算子,该算子会根据当前的参数,计算出计算给下一个算子的数据。算子依次重复这个前向计算的过程(执行顺序:算子1,算子2,算子3),直到最后一个算子结束。最后的算子随之马上开始反向计算。反向计算中,每个算子依次计算出梯度(执行顺序:梯度3,梯度2,梯度1),并利用梯度更新本地的参数。反向计算最终在第一个算子结束。反向计算的结束也标志本次数据小批次的结束,系统随之读取下一个数据小批次,继续更新模型。
- 给定一个模型训练任务,人们会对数据和程序切分(Partition),从而完成并行加速。 ch10-parallel-methods总结了不同的切分方法。单节点训练系统可以被归类于单程序单数据模式。而假如用户希望使用更多的设备实现并行计算,首先可以选择对数据进行分区,并将同一个程序复制到多个设备上并行执行。这种方式是单程序多数据模式,常被称为数据并行(Data Parallelism)。另一种并行方式是对程序进行分区(模型中的算子会被分发给多个设备分别完成)。这种模式是多程序单数据模式,常被称为模型并行(Model Parallelism)。当训练超大型智能模型时,开发人员往往要同时对数据和程序进行切分,从而实现最高程度的并行。这种模式是多程序多数据模式,常被称为混合并行(Hybrid Parallelism)。
-
分布式训练方法分类
接下来详细讲解各种并行方法的执行过程。
数据并行
数据并行往往可以解决单节点算力不足的问题。这种并行方式在人工智能框架中最为常见,具体实现包括:TensorFlow DistributedStrategy、PyTorch Distributed、Horovod DistributedOptimizer等。在一个数据并行系统中,假设用户给定一个训练批大小为\(N\),并且希望使用\(M\)个并行设备来加速训练。那么,该训练批大小会被分为\(M\)个分区,每个设备会分配到\(N/M\)个训练样本。这些设备共享一个训练程序的副本,在不同数据分区上独立执行、计算梯度。不同的设备(假设设备编号为\(i\))会根据本地的训练样本计算出梯度\(G_i\)。为了确保训练程序参数的一致性,本地梯度\(G_i\)需要聚合,计算出平均梯度\((\sum_{i=1}^{N} G_i) / N\)。最终,训练程序利用平均梯度修正模型参数,完成小批次的训练。
图10.2.2展示了两个设备构成的数据并行训练系统(Data Parallel Training System)的例子。假设用户给定的数据批大小是64,那么每个设备会分配到32个训练样本,并且具有相同的神经网络参数(程序副本)。本地的训练样本会依次通过这个程序副本中的算子,完成前向计算和反向计算。在反向计算的过程中,程序副本会生成局部梯度。不同设备上对应的局部梯度(如设备1和设备2上各自的梯度1)会进行聚合,从而计算平均梯度。这个聚合的过程往往由集合通信的AllReduce操作完成。
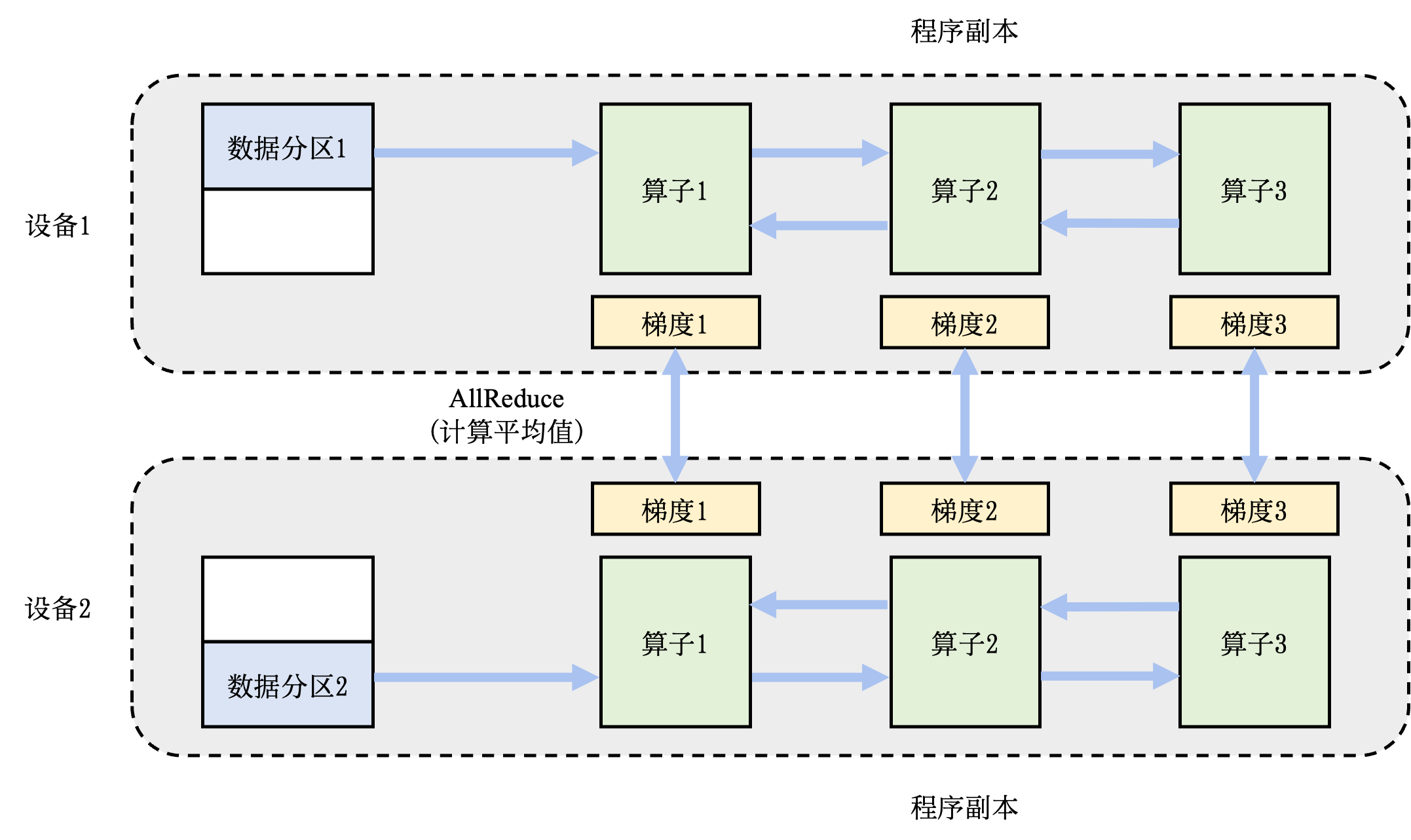
图10.2.2 数据并行训练系统
模型并行
模型并行往往用于解决单节点内存不足的问题。一个常见的内存不足场景是模型中含有大型算子,例如深度神经网络中需要计算大量分类的全连接层。完成这种大型算子计算所需的内存可能超过单设备的内存容量。那么需要对这个大型算子进行切分。假设这个算子具有\(P\)个参数,而系统拥有\(N\)个设备,那么可以将\(P\)个参数平均分配给\(N\)个设备(每个设备分配\(P/N\)个参数),从而让每个设备负责更少的计算量,能够在内存容量的限制下完成前向计算和反向计算。这种切分方式是模型并行训练系统(Model Parallelism Training System)的一种应用,也被称为算子内并行(Intra-operator Parallelism)。
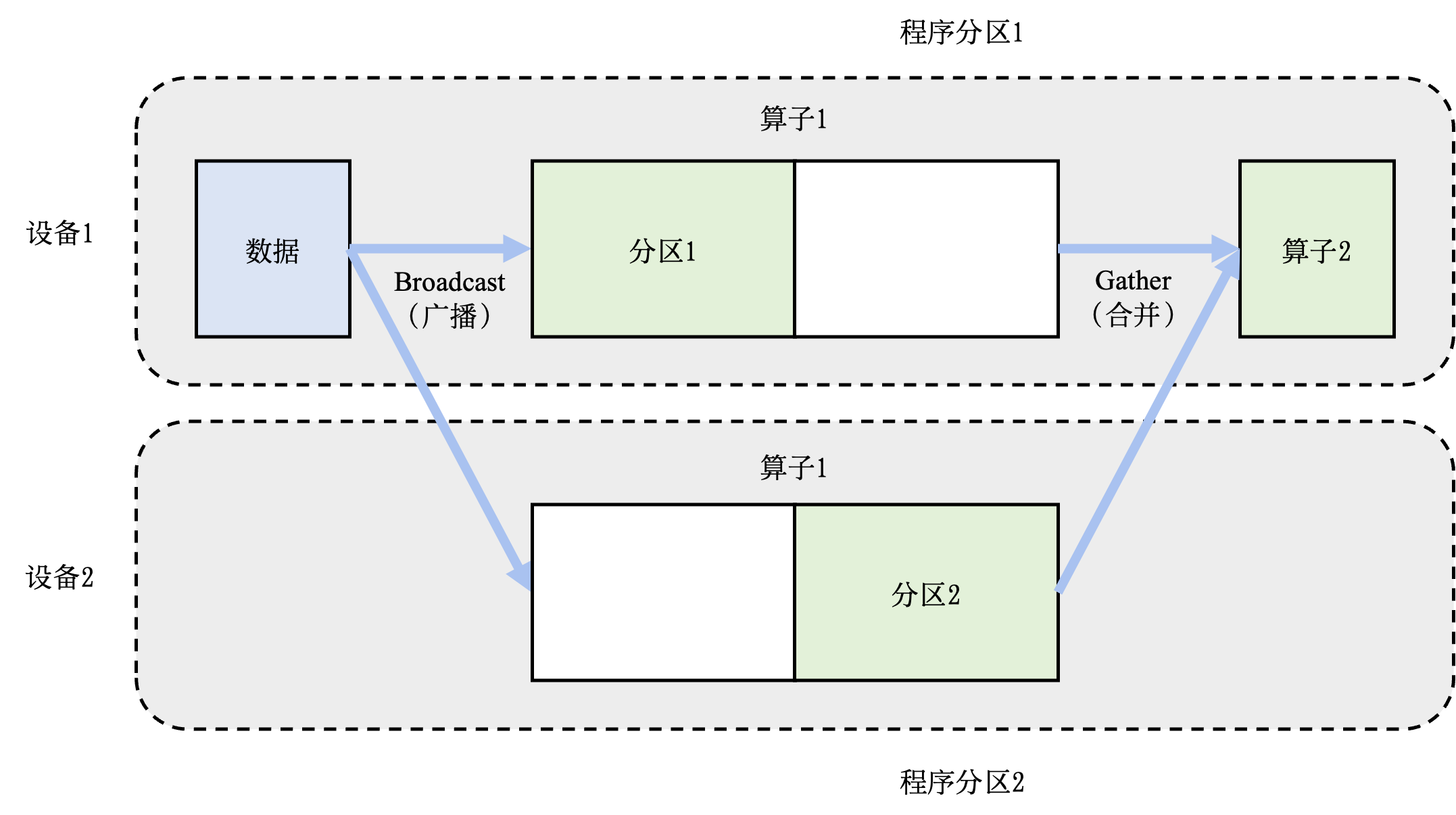
图10.2.3 模型并行训练系统:算子内并行
图10.2.3给出了一个由两个设备实现的算子内并行的例子。在这个例子中,假设一个神经网络具有两个算子,算子1的计算(包含正向和反向计算)需要预留16GB的内存,算子2的计算需要预留1GB的内存。而本例中的设备最多可以提供10GB的内存。为了完成这个神经网络的训练,需要对算子1实现并行。具体做法是,将算子1的参数平均分区,设备1和设备2各负责其中部分算子1的参数。由于设备1和设备2的参数不同,因此它们各自负责程序分区1和程序分区2。在训练这个神经网络的过程中,训练数据(按照一个小批次的数量)会首先传给算子1。由于算子1的参数分别由两个设备负责,因此数据会被广播(Broadcast)给这两个设备。不同设备根据本地的参数分区完成前向计算,生成的本地计算结果需要进一步合并,发送给下游的算子2。在反向计算中,算子2的数据会被广播给设备1和设备2,这些设备根据本地的算子1分区各自完成局部的反向计算。计算结果进一步合并计算回数据,最终完成反向计算。
另一种内存不足的场景是:模型的总内存需求超过了单设备的内存容量。在这种场景下,假设总共有\(N\)个算子和\(M\)个设备,可以将算子平摊给这\(M\)个设备,让每个设备仅需负责\(N/M\)个算子的前向和反向计算,降低设备的内存开销。这种并行方式是模型并行的另一种应用,被称为算子间并行(Inter-operator Parallelism)。
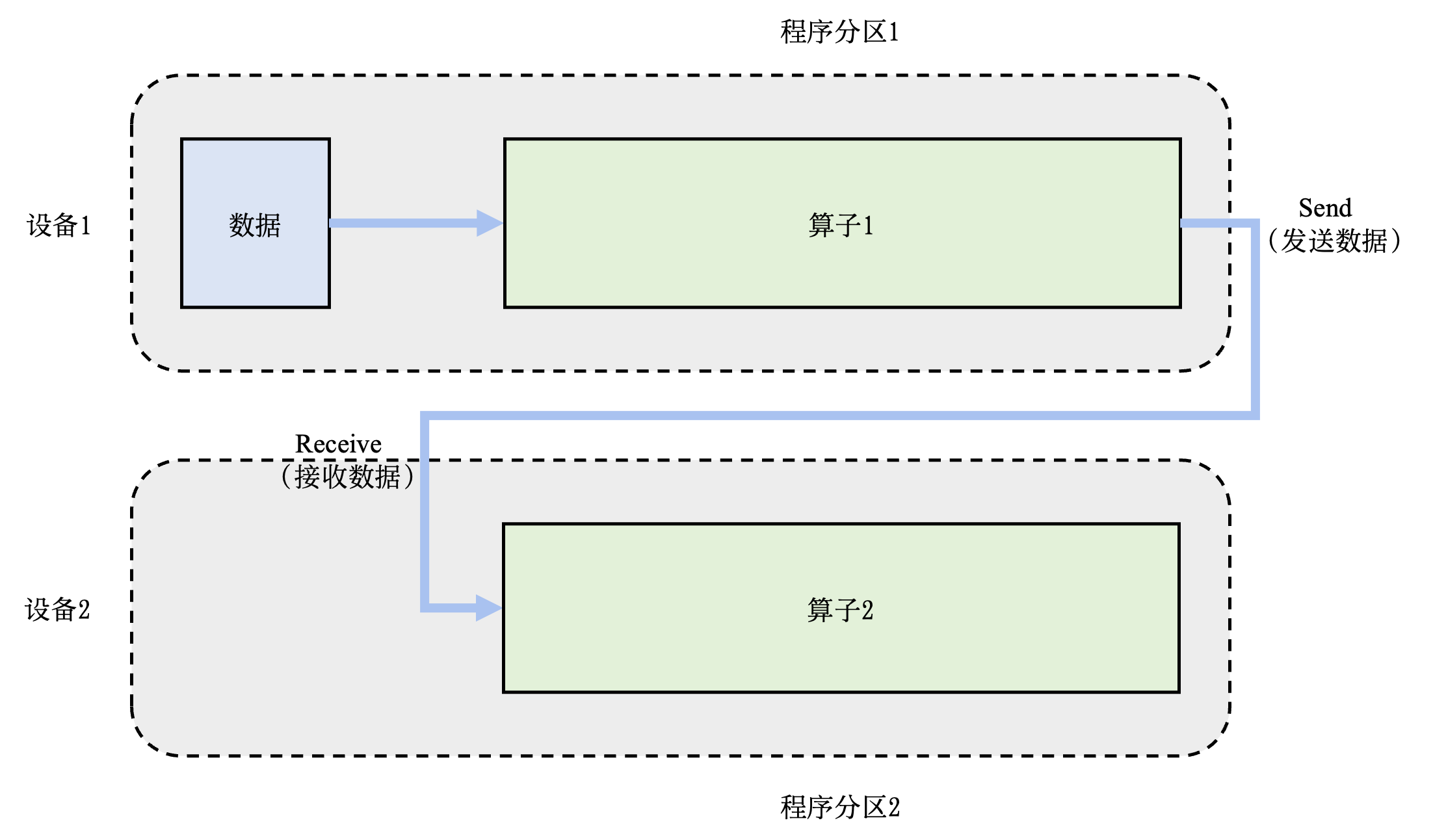
图10.2.4 模型并行训练系统:算子间并行
图10.2.4给出了一个由两个设备实现的算子间并行的例子。在这个例子中,假设一个神经网络具有两个算子,算子1和算子2各自需要10GB的内存完成计算,则模型总共需要20GB的内存。而每个设备仅能提供10GB内存。在这个例子中,用户可以把算子1放置在设备1上,算子2放置在设备2上。在前向计算中,算子1的输出会被发送(Send)给下游的设备2。设备2接收(Receive)来自上游的数据,完成算子2的前向计算。在反向计算中,设备2将算子2的反向计算结果发送给设备1。设备1完成算子1的反向计算,完成本次小批次(Mini-Batch)的训练。
混合并行
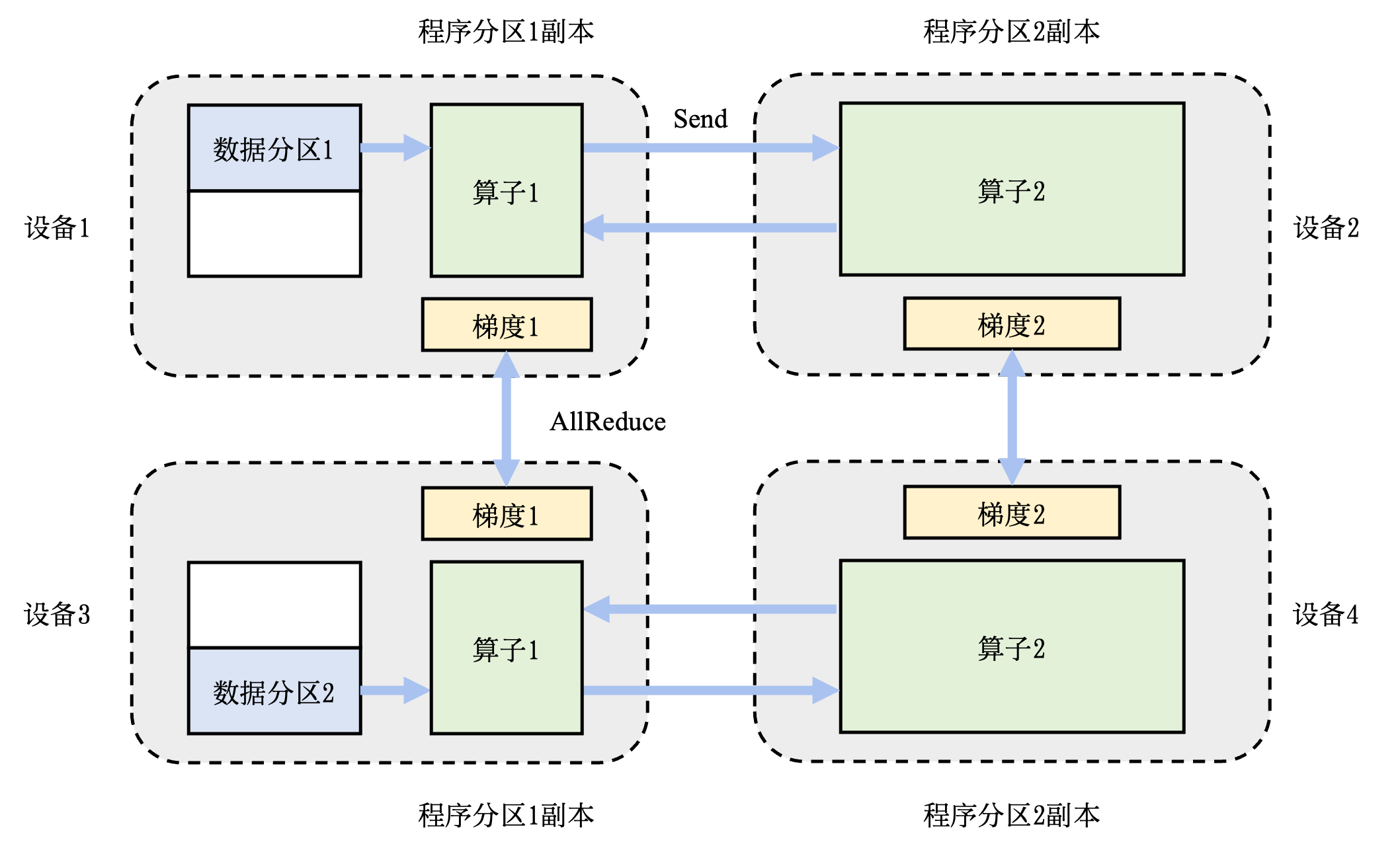
图10.2.5 混合并行系统
在训练大型人工智能模型中,往往会同时面对算力不足和内存不足的问题。因此,需要混合使用数据并行和模型并行,这种方法被称为混合并行。 图10.2.5提供了一个由4个设备实现的混合并行的例子。在这个例子中,首先实现算子间并行解决训练程序内存开销过大的问题:该训练程序的算子1和算子2被分摊到了设备1和设备2上。进一步,通过数据并行添加设备3和设备4,提升系统算力。为了达到这一点,对训练数据进行分区(数据分区1和数据分区2),并将模型(算子1和算子2)分别复制到设备3和设备4。在前向计算的过程中,设备1和设备3上的算子1副本同时开始,计算结果分别发送(Send)给设备2和设备4完成算子2副本的计算。在反向计算中,设备2和设备4同时开始计算梯度,本地梯度通过AllReduce操作进行平均。反向计算传递到设备1和设备3上的算子1副本结束。
流水线并行
除了数据并行和模型并行以外,流水线并行是另一种常用的实现分布式训练的方法。流水线并行往往被应用在大型模型并行系统中。这种系统通过算子内并行和算子间并行解决单设备内存不足的问题。然而,这类系统的运行中,计算图中的下游设备(Downstream Device)需要长期持续处于空闲状态,等待上游设备(Upstream Device)的计算完成,才可以开始计算,这极大降低了设备的平均使用率。这种现象称为模型并行气泡(Model Parallelism Bubble)。
为了减少气泡,通常可以在训练系统中构建流水线。这种做法是将训练数据中的每一个小批次划分为多个微批次(Micro-Batch)。假设一个小批次有\(D\)个训练样本,将其划分为\(M\)个微批次,那么一个微批次就有\(D/M\)个数据样本。每个微批次依次进入训练系统,完成前向计算和反向计算,计算出梯度。每个微批次对应的梯度将会缓存,等到全部微批次完成,缓存的梯度会被加和,算出平均梯度(等同于整个小批次的梯度),完成模型参数的更新。
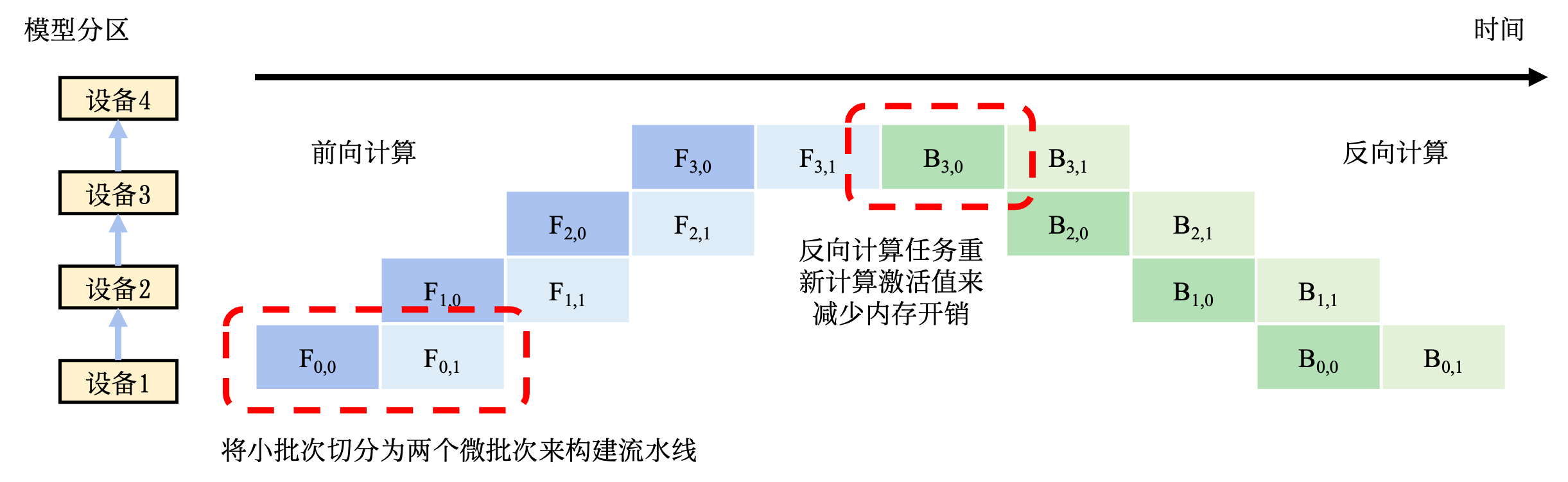
图10.2.6 流水线并行训练系统(Pipeline Parallel Training System)
图10.2.6 给出了一个流水线训练系统的执行例子。在本例中,模型参数需要切分给4个设备存储。为了充分利用这4个设备,将小批次切分为两个微批次。假设\(F_{i,j}\)表示第\(j\)个微批次的第\(i\)个前向计算任务,\(B_{i,j}\)表示第\(j\)个微批次的第\(i\)个反向计算任务。当设备1完成第一个微批次的前向计算后(表示为\(F_{0,0}\)),会将中间结果发送给设备2,触发相应的前向计算任务(表示为\(F_{1,0}\))。与此同时,设备1也可以开始第二个微批次的前向计算任务(表示为\(F_{0,1}\))。前向计算会在流水线的最后一个设备,即设备3,完成。
系统于是开始反向计算。设备4开始第1个微批次的反向计算任务(表示为\(B_{3,0}\))。该任务完成后的中间结果会被发送给设备3,触发相应的反向计算任务(表示为\(B_{2,0}\))。与此同时,设备4会缓存对应第1个微批次的梯度,接下来开始第2个微批次计算(表示为\(B_{3,1}\))。当设备4完成了全部的反向计算后,会将本地缓存的梯度进行相加,并且除以微批次数量,计算出平均梯度,该梯度用于更新模型参数。
需要注意的是,计算梯度往往需要前向计算中产生的激活值。经典模型并行系统中会将激活值缓存在内存中,反向计算时就可以直接使用,避免重复计算。而在流水线训练系统中,由于内存资源紧张,前向计算中的激活值往往不会缓存,而是在反向计算中重新计算(Recomputation)。
在使用流水线训练系统中,时常需要调试微批次的大小,从而达到最优的系统性能。当设备完成前向计算后,必须等到全部反向计算开始,在此期间设备会处于空闲状态。在 图10.2.6中,可以看到设备1在完成两个前向计算任务后,要等很长时间才能开始两个反向计算任务。这其中的等待时间即被称为流水线气泡(Pipeline Bubble)。为了减少设备的等待时间,一种常见的做法是尽可能地增加微批次的数量,从而让反向计算尽可能早开始。然而,使用非常小的微批次,可能会造成微批次中的训练样本不足,从而无法充分的利用起来硬件加速器中的海量计算核心。因此最优的微批次数量由多种因素(如流水线深度、微批次大小和加速器计算核心数量等)共同决定。
机器学习集群架构
机器学习集群架构
机器学习模型的分布式训练通常会在计算集群(Compute Cluster)中实现。接下来,我们将介绍计算集群的构成,特别是其集群网络的设计。
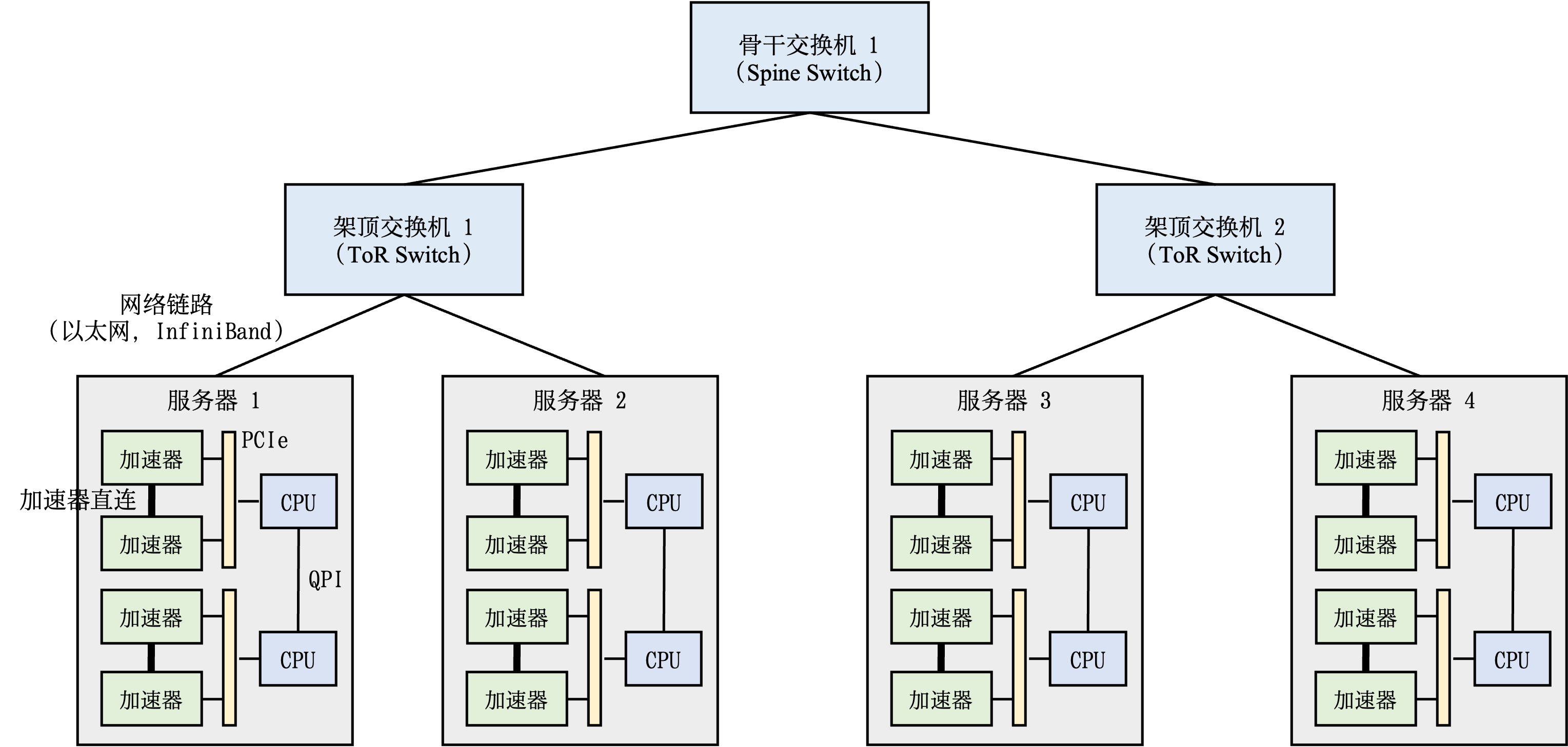
图10.3.1 机器学习集群架构
图10.3.1 描述了一个机器学习集群的典型架构。这种集群中会部署大量带有硬件加速器的服务器。每个服务器中往往有多个加速器。为了方便管理服务器,多个服务器会被放置在一个机柜(Rack)中,同时这个机柜会接入一个架顶交换机(Top of Rack Switch)。在架顶交换机满载的情况下,可以通过在架顶交换机间增加骨干交换机(Spine Switch)进一步接入新的机柜。这种连接服务器的拓扑结构往往是一个多层树(Multi-Level Tree)。
需要注意的是,在集群中跨机柜通信(Cross-Rack Communication)往往会有网络瓶颈。这是因为集群网络为了便于硬件采购和设备管理,会采用统一规格的网络链路。因此,在架顶交换机到骨干交换机的网络链路常常会形成网络带宽超额认购(Network Bandwidth Oversubscription),即峰值带宽需求会超过 实际网络带宽。如 图10.3.1 的集群内,当服务器1和服务器2利用各自的网络链路(假设10Gb/s)往服务器3发送数据时,架顶交换机1会汇聚2倍数据(即20Gb/s)需要发往骨干交换机1。然而骨干交换机1和架顶交换机1 之间只有一条网络链路(10Gb/s)。这里,峰值的带宽需求是实际带宽的两倍,因此产生网络超额订购。在实际的机器学习集群中,实际带宽和峰值带宽的比值一般在1:4到1:16之间。因此如果将网络通信限制在机柜内,从而避免网络瓶颈成为了分布式机器学习系统的核心设计需求。
那么,在计算集群中训练大型神经网络需要消耗多少网络带宽呢?假设给定一个千亿级别参数的神经网络(比如OpenAI 发布的大型语言模型GPT-3有最多将近1750亿参数),如果用32位浮点数来表达每一个参数,那么每一轮训练迭代(Training Iteration)训练中,一个数据并行模式下的模型副本(Model Replica)则需要生成700GB,即175G \(*\) 4 bytes = 700GB,的本地梯度数据。假如有3个模型副本,那么至少需要传输1.4TB,即700GB \(*\) \((3-1)\),的梯度数据。这是因为对于\(N\)个副本,只需传送其中的\(N-1\)个副本完成计算。当平均梯度计算完成后,需要进一步将其广播(Broadcast)到全部的模型副本(即1.4TB的数据)并更新其中的本地参数,从而确保模型副本不会偏离(Diverge)主模型中的参数。
当前的机器学习集群一般使用以太网(Ethernet)构建不同机柜之间的网络。主流的商用以太网链路带宽一般在10Gb/s到25Gb/s之间。这里需要注意的是,网络带宽常用Gb/s为单位,而内存带宽常用GB/s为单位。前者以比特(bit)衡量,后者以字节(byte)衡量。
利用以太网传输海量梯度会产生严重的传输延迟。新型机器学习集群(如英伟达的DGX系列机器)往往配置有更快的InfiniBand。单个InfiniBand链路可以提供100Gb/s或200Gb/s的带宽。即使拥有这种高速网络,传输TB级别的本地梯度依然需要大量延迟(即使忽略网络延迟,1TB的数据在200Gb/s的链路上传输也需要至少40s)。InfiniBand的编程接口以远端内存直接读取(Remote Direct Memory Access,RDMA)为核心,提供了高带宽,低延迟的数据读取和写入函数。然而,RDMA的编程接口和传统以太网的TCP/IP的Socket接口有很大不同,为了解决兼容性问题,人们可以用IPoIB (IP-over-InfiniBand)技术。这种技术确保了遗留应用(Legacy Application)可以保持Socket调用,而底层通过IPoIB调用InfiniBand的RDMA接口。
为了在服务器内部支持多个加速器(通常2-16个),通行的做法是在服务器内部构建一个异构网络。以 图10.3.1 中的服务器1为例,这个服务器放置了两个CPU,CPU之间通过QuickPath Interconnect (QPI)进行通信。而在一个CPU接口(Socket)内,加速器和CPU通过PCIe总线(Bus)互相连接。由于加速器往往采用高带宽内存(High-Bandwidth Memory,HBM)。HBM的带宽(例如英伟达A100的HBM提供了1935 GB/s的带宽)远远超过PCIe的带宽(例如英伟达A100服务器的PCIe 4.0只能提供64GB/s的带宽)。在服务器中,PCIe需要被全部的加速器共享。当多个加速器同时通过PCIe进行数据传输时,PCIe就会成为显著的通信瓶颈。为了解决这个问题,机器学习服务器往往会引入加速器高速互连(Accelerator High-speed Interconnect),例如英伟达A100 GPU的NVLink提供了600 GB/s的带宽,从而绕开PCIe进行高速通信。
集合通信
集合通信
下面讨论如何利用集合通信在机器学习集群中实现分布式训练系统。作为并行计算的一个重要概念,集合通信经常被用来构建高性能的单程序流/多数据流(Single Program-Multiple Data, SPMD)程序。接下来,首先会介绍集合通信中的常见算子。然后描述如何使用AllReduce算法解决分布式训练系统中网络瓶颈,并且讨论AllReduce算法在不同网络拓扑结构下的差异性以及重要性能指标的计算方法。最后介绍现有机器学习系统对不同集合通信算法的支持
常见集合通信算子
下面首先定义一个简化的集合通信模型,然后引入常见的集合通信算子:Broadcast、Reduce、AllGather、Scatter和 AllReduce。需要指出的是,在分布式机器学习的实际场景下,人们还会使用许多其他的集合通信算子,如ReduceScatter、Prefix Sum、Barrier、All-to-All等,但由于篇幅限制,便不再赘述。
通信模型
假定在一个分布式机器学习集群中,存在\(p\)个计算设备,并由一个网络来连接所有的设备。每个设备有自己的独立内存,并且所有设备间的通信都通过该网络传输。同时,每个设备都有一个编号\(i\),其中\(i\)的范围从\(1\)到\(p\)。 设备之间的点对点(Point-to-Point, P2P)通信由全双工传输(Full-Duplex Transmission)实现。该通信模型的基本行为可以定义如下:
- 每次通信有且仅有一个发送者(Sender)和一个接收者(Receiver)。在某个特定时刻,每个设备仅能至多发送或接收一个消息(Message)。每个设备可以同时发送一个消息和接收一个消息。一个网络中可以同时传输多个来自于不同设备的消息。
- 传输一个长度为\(l\)个字节(Byte)的消息会花费\(a+b \times l\)的时间,其中\(a\)代表延迟(Latency),即一个字节通过网络从一个设备出发到达另一个设备所需的时间;\(b\)代表传输延迟(Transmission Delay),即传输一个具有\(l\)个字节的消息所需的全部时间。前者取决于两个设备间的物理距离(如跨设备、跨机器、跨集群等),后者取决于通信网络的带宽。需要注意的是,这里简化了传输延迟的定义,其并不考虑在真实网络传输中会出现的丢失的消息(Dropped Message)和损坏的消息(Corrupted Message)的情况。
根据上述通信模型,我们可以定义集合通信算子,并且分析算子的通信性能。下面介绍一些常见的集合通信算子。
Broadcast
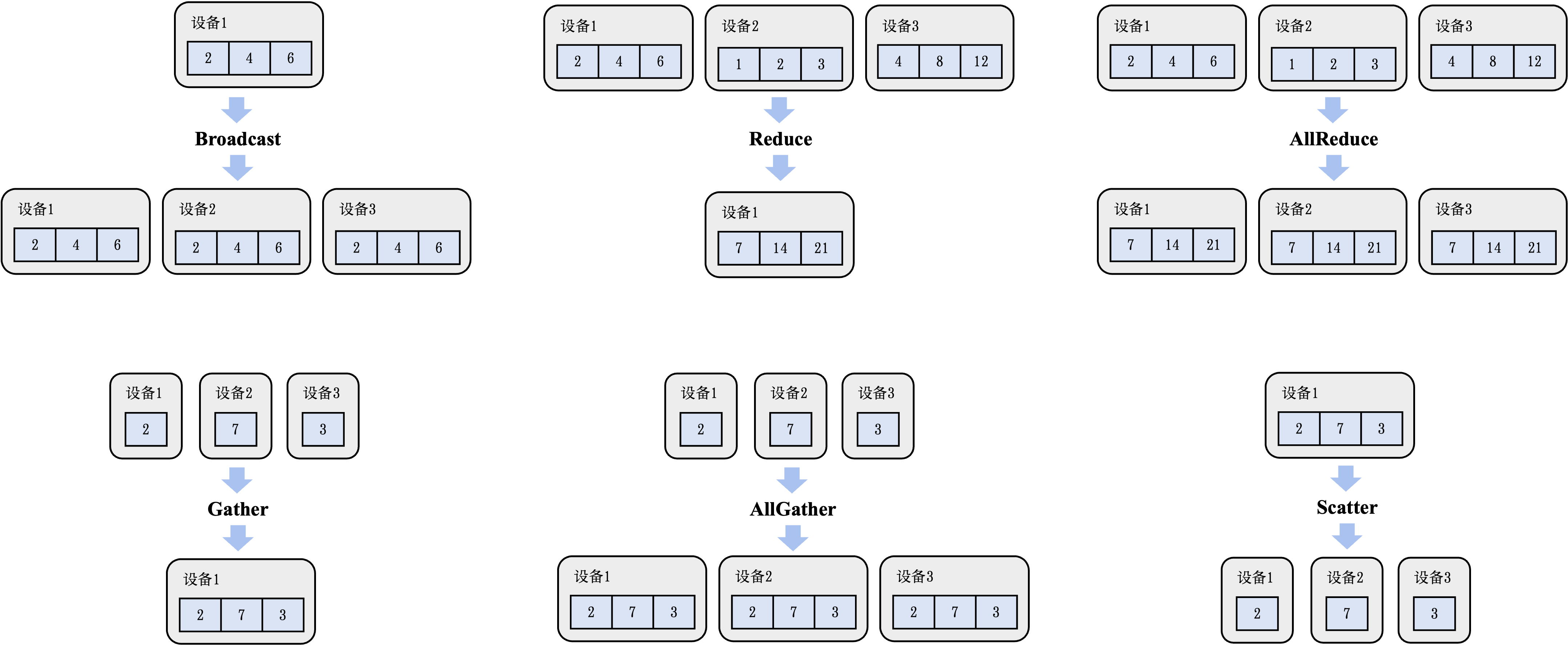
图10.4.1 常用集合通信算子
一个分布式机器学习系统经常需要将一个设备\(i\)上的模型参数或者配置文件广播(Broadcast)给其余全部设备。因此,可以把Broadcast算子定义为从编号为\(i\)的设备发送长度为\(l\)字节的消息给剩余的\(p-1\)个设备。 图10.4.1展示了设备1(在三个设备的集群里)调用Broadcast的初始和结束状态。
一种简单实现Broadcast的算法是在设备\(i\)上实现一个循环,该循环使用\(p-1\)次Send/Receive操作来将数据传输给相应设备。然而,该算法不能达到并行通信的目的(该算法只有\((a+b \times l) \times (p-1)\)的线性时间复杂度)。为此,可以利用分治思想对上述简单实现的Broadcast算法进行优化。假设所有的设备可以重新对编号进行排列,使得Broadcast的发送者为编号为\(1\)的设备。同时,为了简化计算过程,假设对某个自然数\(n\),\(p = 2^n\)。 现在,可以通过从1 向 \(p/2\) 发送一次信息把问题转换为两个大小为\(p/2\)的子问题:编号为1的设备对编号1到编号\(p/2-1\) 的Broadcast,以及编号为\(p/2\)的设备对编号\(p/2\)到编号\(p\)的Broadcast。我们便可以通过在这两个子问题上进行递归来完成这个算法,并把临界条件定义为编号为\(i\)的设备在\([i,i]\)这个区间中的Broadcast。此时,由于\(i\)本身已经拥有该信息,不需要做任何操作便可直接完成Broadcast。这个优化后的算法为\((a+b \times l) \times \log p\) 时间复杂度,因为在算法的每一阶段(编号为\(t\)),有\(2^t\)个设备在并行运行Broadcast算子。同时,算法一定会在\(\log p\) 步之内结束。
Reduce
在分布式机器学习系统中,另一个常见的操作是将不同设备上的计算结果进行聚合(Aggregation)。例如,将每个设备计算的本地梯度进行聚合,计算梯度之和(Summation)。这些聚合函数(表达为\(f\))往往符合结合律(Associative Law)和交换律(Commutative Law)。这些函数由全部设备共同发起,最终聚合结果存在编号为\(i\)的设备上。常见聚合函数有加和、乘积、最大值和最小值。集合通信将这些函数表达为Reduce算子。 图10.4.1展示了设备1调用Reduce来进行加和的初始和结束状态。
一个简易的Reduce的优化实现同样可以用分治思想来实现,即把\(1\)到\(p/2-1\)的Reduce结果存到编号为\(1\)的设备中,然后把\(p/2\)到\(p\)的Reduce结果存到\(p/2\)上。最后,可以把\(p/2\)的结果发送至\(1\),执行\(f\),并把最后的结果存至\(i\)。假设\(f\)的运行时间复杂度为常数并且其输出信息的长度\(l\)不改变,Reduce的时间复杂度仍然为\((a+b \times l) \times \log p\)。
AllReduce
集合通信通过引入AllReduce算子,从而将Reduce函数\(f\)的结果存至所有设备上。图10.4.1展示了设备1,设备2和设备3共同调用AllReduce来进行加和的初始和结束状态。
一种简单的AllReduce实现方法是首先调用Reduce算法并将聚合结果存到编号为\(1\)的设备上。然后,再调用Broadcast算子将聚合结果广播到所有的设备。这种简单的AllReduce实现的时间复杂度为\((a+b \times l) \times \log p\)。
Gather
Gather算子可以将全部设备的数据全部收集(Gather)到编号为\(i\)的设备上。 图10.4.1展示了设备1调用Gather来收集全部设备的数据的初始和结束状态。
在收集函数(Gather Function)符合结合律和交换律的情况下,可以通过将其设为Reduce算子中的\(f\)来实现Gather算子。但是,在这种情况下,无论是基于链表还是数组的实现,在每一步的Reduce操作中\(f\)的时间复杂度和输出长度\(l\)都发生了改变。因此,Gather的时间复杂度是\(a \times \log p + (p-1) \times b \times l\)。这是因为在算法的每一阶段\(t\),传输的信息长度为\(2^{t} \times l\)。
AllGather
AllGather算子会把收集的结果分发到全部的设备上。 图10.4.1展示了设备1,设备2和设备3共同调用AllGather的初始和结束状态。
在这里,一个简单的方法是使用Gather和Broadcast算子把聚合结果先存到编号为1的设备中,再将其广播到剩余的设备上。这会产生一个\(a \times \log p + (p-1) \times b \times l + (a+p \times l \times b) \times \log p\)的时间复杂度,因为在广播时,如果忽略链表/数组实现所带来的额外空间开销,每次通信的长度为\(pl\)而不是\(l\)。简化后,得到了一个\(a \times \log p + p \times l \times b \times \log p\) 的时间复杂度。在一个基于超立方体的算法下,可以将其进一步优化到和Gather算子一样的时间复杂度\(a \times \log p + (p-1) \times b \times l\),由于篇幅问题此处便不再赘述。
Scatter
Scatter算子可以被视作Gather算子的逆运算:把一个存在于编号为\(i\)的设备上,长度为\(p\)(信息长度为\(p \times l\))的链式数据结构\(L\)中的值分散到每个设备上,使得编号为\(i\)的设备会得到\(L[i]\)的结果。 图10.4.1展示了设备1调用Scatter的初始和结束状态。
可以通过模仿Gather算法设计一个简易的Scatter实现:每一步的运算中,我们把现在的子链继续对半切分,并把前半段和后半段作为子问题进行递归。这时候,在算法的每一阶段\(t\),传输的信息长度为\(l \times 2^{(m-t)}\),其中\(m\)是算法总共运行的步骤,不会超过\(\log p\) (见Broadcast算子的介绍)。最终,Scatter算子的简易实现和Gather算子一样都有\(a \times \log p + (p-1) \times b \times l\) 的时间复杂度。在机器学习系统中,Scatter算子经常同时被用于链式数据结构和可切分的数据结构,例如张量在一个维度上的\(p\)等分等。
基于AllReduce的梯度平均算法
下面讨论如何利用AllReduce算子实现大型集群中的高效梯度平均。首先,参照前面的分析,可以考虑一种简单的计算平均梯度的方法:在集群中分配一个设备收集本地梯度,并在计算平均梯度后再将其广播到全部的设备。这种做法易于实现,但是引入了两个问题。首先,多台设备同时给该聚合设备发送数据时,聚合设备会因严重的带宽不足产生网络拥塞。其次,单台设备需要负担大量的梯度平均计算,而受限于单台设备上的有限算力,这种计算往往会受限于算力瓶颈。
为了解决上述问题,可以引入AllReduce算子的Reduce-Broadcast实现来优化算法,其设计思路是:通过让全部的节点参与到梯度的网络通信和平均计算中,将巨大的网络和算力开销均摊给全部节点。这种做法可以解决先前单个梯度聚合节点的问题。假设有\(M\)个设备,每个设备存有一个模型副本,该模型由\(N\)个参数/梯度构成。那么按照AllReduce算子的要求,需要先将全部的参数按照设备数量切分成\(M\)个分区(Partition),使得每个分区具有\(N/M\)个参数。首先给出这个算法的初始和结束状态。如 图10.4.1的AllReduce的例子所示,该例子含有3个设备。在每个设备有一个模型副本的情况下,这个副本有3个参数。那么按照AllReduce的分区方法,参数会被划分成3个分区(3个设备),而每一个分区则有1个参数(\(N/M\),\(N\)代表3个参数,\(M\)代表3个设备)。在这个例子中,假定设备1拥有参数2,4,6,设备2拥有参数1,2,3,设备3拥有参数4,8,12,那么在使用一个AllReduce算子进行计算过后,全部的设备都将拥有梯度相加后的结果7,14,21,其中分区1的结果7是由3个设备中分区1的初始结果相加而成(7 = 1 + 2 + 4)。为了计算平均梯度,每个设备只需要在最后将梯度之和除以设备数量即可(分区1的最终结果为7除以3)。
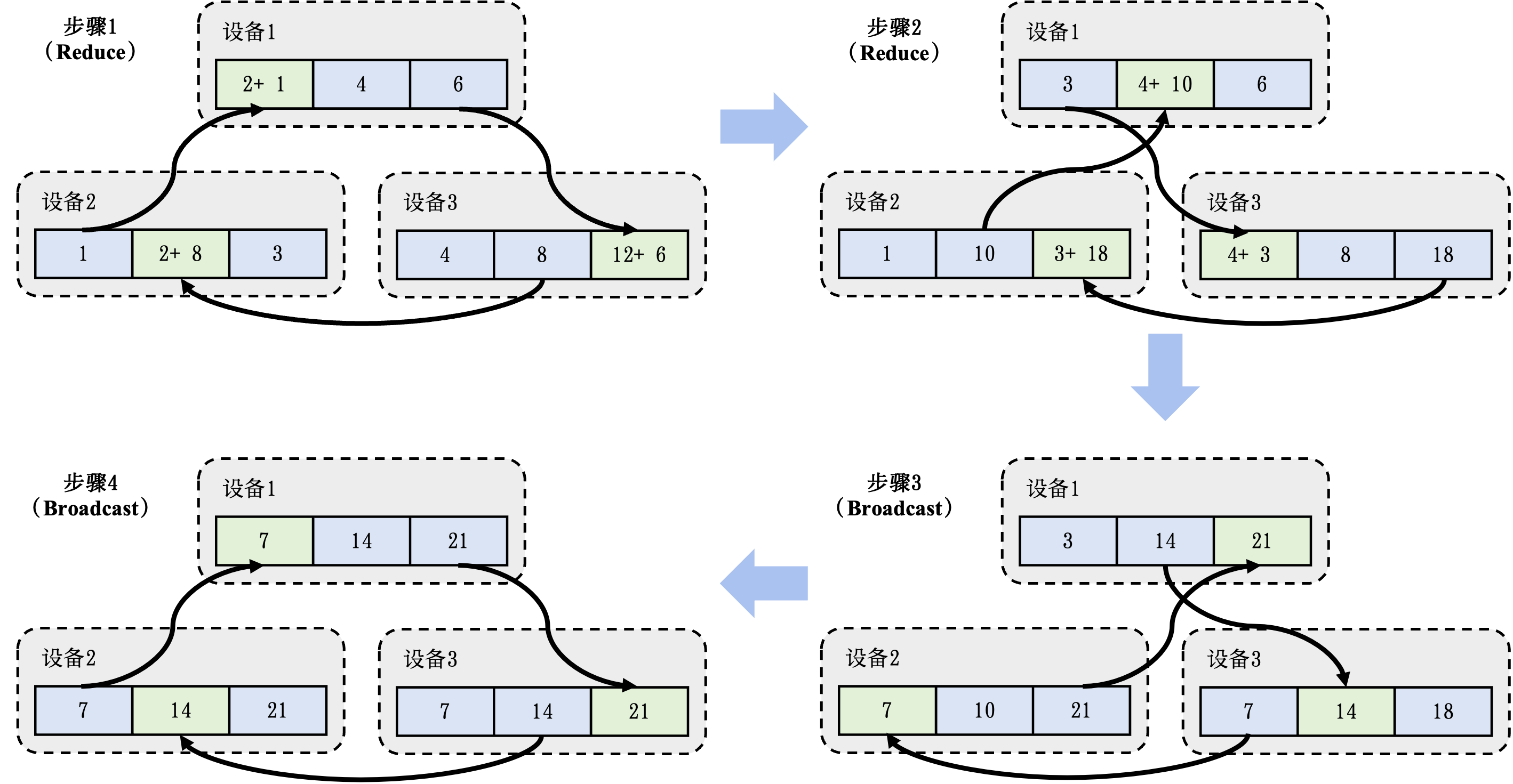
图10.4.2 AllReduce算法的过程
AllReduce算子会把梯度的计算拆分成\(M-1\)个Reduce算子和\(M-1\)个Broadcast算子(其中\(M\)是节点的数量)。其中,Reduce算子用于计算出梯度的加和,Broadcast算子用于把梯度之和广播给全部的节点。 图10.4.2展示了一个AllReduce算子的执行过程。AllReduce算子由Reduce算子开始,在第一个Reduce算子中,AllReduce算子会对全部节点进行配对(Pairing),让它们共同完成梯度相加的操作。在 图10.4.2的第一个Reduce算子中,设备1和设备2进行了配对共同对分区1的数据相加。其中,设备2把本地的梯度数据1发送给设备1,设备1将接收到的梯度数据1和本地的分区1内的梯度数据2进行相加,计算出中间梯度相加的结果3。与此同时,设备1和设备3进行配对,共同完成对分区3的数据相加。而设备3和设备2进行配对,共同完成对于分区2的数据相加。
上述的Reduce算子对梯度的分布式计算实现了以下的性能优化:
- 网络优化: 全部设备都同时在接收和发送数据,利用起了每个设备的入口(Ingress)和出口(Egress)带宽。因此在AllReduce算法的过程中,可利用的带宽是\(M * B\),其中\(M\)是节点数量,\(B\)是节点带宽,从而让系统实现网络带宽上的可扩展性。
- 算力优化: 全部设备的处理器都参与了梯度相加的计算。因此在AllReduce算法的过程中,可利用的处理器是\(M * P\),其中\(M\)是节点数量,\(P\)是单个设备的处理器数量,从而让系统实现计算上的可扩展性。
- 负载均衡: 由于数据分区是平均划分的,因此每次设备分摊到的通信和计算开销是相等的。
在接下来的Reduce算子中,AllReduce算法会对不同数据分区选择另外的配对方法。例如,在 图10.4.2 的第二个Reduce算子中,AllReduce算法会将设备1和设备3进行配对,负责分区1的数据相加。将设备1和设备2进行配对,负责分区2。将设备2和设备3进行配对,负责分区3。在一个3个节点的AllReduce集群里,在2个Reduce算子完成后,就计算出了每个分区的数据相加结果(分区1的数据相加结果7此时在设备3上,分区2的数据相加结果14此时在设备1上,分区3的数据相加结果21此时在设备2上)。
接下来,AllReduce算法将进入Broadcast阶段。这一阶段的过程和Reduce算子类似,核心区别是节点进行配对后,它们不再进行数据相加,而是将Reduce的计算结果进行广播。在 图10.4.2 中的第一个Broadcast算子中,设备1会将分区2的结果14直接写入设备3的分区2中。设备2会将分区3的结果21直接写入设备1中。设备3会将分区1的结果直接写入设备2中。在一个3个节点的AllReduce集群中,我们会重复2次Broadcast算子将每个分区的Reduce结果告知全部的节点。
在本节中,我们讨论了AllReduce的其中一种常用实现方法。根据集群网络拓扑的不同,人们也会用以下的方法来实现AllReduce:树形结构,环形结构,二维环面结构以及CollNet。在此我们不展开讨论。
集合通信算法性能分析
在讨论集合通信算子的性能时,人们经常会使用一些数值化指标量化不同的算法实现。在计算点对点通信所需的时间时,会在信息长度上乘以一个系数\(b\)。这个数值化指标就是算法带宽(Algorithm Bandwidth),泛指单位时间内执行操作(通信和计算等)的数量。一般计算公式为\(b = s/t\),其中\(s\)代指操作的大小,\(t\)指操作指定的两个端点之间所经过的时间。以P2P通信举例,可以通过衡量一个大小已知的信息\(m\)在执行Send函数时所花的时间来确定两个设备之间网络的带宽。
前文提到,在计算点对点通信所需的时间是,会在信息长度之上乘以一个系数b。这个系数就是算法带宽,泛指单位时间内执行操作(通信,计算等)的数量。一般计算公式为\(b = s/t\),其中\(s\)代指操作的大小,\(t\)指操作指定的两个端点之间所经过的时间。以点到点通信举例,我们可以通过衡量一个大小已知的信息\(m\)在执行send函数时所花的时间来确定两个处理单元之间网络的带宽。
虽然算法带宽的计算方法既简单又高效,但很难将其拓展至对于集合通信算子的带宽计算。这是因为,取决于具体算子和算法实现的不同,一个集合通信算子在执行过程中测得的算法带宽往往会远小于硬件本身的最高带宽。在实际运行相应的测试中,经常能观测到随着设备增加,算法带宽呈下降趋势。为了解决这一问题,NCCL提出了总线带宽(Bus Bandwidth)这一数值化指标,将根据每个集合通信算子的分析所测得的算法带宽乘以一个校正系数(Correction Factor),从而给出贴近实际硬件表现的带宽值。下面给出常见算子的校正系数:
- AllReduce:对于在设备\(n_1, n_2, \cdots, n_p\) 上的值 \(v_1, v_2, \cdots, v_p\) 计算 \(v_1 o v_2 o \cdots o v_p\)(其中\(o\)为符合结合律的算子),再存回每个设备中。在不考虑实际实现算法和网络拓扑的情况下,这个操作在理论上只需要\(2 \times (p-1)\)次数据传输,其中包含在每个设备上分开进行的\(p-1\)次 \(o\)的运算,以及最后 \(p\) 次最终数据值的广播,再减去第一个设备的运算和最后一个设备的广播对运行时间的影响。假设每个设备对于外界所有信息处理的带宽为\(B\),可以得出对于\(S\)个在不同设备上的数据运行AllReduce算子能得到最优情况下的运行时间:\(t = (2 \times S \times (p-1)) / (p*B)\),进行简化后可得 \(B = (S/t) \times (2 \times (p-1)/p) = b (2 \times (p-1)/p)\)。这里的 \(2(p-1)/p\)便是校正系数。
- ReduceScatter:对于每个设备来说,可以把ReduceScatter理解为只执行AllReduce中的聚合部分。对此,只需要考虑上面分析中的\(n-1\)次\(op\)的运算,整理后可得\(B = (S/t) \times ((p-1)/p) = b \times ((p-1)/p)\)。即校正系数为\(b \times ((p-1)/p)\)。
- AllGather:对于每个设备来说,可以把AllGather理解为只执行AllReduce中的广播部分,同理可得\(B = (S/t) \times ((p-1)/p) = b \times ((p-1)/p)\)。即校正系数为\(b \times ((p-1)/p)\)。
- Broadcast:与AllReduce不同的是,Broadcast中所有数据需要从算子本身的发送者发出。即使在上面分治的情况下,也需要等待所有子问题运行结束才能确保Broadcast算子本身的正确性。因此,在计算带宽时,瓶颈仍为发送者对于外界所有信息处理的带宽,所以 \(B = S/t\),即校正系数为\(1\)。
- Reduce:Reduce需要将所有数据送往算子的接收者,因此校正系数为\(1\)。
由于Gather和Scatter的带宽计算与实际聚合/分散时的数据结构相关性更高,故不给出特定的校正系数。
利用集合通信优化模型训练的实践
针对不同的集群,机器学习系统往往会灵活组合不同集合通信算子来最大化通信效率。下面提供两个案例分析:ZeRO和DALL-E。
ZeRO
ZeRO是微软提出的神经网络优化器,在实践中成功训练了2020年世界上最大的语言模型(高达1700亿参数)。在训练这个级别的神经网络时优化器本身的参数,反向计算时的梯度,以及模型参数本身都会对加速器内存空间产生极大的压力。通过简易的计算不难得出,1700亿参数的模型在32位浮点表示情况下会占用至少680GB的内存,远超于现在内存最高的加速器A100 (最高内存80GB)。于是,需要考虑如何高效地把模型切成数份存储在不同的加速器上,以及如何高效地通过使用集合通信算子来进行模型训练和推理。这里,介绍三个主要的关于集合通信的优化技术:
- 单一节点上的参数存储: 现代集群中节点内部加速器的带宽远大于节点之间的带宽。为此,需要尽量减少节点间的通信,并且保证大部分通信仅存在于节点内部的加速器之间。在观察模型切片时,又可得模型本身前向和反向计算时需要在不同切片之间进行的通信远小于不同模型副本梯度平均的通信量。针对这一特性,ZeRO选择了将单一模型的全部切片存储到同一节点内部,从而大大提高了训练效率。
- 基于AllGather算子的前向计算: 假设模型中的参数在层级上呈线性,便可按照参数在网络上的顺序从前到后将其分别存储到不同加速器中。在前向时,可以注意到某一层的计算仅依赖于其相邻层的参数。对此,可以对所有包含模型参数的加速器进行一次AllGather计算,用来提取每一层的后一层的参数,以及计算该层本身的激活值。为了节约内存,在AllGather操作结束后需要立即丢弃除了该层以外其他层的参数。
- 基于ReduceScatter算子的梯度平均: 在反向计算时我们只需要前一层的参数来计算本层的激活值和梯度,因此只需要再次使用AllGather来完成每个加速器上的梯度计算。同时,在聚集梯度后,对于每个加速器仅需要和加速器的编号相同的层数对应的梯度。对此,可以使用ReduceScatter算子直接把相应的梯度存到编号为\(i\)的加速器上,而不是通常情况下使用AllReduce算子。
DALL-E
DALL-E是OpenAI提出的一个基于文字的图片生成模型,模型同样拥有高达120亿的参数。在训练时,除了运用到ZeRO所使用的AllGather + ReduceScatter 技巧,OpenAI团队在其他细节上做了进一步的优化。这里,介绍两个主要的关于集合通信的优化技术:
- 矩阵分解: 集合通信算子的运行速度和信息本身的长度正相关。在模型训练中,这代表了模型参数本身的大小。对此,DALL-E 选择用矩阵分解(Matrix Factorization)的方法先把高维张量调整为一个二维矩阵,通过分解后分开用集合通信算子进行传输,从而大大减少了通信量。
- 自定义数据类型: 一种减少通信量的方法在于修改数据类型本身。显然地,可以使用16位的半精度浮点数,相比正常的32位参数表示可以节省近一倍的通信量。但是,在实践中发现低精度的数据类型会使得模型收敛不稳定,导致最终训练效果大打折扣。为此,OpenAI分析了DALL–E的模型结构,并把其中的参数根据对数据类型精度的敏感性分为了三类。其中对精度最敏感的一类照常使用32位浮点表示并只通过AllReduce算子来同步,而最不敏感的参数则照常通过矩阵分解进行压缩和传输。对于比较敏感的一类,例如Adam优化器其中的动能(Moments)和方差(Variance)参数,OpenAI 基于 IEEE 754 标准实现了两个全新的数据类型:1-6-9和0-6-10(其中第一表示正负所需的位数,第二表示指数所需的位数,第三表示有效数字所需的位数),在节省空间的同时保证了训练的收敛。
集合通信在数据并行的实践
数据并行作为最广泛使用的分布式训练方法,是集合通信首先需要支持的范式。 对于数据并行的支持,机器学习系统通常提供了两个级别的抽象:在第一种级别的抽象里,机器学习系统更与硬件耦合,可以直接调用集合通信算子的库;在另一种级别的抽象里,机器学习系统更偏向神经网络实现,通过内部调用集合通信算子实现分布式训练和推理的机器学习框架。作为算法工程师,通常会接触到后者的抽象(包括Horovod、KungFu、TensorFlow Distributed等),而作为集群的维护者,往往需要深入了解前者的运行原理和具体的调试方法。以 PyTorch 举例,在torch.distributed 命名空间(Namespace)下实现了一系列方便开发者使用的分布式模型训练和推理函数。在其内部,会根据实际运行的集群调用更底层的集合通信算子库,例如MPI,NCCL(前面已有介绍,适用于GPU分布式训练),Gloo(适用于CPU分布式训练)等。下面具体对比PyTorch Distributed和NCCL在AllReduce应用方面的差异: 以下代码通过PyTorch自带的分布式数据并行(Distributed Data Parallel,DDP)方法完成了一次简易的机器学习模型计算。
# 基于PyTorch DDP高层次封装实现AllReduce算法
def ddp_allreduce(rank, world_size):
setup(rank, world_size)
model = ToyModel().to(rank)
# 通过调用DDP(分布式数据并行)方法将模型在每个处理器上完成初始化
ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
# 在反向计算时,框架内部会执行AllReduce算法
loss_fn(outputs, labels).backward()
optimizer.step()
下面代码通过Gloo的Python 接口pygloo和Ray完成了一个二维张量的AllReduce计算。
# 基于pygloo底层接口实现AllReduce算法
@ray.remote(num_cpus=1)
def gloo_allreduce(rank, world_size):
context = pygloo.rendezvous.Context(rank, world_size)
...
Sendbuf = np.array([[1,2,3],[1,2,3]], dtype=np.float32)
recvbuf = np.zeros_like(Sendbuf, dtype=np.float32)
Sendptr = Sendbuf.ctypes.data
recvptr = recvbuf.ctypes.data
# 标明发送者和接收者并直接调用AllReduce算法
pygloo.allreduce(context, Sendptr, recvptr,
Sendbuf.size, pygloo.glooDataType_t.glooFloat32,
pygloo.ReduceOp.SUM, pygloo.allreduceAlgorithm.RING)
可以注意到,PyTorch Distributed并没有显式地调用集合通信算子,而是通过DistributedDataParallel方法将分布式训练和非分布式训练之间的不同隐藏了起来。如果需要在不同集群上运行这段代码,只需要在setup 函数内对应地更改PyTorch使用的底层集合通信库即可。在backward函数被调用时,才会真正地使用AllReduce算法。相比,如果想要直接使用Gloo,不仅需要一步一步地创建通信所需要的数据结构,同时也很难和现有的模型训练框架无缝连接。
集合通信在混合并行的实践
随着深度学习的发展,模型和训练数据集的规模呈爆发式增长,单机的算力和存储能力已无法满足需求,因此,分布式训练技术成为行业发展趋势。
本章前几节已总结当前常用的分布式并行训练技术方案,如数据并行、模型并行和流水线并行,在复杂场景下,往往需要不同技术点组合使用,才能达到训练大模型的高性能。华为MindSpore开源框架提供混合并行的能力,来支撑大模型分布式训练,用户可以根据自己的需要进行灵活组合。以下通过简单代码示例来说明如何在MindSpore中组合使用数据并行、模型并行和流水线并行训练技术,其他大模型训练技术的使用方法请参照官网教程。
以下代码利用set_auto_parallel_context接口设置并行模式和可用于训练的卡数,同时利用该接口设置流水线并行中的stage数量。通过扩展nn.Cell, 定义了简单的神经网络模型,其中self.matmul1和self.matmul2的两个矩阵乘操作,调用shard接口来配置切分策略,如matmul1将第一个输入按照行切成4份,实则是在数据维度上切分,是数据并行的样例,而matmul2对第二个输入进行列切,采用了模型并行的方式。为了实现流水线并行,以下代码调用nn.PipelineCell接口来包装net_with_loss,并指定流水线并行所需的微批次大小。最后,通过model.train接口来对神经网络进行混合并行训练。
MindSpore提供了shard接口来允许用户配置切分策略。在这种切分的场景下,需要在必要的时候插入集合通信算子来保证计算逻辑的正确性:第一种是切分了单一算子的情况,将算子切分到多卡进行计算,为了保证计算结果和单卡计算结果一致,需要集合通信算子来将多卡计算的部分结果同步聚合到每张卡上;第二种是多算子情况下,相邻算子的切分方式不同,前继算子的计算结果排布在不同的卡上,后续算子的计算需要用到非当前卡上的数据才能进行,此时需要一个集合通信算子来重新排布前继算子的计算结果。
# 基于MindSpore对模型进行混合并行分布式训练
import mindspore.nn as nn
from mindspore import ops
import mindspore as ms
# 设置并行模式为半自动并行,同时设置训练的卡数
ms.set_auto_parallel_context(parallel_mode="semi_auto_parallel", device_num=4)
# 设置流水线并行的stage数量
ms.set_auto_parallel_context(pipeline_stages=stages)
class DenseMatMulNet(nn.Cell):
def __init__(self):
super(DenseMutMulNet, self).__init__()
# 通过shard定义算子切分的方式:matmul1是数据并行的样例,matmul2是模型并行的样例
self.matmul1 = ops.MatMul.shard(((4, 1), (1, 1)))
self.matmul2 = ops.MatMul.shard(((1, 1), (1, 4)))
def construct(self, x, w, v):
y = self.matmul1(x, w)
z = self.matmul2(y, v)
return z
# 定义训练数据集
data_path = os.getenv('DATA_PATH')
dataset = create_dataset(data_path)
net = DenseMatMulNet()
loss = SoftmaxCrossEntropyExpand(sparse=True)
net_with_loss = nn.WithLossCell(net, loss)
# 用PipelineCell接口包装神经网络,第二个参数指定MicroBatch Size
net_pipeline = nn.PipelineCell(net_with_loss, micro_size)
opt = Momentum(net.trainable_params(), 0.01, 0.9)
model = ms.Model(net_pipeline, optimizer=opt)
# 对模型进行迭代训练
model.train(epoch_size, dataset, dataset_sink_mode=True)
图10.4.3 展示了上述代码中matmul1和matmul2在调用shard函数后的数据排布情况。matmul1算子将输入\(X\)按照行切成4份后,分别放置在4个计算设备上(D1-D4),\(W\)不切分,则以复制的形式放置在4个计算设备上,此时matmul1算子计算的结果\(Y\),以行切的形式被放置在不同设备上,而matmul2算子在做计算时,需要\(Y\)的全量数据,因此两个计算算子之间需要插入AllGather集合通信算子,来从4个不同的设备上收集到\(Y\)的全量数据。MindSpore能够自动识别不同切分方式的算子之间应该插入哪种集合通信算子,并且将该逻辑对用户隐藏,只暴露出shard接口供用户配置,开发者可以通过合理的策略配置,来减少算子间重排布通信算子在神经网络计算图中的占比,以提升混合并行分布式训练的端到端速率。
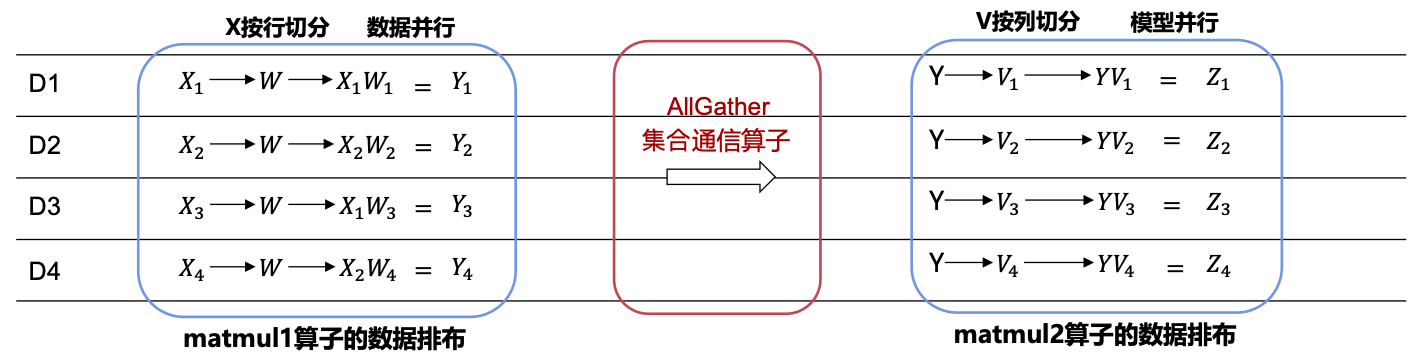
图10.4.3 相邻算子之间插入集合通信算子举例
参数服务器
参数服务器
下面介绍另一种常见的分布式训练系统:参数服务器。不同的机器学习框架以不同方式提供参数服务器的实现。TensorFlow和MindSpore内置了参数服务器的实现。PyTorch需要用户使用RPC接口自行实现。同时,我们也有参数服务器的第三方实现,如PS-Lite。
系统架构
不同于基于集合通信实现的机器学习系统,参数服务器系统中的服务器会被分配两种角色:训练服务器和参数服务器。其中参数服务器需要提供充足内存资源和通信资源,训练服务器需要提供大量的计算资源(如硬件加速器)。 图10.5.1 描述了带有参数服务器的机器学习集群。这个集群中含有两个训练服务器和两个参数服务器。 假设我们有一个模型,可以切分为两个参数分区。每个分区被分配给一个参数服务器负责参数同步。 在训练的过程中,每个训练服务器都会有完整的模型,根据本地的训练数据集切片(Dataset Shard)训练出梯度。这个梯度会被推送(Push)到各自参数服务器。参数服务器等到两个训练服务器都完成梯度推送,开始计算平均梯度,更新参数。它们然后通知训练服务器来拉取(Pull)最新的参数,开始下一轮训练迭代。
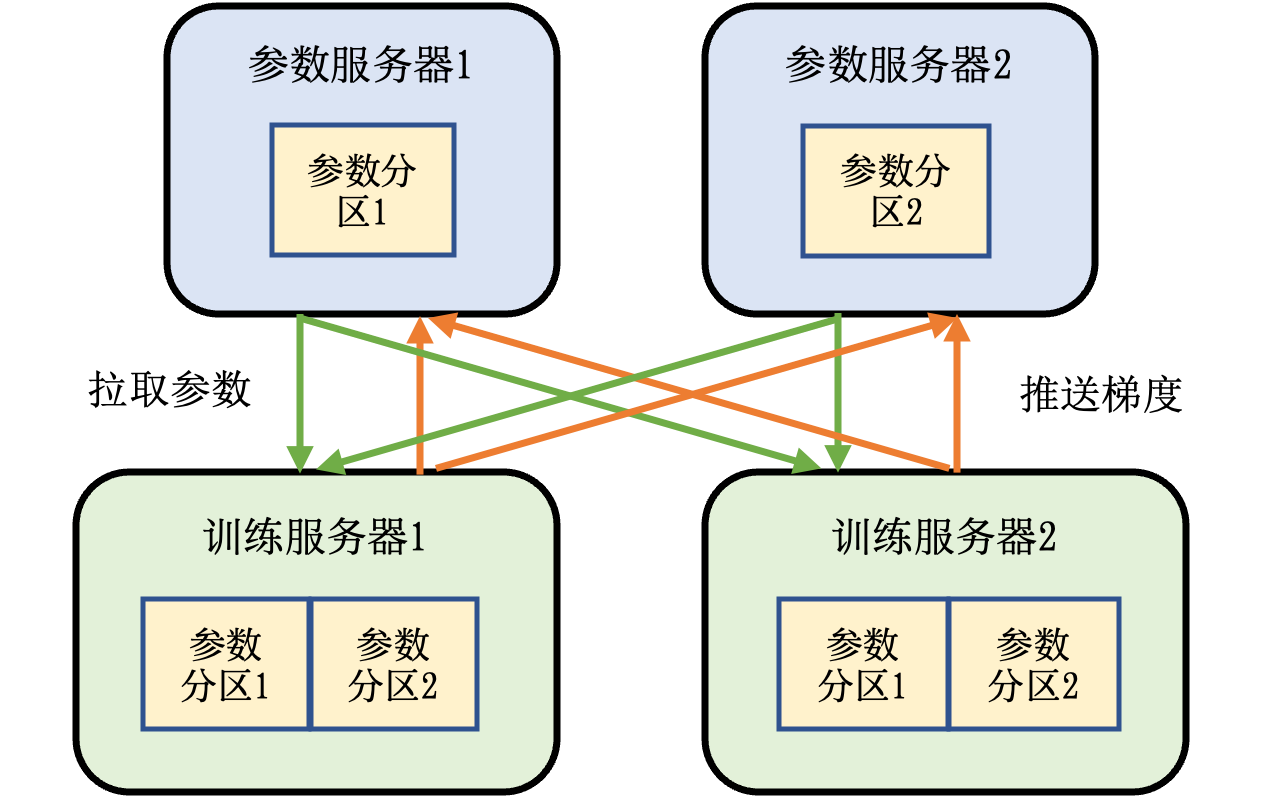
图10.5.1 参数服务器架构
异步训练
参数服务器的一个核心作用是可以处理分布式训练服务器中出现的落后者(Straggler)。在之前的讨论中,在每一轮训练结束后,训练服务器都需要计算平均梯度对每一个模型副本进行更新,从而保证下一轮训练开始前,全部模型副本参数的一致性,这种对于参数一致性的确保一般被称为同步训练(Synchronous Training)。同步训练一般有助于训练系统达到更好的模型精度,但是当系统规模变大,往往会观察到落后者服务器的出现。落后者出现的原因很多。常见的原因包括:落后者设备可能和其他设备不在同一个机柜中,因此落后者的通信带宽显著小于其他设备。另外,落后者设备也可能和其他进程共享本地的服务器计算和通信资源,形成资源竞争,从而降低了性能。
落后者对于基于AllReduce的同步训练系统的性能有显著影响,这是因为AllReduce让全部节点参与到平均梯度的计算和通信中,而每个节点负责等量的数据。因此一个落后者的出现,都会让整个AllReduce操作延迟完成。为了解决这个问题,人们常使用参数服务器同步梯度。一种常见的设计是:训练服务器训练出梯度后,会把本地梯度全部推送到参数服务器。参数服务器在等到一定训练服务器(例如90%的训练服务器)的梯度后,就开始计算平均梯度。这样可以确保平均梯度的计算不会被落后者的出现延误。计算好的平均梯度马上推送给全部训练服务器,开始下一轮训练。
解决落后者的另一种常见做法是利用参数服务器实现异步训练(Asynchronous Training)。在一个异步训练系统中,每个训练服务器在训练开始时,有相同的模型参数副本。在训练中,它们计算出梯度后会马上将梯度推送到参数服务器,参数服务器将推送的梯度立刻用于更新参数,并通知训练服务器立刻来拉取最新的参数。在这个过程中,不同的训练服务器很可能会使用不同版本的模型参数进行梯度计算,这种做法可能会伤害模型的精度,但它同时让不同训练服务器可以按照各自的运算速度推送和拉取参数,而无须等待同伴,因此避免了落后者对于整个集群性能的影响。
数据副本
在参数服务器的实际部署中,人们往往需要解决数据热点问题。互联网数据往往符合幂律概率(Power-Law Distribution),这会导致部分参数在训练过程中被访问的次数会显著高于其他参数。例如,热门商品的嵌入项(Embedding Item)被训练服务器拉取的次数就会远远高于非热门商品。因此,存储了热门数据的参数服务器所承受的数据拉取和推送请求会远远高于其他参数服务器,因此形成数据热点,伤害了系统的可扩展性。
利用数据副本的另一个作用是增加系统的鲁棒性。当一个参数服务器出现故障,其所负责的参数将不可用,从而影响了整体系统的可用性。通过维护多个参数副本,当一个参数服务器故障时,系统可以将参数请求导向其他副本,同时在后台恢复故障的参数服务器,确保系统的可用性不受影响。
解决参数服务器故障和数据热点问题的常用技术是构建模型主从复制(Leader-Follower Replication)。一份参数在多个机器上拥有副本,并指定其中一个副本作为主副本(Leader Replica)。训练服务器的所有更新操作都向主副本写入,并同步至全部从副本(Follower Replica)。如何取得共识并确定哪一个副本是主副本是分布式系统领域一个经典问题,对该问题已经有了相当多的成熟算法,例如Paxos和Raft。此外,主副本上的更新如何复制到从副本上也是分布式系统领域的经典共识问题。通常系统设计者需要在可用性(Availability)和一致性(Consistency)之间做出取舍。如果参数服务器副本间采用强一致性(Strong Consistency)的复制协议(Replication Protocol),例如链式复制(Chain Replication),则可能导致训练服务器的推送请求失败,即参数服务器不可用。反之,如果参数服务器采用弱一致性(Weak Consistency)的复制协议,则可能导致副本间存储的参数不一致。
总结
总结
-
大型机器学习模型的出现带来了对于算力和内存需求的快速增长,催生了分布式训练系统的出现。
-
分布式训练系统的设计往往遵循“分而治之”的设计思路。
-
利用分布式训练系统,人们可以显著提升训练性能,体现经济性,并且帮助防范硬件故障。
-
分布式训练系统可以通过数据并行增加设备来提升算力。
-
当单节点内存不足时,可以通过模型并行解决单设备内存不足。模型并行有两种实现方式:算子内并行和算子间并行。
-
大型模型并行系统容易出现设备使用气泡,而这种气泡可以通过流水线并行解决。
-
分布式训练系统往往运行在计算集群之中,集群网络无法提供充足的网络带宽来传输大量训练中生成的梯度。
-
为了提供海量的通信带宽,机器学习集群拥有异构的高性能网络,包括以太网、加速器高速互连技术NVLink和高带宽网络InfiniBand。
-
为了解决单节点瓶颈,可以使用AllReduce算法来分摊梯度聚合过程中产生的计算和通信操作,同时实现负载均衡。
-
参数服务器可以帮助实现灵活的梯度同步和异步训练,从而防范集群中可能出现的落后者服务器。
-
参数服务器常用数据副本技术解决数据热点问题和防范硬件故障。
拓展阅读
第三部分:拓展篇
在本书的第三部分,我们将会介绍机器学习框架生态下的众多拓展应用。我们将会首先介绍深度学习推荐系统,这一类系统是深度学习应用最成功的领域之一,在各大互联网公司中得到了大量部署。 其后,我们将会介绍联邦学习系统,这一类希望在数据隐私保护意识快速崛起的今天具有举足轻重的作用。我们同时也会介绍可解释性AI系统,这一类系统能够对机器学习推理的过程给出解释,因此在金融,医疗等安全攸关系统(Safety-critical System)中得到大量应用。 最后,我们会介绍强化学习系统,这一类系统可以帮助计算机和人类进行自动化决策,是实现通用人工智能的关键基础设施。
机器学习系统作为一个蓬勃发展的领域,我们也会在不远的将来看到更多相关系统的崛起。我们也欢迎社区贡献更多的章节进入拓展篇,如有想法可以和本书的编辑们联系。
深度学习推荐系统
推荐模型通过对用户特征、物品特征、用户-物品历史交互行为等数据的分析,为用户推荐可能感兴趣的内容、商品或者广告1。在信息爆炸的时代,高效且准确的推荐结果能够极大地提升用户在使用服务时的体验。近年来,基于深度学习的推荐模型2 由于可以高效地从海量数据中发掘用户的潜在兴趣,被谷歌、脸书、阿里巴巴等各大公司广泛应用于生产环境中。为了支持推荐模型的稳定高质量服务,人们围绕其搭建了一系列组件,这些组件和推荐模型共同构成了庞大而又精巧的深度学习推荐系统。本章主要介绍以深度学习模型为中心的推荐系统的基本组成、运行原理以及其在在线环境中面临的挑战和对应的解决方案。
系统基本组成
系统基本组成
推荐系统的核心模块是其中的推荐模型,其负责根据输入数据找出用户可能感兴趣的物品。为了支持推荐模型的持续、稳定、高质量运行,大型推荐系统还包括了围绕推荐模型搭建了的一系列其他模块。图 图12.1.1展示了一个典型的推荐系统的基本组件。首先有一个消息队列接收从推荐服务的客户端上传的日志,其中包括了用户对于此前推荐结果的反馈,例如用户是否点击了推荐的物品。然后数据处理模块对日志中的原始数据进行处理。处理得到新的训练样本写入另一条消息队列中,由训练服务器读取并更新模型参数。主流的推荐模型主要由两部分构成:嵌入表和神经网络。在训练过程中,训练服务器从参数服务器拉取模型参数,计算梯度并将梯度上传回参数服务器,参数服务器聚合各个训练服务器的结果并更新参数。推理服务器负责处理用户请求,根据用户请求从参数服务器拉取对应的模型参数然后计算推荐结果。
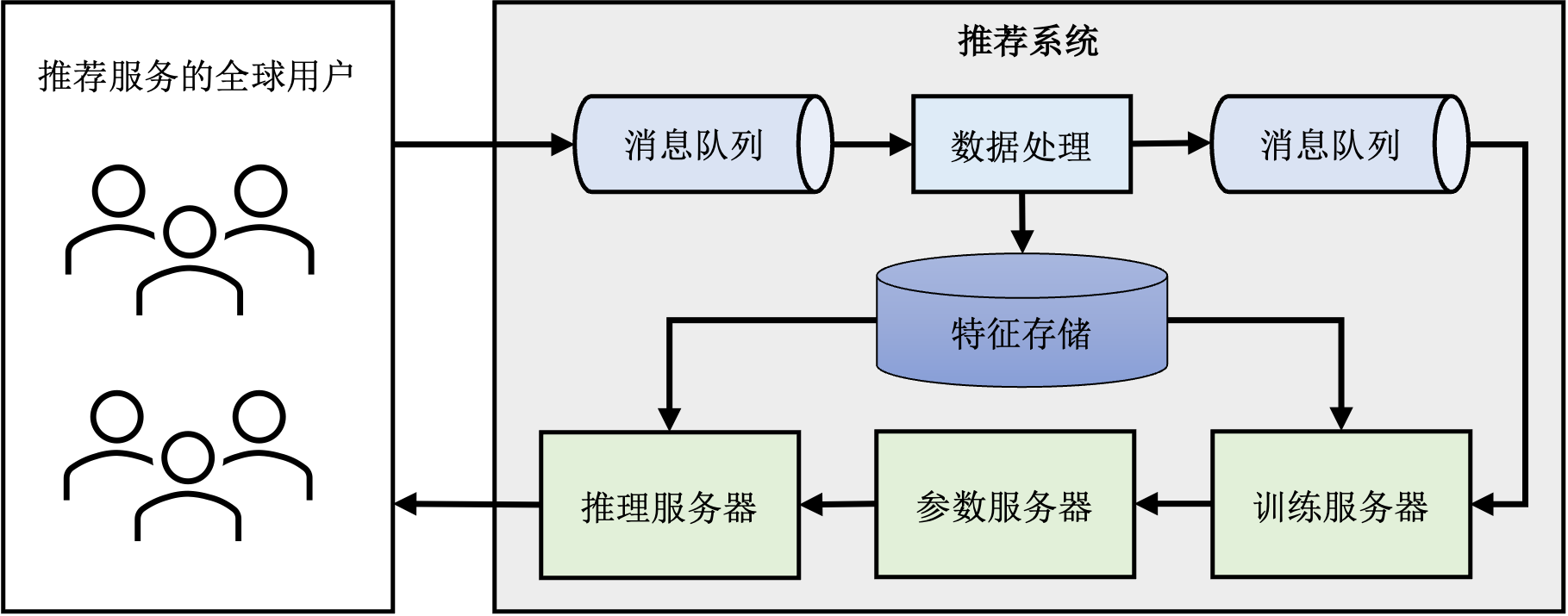
图12.1.1 推荐系统的分布式架构
以下各个小节详细介绍推荐系统工作流中的各个组件的功能和特点。
消息队列
消息队列(Message Queue)是一种服务(Service)间异步通信的方式,常用于无服务(Serverless)或微服务(Microservices)架构中。
例如在推荐系统中,各个模块可以部署成一个个相对独立的微服务。客户端向服务器上报的日志(包含用户对推荐结果的反馈)由消息队列负责收集,然后数据处理服务从消息队列中读取原始日志,进行清洗、转化,得到的用户、物品特征存入特征存储中,而得到的训练样本再写入另一条消息队列中等待训练服务器使用。
消息队列带来的益处非常多,其中之一是允许消息的生产者(Producer),例如客户端的上报组件,和消息的消费者(Consumer),例如服务端的数据处理模块,可以以不同的速率生产消费数据。假设在推荐服务使用的高峰期,用户端产生了大量反馈,如果令数据处理模块直接接受数据,那么很可能因为处理速度跟不上产生速度而导致大量数据被丢弃。即使可以按最高峰的反馈量配置数据处理模块,那么也会导致大部分非高峰期时间资源是浪费的。而消息队列可以在高峰期将用户日志缓存起来,从而使得数据处理模块可以以一个较为恒定且经济的速度处理用户反馈。
作为分布式系统的重要基础组件,业界已经开发了许多成熟的消息队列系统,例如RabbitMQ,Kafka,Pulsar等。限于篇幅和主题,本节无法详细介绍消息队列的各个方面,感兴趣的读者可以参考这些开源系统的文档或者拓展阅读中给出的资料深入学习。
特征存储
特征存储是存储并组织特征的地方,被用于模型训练和推理服务中。
前文提到数据处理模块从消息队列中读取原始日志,例如日志中包含用户性别信息可能是“男”“女”,“未知”中的一种。这样的原始特征无法直接输入推荐模型中使用,因此数据处理模块对其进行简单的映射转化:“男” –> 0,“女”-> 1,“未知”-> 2。经过这样转化之后,性别特征就可以被数据处理模块或者推荐模型所使用。转化后的特征被存入特征存储中。一种典型的特征存储格式如图 图12.1.2所示,当训练或推理模块需要用到用户特征时,只需要知道用户ID就可以从特征存储中查询到所有需要的特征。
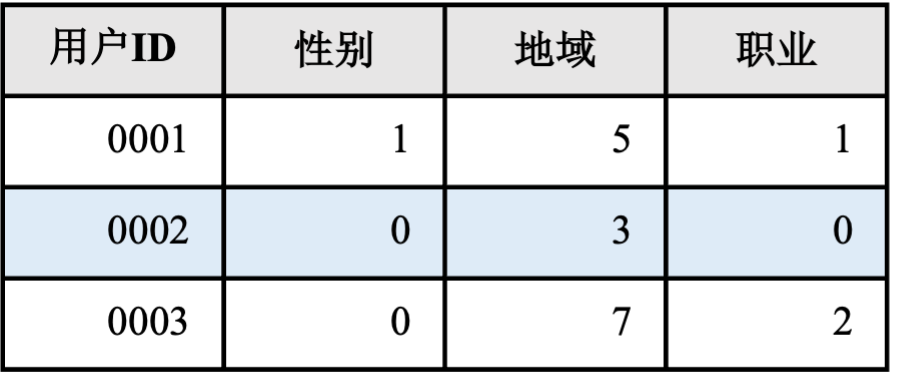
图12.1.2 特征存储示例
使用特征存储的一个显著优势是复用数据处理模块的结果并减少存储冗余,即避免每个模块都要单独对原始数据进行加工处理并维护一个数据存储系统来保存可能会用到的特征。然而其带来的一个更大的益处是可以保证整个系统中的各个组件拥有一致的特征视图。设想一个极端场景,假如训练模块自己维护的数据库中性别“男”对应的值是1,而“女”对应0,而推理模块恰好相反,这样会导致模型推理得到灾难性的结果。
特征存储是机器学习系统中的重要基础组件,工业界有许多成熟的产品,例如SageMaker,Databricks等,也有许多优秀的开源系统,例如Hopsworks,Feast等。关于特征存储更加详细的介绍可以参考拓展阅读中提供的资料。
稠密神经网络
稠密神经网络(Dense Neural Network,DNN)是推荐模型的核心,负责探索各个特征之间隐含的联系从而为用户推荐出可能感兴趣的物品。一般在推荐系统中,简单的多层感知机(Multilayer Perceptron,MLP)模型就已经显示出了强大的效果并被应用在谷歌 [1]、Meta [2]等各大公司的推荐模型中。虽然MLP的大矩阵相乘操作属于计算密集型任务,对于计算能力要求很高,但是推荐模型中的MLP尺寸一般不超过数MB,对存储要求不高。
虽然MLP已经取得了不错的效果,在推荐系统领域,近年来应用各种新型深度神经网络的尝试从未止步,更加精巧复杂的网络结构层出不穷,近年来也有工作尝试应用Transformer模型完成推荐任务 [3]。在可以预见的未来,推荐模型中的稠密神经网络也必然会增长到数GB乃至TB。
嵌入表
嵌入表是几乎所有推荐模型的共有组件,负责将无法直接参与计算的离散特征数据,例如:用户和物品ID、用户性别、物品类别等,转化为高维空间中的一条向量。推荐模型中的嵌入表的结构和自然语言处理模型中的类似,不同的是自然语言处理模型中的深度神经网络贡献了主要的参数量,而在推荐模型中,如图 图12.1.3所示,嵌入表贡献主要的参数量。这是因为,推荐系统中有大量的离散特征,而每个离散特征的每一种可能的取值都需要有对应的嵌入项。例如,性别特征的取值可能是“女”,“男”,“未知”,则需要三个嵌入项。假设每条嵌入项是一个64维的单精度浮点数向量,如果一个推荐系统服务一亿用户,那么仅仅对应的用户嵌入表(其中的每条嵌入项对应一个用户)的大小就有\(4*64*10^8~=23.8\)GB。除了用户嵌入表,还有商品嵌入表(其中的每条嵌入项对应一个商品),以及用户和商品的各项特征的嵌入表。总的嵌入表大小可以轻易达到几百GB甚至几十TB。 而正如上文提到的,推荐系统中通常用的MLP模型尺寸较小。例如一个在Ali-CCP数据集 [4]上训练的DLRM [2]的嵌入表大小超过1.44GB,而稠密神经网络仅有大约100KB。
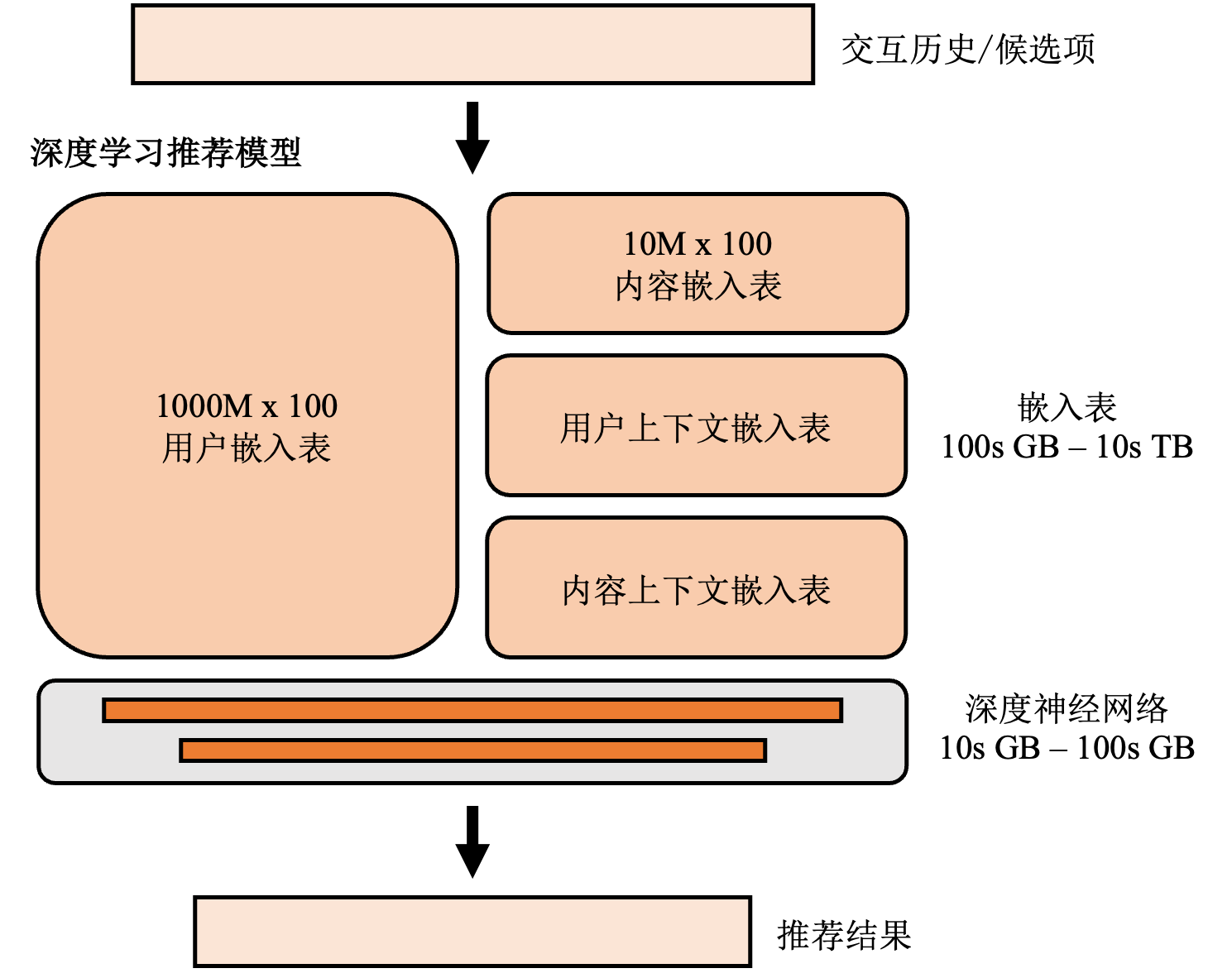
图12.1.3 推荐模型的基本结构
在推荐系统中,人们通常使用存算分离的参数服务器架构来服务推荐模型。尽管嵌入表占据了推荐模型的主要存储空间,但是其计算却是十分稀疏的。这是因为无论是在训练还是推理过程中,数据都是以小批次的形式依次计算。而在一个批次的计算过程中,只有涉及到的那些嵌入项才会被访问到。假设在一个服务一亿用户的推荐系统每次处理1000条用户的请求,那么一次只有大约十万分之一的嵌入项会被访问到。因此负责计算推荐结果的服务器(训练服务器或者推理服务器)根本没有必要存储所有的嵌入表。
训练服务器
因为深度学习推荐系统同时具有存储密集(嵌入表)和计算密集(深度神经网路)的特点,工业界通常使用参数服务器架构来支持超大规模推荐模型的训练和推理。参数服务器架构包含训练服务器、参数服务器和推理服务器。本书 :ref:parameter_servers章详细介绍了参数服务器架构,因此本节只重点介绍参数服务器架构具体在推荐系统中的功能。
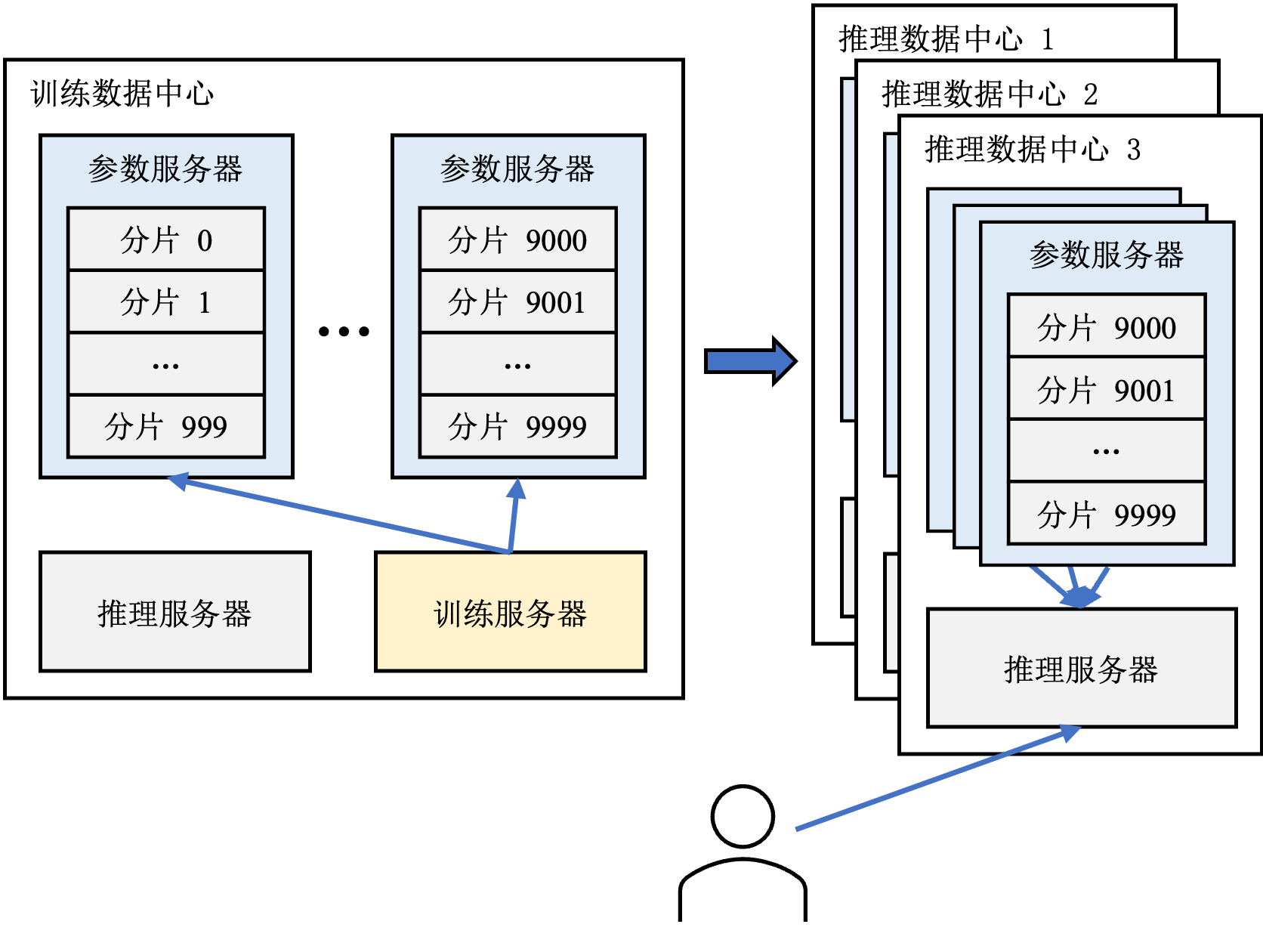
图12.1.4 推荐系统中的参数服务器
在推荐系统中,训练服务器从消息队列中读取一个批次的数据,然后从参数服务器上拉取对应的嵌入项和深度神经网络,得出推荐结果、计算损失、进行反向传播得到梯度。参数服务器从所有训练服务器处收集梯度,聚合得到新的参数。这就完成了一轮模型训练。
由于参数服务器要聚合所有训练服务器的梯度,为了避免网络延迟导致的掉队者严重影响训练效率,通常一个模型的所有训练服务器位于同一个数据中心中。我们将这个数据中心称之为训练数据中心。
参数服务器
在推荐系统中,参数服务器除了协调训练过程,还要负责支持模型推理。在模型推理过程中,推理服务器需要访问参数服务器上的模型参数以计算推荐结果。因此为了降低推理过程的延迟,通常会在推理服务器所在的数据中心(以下称之为推理数据中心)中的参数服务器上保存至少一份模型参数的副本,结构如图 图12.1.4所示。这种做法还有利于容灾——当一个数据中心因为某些原因被迫下线无法访问时,可以将用户请求重定向至其他的推理数据中心。
推理服务器
推荐系统中的推理服务器负责从客户端接受用户的推荐请求,然后根据请求从参数服务器拉取模型参数,从特征存储中拉取用户和物品特征,然后计算推荐结果。本节为了方便理解,假设用户请求由一个推理服务器处理,实际上在大规模推荐系统中,推理结果由(多个推理服务器上的)多个模型组成的推荐流水线给出。具体的细节将会在下一节多阶段推荐系统中介绍。
参考文献
- Cheng, Heng-Tze and Koc, Levent and Harmsen, Jeremiah and Shaked, Tal and Chandra, Tushar and Aradhye, Hrishi and Anderson, Glen and Corrado, Greg and Chai, Wei and Ispir, Mustafa and others. Wide \& deep learning for recommender systems. Proceedings of the 1st workshop on deep learning for recommender systems. 2016. ↩
- Naumov, Maxim and Mudigere, Dheevatsa and Shi, Hao-Jun Michael and Huang, Jianyu and Sundaraman, Narayanan and Park, Jongsoo and Wang, Xiaodong and Gupta, Udit and Wu, Carole-Jean and Azzolini, Alisson G and others. Deep learning recommendation model for personalization and recommendation systems. arXiv preprint arXiv:1906.00091. 2019. ↩
- de Souza Pereira Moreira, Gabriel and Rabhi, Sara and Lee, Jeong Min and Ak, Ronay and Oldridge, Even. Transformers4rec: Bridging the gap between nlp and sequential/session-based recommendation. Proceedings of the 15th ACM Conference on Recommender Systems. 2021. ↩
- Ma, Xiao and Zhao, Liqin and Huang, Guan and Wang, Zhi and Hu, Zelin and Zhu, Xiaoqiang and Gai, Kun. Entire space multi-task model: An effective approach for estimating post-click conversion rate. The 41st International ACM SIGIR Conference on Research \& Development in Information Retrieval. 2018. ↩
多阶段推荐系统
多阶段推荐系统
推荐流水线的功能是根据用户请求推荐为其可能感兴趣的物品。具体来说,当用户需要使用推荐服务时向推理服务发送一个推荐请求,其中包括用户ID和当前的上下文特征(例如,用户刚刚浏览过的物品、浏览时长等),推荐流水线将该用户的特征和备选物品特征作为输入,进行计算后得出这名用户对各个备选物品的评分,并选出评分最高的(数十个到数百个)物品作为推荐结果返回。
一个推荐系统中通常会有多达数十亿的备选物品,如果用一个模型来计算用户对于每个备选物品的评分,必然会导致模型在准确度和速度上做取舍。换句话说,要么选择简单的模型牺牲准确度换取速度——导致用户对推荐结果毫无兴趣;要么选择复杂的模型牺牲速度换取准确度——导致用户因等待时间过长而离开。有鉴于此,现代推荐系统通常以如图 图12.2.1所示的流水线的形式部署多个推荐模型。在流水线的最前端,召回(Retrieval)阶段(通常使用结构较为简单、运行速度较快的模型)从所有备选物品中过滤出用户可能感兴趣的数千至数万个物品。接下来排序(Ranking)阶段(通常使用结构更为复杂、运行速度也更慢的模型)对选出的物品进行打分并排序,然后再根据业务场景为用户返回最高分的数十或数百个物品作为推荐结果。当排序模型过于复杂而不能在规定时间内处理所有被召回的物品时,排序阶段可以被进一步细分为:粗排(Pre-ranking),精排(Ranking)和重排(Re-ranking)三个阶段。
推荐流水线概述

图12.2.1 多阶段推荐流水线示例图
下面几个小节详细将会详细介绍召回和排序阶段的常用模型、训练方法以及关键指标。
召回
在召回阶段,模型以用户特征作为输入,从所有备选物品中粗略筛选出一部分用户可能感兴趣的物品作为输出。召回阶段的主要目的是将候选物品范围缩小,减轻下一阶段排序模型的运行负担。
1. 双塔模型
接下来以如图 图12.2.2所示双塔模型 [1]为例介绍召回的流程。双塔模型具有两个MLP,分别对用户特征和物品特征进行编码,称之为用户塔1 和物品塔。对于输入数据,连续特征可以直接作为MLP的输入,而离散特征需要通过嵌入表映射为一个稠密向量再输入到MLP中。用户塔和物品塔对特征进行处理得到用户向量和物品向量用于表示不同用户或物品。双塔模型使用一个评分函数衡量用户向量和物品向量之间的相似度。
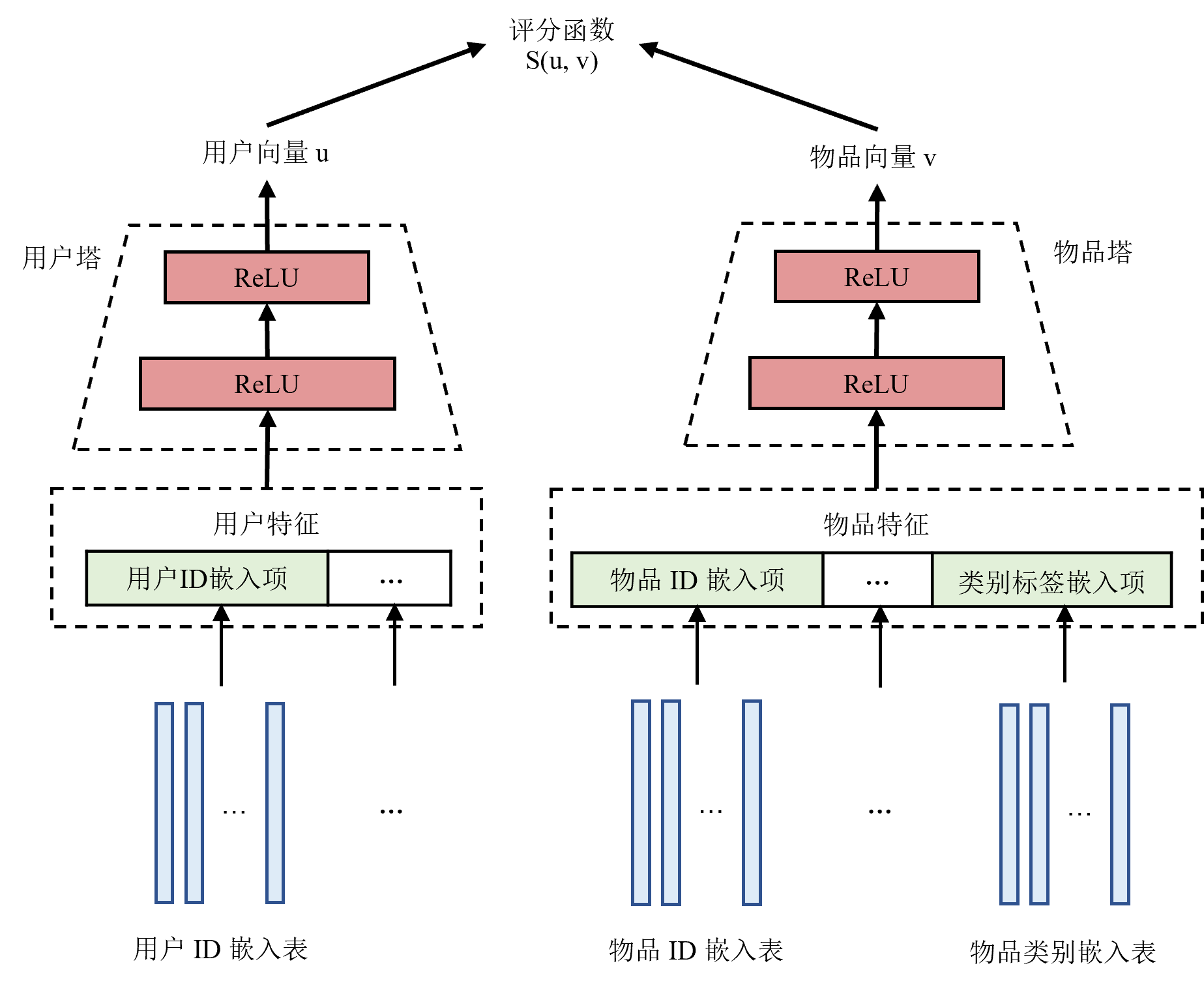
图12.2.2 双塔模型结构图
2. 训练
%关于如何训练这一模型,一个自然的想法是:每个用户都与所有的物品两两进行评分。然而如前文提及,训练数据集来自以往做出的推荐和用户反馈,同一名用户只可能对少数物品做出过反馈,因此数据集只包含用户与部分物品的互动。此外,召回阶段的备选物品通常很多,两两评分得到的分数矩阵会占用大量内存。所以在实际训练中,我们只选取用户点击了的(用户,物品)对,即正样本作为训练数据集,在训练过程中使用采样器对其他物品进行采样作为负样本。 训练时,模型的输入为用户对历史推荐结果的反馈数据,即(用户,物品,标签)对,其中标签表示用户是否点击了物品。一般点击记为1,而未点击记为0。双塔模型使用正样本(即标签为1的样本)作为训练数据。然后使用一种可以纠正采样偏差的批次内采样器在批次内进行采样得到负样本,其算法细节在不是本节介绍的重点,感兴趣的读者可以深入研究原论文。模型输出的结果是用户点击不同物品的概率。训练时选用合适的损失函数使得正样本的预测结果尽可能接近1,而负样本的预测结果尽可能接近0。
3. 推理
推理之前,首先使用训练好的模型计算出所有物品的物品向量并保存。这是因为物品的特征是相对稳定的,这样做可以减少推理时的计算开销,从而加快推理速度。而用户特征和用户的使用情况相关,因此当用户请求到达时,双塔模型使用用户塔对当前的用户特征进行计算,得到用户向量。然后使用训练时的评分函数作为相似度的衡量,使用这一用户的用户向量与所有备选物品的物品向量进行相似度搜索。选出相似度最高的一部分物品输出作为召回结果。
4. 评估指标
召回模型的常见评估指标是在召回\(k\)个物品时的召回率(Recall@k),召回\(k\)个物品时的召回率定义如下: \[ \text{Recall@k} = \frac{\text{TP}}{\min(\text{TP} + \text{FN}, k)} \]
其中,TP、FN分别是真阳性(即召回的\(k\)个物品中真实标签为1的)和假阴性(即没有被召回的物品中真实标签为1的)。换句话说,召回率衡量的是所有正样本中有多少被模型成功找到了。这里需要注意的是,因为最多只能召回\(k\)个物品,因此如果正样本数多于\(k\),那么最好的情况下也只能找出\(k\)个。因此分母选择正样本数和\(k\)中较小的那一个。
排序
在排序阶段,模型结合用户和物品特征对召回得到的物品逐一打分。分数大小反映了该用户对物品感兴趣的概率。根据排序结果,选取评分最高的一部分物品向用户推荐。
当推荐模型所需要处理的备选物品越来越多,或者需要加入更为复杂的推荐逻辑和规则时,排序可以进一步细分为三个阶段:粗排、精排和重排:
- 粗排在召回与精排之间对物品进行进一步筛选。当有海量的备选物品或者使用了多路召回来增加召回结果的多样性时,召回阶段输出的物品数量依然会非常多。如果全部输入精排模型,会导致精排的耗时极高。因此在推荐流水线中加入粗排阶段可以进一步减少需要被精排的物品。
- 精排是排序最重要的阶段。在精排阶段,模型应尽量准确地反映用户对不同物品的喜好程度。下文中的排序模型均指代精排模型。
- 重排阶段会根据一定的商业逻辑(例如,增加新物品的曝光率或者过滤掉用户已经购买过的物品、看过的视频等)和规则(打乱推荐的物品、减少相似物品推荐)对精排的结果进行进一步处理以从整体上提升推荐服务的质量,而不是仅仅关注单个物品的点击率。
1. DLRM
接下来以DLRM [2]为例,介绍排序模型如何处理特征数据。如图 图12.2.3所示,DLRM包括嵌入表、两层MLP和一层交互层2。
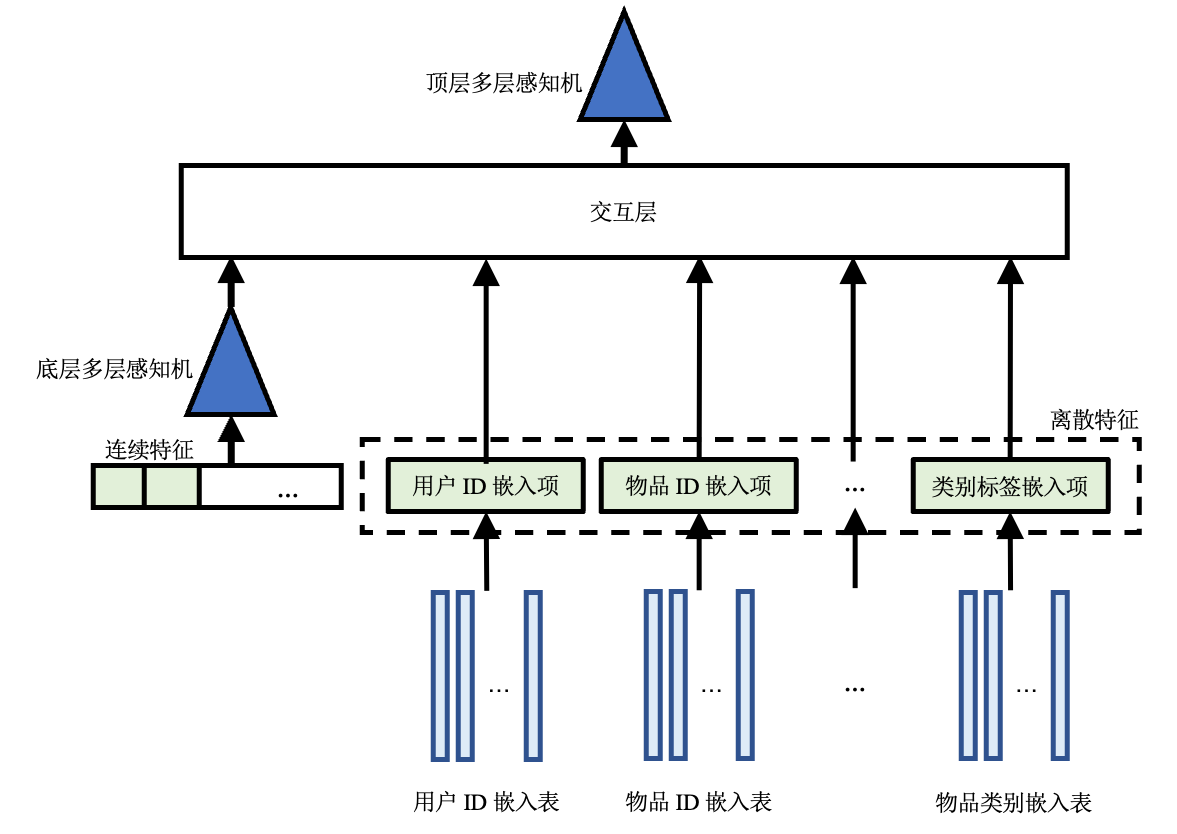
图12.2.3 DLRM结构图
和双塔模型类似,DLRM首先使用嵌入表将离散特征转化为对应的嵌入项(一条稠密向量),并将所有连续特征连接成一个向量输入底层MLP,处理得到与嵌入项维度相同的一个向量。底层MLP的输出和所有嵌入项一同送进交互层进行交互。
如图 图12.2.4所示,交互层将所有特征(包括所有嵌入项和经过处理连续特征)进行点积(Dot production)操作,从而得到二阶交叉特征。由于交互层得到的交互特征是对称的,对角线是同一个特征与自己交互的结果,对角线以外的部分,每对不同特征的交互都出现了两次(例如,对于特征\(p,q\),会得到\(<p,q>, <q,p>\)),所以只保留结果矩阵的下三角部分,并将这一部分拉平。拉平后的交叉结果和底层MLP的输出拼接起来,一起作为顶层MLP的输入,顶层MLP的进一步学习后,输出的评分代表用户点击该物品的概率
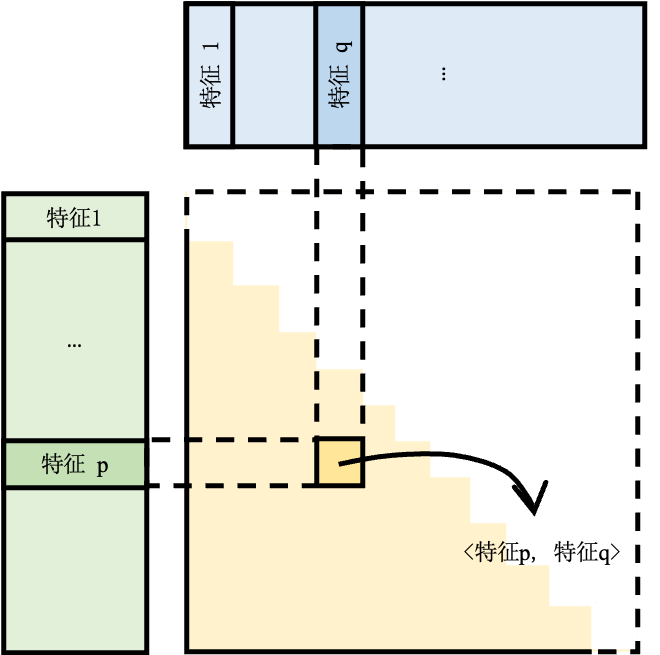
图12.2.4 交互原理示意图
2. 训练方法
DLRM直接基于(用户,物品,标签)对进行训练。模型将用户和物品特征一起输入,进行交互处理预测出用户点击物品的概率。对于正样本应当令概率尽可能接近1,而负样本接近0。
3. 训练评估指标
排序实际上可以被看作一个二分类问题,即将(用户,物品)分类为点击(标签为1)或不点击(标签为0),所以评估排序模型的方法与评估二分类模型类似。但是由于推荐系统数据集通常极度不平衡(正负样本比例悬殊),为了减少数据不平衡对指标的影响,排序模型的常用评估指标为AUC(Area Under Curve, 曲线下面积)和F1评分。 其中,AUC是ROC(Receiver Operating Characteristic,受试者工作特征)曲线下的面积,ROC曲线是在选取不同分类阈值时的真阳性率-假阳性率曲线。通过计算AUC和ROC曲线,可以选取合适的分类阈值。如果预测概率大于分类阈值,则认为预测结果为1(点击);否则为0(不点击)。根据预测结果可以算出召回率(recall)和精确率(precision),然后根据公式 (1)计算F1评分。
\[ F1 = 2 \times \frac{recall \times precision}{recall + precision} \tag{1}\label{f1} \]
4. 推理流程
推理时,首先将召回的物品的特征和相应的该用户的特征拼接起来,然后输入DLRM。根据模型的预测分数,选择概率最高的一部分物品输出。
参考文献
- Yi, Xinyang and Yang, Ji and Hong, Lichan and Cheng, Derek Zhiyuan and Heldt, Lukasz and Kumthekar, Aditee and Zhao, Zhe and Wei, Li and Chi, Ed. Sampling-bias-corrected neural modeling for large corpus item recommendations. Proceedings of the 13th ACM Conference on Recommender Systems. 2019. ↩
- Naumov, Maxim and Mudigere, Dheevatsa and Shi, Hao-Jun Michael and Huang, Jianyu and Sundaraman, Narayanan and Park, Jongsoo and Wang, Xiaodong and Gupta, Udit and Wu, Carole-Jean and Azzolini, Alisson G and others. Deep learning recommendation model for personalization and recommendation systems. arXiv preprint arXiv:1906.00091. 2019. ↩
模型更新
模型更新
通过以上两节的学习,我们了解了推荐系统的基本组件和运行流程。然而在实际的生产环境中,因为种种原因,推荐系统必须经常性地对模型参数进行更新。在保证上亿在线用户的使用体验的前提下,更新超大规模推荐模型是极具挑战性的。本节首先介绍为何推荐系统需要持续更新模型参数,然后介绍一种主流的离线更新方法,以及一个支持在线更新的推荐系统。
持续更新模型的需求
在学习过程中,我们用到的数据集通常都是静态的,例如ImageNet [1],WikiText [2]。其中的数据分布通常是不变的,因此训练一个模型使其关键指标,如准确率(Accuracy)和困惑度(Perplexity),达到一定要求之后训练任务就结束了。然而在线服务中使用的推荐模型需要面临高度动态的场景。这里的动态主要指两个方面:
- 推荐模型所服务的用户和所囊括的物品是在不断变化的,每时每刻都会有新的用户和新的物品。如图 图12.3.1所示,如果嵌入表中没有新用户所对应的嵌入项,那么推荐模型就很难服务于这个用户;同理如果新加入的物品没有在推荐模型的嵌入表中,如图 图12.3.2所示,就无法出现在推荐流水线中,从而导致不能被推荐给目标用户。
- 推荐模型所面临的用户兴趣是在不断变化的,如果推荐模型不能及时地改变权重以适应用户新的兴趣,那么推荐效果就会下降。例如在一个新闻推荐的应用中,每天的热点新闻都是不一样的,如果推荐模型总是推荐旧的热点,用户的点击率就会持续下降。

图12.3.1 用户嵌入项缺失
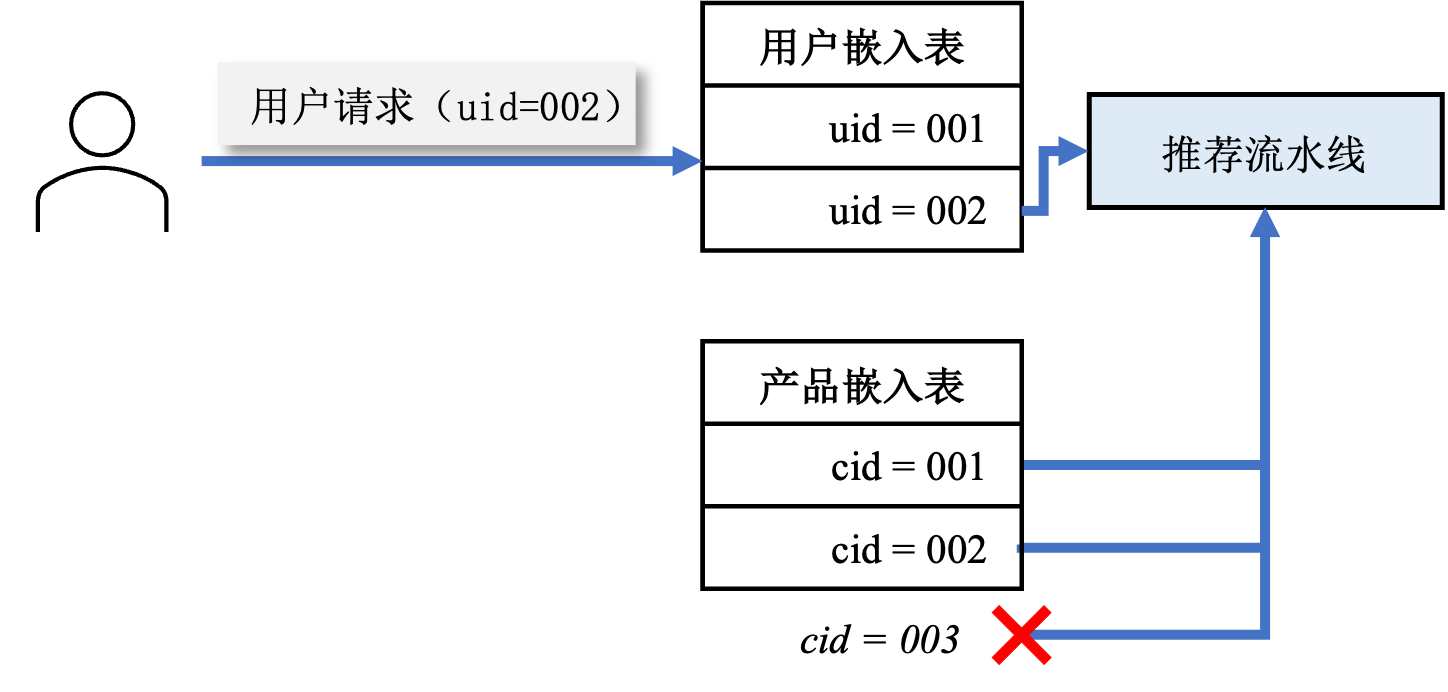
图12.3.2 物品嵌入项缺失
以上问题虽然也可以通过人工制定的规则来处理,例如,在直接在推荐结果中加入新物品,或者基于统计的热点物品,但是这些规则只能在短时间内一定程度上缓解问题,而不能彻底解决问题,因为基于人工规则的推荐性能和推荐模型存在较大差距。
离线更新
传统的推荐系统采用基于模型检查点的离线更新的方式,更新频率从每天到每小时不等,如图 图12.3.3所示。
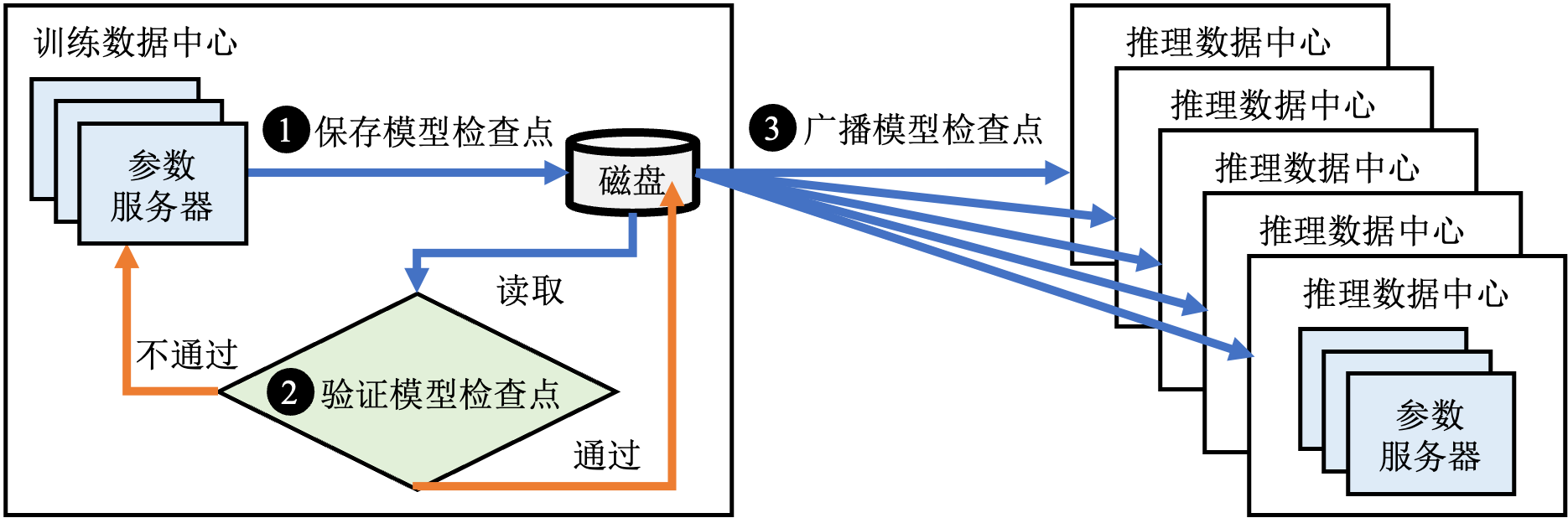
图12.3.3 离线更新
具体来讲,在训练一段时间之后,有如下步骤:
- 从训练数据中心的参数服务器上保存一份模型检查点到磁盘中;
- 基于离线数据集对模型检查点进行验证,如果离线验证不通过则继续训练;
- 如果离线验证通过,则将检查点以广播的方式发送到所有的推理数据中心。
这一流程耗费的时间从数分钟到数小时不等。也有一些系统对保存和发送检查点的过程进行了优化,可以做到分钟级模型更新。
然而随着互联网服务的进一步发展,分钟级的模型更新间隔在一些场景下依然是远远不够的:
- 一些应用非常看重其中物品的实时性。例如在短视频推荐场景下,内容创作者可能会根据实时热点创作视频,如果这些视频不能被及时推荐出去,等热点稍过观看量可能会远远不及预期。
- 无法获取用户特征或者特征有限的场景。近年来,随着用户隐私保护意识的增长和相关数据保护法规的完善,用户常常倾向于匿名使用应用,或者尽量少地提供非必要的数据。这就使得推荐系统需要在用户使用的这段极短的时间内时间内在线学习到用户的兴趣。
- 需要使用在线训练范式的场景。传统的推荐系统通常采用离线训练的方式,即累计一段时间(例如,一天)的训练数据来训练模型,并将训练好的模型在低峰期(例如,凌晨)上线。最近越来越多的研究和实践表明,增大训练频率可以有效提升推荐效果。将训练频率增加到最高的结果就是在线训练,即流式处理训练数据并送给模型,模型持续地基于在线样本调整参数,模型更新被即时用于服务于用户。模型更新作为在线训练的一个主要环节,必须要降低延迟以达到更好的训练效果。
在下一小节,我们将详细分析一个前沿的推荐系统是如何解决模型快速更新的问题的。
参考文献
- Russakovsky, Olga and Deng, Jia and Su, Hao and Krause, Jonathan and Satheesh, Sanjeev and Ma, Sean and Huang, Zhiheng and Karpathy, Andrej and Khosla, Aditya and Bernstein, Michael. Imagenet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV). 2015. ↩
- Merity, Stephen and Xiong, Caiming and Bradbury, James and Socher, Richard. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843. 2016. ↩
案例分析:支持在线模型更新的大型推荐系统
案例分析:支持在线模型更新的大型推荐系统
下面我们分析一个新型的支持低延迟模型更新的推荐系统Ekko ,从而引入实际部署推荐系统所需要考虑的系统设计知识。Ekko的核心思想是将训练服务器产生的梯度或模型更新立刻发送至所有参数服务器,绕过费时长达数分钟乃至数小时的保存模型检查点、验证模型检查点、广播模型检查点到所有推理数据中心的过程。如此一来,推理服务器每次都能从同一数据中心的参数服务器上读到最新的模型参数。我们将这样的模型更新方式称为在线更新,以区别于上一小节介绍的离线更新,如图 图12.4.1所示。
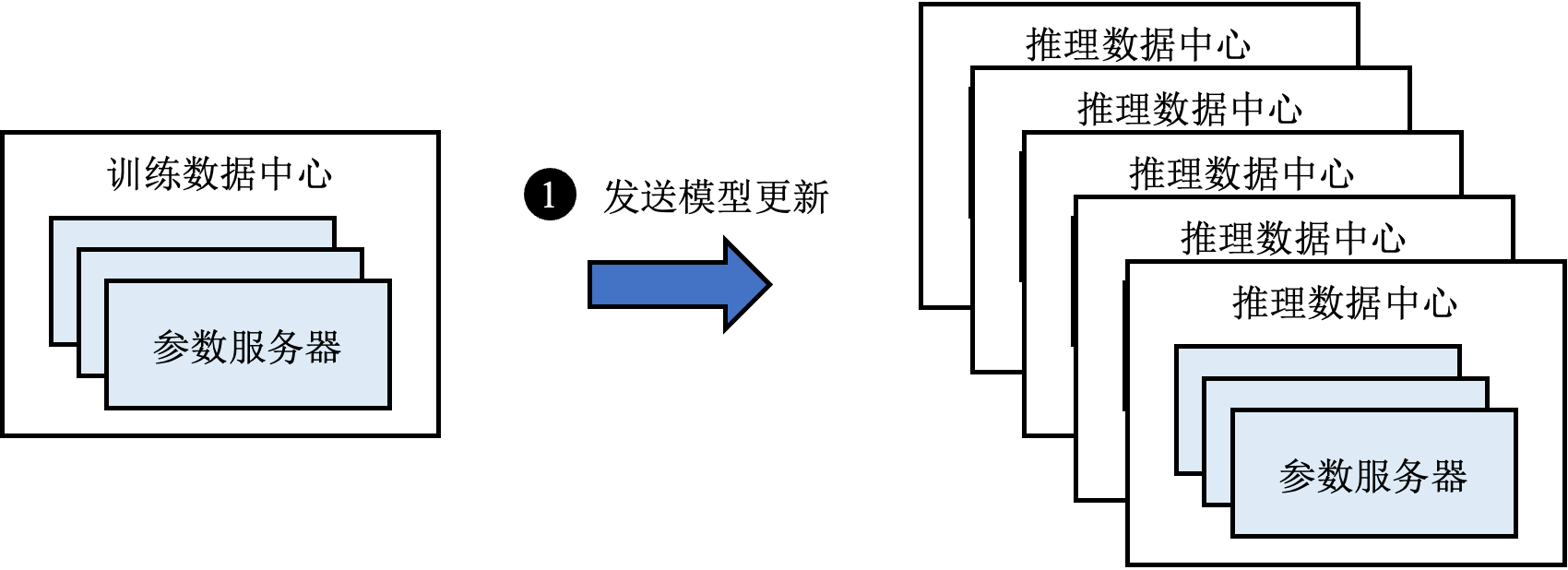
图12.4.1 在线更新
系统设计挑战
相比于离线更新,在线更新避免了费时的存储和验证模型检查点的步骤,然而也带来了新的问题和挑战:
1. 通过广域网传输海量的模型更新
在训练数据中心内部,训练服务器通过局域网(LAN)向参数服务器发送模型更新的速度可达几百GB每秒,而不同数据中心之间的网络带宽往往只有数Gbps,而且所有数据中心的网络带宽需要优先满足推理服务的需求——接受用户的推理请求并返回推荐结果。因此留给模型同步的带宽更加有限。
如果从训练数据中心向所有其他数据中心广播参数更新,会导致训练数据中心成为影响同步速度的瓶颈。假设训练数据中心需要广播一个100GB的模型至5个推理数据中心,训练数据中心可用的带宽为5Gbps,则需要花费800秒时间,这离秒级模型更新的需求还差了两个数量级。
如果使用如图 图12.4.2所示的链式复制 ,虽然可以避免在训练数据中心出现瓶颈,但是这种方式的更新延迟很大程度上取决于链上最慢的一段网络,导致在广域网的场景下延迟极高。

图12.4.2 链式复制
2. 防范网络拥塞影响推荐质量
模型跨地域更新的延迟很大程度上取决于网络状况,一旦网络繁忙出现拥塞,则整体更新延迟不可避免会上升,从而影响服务质量。而且采用在线更新的推荐系统更新流量也会有波峰,当模型更新流量波峰叠加网络拥塞,整体更新延迟更是雪上加霜。
3. 防范有偏差的模型更新影响推荐质量
模型在线更新带来的一个问题是,不可能单独对每一条更新进行检查以确保其对服务质量不会产生负面影响。因此有偏差的模型更新可能被发送到推理集群中,从而直接影响在线服务质量。而且在大规模在线环境中,出现有偏差的模型更新的概率并不低。
图 图12.4.3总结了在线更新会面临的系统挑战。
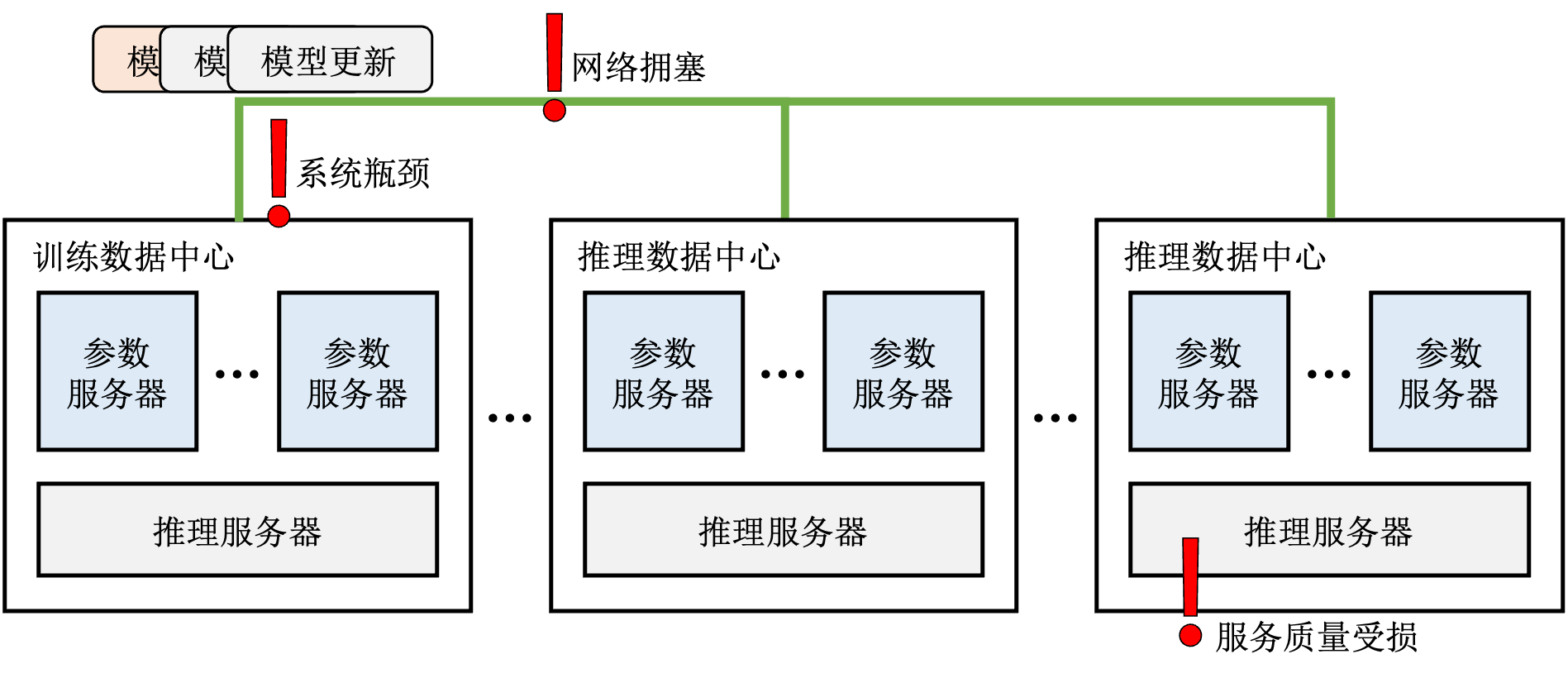
图12.4.3 系统挑战
系统架构
针对这些挑战,Ekko提出了如图 图12.4.4所总结的三个核心组件。概括来讲:
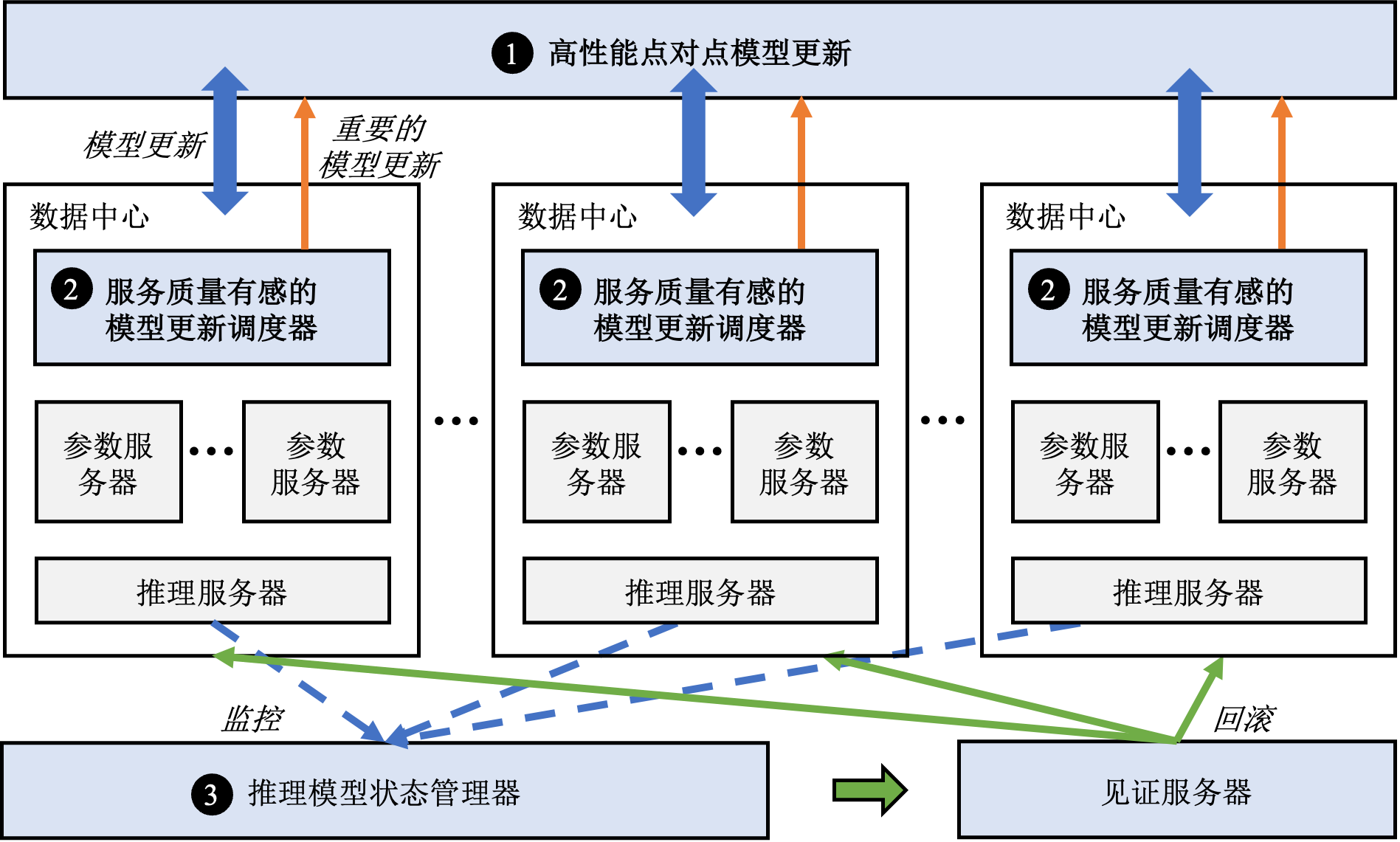
图12.4.4 Ekko的系统概览
- Ekko设计了一套高性能的点对点(Peer-to-Peer,P2P)模型更新传播算法,令参数服务器根据不同的网络带宽从同伴(peer)处以自适应的速率拉取模型更新,并且结合推荐模型的特点优化了拉取效率。
- Ekko设计了服务质量有感的模型更新调度器来发现那些会对服务质量产生重大影响的模型更新并且将其在点对点传播的过程中加速。
- Ekko设计了推理模型状态管理器来监控在线服务的质量并快速回滚被有害更新损害的模型状态以避免SLO(Service-Level Objectives)受到严重影响。
点对点模型更新传播算法
Ekko需要支持上千台分布在数个相隔上千公里的数据中心内的参数服务器之间传播模型更新。然而一个超大规模深度学习推荐系统每秒钟可以生成几百GB的模型更新,而数据中心之前的网络带宽仅有100Mbps到1Gbps不等。如果采用已有参数服务器架构,例如Project Adam 的两阶段提交协议,由训练数据中心向其他数据中心发送这些模型更新,不仅训练数据中心的带宽会成为瓶颈,而且整个系统的模型更新速度会受限于最慢的一条网络。同时Ekko的研究人员发现使用深度学习模型的推理服务器并不需要知道参数的更新过程,而仅需要知道参数的最新权重(状态)。有鉴于此,Ekko设计了基于状态的无日志同步算法,如图 P2P-replication所示,令参数服务器之间以自适应的速度相互拉取最新的模型更新。
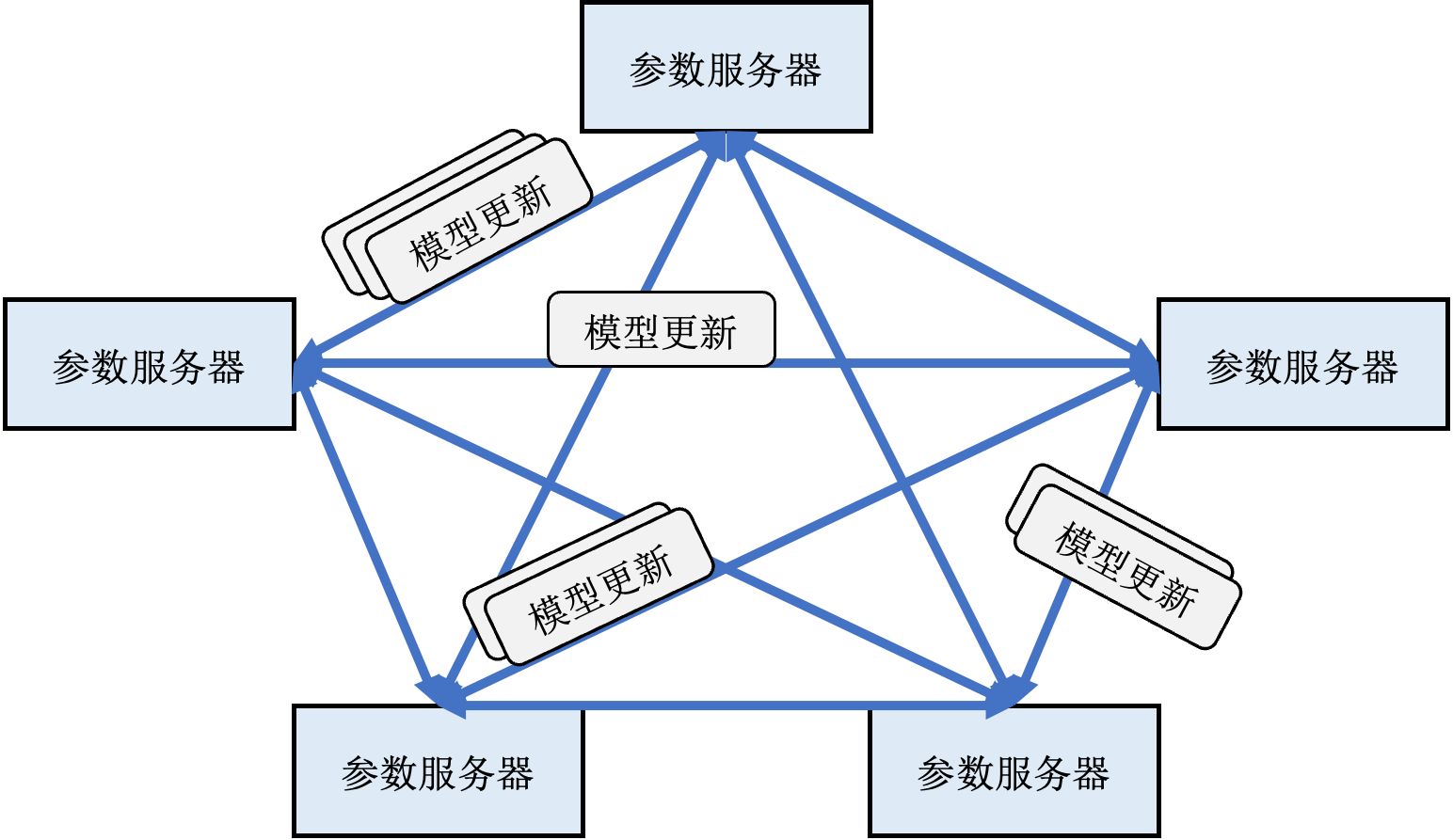
图12.4.5 点对点模型更新
为了实现点对点无日志同步算法,Ekko首先借鉴已有的版本向量(Version Vector)算法 [1][2],为每个参数(即每个键值对)赋予一个版本(Version)。版本可以记录参数的更新时间和地点。此外,Ekko在每个分片内设置一条版本向量(也称之为见闻,Knowledge),用来记录该分片的所有已知版本。通过对比版本号和版本向量,参数服务器可以在不发送参数本身的前提下从同伴处拉取更新的参数状态。对版本向量算法感兴趣的读者可以参考原论文了解细节。
然而Ekko的研究人员发现,即使使用了版本向量算法,从海量的模型参数中找出被更新的参数依然是非常慢的。为了加速找出被更新的参数的过程,Ekko利用了推荐模型的两个重要的特点。
- **更新稀疏性:**虽然一个模型可以有数百GB甚至数TB的嵌入表,但是由于模型训练一般采用小批次的方式,因此每次训练服务器只会更新这一小批次中涉及到的那些嵌入项。从全局来看,一段时间内嵌入表中仅有一小部分参数的状态会被更新。
- **时间局部性:**推荐系统中的模型更新并不是均匀分布在所有参数上的,一些热门的物品和活跃用户所对应的嵌入项在一段时间内会被频繁更新,反之,冷门物品和非活跃用户所对应的嵌入项根本不会被涉及。
结合这两个特点,Ekko加速比较过程的核心理念是:尽量避免浪费时间去比较那些没有被更新的参数的版本。
具体来讲,Ekko首先在每个分片内设计了一个模型更新缓存,其中保存的是近期刚刚被更新的参数的指针。假设参数服务器A正在试图从参数服务器B中拉取模型更新,如果参数服务器A已经知道所有不在B的缓存中的模型更新,那么A仅需要和B的缓存中的那些参数做比较,就能得到所有自己可能不知道的模型更新。
除此之外,Ekko还利用以上两个特点,为每个分片添加了一个分片版本(Shard Version),从而可以通过仅仅发送一个64比特的分片向量过滤掉那些根本没有模型更新的分片。分片版本减小的通信量带来的同步速度的提升也是非常显著的,Ekko的消融实验显示分片版本可以将更新延迟从27.4秒降低至6秒。
考虑到跨地域的网络带宽资源十分紧张,而集群内部的网络带宽相对宽裕,Ekko令每个集群内部选举一个本地领导负责从训练数据中心拉取模型更新,而集群内部的其他参数服务器从本地领导处拉取模型更新。在应用了这个简单但高效的优化之后,Ekko可以更进一步将模型更新延迟从6秒降低至2.6秒。此外,由于Ekko支持非常灵活的通讯拓扑,也可以应用已有的覆盖网络(Network Overlay)技术来进一步更加细致地优化通讯。
模型更新调度器
秒级模型更新的服务质量非常容易受到网络延迟的影响,而跨地域数据中心之间出现短暂的网络拥塞并不罕见。Ekko的设计者在实践中观察发现仅有一小部分关键的模型更新对服务质量具有决定性影响。为了最大程度保证在网络拥塞时的模型服务质量,Ekko会根据模型更新对服务质量的影响,赋予不同的优先级,并在点对点传播过程中优先发送这些关键更新。
具体来讲,Ekko的设计者提出了三种优先级指标来发现对服务质量具有决定性影响的模型更新:
- 更新的时新性 正如前文提到的,如果推荐模型的嵌入表中没有新用户或新物品所对应的嵌入项,那么该用户或物品完全无法受益于推荐模型带来的高服务质量。为了避免这种情况的发生,Ekko对新加入的嵌入项赋予最高优先级,使得这些嵌入项永远以最快的速度传播至所有推理服务集群。
- 更新的显著性 已有的大量研究都表明,大梯度的模型更新对模型的准确度会产生更加显著的影响,因此Ekko根据更新的幅度\footnote{根据模型的训练方式不同,更新幅度可能是梯度或梯度\(\times\)学习率}赋予不同模型更新不同的优先值。又因为Ekko服务于多模型场景,不同模型的数据分布不同,Ekko对每个模型在后台分别抽样统计平均更新幅度,每个更新的优先值取决于更新幅度和该模型平均更新幅度的比值。
- 模型的重要性 在在线服务的多个模型中,每个模型承载的推理流量并不相同,因此在网络拥塞的情况下,Ekko优先保证那些承载着大多数流量的模型的更新。具体来讲,每个更新根据其所属模型的流量比例决定优先值。
除了以上三种默认的优先级指标,Ekko也允许使用者自定义函数来根据模型自身情况使用其他指标。
如图 图12.4.6所示,对于每一条模型更新,Ekko根据公式 :eqrefpriority计算其总的优先值,然后和k%分位阈值做比较,如果大于k%分位阈值,则视为高优先级,否则为低优先级。K值由使用者设置,而k%分位阈值采用已有算法根据历史优先值估计。
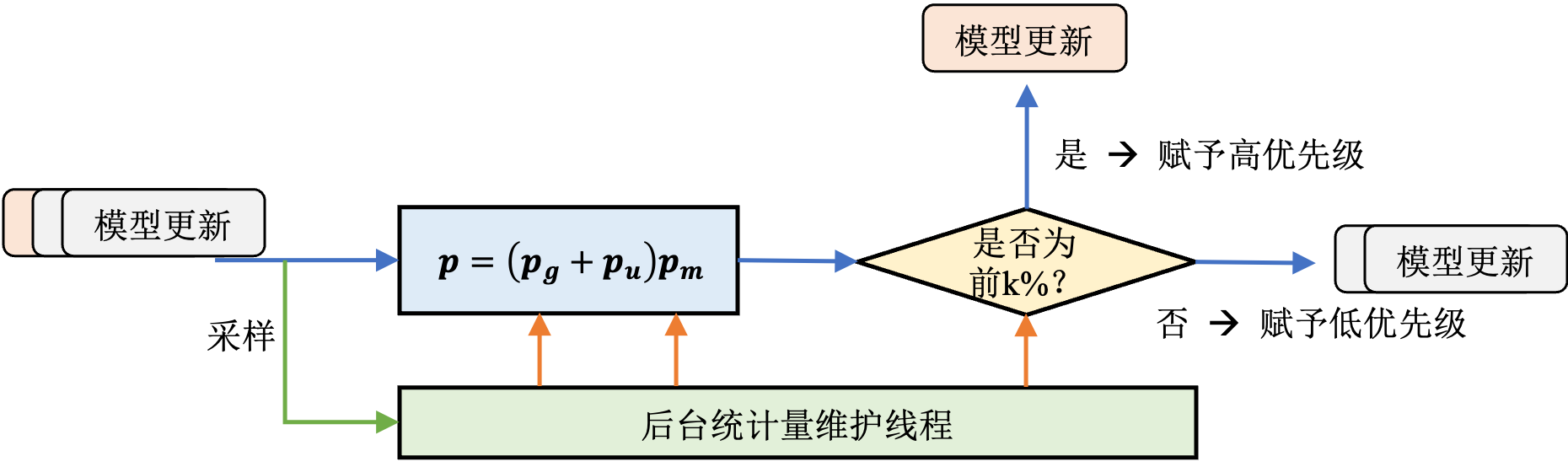
图12.4.6 SLO有感的模型更新调度器
\[ p=(p_g+p_u) \times p_m \tag{1}\label{priority} \]
具有高优先级的模型更新在后续点对点传播过程中会被加速,具体的传播算法见原论文的算法2。
Ekko的线上实验结果显示,当网络拥塞时,采用服务质量有感的模型更新调度器可以避免超过2%的服务质量下滑。
模型状态管理器
为了防止有害的模型更新影响到在线服务质量,Ekko设计了推理模型状态管理器来监控推理模型的健康状态。其核心思想是设置一组基线模型,并从推理请求中分出不到1%的流量给基线模型,从而可以得到基线模型的服务质量相关指标。如图 图12.4.7所示,推理模型状态管理器中的时序异常检测算法不断监控基线模型和在线模型的服务质量。模型质量的状态可能是健康、未定或者损害,由复制状态机维护。一旦确定在线模型处于损坏状态,首先将被损坏模型的流量切换至其他健康的替换模型上,然后在线回滚模型至健康的状态。
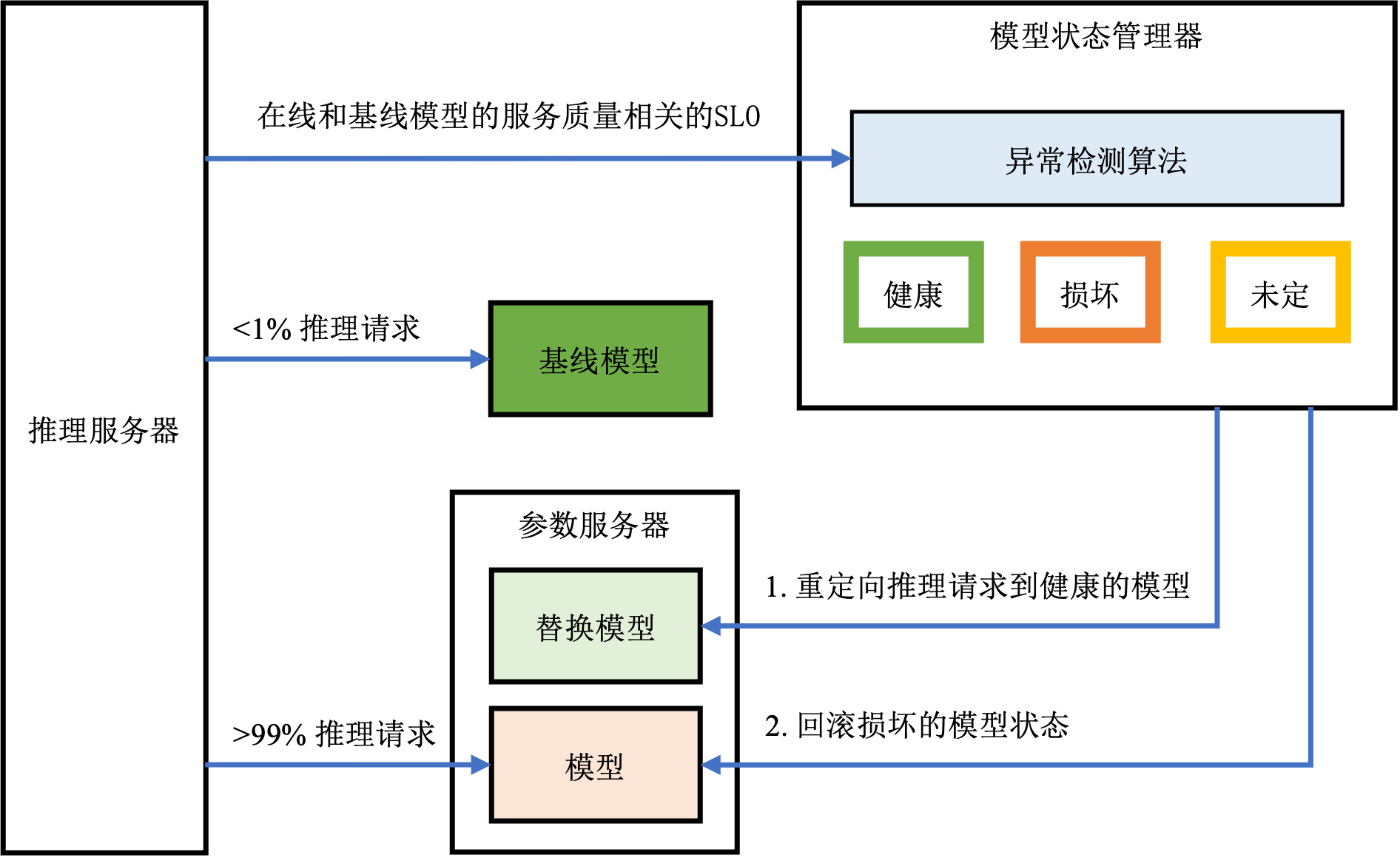
图12.4.7 模型状态管理器
小结
Ekko已经在生产环境中部署超过一年,服务超过10亿用户。Ekko成功将跨地域数据中心之间的模型平均更新延迟从分钟级别降低到了2.4秒,而在数据中心内部模型平均更新延迟可以低至0.7秒。秒级模型更新对于线上服务质量的提升十分明显,论文中的实验结果显示,仅仅加速多阶段推荐流水线中的一个排序模型,各项关键指标相比于分钟级模型更新就能够提升1.30%-3.28%。考虑到Ekko服务的用户规模,这种程度的提升是非常不平凡的,其所带来的收益也是非常可观的。
总而言之,Ekko提出了一种设计深度学习推荐系统的新思路,通过直接将模型更新发送到所有参数服务器这样一种在线更新的方式绕过了繁琐耗时的中间步骤,从而实现了秒级模型更新,显著提升了在线服务质量。针对在线更新可能带来的风险,Ekko设计了SLO保护机制,并且通过实验证明是行之有效的。这一小节简单介绍了工业界和学术界的前沿研究成果——Ekko的系统设计和背后的设计思想,希望能够给读者带来一些大型深度学习推荐系统设计的思考。受限于篇幅以及考虑到读者的阅读目标,本小节没有详细讨论Ekko的技术细节,如果读者对Ekko的技术设计细节感兴趣可以深入阅读原论文。
参考文献
- Malkhi, Dahlia and Terry, Doug. Concise Version Vectors in WinFS. Distributed Computing. 2005. ↩
- Malkhi, Dahlia and Novik, Lev and Purcell, Chris. P2P Replica Synchronization with Vector Sets. SIGOPS Oper. Syst. Rev.. 2007. ↩
小结
小结
推荐系统作为深度学习在工业界最成功的落地成果之一,极大地提升了用户的在线使用体验,并且为各大公司创造了可观的利润,从而促使各大公司持续加大对推荐系统的投入。过去两年推荐模型的规模成指数增长,带来了许多系统层面的挑战亟待解决。在实际的生产环境中面临的问题与挑战是本章区区几千字难以概括的,因此工业级推荐系统的架构必然十分复杂,本章只能抛砖引玉地简单介绍一种典型的推荐系统组成的基本架构和运行过程,并介绍了推荐系统面临的持续更新模型的挑战和一种前沿的解决方案。面对实际生产环境,具体的系统设计方案需要根据不同推荐场景的需求而变化,不存在一种万能的解决方案。
扩展阅读
-
推荐模型:Wide & Deep
-
消息队列介绍:什么是消息队列
-
特征存储介绍:什么是机器学习中的特征存储
联邦学习系统
在本章中,我们介绍深度学习的一个重要分支——联邦学习及其在系统方面的知识。本章的学习目标包括:
-
掌握联邦学习基本定义,并了解现有主流联邦开源框架。
-
了解横向联邦学习算法。
-
了解纵向联邦学习算法。
-
了解联邦学习加密算法。
-
了解联邦学习前沿算法和未来研究方向。
概述
概述
随着人工智能的飞速发展,大规模和高质量的数据对模型的效果和用户的体验都变得越来越重要。与此同时,数据的利用率成为了制约了人工智能的进一步发展的瓶颈。隐私、监管和工程等问题造成了设备与设备之间的数据不能共享,进而导致了数据孤岛问题的出现。为了解决这一难题,联邦学习(Federated Learning,FL)应运而生。联邦学习的概念最早在2016年被提了出来。在满足用户隐私保护、数据安全和政府法规的要求下,联邦学习能有效地使用多方机构的数据进行机器学习建模。
定义
联邦学习的核心是数据不动,模型动。显然,若是将数据从各方集中在一起,无法保证对用户隐私的保护,且不符合相关法律法规。联邦学习让模型在各个数据方“移动”,这样就可以达到数据不出端即可建模的效果。在联邦学习中,各方数据都保留在本地,通过(在中心服务器上)交换加密的参数或其他信息来建立机器学习模型。
应用场景
在实际的应用场景中,根据样本和特征的重叠情况,联邦学习可以被分为横向联邦学习(样本不同,特征重叠),纵向联邦学习(特征不同,样本重叠)和联邦迁移学习(样本和特征都不重叠)。
横向联邦学习适用于不同参与方拥有的特征相同、但参与的个体不同的场景。比如,在广告推荐场景中,算法开发人员使用不同手机用户的相同特征(点击次数、停留时间或使用频次等)的数据来建立模型。因为这些特征数据不能出端,横向联邦学习被用来联合多用户的特征数据来构建模型。
纵向联邦学习适用于样本重叠多、特征重叠少的场景。比如,有两个不同机构,一家是保险公司,另一家是医院。它们的用户群体很有可能包含该地的大部分居民。它们两方的用户交集可能较大。由于保险公司记录的是用户的收支行为与信用评级,而医院则拥有用户的疾病与购药记录,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力的方法。
联邦迁移学习的核心是找到源领域和目标领域之间的相似性。比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受到地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习。联邦迁移学习可以解决单边数据规模小和标签样本少的问题,并提升模型的效果。
部署场景
联邦学习和参数服务器(数据中心分布式学习)架构非常相似,都是采用中心化的服务器和分散的客户端去构建同一个机器学习模型。此外,根据部署场景的不同,联邦学习还可以细分为跨组织(Cross-silo)与跨设备(Cross-device)联邦学习。一般而言,跨组织联邦学习的用户一般是企业、机构单位级别的,而跨设备联邦学习针对的则是便携式电子设备、移动端设备等。 图13.1.1展示了三者的区别和联系:
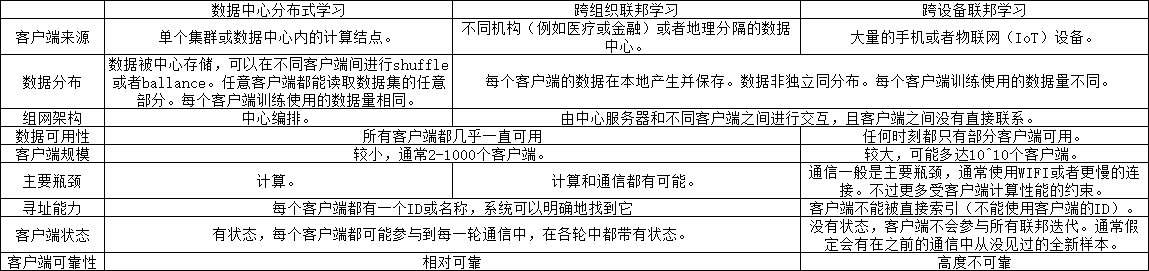
图13.1.1 数据中心分布式训练、跨组织和跨设备联邦学习的区别和联系
常用框架
随着用户和开发人员对联邦学习技术的需求不断增长,联邦学习工具和框架的数量也越来越多。下面将介绍一些主流的联邦学习框架。
TFF (TensorFlow Federated)是谷歌牵头开发的联邦学习开源框架,用于在分散数据上进行机器学习和其他计算。TFF的开发是为了促进联邦学习的开放研究和实验。在许多参与的客户中训练共享的全局模型,这些客户将其训练数据保存在本地。例如,联邦学习已被用于训练移动键盘的预测模型,而无需将敏感的键入数据上载到服务器。
PaddleFL是百度提出的一个基于PaddlePaddle的开源联邦学习框架。研究人员可以很轻松地用PaddleFL复制和比较不同的联邦学习算法,开发人员也比较容易在大规模分布式集群中部署PaddleFL联邦学习系统。PaddleFL提供很多种联邦学习策略(横向联邦学习、纵向联邦学习)及其在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,PaddleFL还提供传统机器学习训练策略的应用,例如多任务学习、联邦学习环境下的迁移学习。依靠着PaddlePaddle的大规模分布式训练和Kubernetes对训练任务的弹性调度能力,PaddleFL可以基于全栈开源软件轻松地部署。
FATE (Federated AI Technology Enabler)由微众银行提出,是全球首个联邦学习工业级开源框架,可以让企业和机构在保证数据安全和数据隐私不泄露的前提下进行数据协作。 FATE项目使用多方安全计算 (Secure Multi-Party Computation,MPC) 以及同态加密 (Homomorphic Encryption,HE) 技术构建底层安全计算协议,以此支持不同种类的机器学习的安全计算,包括逻辑回归、基于树的算法、深度学习和迁移学习等。 FATE于2019年2月首次对外开源,并成立FATE社区。社区成员包含国内主要云计算和金融服务企业。
FedML是一个南加利福尼亚大学(University of Southern California,USC)牵头提出的联邦学习开源研究和基准库,它有助于开发新的联合学习算法和公平的性能比较。FedML支持三种计算范式(分布式训练、移动设备上训练和独立模拟),供用户在不同的系统环境中进行实验。FedML还通过灵活和通用的API设计和参考基线实现并促进了多样化的算法研究。为了使各联邦学习算法可以进行公平比较,FedML设置了全面的基准数据集,其中包括非独立同分布(Independent Identically Distribution,IID)数据集。
PySyft是伦敦大学学院(University College London,UCL)、DeepMind和OpenMined发布的安全和隐私深度学习Python库,包括联邦学习、差分隐私和多方学习。PySyft使用差分隐私和加密计算(MPC和HE)将私有数据与模型训练解耦。
Fedlearner是字节跳动提出的纵向联邦学习框架,它允许对分布在机构之间的数据进行联合建模。Fedlearner附带了用于集群管理、作业管理、作业监控和网络代理的周围基础架构。Fedlearner采用云原生部署方案,并将数据存放在HDFS中。Fedlearner通过Kubernetes管理和拉起任务。每个Fedlearner的参与双方需要同时通过Kubernetes拉起训练任务,并通过Master节点统一管理多个训练任务,以及通过Worker实现通信。
OpenFL是英特尔提出的用于联邦学习的Python框架。OpenFL旨在成为数据科学家的灵活、可扩展和易于学习的工具。
Flower是剑桥大学发布的联邦学习开源系统,主要针对在大规模、异质化设备上部署联邦学习算法的应用场景进行优化。
MindSpore Fedrated是华为提出的一款开源联邦学习框架,支持千万级无状态终端设备商用化部署,在用户数据留存在本地的情况下,使能全场景智能应用。MindSpore Federated专注于大规模参与方的横向联邦学习的应用场景,使参与联邦学习的各用户在不共享本地数据的前提下共建AI模型。MindSpore Federated主要解决隐私安全、大规模联邦聚合、半监督联邦学习、通信压缩和跨平台部署等联邦学习在工业场景部署的难点。
横向联邦学习
横向联邦学习
云云场景中的横向联邦
在横向联邦学习系统中,具有相同数据结构的多个参与者通过云服务器协同建立机器学习模型。一个典型的假设是参与者是诚实的,而服务器是诚实但好奇的,因此不允许任何参与者向服务器泄漏原始的梯度信息。这种系统的训练过程通常包括以下四个步骤:
①:参与者在本地计算训练梯度,使用加密、差分隐私或秘密共享技术掩码所选梯度,并将掩码后的结果发送到服务器。
②:服务器执行安全聚合,不了解任何参与者的梯度信息。
③:服务器将汇总后的结果发送给参与者。
④:参与者用解密的梯度更新他们各自的模型。
和传统分布式学习相比,联邦学习存在训练结点不稳定和通信代价大的难点。这些难点导致了联邦学习无法和传统分布式学习一样:在每次单步训练之后,同步不同训练结点上的权重。为了提高计算通信比并降低频繁通信带来的高能耗,谷歌公司在2017年 [1]提出了联邦平均算法(Federated Averaging,FedAvg)。 :numfef:ch10-federated-learning-fedavg展示了FedAvg的整体流程。在每轮训练过程中,客户端进行了多次单步训练。然后服务端聚合多个客户端的权重,并取加权平均。

图13.2.1 联邦平均算法
端云场景中的横向联邦
端云联邦学习的总体流程和云云联邦学习一样,但端云联邦学习面临的难点还包括以下三个方面:
1.高昂的通信代价。和云云联邦学习不同之处,端云联邦学习的通信开销主要在于单次的通信量,而云云联邦学习的开销主要在于通信的频率。在端云联邦学习场景中,通常的通信网络可能是WLAN或移动数据,网络通信速度可能比本地计算慢许多个数量级,这就造成高昂的通信代价成为了联邦学习的关键瓶颈。
2.系统异质性。由于客户端设备硬件条件(CPU、内存)、网络连接(3G、4G、5G、WIFI)和电源(电池电量)的变化,联邦学习网络中每个设备的存储、计算和通信能力都有可能不同。网络和设备本身的限制可能导致某一时间仅有一部分设备处于活动状态。此外,设备还会出现没电、网络无法接入等突发状况,导致瞬时无法连通。这种异质性的系统架构影响了联邦学习整体策略的制定。
3.隐私问题。由于端云联邦学习的客户端无法参与每一轮迭代,因此在数据隐私保护上的难度高于其他的分布式学习方法。而且,在联邦学习过程中,端云传递模型的更新信息还存在向第三方或中央服务器暴露敏感信息的风险。隐私保护成为端云联邦学习需要重点考虑的问题。
为了解决端云联邦学习带来的挑战,MindSpore Federated设计了分布式FL-Server架构。系统由调度器模块、服务器模块和客户端模块三个部分组成,其系统架构如 图13.2.2所示。各个模块的功能说明:
-
联邦学习调度器:
联邦学习调度器(FL-Scheduler)协助集群组网,并负责管理面任务的下发。
-
联邦学习服务器:
联邦学习服务器(FL-Server)提供客户端选择、限时通信、分布式联邦聚合功能。FL-Server需要具备支持端云千万台设备的能力以及支持边缘服务器的接入和安全处理的逻辑。
-
联邦学习客户端:
联邦学习客户端(FL-Client)负责本地数据训练,并在和FL-Server进行通信时,对上传权重进行安全加密。

图13.2.2 联邦学习系统架构图
此外,MindSpore Federated针对端云联邦学习设计了出四大特性:
1.限时通信:在FL-Server和FL-Client建立连接后,启动全局的计时器和计数器。当预先设定的时间窗口内的FL-Server接收到FL-Client训练后的模型参数满足初始接入的所有FL-Client的一定比例后,就可以进行聚合。若时间窗内没有达到比例阈值,则进入下一轮迭代。保证即使有海量FL-Client接入的情况下,也不会由于个别FL-Client训练时间过长或掉线导致的整个联邦学习过程卡死。
2.松耦合组网:使用FL-Server集群。每个FL-Server接收和下发权重给部分FL-Client,减少单个FL-Server的带宽压力。此外,支持FL-Client以松散的方式接入。任意FL-Client的中途退出都不会影响全局任务,并且FL-Client在任意时刻访问任意FL-Server都能获得训练所需的全量数据。
3.加密模块:MindSpore Federated为了防止模型梯度的泄露,部署了多种加密算法:本地差分隐私(Local Differential Privacy,LDP)、基于多方安全计算(MPC)的安全聚合算法和华为自研的基于符号的维度选择差分隐私算法(Sign-based Dimension Selection,SignDS)。
4.通信压缩模块:MindSpore Federated分别在FL-Server下发模型参数和FL-Client上传模型参数时,使用量化和稀疏等手段将权重压缩编码成较小的数据格式,并在对端将压缩编码后的数据解码为原始的数据。
参考文献
- Brendan McMahan and Eider Moore and Daniel Ramage and Seth Hampson and Blaise Ag\"uera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 20-22 April 2017, Fort Lauderdale, FL, USA. 2017. ↩
纵向联邦学习
纵向联邦学习
现在我们介绍另一种联邦学习算法:纵向联邦学习(Vertical Federated Learning)。纵向联邦学习的参与方拥有相同样本空间、不同特征空间的数据,通过共有样本数据进行安全联合建模,在金融、广告等领域拥有广泛的应用场景。和横向联邦学习相比,纵向联邦学习的参与方之间需要协同完成数据求交集、模型联合训练和模型联合推理。并且,参与方越多,纵向联邦学习系统的复杂度就越高。
下面以企业A和企业B两方为例来介绍纵向联邦学习的基本架构和流程。假设企业A有特征数据和标签数据,可以独立建模;企业B有特征数据,缺乏标签数据,因此无法独立建模。由于隐私法规和行业规范等原因,两个企业之间的数据无法直接互通。企业A和企业B可采用纵向联邦学习解决方案进行合作,数据不出本地,使用双方共同样本数据进行联合建模和训练。最终双方都能获得一个更强大的模型。
纵向联邦架构

图13.3.1 纵向联邦两方架构
纵向联邦学习系统中的模型训练一般分为如下阶段:
- 样本对齐:首先对齐企业A和企业B中具有相同ID(Identification)的样本数据。在数据对齐阶段,系统会采用加密算法对数据进行保护,确保任何一方的用户数据不会暴露。
- 联合训练:在确定企业A和企业B共有用户数据后,可以使用这些共有的数据来协同训练一个业务模型。模型训练过程中,模型参数信息以加密方式进行传递。已训练好的联邦学习模型可以部署在联邦学习系统的各参与方。
样本对齐
隐私集合求交(Private Set Intersection,PSI)技术是纵向联邦学习中数据样本对齐的常用解决方案。业界PSI实现方案有多种:基于电路、基于公钥加密、基于不经意传输协议和基于全同态加密等。不同PSI方案各有优劣势。例如,基于公钥加密方案不需要辅助服务器运行,但公钥加密的计算开销大;而基于不经意传输方案计算性能高,但通信开销较大。因此在具体应用时,要根据实际场景来选择功能、性能和安全之间的最佳平衡方案。
基于RSA盲签名是一种基于公钥加密的经典PSI方法,也是当前业界纵向联邦学习系统中广泛应用的技术之一。下面以企业A和企业B为例描述RSA盲签名算法的基本流程。
图13.3.2 纵向联邦样本对齐
企业A作为服务端,拥有一个包含了标签数据+样本ID的集合。企业B则作为客户端,拥有样本ID集合。首先,企业A利用RSA算法生成私钥和公钥。其中,私钥保留在服务端,公钥则发送给企业B。
服务端利用RSA算法计算出参与样本对齐的ID的签名: \[t_j=H^{‘}(K_{a:j})\] 其中,\(K_{a:j}=(H(a_j))^d \ mod \ n\),是采用私钥\(d\)加密的对\(H(a_j)\)的RSA加密的结果。\(H()\)和\(H^{’}()\)是哈希函数。
_同样,在客户端侧对样本ID进行公钥加密,并乘以一个随机数\(R_{b,i}\)用于加盲扰动: \[y_i=H(b_i)\cdot(R_{b,i})^e \ mod \ n\] 客户端侧将上述计算出来的\({y_1,…,y_v}\)值传输给服务端侧。服务端侧收到\(y_i\)值后,使用私钥\(d\)进行签名并计算: \[y_i^{‘}=y_i^d \ mod \ n\] 然后将计算出的\({y_1^{’},…,y_v^{‘}}\)和\({t_1,…,t_w}\)发送给客户端侧。 而客户端侧收到\(y_i^{’}\)和\(t_j\)后,首先完成去盲操作: \[K_{b:i}={y_i}^{‘}/R_{b,i}\] 并将自己的ID签名与服务端发过来的ID签名进行样本对齐,得到加密和哈希组合状态下的ID交集\(I\), \[{t_i}^{’}=H^{‘}(K_{b:i}) \\I={t_1,…,t_w}\cap {{t_1}^{’},…,{t_v}^{’}}\]
最后,将对齐后的样本ID交集\(I\)发送给服务端,服务端利用自身的映射表单独求取明文结果。这样企业A和企业B在加密状态下完成了求取相交的用户集合,并且在整个过程中双方非重叠样本ID都不会对外暴露。
联合训练
在样本ID对齐后,开发人员就可以使用这些公共的数据来建立机器学习模型。
目前,线性回归、决策树和神经网络等模型已经被广泛应用到纵向联邦学习系统中。在纵向联邦学习的模型训练过程中,一般会引入第三方协作者C来实现中心服务器功能,并且假设这个第三方协作者C是可信的,不会与其他参与方合谋。中心服务器在训练过程中作为中立方,产生和分发密钥,并对加密数据进行解密和计算。但中心服务器角色是非必须的,例如在两方联邦学习的场景下,不需要第三方协作者C来协调双方的训练任务,可以由具有标签数据的企业A来充当中心服务器的角色。不失一般性,下面继续以包含第三方协作者C的方案来描述纵向联邦学习模型联合训练过程。

图13.3.3 纵向联邦联合建模
- 第一步:由第三方协作者C创建密钥对,将公钥发送给企业A和B。
- 第二步:在企业A和B侧分别计算梯度和损失计算需要的中间结果,并进行加密和交换。
- 第三步:企业A和B分别计算加密梯度和添加掩码。同时企业A还将计算加密损失值。计算完成后,企业A和B向第三方协作者C发送加密后的值。
- 第四步:第三方协作者C对梯度和损失值解密,然后将结果发送回企业A和B。
- 第五步:企业A和B将收到的值首先去除梯度上的掩码,然后更新本地模型参数。
在整个训练过程中,企业A和B之间的任何敏感数据都是经过加密算法加密之后再发出的各自的信任域。同态加密(Homomorphic Encryption,HE)是业界联邦学习框架常用的算法之一。同态加密是指加密过后的两份数据进行某些运算之后直接解密,可以得到真实数据经过相同运算的结果。当这种运算是加法时,就称为加法同态加密。将加密函数记为\([[\cdot]]\)。
隐私加密算法
隐私加密算法
联邦学习过程中,用户数据仅用于本地设备训练,不需要上传至中央FL-Server。这样可以避免用户个人数据的直接泄露。然而联邦学习框架中,模型的权重以明文形式上云仍然存在间接泄露用户隐私的风险。敌手获取到用户上传的明文权重后,可以通过重构、模型逆向等攻击恢复用户的个人训练数据,导致用户隐私泄露。
MindSpore Federated框架,提供了基于本地差分隐私(LDP)、基于多方安全计算(MPC)的安全聚合算法和华为自研的基于符号的维度选择差分隐私算法(SignDS),在本地模型的权重上云前对其进行加噪或加扰。在保证模型可用性的前提下,解决联邦学习中的隐私泄露问题。
基于LDP的安全聚合
差分隐私(differential privacy)是一种保护用户数据隐私的机制。差分隐私定义为: \[ Pr[\mathcal{K}(D)\in S] \le e^{\epsilon} Pr[\mathcal{K}(D’) \in S]+\delta \]
对于两个差别只有一条记录的数据集\(D\)和\(D’\),通过随机算法\(\mathcal{K}\),输出结果为集合\(S\)子集的概率满足上面公式。\(\epsilon\)为差分隐私预算,\(\delta\)为扰动,\(\epsilon\)和\(\delta\)越小,说明\(\mathcal{K}\)在\(D\)和\(D’\)上输出的数据分布越接近。
在联邦学习中,假设FL-Client本地训练之后的模型权重矩阵是\(W\),由于模型在训练过程中会“记住”训练集的特征,所以敌手可以借助\(W\)还原出用户的训练数据集。
MindSpore Federated提供基于本地差分隐私的安全聚合算法,防止本地模型的权重上云时泄露隐私数据。
FL-Client会生成一个与本地模型权重矩阵\(W\)相同维度的差分噪声矩阵\(G\),然后将二者相加,得到一个满足差分隐私定义的权重矩阵\(W_p\):
\[ W_p=W+G \]
FL-Client将加噪后的模型权重矩阵\(W_p\)上传至云侧FL-Server进行联邦聚合。噪声矩阵\(G\)相当于给原模型加上了一层掩码,在降低模型泄露敏感数据风险的同时,也会影响模型训练的收敛性。如何在模型隐私性和可用性之间取得更好的平衡,仍然是一个值得研究的问题。实验表明,当参与方的数量\(n\)足够大时(一般指1000以上),大部分噪声能够相互抵消,本地差分隐私机制对聚合模型的精度和收敛性没有明显影响。
基于MPC的安全聚合
尽管差分隐私技术可以适当保护用户数据隐私,但是当参与FL-Client数量比较少或者高斯噪声幅值较大时,模型精度会受较大影响。为了同时满足模型保护和模型收敛这两个要求,MindSpore Federated提供了基于MPC的安全聚合方案。
尽管差分隐私技术可以适当保护用户数据隐私,但是当参与FL-Client数量比较少或者高斯噪声幅值较大时,模型精度会受较大影响。为了同时满足模型保护和模型收敛这两个要求,MindSpore Federated提供了基于MPC的安全聚合方案。
在这种训练模式下,假设参与的FL-Client集合为\(U\),对于任意FL-Client \(u\)和\(v\),它们会两两协商出一对随机扰动\(p_{uv}\)、\(p_{vu}\),满足
\[ \label{puv} p_{uv}= \begin{cases} -p_{vu}, &u{\neq}v\\ 0, &u=v \end{cases} \] 于是每个FL-Client \(u\) 在上传模型权重至FL-Server前,会在原模型权重\(x_u\)加上它与其它用户协商的扰动:
\[ x_{encrypt}=x_u+\sum\limits_{v{\in}U}p_{uv} \]
从而FL-Server聚合结果\(\overline{x}\)为: \[ \label{eq:juhejieguo} \overline{x}=\sum\limits_{u{\in}U}(x_{u}+\sum\limits_{v{\in}U}p_{uv})=\sum\limits_{u{\in}U}x_{u}+\sum\limits_{u{\in}U}\sum\limits_{v{\in}U}p_{uv}=\sum\limits_{u{\in}U}x_{u} \] 上面的过程只是介绍了聚合算法的主要思想,基于MPC的聚合方案是精度无损的,代价是通讯轮次的增加。
基于LDP-SignDS算法的安全聚合
对于先前的基于维度加噪的LDP算法,添加到每个维度的噪声规模基本上与模型参数的数量成正比。因此,对于高维模型,可能需要非常多的参与方来减轻噪音对模型收敛的影响。为了解决上述“维度依赖”问题,MindSpore Federated 进一步提供了基于维度选择的Sign-based Dimension Selection (SignDS) [1]算法。
SignDS算法的主要思想是,对于每一条真实的本地更新\(\Delta\in\mathbb{R}^{d}\),FL-Client首先选择一小部分更新最明显的维度构建Top-K集合\(S_k\),并以此选择一个维度集合\(J\)返回给FL-Server。FL-Server根据维度集合\(J\)构建一条对应的稀疏更新\(\Delta^\prime\),并聚合所有稀疏更新用于更新全局模型。由于本地模型更新与本地数据信息相关联,直接选取真实的最大更新维度可能导致隐私泄露。对此,SignDS算法在两方面实现了隐私安全保证。一方面,算法使用了一种基数机制(Exponential Mechanism, EM [2])的维度选择算法EM-MDS,使得所选维度集满足严格的\(\epsilon\)-LDP保证;另一方面,在构建稀疏更新时,对所选维度分配一个常量值而不直接使用实际更新值,以保证稀疏更新和本地数据不再直接关联。由于维度选择满足\(\epsilon\)-LDP,且分配给所选维度的更新值与本地数据无关,根据差分隐私的传递性 [3],所构建的稀疏更新同样满足\(\epsilon\)-LDP保证。相较于之前基于维度加噪的LDP算法,SignDS算法可以显著提升高维模型的训练精度。同时,由于FL-Client只需上传一小部分的维度值而不是所有的模型权重,因此联邦学习的上行通信量也被大大降低。
下面,我们分别对Top-K集合\(S_k\)的构建和EM-MDS维度选择算法进行详细介绍。
首先,由于实际更新值有正负,直接给所有选定的维度分配相同的常量值可能会明显改变模型更新方向,影响模型收敛。为了解决这个问题,SignDS提出了一种基于符号的Top-K集合构建策略。具体来讲,算法引入了一个额外的符号变量\(s\in\\{-1,1\\}\)。该变量由FL-Client以等概率随机采样,用于确定本地更新\(\Delta\)的Top-K集合\(S_k\)。如果\(s=1\),我们将\(\Delta\)按真实更新值排序,并将最大的\(k\)个更新维度记为\(S_k\)。我们进一步从\(S_k\)中随机选择一部分维度,并将\(s=1\)作为这些维度的更新值用以构建稀疏更新。直觉上,\(S_k\)中维度的更新值很可能大于零。因此,将\(s=1\)分配给选定的维度不会导致模型更新方向的太大差异,从而减轻了对模型精度的影响。类似的,当\(s=-1\)时,我们选取最小的\(k\)个更新维度记为\(S_k\),并将\(s=-1\)分配给所选维度。
下面,我们进一步介绍用于维度选择的EM-MDS算法。简单来说,EM-MDS算法的目的是从输出维度域\(\mathcal{J}\)中以一定概率\(\mathcal{P}\)随机选择一个维度集合\(J\in\mathcal{J}\),不同维度集合对应的概率不同。我们假设\(J\)总共包含\(h\)个维度,其中有\(\nu\)个维度属于Top-K集合(即\(|S_k \cap J|=\nu\),且\(\nu\in[0,h]\)),另外\(h-\nu\)个维度属于非Top-K集合。直观上,\(\nu\)越大,\(J\)中包含的Top-K维度越多,模型收敛越好。因此,我们希望给\(\nu\)较大的维度集合分配更高的概率。基于这个想法,我们将评分函数定义为: \[ u(S_{k}, J) = 𝟙(|S_k\cap J| \geq \nu_{th}) = 𝟙(\nu \geq \nu_{th}) \tag{1}\label{score_function} \]
\(u(S_{k}, J)\)用来衡量输出维度集合\(J\)中包含的Top-K维度的数量是否超过某一阈值\(\nu_{th}\)(\(\nu_{th}\in[1,h]\)),超过则为1,否则为0。进一步,\(u(S_{k}, J)\)的敏感度可计算为:
\[ \phi = \max_{J\in\mathcal{J}} ||u(S_{k}, J) - u(S^\prime_{k}, J)||= 1 - 0 = 1 \tag{2}\label{sensitivity} \]
注意 (2)对于任意一对不同的Top-K集合\(S_k\)和\(S_k^\prime\)均成立。
根据以上定义,EM-MDS算法描述如下:
给定真实本地更新\(\Delta\in\mathbb{R}^{d}\)的Top-K集合\(S_k\)和隐私预算\(\epsilon\),输出维度集合\(J\in\mathcal{J}\)的采样概率为:
\[ \mathcal{P}=\frac{\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S_{k}, J))}{\sum_{J^\prime\in\mathcal{J}}\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S_{k}, J^\prime))} = \frac{\mathrm{exp}(\epsilon\cdot 𝟙(\nu \geq \nu_{th}))}{\sum_{\tau=0}^{\tau=h}\omega_{\tau}\cdot \mathrm{exp}(\epsilon\cdot 𝟙(\tau\geq\nu_{th}))} = \frac{\mathrm{exp}(\epsilon\cdot 𝟙(\nu \geq \nu_{th}))}{\sum_{\tau=0}^{\tau=\nu_{th}-1}\omega_{\tau} + \sum_{\tau=\nu_{th}}^{\tau=h}\omega_{\tau}\cdot \mathrm{exp}(\epsilon)} \tag{3}\label{emmds} \]
其中,\(\nu\)是\(J\)中包含的Top-K维度数量,\(\nu_{th}\)是评分函数的阈值,\(J^\prime\)是任意一输出维度集合,\(\omega_{\tau}=\binom{k}{\tau}\binom{d-k}{h-\tau}\)是所有包含\(\tau\)个Top-K维度的集合数。
我们进一步提供了EM-MDS算法的隐私证明:
对于每个FL-Client,给定随机采样的符号值\(x\),任意两个本地更新\(\Delta\),\(\Delta^\prime\)的Top-K集合记为\(S_k\)和\(S_k^\prime\),对于任意输出维度集合\(J\in\mathcal{J}\),令\(\nu=|S_k \cap J|\), \(\nu^\prime=|S_k^\prime \cap J|\)为\(J\)与两组Top-K维度集的交集数量。根据 (3),以下不等式成立:
\[ \frac{\mathrm{Pr}[J|\Delta]}{\mathrm{Pr}[J|\Delta^\prime]} = \frac{\mathrm{Pr}[J|S_{k}]}{\mathrm{Pr}[J|S^\prime_{k}]} = \frac{\frac{\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S_{k}, J))}{\sum_{J^\prime\in\mathcal{J}}\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S_{k}, J^\prime))}}{\frac{\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S^\prime_{k}, J))}{\sum_{J^\prime\in\mathcal{J}}\mathrm{exp}(\frac{\epsilon}{\phi}\cdot u(S^\prime_{k}, J^\prime))}} = \frac{\frac{\mathrm{exp}(\epsilon\cdot 𝟙(\nu \geq \nu_{th}))}{\sum_{\tau=0}^{\tau=h}\omega_{\tau}\cdot \mathrm{exp}(\epsilon\cdot 𝟙(\tau\geq\nu_{th}))}}{\frac{ \mathrm{exp}(\epsilon\cdot 𝟙(\nu^\prime \geq \nu_{th}))}{\sum_{\tau=0}^{\tau=h}\omega_{\tau}\cdot \mathrm{exp}(\epsilon\cdot 𝟙(\tau\geq\nu_{th}))}} \\ = \frac{\mathrm{exp}(\epsilon\cdot 𝟙(\nu \geq \nu_{th}))}{ \mathrm{exp}(\epsilon\cdot 𝟙(\nu^\prime \geq \nu_{th}))} \leq \frac{\mathrm{exp}(\epsilon\cdot 1)}{\mathrm{exp}(\epsilon\cdot 0)} = \mathrm{exp}(\epsilon) \]
证明EM-MDS算法满足\(\epsilon\)-LDP保证。
值得注意的是,计算 (3)需要先确定Top-K维度数的阈值\(\nu_{th}\)。为此,我们首先推导在给定阈值\(\nu_{th}\)时,任意一组输出维度集合\(J\)包含的Top-K维度的概率分布和期望:
\[ \mathrm{Pr}(\nu=\tau|\nu_{th})= \begin{cases} \omega_{\tau} / \Omega \quad \quad \quad \quad \quad \mathrm{ } &if \quad \tau\in[0,\nu_{th}) \\ \omega_{\tau}\cdot\mathrm{exp}(\epsilon) / \Omega \quad \quad &if \quad \tau\in[\nu_{th},h] \end{cases} \tag{4}\label{discrete-prob} \]
\[ \mathbb{E}[\nu|\nu_{th}] = \sum_{\tau=0}^{\tau=h}\tau\cdot \mathrm{Pr}(\nu=\tau|\nu_{th}) \tag{5}\label{expectation} \]
这里,\(\Omega\)为 (3)中\(\mathcal{P}\)的分母部分。直觉上,\(\mathbb{E}[\nu|\nu_{th}]\)越高,随机采样的\(J\)集合中包含的Top-K维度的概率就越大,从而模型效用就越好。因此,我们将\(\mathbb{E}[\nu|\nu_{th}]\)最高时的阈值确定为目标阈值\(\nu_{th}^{\*}\),即:
\[ \nu_{th}^{\*} = \underset{\nu_{th}\in[1, h]}{\operatorname{argmax}} \mathbb{E}[\nu|\nu_{th}] \tag{6}\label{threshold} \]
最后,我们在 图13.4.1中描述了SignDS算法的详细流程。给定本地模型更新\(\Delta\),我们首先随机采样一个符号值\(s\)并构建Top-K集合\(S_k\)。接下来,我们根据 (6)确定阈值\(\nu_{th}^{\*}\)并遵循 (3)定义的概率选择输出集合\(J\)。考虑到输出域\(\mathcal{J}\)包含\(\binom{d}{k}\)个可能的维度集合,以一定概率直接从\(\mathcal{J}\)中随机采样一个组合需要很大的计算成本和空间成本。因此,我们采用了逆采样算法以提升计算效率。具体来说,我们首先从标准均匀分布中采样一个随机值\(\beta\sim U(0,1)\),并根据 (4)中\(p(\nu=\tau|\nu_{th})\)的累计概率分布\(CDF_{\tau}\)确定输出维度集合中包含的Top-K维度数\(\nu\)。最后,我们从Top-K集合\(S_k\)中随机选取\(\nu\)个维度,从非Top-K集合中随机采样\(h-\nu\)个维度,以构建最终的输出维度集合\(J\)。

图13.4.1 SignDS工作流程
参考文献
- Jiang, Xue and Zhou, Xuebing and Grossklags, Jens. SignDS-FL: Local Differentially Private Federated Learning with Sign-based Dimension Selection. ACM Transactions on Intelligent Systems and Technology (TIST). 2022. ↩
- McSherry, Frank and Talwar, Kunal. Mechanism design via differential privacy. IEEE Symposium on Foundations of Computer Science. 2007. ↩
- Dwork, Cynthia and Roth, Aaron. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science. 2014. ↩
展望
展望
为了实现联邦学习的大规模商用,我们仍然需要做许多的研究工作。比如我们无法查看联邦学习的分布式化的数据,那就很难选择模型的超参数以及设定优化器,只能采用一些基于模拟的方案来调测模型;比如用于移动设备时,单用户的标签数据很少,甚至无法获取数据的标签信息,联邦学习如何用于无监督学习;比如由于参与方的数据分布不一致,训练同一个全局模型,很难评价模型对于每个参与方的好坏;比如数据一直是公司的核心资产,不同的公司一直在致力于收集数据和创造数据孤岛,如何有效地激励公司或者机构参与联邦学习的系统中来。下面将介绍一些MindSpore Federated在进行的一些尝试和业界的相关工作。
异构场景下的联邦学习
之前探讨的横向联邦学习和纵向联邦学习都是让不同的参与方共同建立一个共享的机器学习模型。然而,企业级联邦学习框架往往需要适应多种异构场景,如数据异构(不同客户端数据规模以及分布不一致),设备异构(不同客户端设备计算能力,通信效率不一致),以及模型异构(不同本地客户端模型学到的特征不一致)。
比较主流的两种联邦学习异构场景下的工作:
1)对异构数据具有高度鲁棒性的本地模型个性化联邦学习策略:
联邦学习训练的是一个全局模型,基于所有数据得到一个全局最优解,但是不同参与方的数据量和分布都是不同的,很多场景下全局模型无法在把握整体的同时又照顾到这种差异。当某一方的数据和整体偏离比较大时,联邦学习的效果确实有可能不如本地训练的效果。那么如何在所有参与方总体的收益最大化的同时,让个体的收益也能够最大化,这就是个性化联邦学习。
个性化联邦学习并不要求所有参与方最终使用的模型必须是一样的,比如允许每个参与方在参与联邦学习之后,根据自己的数据对模型进行微调,从而生成本方独特的个性化模型。在进行个性化微调之后,往往模型在本地测试集上的效果会更好。在这种方式下,不同参与方的模型结构是一样的,但是模型参数会有所不同。还有一些方案,是让所有的参与方拥有同样的特征提取层,但是任务分类层不同。还有的思路是将知识蒸馏引入联邦学习中,将联邦学习的全局模型作为教师模型,将个性化模型作为学生模型,可以缓解个性化过程中的过拟合问题。
2)对于异构模型进行模型聚合的策略研究:
一般在FedAvg的联邦聚合范式下,本地迭代训练次数越少、聚合地越频繁,模型收敛精度会越好,尤其是在不同参与客户端的数据是非IID情况下。但是聚合会带来通信成本开销,联邦学习存在通信成本与模型精度的Trade-Off。因此很多研究者聚焦于如何设计自适应聚合方案,要求在给定训练时间开销的前提下,找到本地更新和全局通信之间的最佳平衡,令全局模型的泛化误差最小。
通信效率提升
在联邦学习流程中,每一个全局训练轮次里,每个参与方都需要给服务端发送完整的参数。然后服务端将聚合后的参数下发。现代的深度学习网络动辄有数百万甚至更大量级的参数,如此多的参数传输将会带来巨大的通信开销。为了降低通信开销,MindSpore Federated采取了一些改善通信效率的方法:
1)智能调频策略:通过改变全局模型聚合的轮次来提高联邦学习效率,减少训练任务达到收敛的通信开销。一种直觉是在联邦学习流程的初期,不同参与方的参数变化较为一致,因此设置较小的聚合频率,可以减少通信成本;在联邦学习流程的后期,不同参与方的参数变化较为不一致,因此设置较大的聚合频率,可以使得模型快速收敛。
2)通信压缩方案:对权重差进行量化以及稀疏化操作,即每次通信仅上传一小部分量化后的权重差值。之所以选择权重差做量化和稀疏,是因为它比权重值的分布更易拟合,而且稀疏性更高。量化就是将float32的数据类型映射到int8甚至更低比特表示的数值上,一方面降低存储和通信开销,另一方面可以更好地采用一些压缩编码方式进行传输(如哈夫曼编码、有限状态熵编码等)。比较常用的稀疏化方法有Top-K稀疏,即按梯度的绝对值从小到大排序,每轮只上传前k个参数。通信压缩方案一般是精度有损的,如何选取合适的k是一个有挑战性的问题。
联邦生态
在前面的章节中,我们介绍了面向隐私保护的联邦学习领域的一些技术与实践,然而随着探索地更加深入,联邦学习领域也变得更具包容性,它涵盖了机器学习、模型压缩部署、信息安全、加密算法、博弈论等等。随着越来越多的公司、高校和机构参与进来,现在的联邦学习已经不仅仅是一种技术解决方案,还是一个隐私保护的生态系统,比如不同的参与方希望以可持续的方式加入联邦学习流程,如何设计激励机制以确保利润可以相对公平地被各参与方共享,同时对于恶意的实施攻击或者破坏行为的参与方进行有效遏制。
另外,随着用户数据隐私保护和合理使用的法律法规越来越多的被推出,制定联邦学习的技术标准显得愈加重要,这一标准能够在法律监管部门和技术开发人员之间建立一座桥梁,让企业知道采用何种技术,能够在合乎法规的同时更好地进行信息的共享。
2020年底正式出版推行了由IEEE 标准委员会通过的联邦学习国际标准(IEEE P3652.1),该标准旨在提供一个搭建联邦学习的体系架构和应用的指导方针,主要内容包括:联邦学习的描述和定义、场景需求分类和安全测评、联邦学习个性指标的评估如何量化、联合管控的需求。这也是国际上首个针对人工智能协同技术框架订立的标准,标志着联邦学习开启大规模工业化应用的新篇章。
小结
小结
在这一章,我们简单介绍了联邦学习的背景、系统架构、联邦平均算法、隐私加密算法以及实际部署时的挑战。联邦学习是一个新起步的人工智能算法,可以在“数据保护”与“数据孤岛”这两大约束条件下,建立有效的机器学习模型。此外,由于联邦学习场景的特殊性(端侧数据不上传、安全隐私要求高和数据非独立同分布等特点),使得系统和算法的开发难度更高:如何平衡计算和通讯的开销,如何保证模型不会泄露隐私,算法如何在非独立同分布场景下收敛。这些难点都需要开发人员对实际的联邦学习场景有更深刻的认识。
强化学习系统
在本章中,我们介绍深度学习的一个重要分支——强化学习及其在系统方面的知识。本章的学习目标包括:
-
掌握强化学习基本知识。
-
掌握单节点和多节点强化学习系统设计思路。
-
掌握多智能体强化学习基础知识及系统设计简介。
强化学习介绍
强化学习介绍
近年来,强化学习作为机器学习的一个分支受到越来越多的关注。2013 年 DeepMind 公司的研究人员提出了深度 Q 学习 [1](Deep Q-learning),成功让 AI 从图像中学习玩电子游戏。自此以后,以 DeepMind 为首的科研机构推出了像 AlphaGo 围棋 AI 这类的引人瞩目的强化学习成果,并在 2016 年与世界顶级围棋高手李世石的对战中取得了胜利。自那以后,强化学习领域连续取得了一系列成就,如星际争霸游戏智能体 AlphaStar、Dota 2 游戏智能体 OpenAI Five、多人零和博弈德州扑克的 Pluribus、机器狗运动控制算法等。在这一系列科研成就的背后,是整个强化学习领域算法在这些年内快速迭代进步的结果,基于模拟器产生的大量数据使得对数据“饥饿”(Data Hungry)的深度神经网络能够表现出很好的拟合效果,从而将强化学习算法的能力充分发挥出来,在以上领域中达到或者超过人类专家的学习表现。目前,强化学习已经从电子游戏逐步走向更广阔的应用场景,如机器人控制、机械手灵巧操作、能源系统调度、网络负载分配、股票期货交易等一系列更加现实和富有意义的领域,对传统控制方法和启发式决策理论发起冲击。
图14.1.1 强化学习框架
强化学习的核心是不断地与环境交互来优化策略从而提升奖励的过程,主要表现为基于某个**状态**(State)下的**动作**(Action)的选择。进行这一决策的对象我们常称为**智能体**(Agent),而这一决策的影响将在**环境**(Environment)中体现。更具体地,不同的决策会影响环境的**状态转移**(State Transition)和**奖励**(Reward)。以上状态转移是环境从当前状态转移到下一状态的函数,它可以是确定性也可以是随机性的。奖励是环境对智能体动作的反馈,通常是一个标量。以上过程可以抽象为 [图14.1.1](#ch12/ch12-rl-framework)所示,这是文献中最常见的强化学习的模型描述。举例来说,当人在玩某个电子游戏的时候,需要逐渐熟悉游戏的操作以取得更好的游戏结果,那么人从刚接触到这个游戏到逐步掌握游戏技巧的这个过程为一个类似于强化学习的过程。该游戏从开始后的任一时刻,会处于一个特定的状态,而人通过观察这个状态会获得一个观察量(Observation)(如观察游戏机显示屏的图像),并基于这个观察量做出一个操作动作(如发射子弹),这一动作将改变这个游戏下一时刻的状态,使其转移到下一个状态(如把怪物打败了),并且玩家可以知道当前动作的效果(如产生了一个正或负的分数,怪物打败了则获得正分数)。这时玩家再基于下一个状态的观察量做出新的动作选择,周而复始,直到游戏结束。通过反复的操作和观察,人能够逐步掌握这个游戏的技巧,一个强化学习智能体也是如此。
这里注意,有几个比较关键的问题:一是观察量未必等于状态,而通常观察量是状态的函数,从状态到观察量的映射可能有一定的信息损失。对于观察量等于状态或者根据观察量能够完全恢复环境状态的情况,我们称为完全可观测(Fully Observable),否则我们称为部分可观测(Partially Observable)环境;二是玩家的每个动作未必会产生立即反馈,某个动作可能在许多步之后才产生效果,强化学习模型允许这种延迟反馈的存在;三是这种反馈对人的学习过程而言未必是个数字,但是我们对强化学习智能体所得到的反馈进行数学抽象,将其转变为一个数字,称为奖励值。奖励值可以是状态的函数,也可以是状态和动作的函数,依具体问题而定。奖励值的存在是强化学习问题的一个基本假设,也是现有强化学习与监督式学习的一个主要区别
强化学习的决策过程通常由一个马尔可夫决策过程(Markov Decision Process,MDP)(马尔可夫决策过程即一个后续状态只依赖当前状态和动作而不依赖于历史状态的函数)描述,可以用一个数组\((\mathcal{S}, \mathcal{A}, R, \mathcal{T}, \gamma)\)来表示。\(\mathcal{S}\)和\(\mathcal{A}\)分别是状态空间和动作空间,\(R\)是奖励函数,\(R(s,a)\): \(\mathcal{S}\times \mathcal{A}\rightarrow \mathbb{R}\)为对于当前状态\(s\in\mathcal{S}\)和当前动作\(a\in\mathcal{A}\)的奖励值。从当前状态和动作到下一个状态的状态转移概率定义为\(\mathcal{T}(s^\prime|s,a)\): \(\mathcal{S}\times\mathcal{A}\times\mathcal{S}\rightarrow \mathbb{R}_+\)。\(\gamma\in(0,1)\)是奖励折扣因子(折扣因子可以乘到每个后续奖励值上,从而使无穷长序列有有限的奖励值之和)。强化学习的目标是最大化智能体的期望累计奖励值\(\mathbb{E}[\sum_t \gamma^t r_t]\)。
马尔可夫决策过程中的马尔可夫性质由以下定义
\[ \mathcal{T}(s_{t+1}|s_t) = \mathcal{T}(s_{t+1}|s_0, s_1, s_2, \dots, s_t) \]
即当前状态转移只依赖于上一时刻状态,而不依赖于整个历史。这里的状态转移函数\(\mathcal{T}\)中省略了动作\(a\),马尔可夫性质是环境转移过程的属性,其独立于产生动作的决策过程。
基于马尔可夫性质,可以进一步推导出在某一时刻最优策略不依赖于整个决策历史,而只依赖于当前最新状态的结论。这一结论在强化学习算法设计中有着重要意义,它简化了最优策略的求解过程。
参考文献
- Mnih, Volodymyr and Kavukcuoglu, Koray and Silver, David and Graves, Alex and Antonoglou, Ioannis and Wierstra, Daan and Riedmiller, Martin. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602. 2013. ↩
单节点强化学习系统
单节点强化学习系统
前面介绍了强化学习的基本知识,这里我们介绍常见的单智能体强化学习系统中较为简单的一类,即单节点强化学习系统,这里的节点是指一个用于模型更新的计算单元。我们按照是否对模型更新的过程做并行化处理,将强化学习系统分为单节点和分布式强化学习系统。其中,单节点强化学习系统可以理解为只实例化一个类对象作为智能体,与环境交互进行采样和利用所采得的样本进行更新的过程分别视为这个类内的不同函数。除此之外的更为复杂的强化学习框架都可视为分布式强化学习系统。
分布式强化学习系统的具体形式有很多,系统的形式也往往依赖于所实现的算法。从最简单的情况考虑,假设我们仍在同一个计算单元上实现算法,但是将强化学习的采样过程和更新过程实现为两个并行的进程,甚至各自实现为多个进程,以满足不同计算资源间的平衡。这时就需要进程间通信来协调采样和更新过程,这是一个最基础的分布式强化学习框架。更为复杂的情况是,整个算法的运行在多个计算设备上进行(如一个多机的计算集群),智能体的函数可能需要跨机跨进程间的通信来实现。对于多智能体系统,还需要同时对多个智能体的模型进行更新,则需要更为复杂的计算系统设计。我们将逐步介绍这些不同的系统内的实现机制。
我们先对单节点强化学习系统进行介绍。在这里,我们以RLzoo [1]为例,讲解一个单节点强化学习系统构建所需要的基本模块。如 图14.2.1所示,是RLzoo算法库中采用的一个典型的单节点强化学习系统,它包括几个基本的组成部分:神经网络、适配器、策略网络和价值网络、环境实例、模型学习器、经验回放缓存(Experience Replay Buffer)等。
我们先对前三个,神经网络、适配器、策略网络和价值网络进行介绍。神经网络即一般深度学习中的神经网络,用于实现基于数据的函数拟合,我们在图中简单列出常见的三类神经网络:全连接网络,卷积网络和循环网络。策略网络和价值网络是一般深度强化学习的常见组成部分,策略网络即一个由深度神经网络参数化的策略表示,而价值网络为神经网络表示的状态价值(State-Value)或状态-动作价值(State-Action Value)函数。这里我们不妨称前三类神经网络为一般神经网络,策略网络和价值网络为强化学习特定网络,前者往往是后者的重要组成部分。在RLzoo中,适配器则是为实现强化学习特定网络而选配一般神经网络的功能模块。首先,根据不同的观察量类型,强化学习智能体所用的神经网络头部会有不同的结构,这一选择可以由一个基于观察量的适配器来实现;其次,根据所采用的强化学习算法类型,相应的策略网络尾部需要有不同的输出类型,包括确定性策略和随机性策略,RLzoo 中使用一个策略适配器来进行选择;最后,根据不同的动作输出,如离散型、连续型、类别型等,需要使用一个动作适配器来选择。图14.2.1中我们统称这三个不类型的适配器为适配器。
介绍完这些,我们已经有了可用的策略网络和价值网络,这构成了强化学习智能体核心学习模块。除此之外,还需要一个学习器(Learner)来更新这些学习模块,更新的规则就是强化学习算法给出的损失函数。而要想实现学习模块的更新,最重要的是输入的学习数据,即智能体跟环境交互过程中所采集的样本。对于离线(Off-Policy)强化学习,这些样本通常被存储于一个称为经验回放缓存的地方,学习器在需要更新模型时从该缓存中采得一些样本来进行更新。这里说到的离线强化学习是强化学习算法中的一类,强化学习算法可以分为在线(On-Policy)强化学习和离线(Off-Policy)强化学习两类,按照某个特定判据。这个判据是,用于更新的模型和用于采样的模型是否为同一个,如果是,则称在线强化学习算法,否则为离线强化学习算法。因而,离线强化学习通常允许与环境交互所采集的样本被存储于一个较大的缓存内,从而允许在许久之后再从这个缓存中抽取样本对模型进行更新。而对于在线强化学习,这个“缓存”有时其实也是存在的,只不过它所存储的是非常近期内采集的数据,从而被更新模型和用于采样的模型可以近似认为是同一个。从而,这里我们简单表示 RLzoo 的强化学习系统统一包括这个经验回放缓存模块。有了以上策略和价值网络、经验回放缓存、适配器、学习器,我们就得到了 RLzoo 中一个单节点的强化学习智能体,将这个智能体与环境实例交互,并采集数据进行模型更新,我们就得到了一个完整的单节点强化学习系统。这里的环境实例化我们允许多个环境并行采样。
图14.2.1 RLzoo算法库中使用的强化学习系统
近来研究人员发现,强化学习算法领域的发展瓶颈,可能不仅在于算法本身,而在于让智能体在其中采集数据的模拟器的模拟速度。Isaac Gym [2]是Nvidia公司于2021年推出的基于GPU(Graphics Processing Unit)的模拟引擎,在单GPU上实现2-3倍于之前基于CPU(Central Processing Unit)的模拟器的运行速度。关于 GPU上运行加速我们已经在章节 5 中有所介绍。之所以 GPU 模拟能够对强化学习任务实现显著的加 速效果,除了 GPU 本身多核心的并行运算能力之外,还在于这省却了 CPU 与 GPU 之间的数据传输和通信时间。传统的强化学习环境,如 OpenAI Gym(这是一个常用的强化学习基准测试环境)等,都是基于 CPU 进行的模拟计算,而深度学习方法的神经网络训练通常是在 GPU 或TPU(Tensor Processing Unit) 上进行的。从智能体与 CPU 上实例化的模拟环境交互过程所收集的数据样本,通常先暂时以 CPU 的数据格式存储,在使用的时候被转移到 GPU 上成为具有 GPU 数据类型的数据(如使用 PyTorch 时可通过tensor.to(device)的函数实现,只需将device设为“cuda”即可将一个类型为torch.Tensor的tensor转移到GPU上),然后来进行模型训练。同时,由于模型参数是以 GPU 上数据的类型存储的,调用模型进行前向传递的过程中也需要先将输入数据从 CPU 转移到 GPU 上,并且可能需要将模型输出的 GPU 数据再转移回 CPU 类型。这一系列冗余的数据转换操作都会显著增长模型学习的时间,并且也增加了算法实际使用过程中的工程量。Isaac Gym 模拟器的设计从模拟器下层运行硬件上解决了这一困难,由于模拟器和模型双双实现在 GPU 上,他们之间的数据通信不再需要通过 CPU 来实现,从而绕过了 CPU 与 GPU 数据双向传输这一问题,实现了对强化学习任务中模拟过程的特定加速。
参考文献
- Ding, Zihan and Yu, Tianyang and Huang, Yanhua and Zhang, Hongming and Li, Guo and Guo, Quancheng and Mai, Luo and Dong, Hao. Efficient Reinforcement Learning Development with RLzoo. arXiv preprint arXiv:2009.08644. 2020. ↩
- Makoviychuk, Viktor and Wawrzyniak, Lukasz and Guo, Yunrong and Lu, Michelle and Storey, Kier and Macklin, Miles and Hoeller, David and Rudin, Nikita and Allshire, Arthur and Handa, Ankur and others. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning. arXiv preprint arXiv:2108.10470. 2021. ↩
多智能体强化学习
多智能体强化学习
以上所讲述的强化学习内容都为单智能体强化学习,而在近来的强化学习研究中,多智能体强化学习越来越受到研究人员关注。回想在本小节初介绍的单智能体强化学习框架 图14.1.1,其中我们只有单个智能体产生的单个动作对环境产生影响,环境也返回单个奖励值给智能体。这里我们把单智能体强化学习扩展到多智能体强化学习,可以得到至少两种可能的多智能体强化学习框架,如 ch12/ch12-marl所示。 ch12/ch12-marl(a)为多智能体同时执行动作的情况,他们相互之间观察不到彼此的动作,他们的动作一同对环境产生影响,并各自接受自己动作所产生的奖励。 ch12/ch12-marl(b)为多智能体顺序执行动作的情况,后续智能体可能观察到前序智能体的动作,他们的动作一同对环境产生影响,并接受到各自的奖励值或共同的奖励值。除此之外,还有许多其他可能的多智能体框架,如更复杂的智能体间观察机制、智能体间通讯机制、多智能体合作与竞争等等。同时,这里假设多个智能体对环境的观察量都为环境的状态,这是最简单的一种,也是现实中最不可能出现的一种,实际情况下的多智能体往往对环境有各自不同的观察量。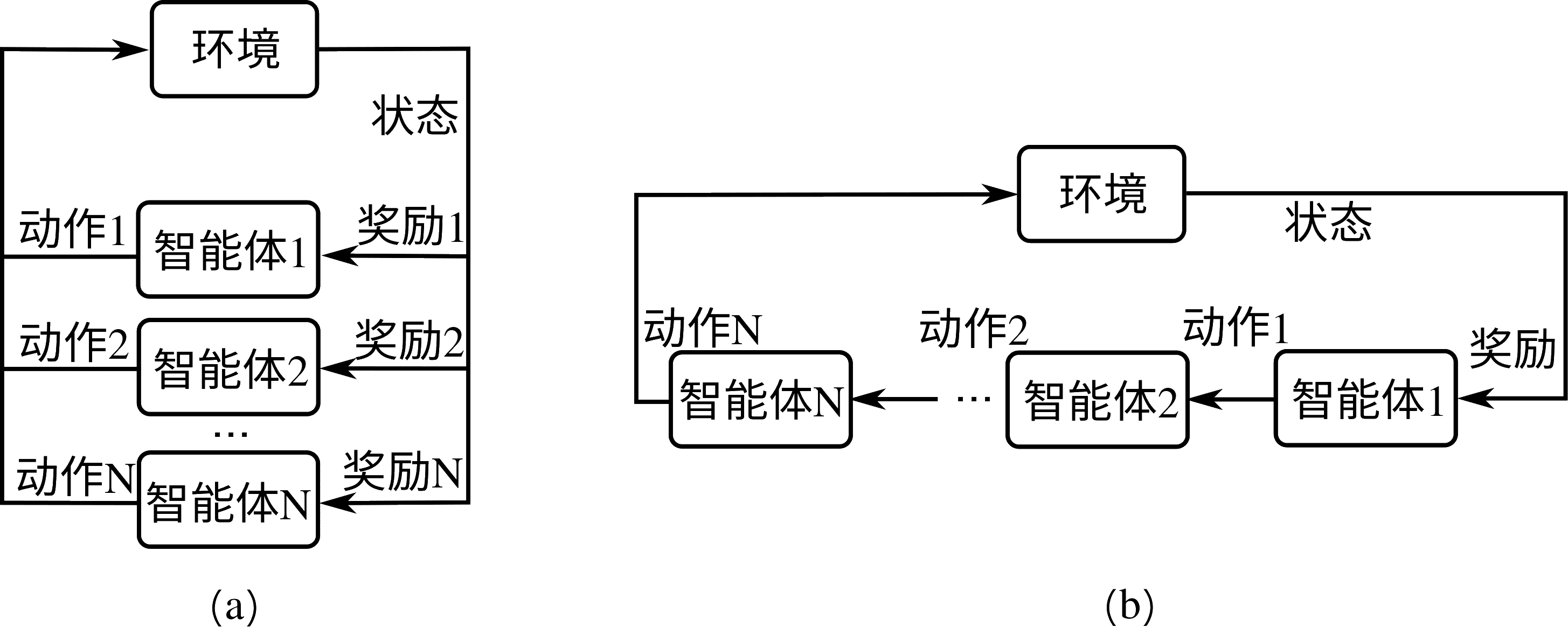
这里我们可以根据前面对单智能体强化学习过程的马尔可夫决策过程描述,给出多智能体强化学习的马尔可夫决策过程,它可以用一个数组\((\mathcal{S}, N, \boldsymbol{\mathcal{A}}, \mathbf{R}, \mathcal{T}, \gamma)\)来表示。\(N\)是智能体个数,\(\mathcal{S}\)和\(\boldsymbol{\mathcal{A}}=(\mathcal{A}_1, \mathcal{A}_2, …, \mathcal{A}_N)\)分别是环境状态空间和多智能体动作空间,其中\(A_i\)是第\(i\)个智能体的动作空间,\(\mathbf{R}=(R_1, R_2, …, R_N)\)是多智能体奖励函数,\(\mathbf{R}(s,\mathbf{a})\): \(\mathcal{S}\times \boldsymbol{\mathcal{A}}\rightarrow \mathbb{R}^N\)为对于当前状态\(s\in\mathcal{S}\)和当前多智能体动作\(\mathbf{a}\in\boldsymbol{\mathcal{A}}\)的奖励向量值,其中\(R_i\)是对第\(i\)个智能体的奖励值。从当前状态和动作到下一个状态的状态转移概率定义为\(\mathcal{T}(s^\prime|s,\mathbf{a})\): \(\mathcal{S}\times\boldsymbol{\mathcal{A}}\times\mathcal{S}\rightarrow \mathbb{R}_+\)。\(\gamma\in(0,1)\)是奖励折扣因子(假设多个智能体采用相同的奖励折扣因子)。不同于单智能体强化学习,多智能体强化学习的目标除了常见的最大化每个智能体各自的期望累计奖励值\(\mathbb{E}[\sum_t \gamma^t r^i_t], i\in[N]\)之外,还有许多其他可能的学习目标,如达到纳什均衡、最大化团队奖励等等。
我们考虑一个大家都熟悉的游戏, 剪刀-石头-布,考虑两个玩家玩这个游戏的输赢情况,我们知道有这样的输赢关系:剪刀<石头<布<剪刀…这里的“<”即前一个纯策略被后一个纯策略完全压制,我们给予奖励值-1、+1到这两个玩家,当他们选择相同的纯策略时,奖励值均为0。于是我们得到一个奖励值表如 tab_ch12_ch12_marl所示,横轴为玩家1,纵轴为玩家2,表内的数组为玩家1和玩家2各自在相应动作下得到的奖励值。
由于这个矩阵的反对称性,这个问题的纳什均衡策略对两个玩家相同,均为\((\frac{1}{3}, \frac{1}{3}, \frac{1}{3})\)的策略分布,即有各\(\frac{1}{3}\)的概率出剪刀、石头或布。如果我们把得到这个纳什均衡策略作为多智能体学习的目标,那么我们可以简单分析得到这个均衡策略无法通过简单的单智能体算法得到。考虑我们随机初始化两个玩家为任意两个纯策略,比如玩家1出剪刀,玩家2出石头。这时假设玩家2策略固定,可以把玩家2看做固定环境的一部分,于是可以使用任意单智能体强化学习算法对玩家1进行训练,使其最大化自己的奖励值。于是,玩家1会收敛到布的纯策略。这时再把玩家1固定,训练玩家2,玩家2又收敛到剪刀的纯策略。于是循环往复,整个训练过程始终无法收敛,玩家1和2各自在3个策略中循环却无法得到正确的纳什均衡策略。

图14.3.1 自学习算法示意图。
我们在上面这个例子中采用的学习方法其实是多智能体强化学习中最基础的一种,叫自学习(Selfplay),如 图14.3.1所示。自学习的方法即固定当前玩家 1 的策略,按照单智能体优化的方法最大化一侧智能体的表现,所得策略称为最佳反应策略(Best Response Strategy)。之后再将这一最佳反应策略作为玩家 2 的固定策略,再来优化另一边的智能体策略,如此循环。我们可以看到自学习在特定的任务设置下可能无法收敛到我们想要的最终目标。正是由于多智能体学习过程中有类似循环结构的出现,我们需要更复杂的训练方法,和专门针对多智能体的学习方式来达到我们想要的目标。
一般来讲,多智能体强化学习是比单智能体强化学习更复杂的一类,对于自学习的方法而言,单智能体强化学习的过程可以看做一个多智能体强化学习的子任务。从前面这一小游戏的角度来理解,当玩家 1 策略固定时,玩家 1 加游戏环境构成玩家 2 的实际学习环境,由于这个环境是固定的,玩家 2 可以通过单智能体强化学习来达到自身奖励值最大化;这时再固定玩家 2 的策略,玩家 1 又可以进行单智能体强化学习…… 这样,单智能体强化学习是多智能体任务的子任务。如 图14.3.2,其他算法如虚构自学习(Fictitious Self-play),需要在每个单智能体强化学习的步骤中,对对手历史策略的平均策略求得最优应对策略,而对手的训练也是如此,进行循环,能够在上面剪刀-石头-布一类的游戏中保证收敛到纳什均衡策略。
图14.3.2 虚构自学习算法示意图。
多智能体强化学习系统
多智能体强化学习系统
上述的简单例子只是为了帮助读者理解强化学习在多智能体问题里的角色,而如今前沿的多智能体强化学习算法已经能够解决相当大规模的复杂多智能体问题,如星际争霸(StarCraft II)、Dota 2等游戏,已相继被DeepMind、OpenAI等公司所研究的智能体AlphaStar [1]和OpenAI Five [2]攻克,达到超越人类顶级玩家的水平。国内公司如腾讯、启元世界等也提出了星际争霸游戏的多智能体强化学习解决方案TStarBot-X [3]和SCC [4]。对于这类高度复杂的游戏环境,整个训练过程对分布式计算系统的要求更高,而整个训练过程可能需要分为多个阶段。以 AlphaStar 为例,它训练的智能体采用了监督学习与强化学习结合的方式。在训练早期,往往先采用大量的人类专业玩家标定数据进行有监督的学习,从而使智能体快速获得较好的能力,随后,训练会切换到强化学习过程,使用前面介绍的虚构自学习的算法进行训练,即自我博弈。为了得到一个表现最好的智能体,算法需要充分探索整个策略空间,从而在训练中不止对一个策略进行训练,而是对一个策略集群(League)进行训练,并通过类似演化算法的方式对策略集群进行筛选,得到大量策略中表现最好的策略。如 图14.4.1所示,在训练过程中每个智能体往往需要 和其他智能体以及剥削者(Exploiter)进行博弈,剥削者是专门针对某一个智能体策略的最佳对手策略,与之对抗可以提高策略自身的防剥削能力。通过对大量智能体策略进行训练并筛选的这类方法称为集群式训练(Population-based Training/League Training),是一种通过分布式训练提高策略种群多样性进而提升模型表现的方式。可见,在实践中这类方法自然需要分布式系统支持,来实现多个智能体的训练和相互博弈,这很好地体现了多智能体强化学习对分布式计算的依赖性。

图14.4.1 集群式多智能体强化学习训练示意图
我们将对构建多智能体强化学习系统中的困难分为以下几点进行讨论:
-
智能体个数带来的复杂度:从单智能体系统到多智能体系统最直接的变化,就是智能体个数从1变为大于1个。对于一个各个智能体独立的\(N\)智能体系统而言,这种变化带来的策略空间表示复杂度是指数增加的,即\(\tilde{O}(e^N)\)。举个简单的例子,对于一个离散空间的单智能体系统,假设其状态空间大小为\(S\), 动作空间大小为\(A\),游戏步长为\(H\),那么这个离散策略空间的大小为\(O(HSA)\);而直接将该游戏扩展为\(N\)玩家游戏后,在最一般的情况下,即所有玩家有对称的动作空间动作空间大小为\(A\)且不共享任何结构信息,所有玩家策略的联合分布空间大小为\(O(HSA^N)\)。这是因为每个独立玩家的策略空间构成联合策略空间是乘积关系\(\mathcal{A}=\mathcal{A}_1\times\dots\mathcal{A}_N\)。而这将直接导致算法搜索复杂度提升。
在这种情况下,原先的单智能体系统,需要扩展为对多智能体策略进行优化的系统,这意味着单智能体分布式系统内的每个并行化的模块现在需要相应扩展到多智能体系统中的每个智能体上。而在复杂的情况下,还需要考虑智能体之间通信过程、智能体之间的异质性等,甚至不同智能体可能需要采用不完全对称模型进行表示,以及采用不同的算法进行优化等等。
-
游戏类型带来的复杂度:从博弈论的角度,多智能系统所产生的游戏类型是复杂的。从最直接的分类角度,有竞争型、合作型、混合型。在竞争型游戏中,最典型的研究模型是二人零和博弈,如前一小节中提到的剪刀-石头-布的游戏。这类游戏中的纳什均衡策略一般为混合型策略,即无法通过单一纯策略达到均衡条件。纯策略纳什均衡存在于少数零和游戏中。合作型游戏即多个智能体需要通过合作来提升整体奖励。在这类问题研究中一般采用基于值分解的思路,将所有智能体得到的奖励值分配到单个智能体作为其奖励值。这一类的算法有VDN [5], COMA [6], QMIX [7]等。
在混合型游戏中,部分智能体之间为合作关系,部分智能体或智能体的集合间为竞争关系。一般的非零和博弈且非纯合作型游戏为混合型游戏,举个简单的例子如囚徒困境(Prisoner’s Dilemma), 其奖励值表如 tab_ch12_ch12_marl_prison所示。囚徒困境的两个玩家各有两个动作,沉默和背叛。可以用警察审查两名罪犯来理解,奖励值的绝对值即他们将被判处的年数。纯所有玩家的奖励值之和非常数,故其为非零和博弈型游戏。因此这一游戏不能被认为是纯竞争型或纯合作型游戏,因为当他们中的一方选择沉默一方选择背叛时,二者没有有效合作,而一方拿到了 0 的奖励,另一方为-3。而两者都选择沉默时是一种合作策略,各自拿到-1 的奖励值。尽管这一策略看起来优于其他策略,但是这并不是这个游戏的纳什均衡策略,因为纳什均衡策略假设玩家间策略需要单独制定,无法形成联合策略分布。这实际上切断了玩家间的信息沟通和潜在合作的可能。因此,囚徒困境的纳什均衡策略是两个玩家都选择背叛对方。 诸如此类的博弈论游戏类型,导致单智能体强化学习不能被直接用来优化多智能体系统中的各个智能体的策略。单智能体强化学习一般是找极值的过程,而多智能体系统求解纳什均衡策略往往是找极大-极小值即鞍点的过程,从优化的角度看这也是不同的。复杂的关系需要更普适的系统进行表达,这也对多智能体系统的构建提出了挑战。多智能体游戏类型也有许多其他的分类角度,如单轮进行的游戏、多轮进行的游戏、多智能体同时决策的、多智能体序贯决策等等,每一类不同的游戏都有相应不同的算法。而现有的多智能体系统往往针对单一类型游戏或者单一算法,缺少普适性多智能体强化学习系统,尤其是分布式的系统。
:囚徒困境奖励值
- 算法的异构:从前面介绍的几个简单的多智能体算法,如自学习、虚构自学习等可以看出,多智能体算法有时由许多轮单智能体强化学习过程组成。而对不同的游戏类型,算法的类型也不相同。比如,对合作型游戏,许多算法是基于功劳分配(Credit Assignment)的思想,如何将多个智能体获得的共同奖励合理分配给单个智能体是这类算法的核心。而这里面按照具体算法执行方式,也可以分为集成训练统一执行的(Centralized Training Centralized Execution)、集成训练分别执行的(Centralized Training Decentralized Execution)、分别训练并分别执行(Decentralized Training Decentralized Execution)的几类,来描述不同智能体训练过程和执行过程的统一性。对于竞争型游戏,往往采用各种计算纳什均衡的近似方法,如前面提到的虚构自学习、Double Oracle、Mirror Descent 等等,将获取单个最优策略的单智能体强化学习过程看做一个“动作”,而对这些“动作”组成的元问题上进行纳什均衡近似。现有的算法在类似问题上有很大的差异性,使得构建一个统一的多智能体强化学习系统比较困难。
- 学习方法组合:在前面提到的AlphaStar [1]等工作中,多智能体系统中优化得到一个好的策略往往不只需要强化学习算法,还需要其他学习方法如模仿学习等的辅助。比如从一些顶级人类玩家的游戏记录中形成有标签的训练样本,来预训练智能体。由于这些大规模游戏的复杂性,这往往是一个在训练前期快速提升智能体表现的有效方式。而对于整个学习系统而言,这就需要对不同学习范式进行结合,如合理地在模仿学习和强化学习之间进行切换等。这也使得大规模多智能体系统不单一是构建强化学习系统的问题,而需要许多其他学习机制和协调机制的配合实现。
如 图14.4.2所示,为一个分布式多智能体强化学习系统。图中的两个智能体可以类似扩展到多个智能体。每个智能体包含多个行动者(Actor)用于采样和学习者(Learner)用于更新模型,这些行动者和学习者可以并行处理来加速训练过程,具体方法可以参考单智能体分布式系统章节介绍的A3C和IMPALA架构。训练好的模型被统一存储和管理在模型存储器中,是否对各个智能体的模型统一存储取决于各个智能体是否对称——如果不对称,需要将模型分别存储。存储器中的模型可以被模型评估器用来打分,从而为下一步模型选择器做准备。模型选择器根据模型评估器或者元学习者(如PSRO算法 [8])以及均衡求解器等进行模型选择,并将选出的模型分发到各个智能体的行动者上。这一处理过程,我们称为联盟型管理(League-based Management)。对于与环境交互的部分,分布式系统可以通过一个推理服务器(Inference Server)对各个并行进程中的模型进行集中推理,将基于观察量(Observation)的动作(Action)发送给环境。环境部分也可以是并行的,对推理服务器传递来的动作进行并行处理后,返回观察量。推理服务器将采集到的交互轨迹发送给各个智能体进行模型训练。以上为一个分布式多智能体系统的例子,实际中根据不同的游戏类型和算法结构可能会有不同的设计。
图14.4.2 分布式多智能体强化学习系统
参考文献
- Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M and Mathieu, Michael and Dudzik, Andrew and Chung, Junyoung and Choi, David H and Powell, Richard and Ewalds, Timo and Georgiev, Petko and others. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature. 2019. ↩
- Berner, Christopher and Brockman, Greg and Chan, Brooke and Cheung, Vicki and D\kebiak, Przemys\law and Dennison, Christy and Farhi, David and Fischer, Quirin and Hashme, Shariq and Hesse, Chris and others. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680. 2019. ↩
- Han, Lei and Xiong, Jiechao and Sun, Peng and Sun, Xinghai and Fang, Meng and Guo, Qingwei and Chen, Qiaobo and Shi, Tengfei and Yu, Hongsheng and Wu, Xipeng and others. Tstarbot-x: An open-sourced and comprehensive study for efficient league training in starcraft ii full game. arXiv preprint arXiv:2011.13729. 2020. ↩
- Wang, Xiangjun and Song, Junxiao and Qi, Penghui and Peng, Peng and Tang, Zhenkun and Zhang, Wei and Li, Weimin and Pi, Xiongjun and He, Jujie and Gao, Chao and others. SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft II. International Conference on Machine Learning. 2021. ↩
- Sunehag, Peter and Lever, Guy and Gruslys, Audrunas and Czarnecki, Wojciech Marian and Zambaldi, Vinicius and Jaderberg, Max and Lanctot, Marc and Sonnerat, Nicolas and Leibo, Joel Z and Tuyls, Karl and others. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296. 2017. ↩
- Foerster, Jakob and Farquhar, Gregory and Afouras, Triantafyllos and Nardelli, Nantas and Whiteson, Shimon. Counterfactual multi-agent policy gradients. Proceedings of the AAAI conference on artificial intelligence. 2018. ↩
- Rashid, Tabish and Samvelyan, Mikayel and Schroeder, Christian and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. International Conference on Machine Learning. 2018. ↩
- Lanctot, Marc and Zambaldi, Vinicius and Gruslys, Audrunas and Lazaridou, Angeliki and Tuyls, Karl and Perolat, Julien and Silver, David and Graepel, Thore. A unified game-theoretic approach to multiagent reinforcement learning. Advances in neural information processing systems. 2017. ↩
小结
小结
在这一章,我们简单介绍了强化学习的基本概念,包括单智能体和多智能体强化学习算法、单节点和分布式强化学习系统等,给读者对强化学习问题的基本认识。当前,强化学习是一个快速发展的深度学习分支,许多实际问题都有可能通过强化学习算法的进一步发展得到解决。另一方面,由于强化学习问题设置的特殊性(如需要与环境交互进行采样等),也使得相应算法对计算系统的要求更高:如何更好地平衡样本采集和策略训练过程?如何均衡 CPU 和 GPU 等不同计算硬件的能力?如何在大规模分布式系统上有效部署强化学习智能体?都需要对计算机系统的设计和使用有更好的理解。
可解释性AI系统
近10年来,籍由算力与数据规模的性价比突破临界点,以深度神经网络为代表的联结主义模型架构及统计学习范式(以后简称深度学习)在特征表征能力上取得了跨越级别的突破,大大推动了人工智能的发展,在很多场景中达到令人难以置信的效果。比如:人脸识别准确率达到97%以上;谷歌智能语音助手回答正确率,在2019年的测试中达到92.9%。在这些典型场景下,深度学习在智能表现上的性能已经超过了普通人类(甚至专家),从而到了撬动技术更替的临界点。在过去几年间,在某些商业逻辑对技术友好,或者伦理法规暂时稀缺的领域,如安防、实时调度、流程优化、竞技博弈、信息流分发等,人工智能和深度学习取得了技术和商业上快速突破。
食髓知味,技术发展的甜头自然每个领域都不愿放过。而当对深度学习的商业化运用来到某些对技术敏感、与人的生存或安全关系紧密的领域,如自动驾驶、金融、医疗和司法等高风险应用场景时,原有的商业逻辑在进行技术更替的过程中就会遇到阻力,从而导致商业化变现速度的减缓甚至失败。究其原因,以上场景的商业逻辑及背后伦理法规的中枢之一是稳定的、可追踪的责任明晰与责任分发;而深度学习得到的模型是个黑盒,我们无法从模型的结构或权重中获取模型行为的任何信息,从而使这些场景下责任追踪和分发的中枢无法复用,导致人工智能在业务应用中遇到技术上和结构上的困难。此外,模型的可解释性问题也引起了国家层面的关注,相关机构对此推出了相关的政策和法规。
因此,从商业推广层面以及从法规层面,我们都需要打开黑盒模型,对模型进行解释,可解释AI正是解决该类问题的技术。
本章的学习目标包括:
-
掌握可解释AI的目标和应用场景
-
掌握常见的可解释AI方法类型及其对应的典型方法
-
思考可解释AI方法的未来发展
背景
背景
在人类历史上,技术进步、生产关系逻辑和伦理法规的发展是动态演进的。当一种新的技术在实验室获得突破后,其引发的价值产生方式的变化会依次对商品形态、生产关系等带来冲击。而同时当新技术带来的价值提升得到认可后,商业逻辑的组织形态在自发的调整过程中,也会对技术发展的路径、内容甚至速度提出诉求,并当诉求得到满足时适配以新型的伦理法规。在这样的相互作用中,技术系统与社会体系会共振完成演进,是谓技术革命。
近10年来,籍由算力与数据规模的性价比突破临界点,以深度神经网络为代表的联结主义模型架构及统计学习范式(以后简称深度学习)在特征表征能力上取得了跨越级别的突破,大大推动了人工智能的发展,在很多场景中达到令人难以置信的效果。比如:人脸识别准确率达到97%以上;谷歌智能语音助手回答正确率,在2019年的测试中达到92.9%。在这些典型场景下,深度学习在智能表现上的性能已经超过了普通人类(甚至专家),从而到了撬动技术更替的临界点。在过去几年间,在某些商业逻辑对技术友好,或者伦理法规暂时稀缺的领域,如安防、实时调度、流程优化、竞技博弈、信息流分发等,人工智能和深度学习取得了技术和商业上快速突破。
食髓知味,技术发展的甜头自然每个领域都不愿放过。而当对深度学习商业化运用来到某些对技术敏感、与人的生存或安全关系紧密的领域,如自动驾驶、金融、医疗和司法等高风险应用场景时,原有的商业逻辑在进行技术更替的过程中就会遇到阻力,从而导致商业化变现速度的减缓甚至失败。究其原因,以上场景的商业逻辑及背后伦理法规的中枢之一是稳定的、可追踪的责任明晰与责任分发;而深度学习得到的模型是个黑盒,我们无法从模型的结构或权重中获取模型行为的任何信息,从而使这些场景下责任追踪和分发的中枢无法复用,导致人工智能在业务应用中遇到技术上和结构上的困难。
举2个具体的例子:例1,在金融风控场景,通过深度学习模型识别出来小部分用户有欺诈嫌疑,但是业务部门不敢直接使用这个结果进行处理。因为人们难以理解结果是如何得到的,从而无法判断结果是否准确。而且该结果缺乏明确的依据,如果处理了,也无法向监管机构交代; 例2,在医疗领域,深度学习模型根据患者的检测数据,判断患者有肺结核,但是医生不知道诊断结果是怎么来的,不敢直接采用,而是根据自己的经验,仔细查看相关检测数据,然后给出自己的判断。从这2个例子可以看出,黑盒模型严重影响模型在实际场景的应用和推广。
此外,模型的可解释性问题也引起了国家层面的关注,相关机构对此推出了相关的政策和法规。
-
2017年7月,国务院印发《新一代人工智能发展规划》,首次涵盖可解释AI。
-
2021年3月,中国人民银行发布金融行业标准《人工智能算法金融应用评价规范》,对金融行业AI模型可解释性提出了明确要求。
-
2021年8月,网信办《互联网信息服务算法推荐管理规定》, 提出对互联网行业算法推荐可解释性的要求。
-
2021年9月,科技部发布《新一代人工智能伦理规范》。
因此,从商业推广层面以及从法规层面,我们都需要打开黑盒模型,对模型进行解释,可解释AI正是解决该类问题的技术。
可解释AI定义
按DARPA(美国国防部先进研究项目局)的描述,如 图15.1.1所示, 可解释AI的概念在于:区别于现有的AI系统,可解释AI系统可以解决用户面对黑盒模型时遇到的问题,使得用户知其然并知其所以然。
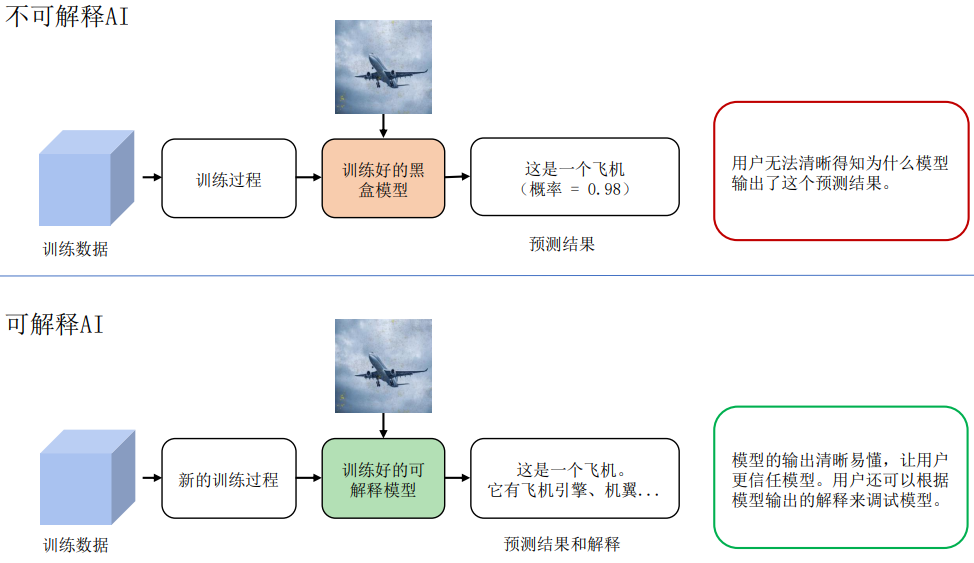
图15.1.1 可解释AI概念(图片来源于Broad Agency Announcement Explainable Artificial Intelligence (XAI) DARPA-BAA-16–53)
然而,不论是学术界还是工业界,对于可解释AI (eXplainable AI(XAI))都没有一个统一的定义。这里列举3种典型定义,供大家参考讨论:
-
可解释性就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。
-
可解释AI是为AI算法所做出的决策提供人类可读的以及可理解的解释。
-
可解释AI是确保人类可以轻松理解和信任人工智能代理做出的决策的一组方法。
我们根据自身的实践经验和理解,将可解释AI定义为:一套面向机器学习(主要是深度神经网络)的技术合集,包括可视化、数据挖掘、逻辑推理、知识图谱等,目的是通过此技术合集,使深度神经网络呈现一定的可理解性,以满足相关使用者对模型及应用服务产生的信息诉求(如因果或背景信息),从而为使用者对人工智能服务建立认知层面的信任。
可解释AI算法现状介绍
随着可解释AI概念的提出,可解释AI越来越受到学术界及工业界的关注,下图展示了人工智能领域顶级学术会议中可解释AI关键字的趋势。为了让读者更好的对现有可解释AI算法有一个整体认知,我们这里参考 [1]总结归纳了可解释AI的算法类型,如 图15.1.2所示。
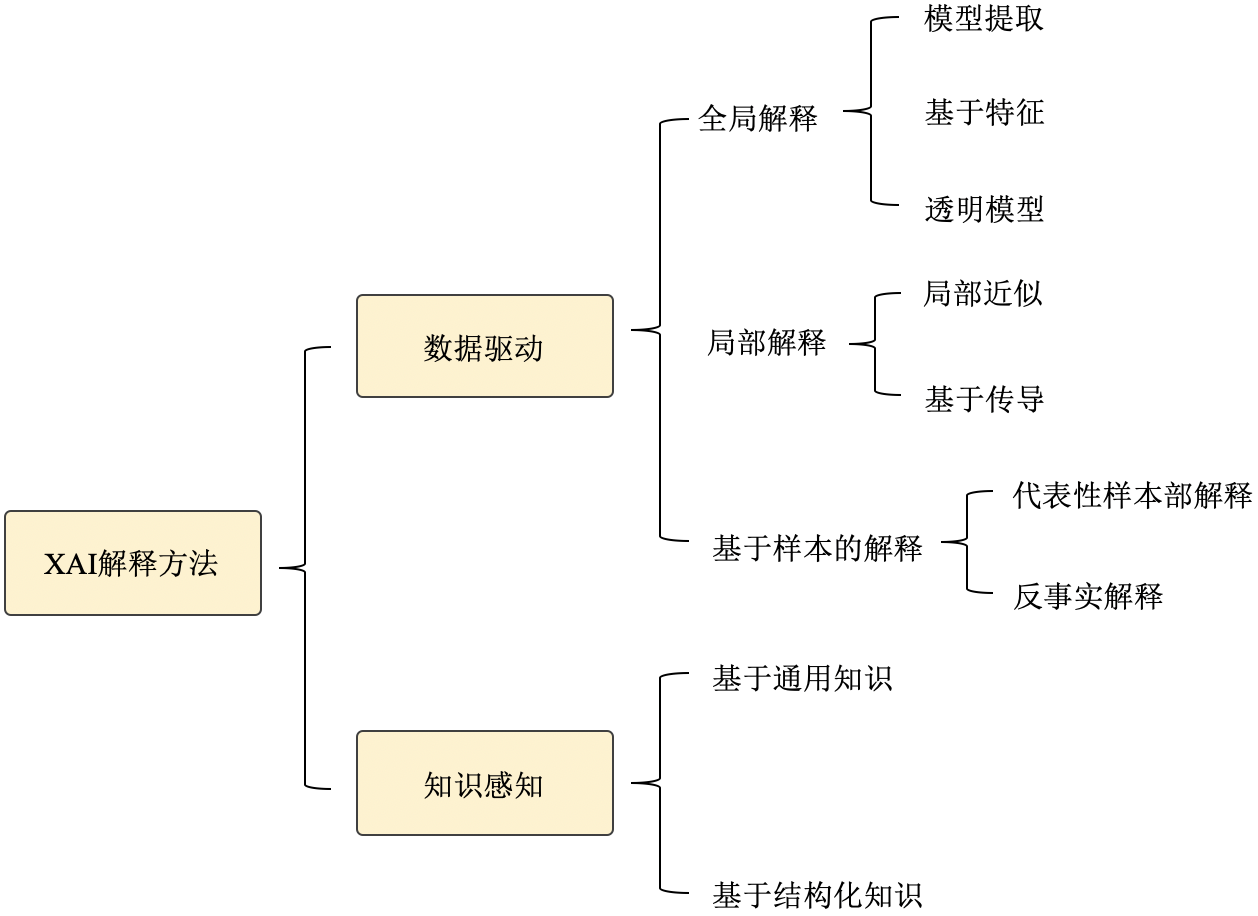
图15.1.2 可解释AI(XAI)算法分支
对模型进行解释有多种多样的方法,这里依据解释过程是否引入数据集以外的外部知识,将其分为数据驱动的解释方法和知识感知的解释方法。
数据驱动的解释
数据驱动的解释是指纯粹从数据本身生成解释的方法,而不需要先验知识等外部信息。为了提供解释,数据驱动的方法通常从选择数据集(具有全局或局部分布)开始。然后,将选定的数据集或其变体输入到黑盒模型(在某些情况下,选取数据集不是所必需的。例如, [2]提出的最大激活值方法),通过对黑盒模型的相应预测进行一定的分析(例如,对预测w.r.t.输入特征进行求导)来生成解释。根据可解释性的范围,这些方法可以进一步分为全局方法或局部方法,即它们是解释所有数据点的全局模型行为还是预测子集行为。特别地,基于实例的方法提供了一种特殊类型的解释–它们直接返回数据实例作为解释。虽然从解释范围的分类来看,基于实例的方法也可以适合全局方法(代表性样本)或局部方法(反事实),但我们单独列出它们,以强调它们提供解释的特殊方式。
全局方法旨在提供对模型逻辑的理解以及所有预测的完整推理,基于对其特征、学习到的组件和结构的整体视图等等。有几个方向可以探索全局可解释性。为了便于理解,我们将它们分为以下三个子类: (i) 模型提取——从原始黑盒模型中提取出一个可解释的模型,比如通过模型蒸馏的方式将原有黑盒模型蒸馏到可解释的决策树 [3] [4],从而使用决策树中的规则解释该原始模型; (ii) 基于特征的方法——估计特征的重要性或相关性,如 图15.1.3所示, 该类型解释可提供如“信用逾期记录是模型依赖的最重要特征”的解释,从而协助判定模型是否存在偏见. 一种典型的全局特征解释方法是SHAP(其仅能针对树模型输出全局解释)[5]。 (iii) 透明模型设计——修改或重新设计黑盒模型以提高其可解释性。这类方法目前也逐渐成为探索热点,近期的相关工作包括ProtoPNet [6], Interpretable CNN [7], ProtoTree [8]等。
图15.1.3 全局特征重要性解释
全局解释可以提供黑盒模型的整体认知。但由于黑盒模型的高复杂性,在实践中往往很难通过模型提取/设计得到与原模型行为相近的简单透明模型,也往往很难对整个数据集抽象出统一的特征重要性。此外,在为单个观察生成解释时,全局解释也缺乏局部保真度,因为全局重要的特征可能无法准确解释单个样例的决定。因此,局部方法成为了近些年领域内重要的研究方向。局部方法尝试为单个实例或一组实例检验模型行为的合理性。当仅关注局部行为时,复杂模型也可以变得简单,因此即使是简单的函数也有可以为局部区域提供可信度高的解释。基于获得解释的过程,局部方法可以分为两类:局部近似和基于传播的方法。
局部近似是通过在样本近邻区域模拟黑盒模型的行为生成可理解的子模型。相比于全局方法中的模型提取,局部近似仅需关注样本临近区域,因此更容易获得精确描述局部行为的子模型。如 图15.1.4所示,通过在关注数据点\(x\)附近生成\(m\)个数据点\((x_i^\prime, f(x_i^\prime)), for\ i=1,2, …m\)(这里\(f\)为黑盒模型决策函数),用线性拟合这些数据点,可以得到一个线性模型\(g=\sum_i^k w_ix^i\),这里\(k\)表示数据的特征维度。那么线性模型中的权重\(w_i\)即可用于表示数据\(x\)中第\(i\)个特征对于模型\(f\)的重要性。
图15.1.4 局部近似方法示例
基于传播的方法通常是传播某些信息直接定位相关特征,这些方法包含了基于反向传播的方法和基于前向传播的方法。基于反向传播的方法通过梯度回传将输出的贡献归因于输入特征。如 图15.1.5所示,通过梯度回传,计算模型输出对输入的梯度\(\frac{d(f(x))}{dx}\) 作为模型解释。常见的基于梯度传播的方法有基本Gradient方法,GuidedBackprop [9], GradCAM [10]等. 而基于前向传播的方法通过扰动特征后, 进行前向推理的输出差异来量化输出与特征的相关性。其中,常见的几种方法有RISE [11],ScoreCAM [12]等。
图15.1.5 局部近似方法示例
知识感知的解释
数据驱动的解释方法能够从数据集或输入和输出之间的关系提供全面的解释。在此基础上,还可以利用外部知识来丰富解释并使其更加人性化。没有机器学习背景知识的门外汉可能很难直接理解特征的重要性,以及特征和目标之间的联系。借助外部领域知识,我们不仅可以生成表明特征重要性的解释,还可以描述某些特征比其他特征更重要的原因。因此,在过去几年中,基于知识感知的可解释AI方法引起了越来越多的关注。与从多种情景中收集的原始数据集相比,知识通常被视为人类根据生活经验或严格的理论推理得出的实体或关系。一般来说,知识可以有多种形式。它可以保留在人的头脑中,也可以用自然语言、音频或规则记录,具有严格的逻辑。为了对这些方法进行系统回顾,我们在此根据知识来源将它们分为两类:通用知识方法和知识库(KB)方法。前者以非结构化数据为知识源来构建解释,后者以结构化知识库为基础来构建解释。
提供知识的一个相对直接的方法是通过人类的参与。事实上,随着人工智能研究和应用的爆炸式增长,人类在人工智能系统中的关键作用已经慢慢显现。这样的系统被称为以人为中心的人工智能系统。 [13]认为,以人为中心的人工智能不仅能让人工智能系统从社会文化的角度更好地了解人类,还能让人工智能系统帮助人类了解自己。为了实现这些目标,人工智能需要满足可解释性和透明度等几个属性。
具体来说,人类能够通过提供相当多的人类定义的概念来在人工智能系统中发挥作用。 [14]利用概念激活向量(CAV)来测试概念在分类任务中的重要性(TCAV)。CAV是与感兴趣目标概念的激活与否决策边界垂直的矢量,该矢量可以这样获取: 输入目标概念的正负样本, 进行线性回归, 得到决策边界, 从而得到CAV。以“斑马”的“条纹”概念为例,用户首先收集包含有“条纹”的数据样本及不含“条纹”的数据样本,输入到网络中,获取中间层的激活值,基于正负样本的标签(\(1\)代表含有概念,\(0\)代表不含概念)对中间层激活值进行拟合,获取决策边界,CAV即为该决策边界的垂直向量。
如 图15.1.6所示,为了计算TCAV评分,代表第\(l\)层概念对类\(k\)预测的重要性的“概念敏感度”可以首先计算为方向导数\(S_{C,k,l}(\mathbf{x})\): \[\begin{split} S_{C,k,l}(\mathbf{x}) = &\lim_{\epsilon\rightarrow 0}\frac{h_{l,k}(f_{l}(\mathbf{x})+\epsilon \mathbf{v}^{l}_{C})-h_{l,k}(f_{l}(\mathbf{x}))}{\epsilon} \\ = &\nabla h_{l,k}(f_{l}(\mathbf{x})) \cdot \mathbf{v}^{l}_{C} \end{split} \label{eq:TCAV_score}\] 其中\(f_{l}(\mathbf{x})\)是在第\(l\)、\(h_{l,k}(\cdot)\)是类\(k\)的logit,\(\nabla h_{l,k}(\cdot)\)是\(h_{l,k}\) w.r.t层\(l\)的激活的梯度。\(\mathbf{v}^{l}_{C}\)是用户旨在探索的概念\(C\)的CAV。正(或负)敏感性表明概念\(C\)对输入的激活有正(或负)影响。
基于\(S_{C,k,l}\), TCAV就可以通过计算类\(k\)的具有正\(S_{C,k,l}\)’s的样本的比率来获得:
\[\textbf{TCAV}_{Q_{C,k,l}}=\frac{\vert {\mathbf{x}\in X_{k}:S_{C,k,l}(\mathbf{x})>0}\vert}{\vert X_{k}\vert} \label{eq:TCAV}\] 结合\(t\)-分布假设方法,如果\(\textbf{TCAV}_{Q_{C,k,l}}\)大于0.5,则表明概念\(C\)对类\(k\)有重大影响。
![TCAV流程(图片来源于 <sup id="cite-2020tkde_li"><a href="#ref-2020tkde_li">[1]</a></sup>)](img/ch11/xai_tcav.png)
图15.1.6 TCAV流程(图片来源于 [1])
人类的知识可以是主观的,而KB可以是客观的。在当前研究中,KB通常被建模为知识图谱(KG)。以下以MindSpore支持的可解释推荐模型TB-Net为例,讲解如何使用知识图谱构建可解释模型。知识图谱可以捕捉实体之间丰富的语义关系。TB-Net的目的之一就是确定哪一对实体(即,物品-物品)对用户产生最重大的影响,并通过什么关系和关键节点进行关联。不同于现有的基于KG嵌入的方法(RippleNet使用KG补全方法预测用户与物品之间的路径),TB-Net提取真实路径,以达到推荐结果的高准确性和优越的可解释性。
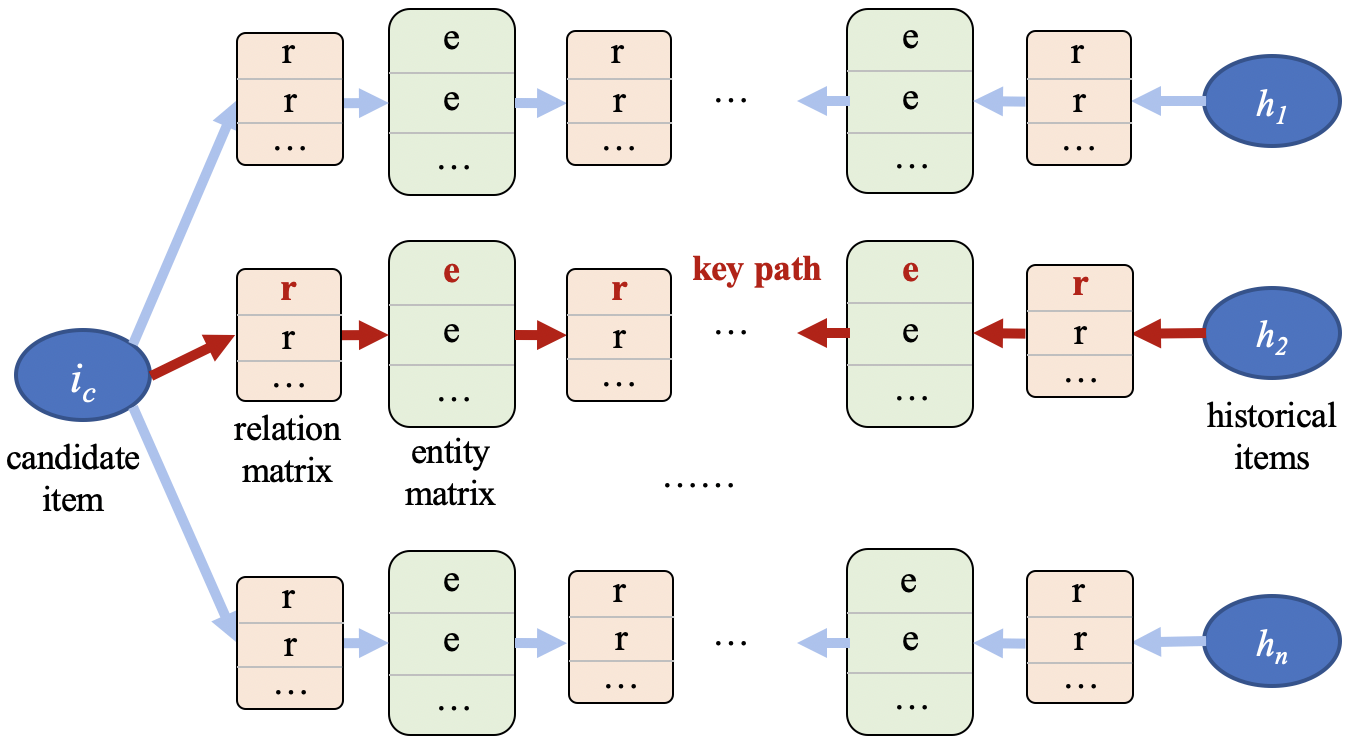
图15.1.7 TB-Net网络训练框架
TB-Net的框架如 图15.1.7所示:其中,\(i_c\)代表待推荐物品,\(h_n\)代表历史记录中用户交互的物品,\(r\)和\(e\)代表图谱中的关系(relation)和实体(entity),它们的向量化表达拼接在一起形成关系矩阵和实体矩阵。首先,TB-Net通过\(i_c\)和\(h_n\)的相同特征值来构建用户\(u\)的子图谱,每一对\(i_c\)和\(h_n\)都由关系和实体所组成的路径来连接。然后,TB-Net的路径双向传导方法将物品、实体和关系向量的计算从路径的左侧和右侧分别传播到中间节点,即计算左右两个流向的向量汇集到同一中间实体的概率。该概率用于表示用户对中间实体的喜好程度,并作为解释的依据。最后,TB-Net识别子图谱中关键路径(即关键实体和关系),输出推荐结果和具有语义级别的解释。
以游戏推荐为场景,随机对一个用户推荐新的游戏,如 xai_kg_recommendation所示,其中Half-Life, DOTA 2, Team Fortress 2等为游戏名称。关系属性中,game.year 代表游戏发行年份,game.genres代表游戏属性,game.developer代表游戏的开发商,game.categories代表游戏分类。属性节点中,MOBA代表多人在线战术竞技游戏,Valve代表威尔乌游戏公司,Action代表动作类,Multi-player代表多人游戏,Valve Anti-Cheat enabled代表威尔乌防作弊类,Free代表免费,Cross-Platform代表跨平台。右边的游戏是用户历史记录中玩过的游戏。而测试数据中正确推荐的游戏是“Team Fortress 2”。
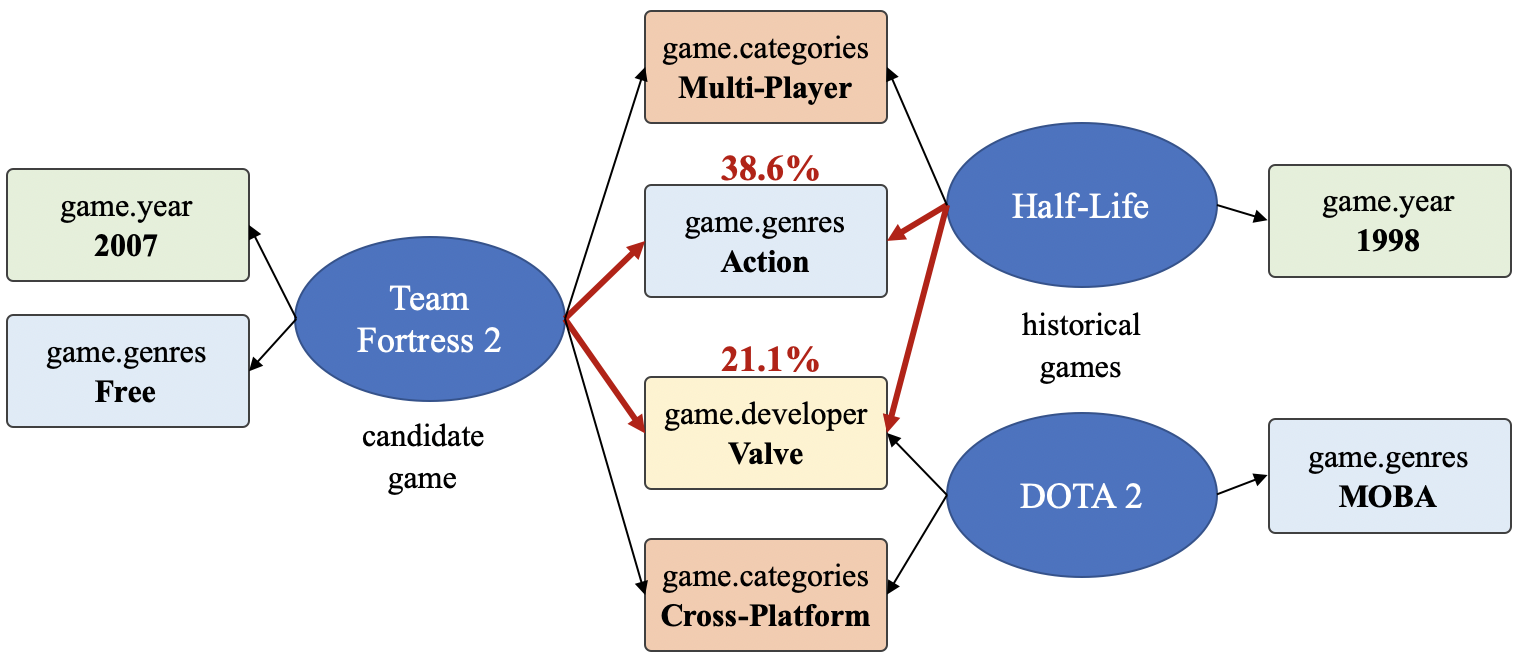
在 xai_kg_recommendation中,有两个突出显示的相关概率(38.6%, 21.1%),它们是在推荐过程中模型计算的关键路径被激活的概率。红色箭头突出显示从“Team Fortress 2”到历史项目“Half-Life”之间的关键路径。它表明TB-Net能够通过各种关系连接向用户推荐物品,并找出关键路径作为解释。因此,将“Team Fortress 2”推荐给用户的解释可以翻译成固定话术:“Team Fortress 2”是游戏公司“Valve”开发的一款动作类、多人在线、射击类电子游戏。这与用户历史玩过的游戏“Half-Life”有高度关联。
可解释AI系统及实践
随着各领域对可解释的诉求快速增长,越来越多企业集成可解释AI工具包,为广大用户提供快速便捷的可解释实践,业界现有的主流工具包有:
- TensorFlow团队的What-if Tool,用户不需编写任何程序代码就能探索学习模型,让非开发人员也能参与模型调校工作。
- IBM的AIX360,提供了多种的解释及度量方法去评估模型在各个不同维度上的可解释及可信性能。
- Facebook Torch团队的captum,针对图像及文本场景,提供了多种主流解释方法。
- 微软的InterpretML,用户可以训练不同的白盒模型及解释黑盒模型。
- SeldonIO的Alibi,专注于查勘模型内部状况及决策解释,提供各种白盒、黑盒模型、单样本及全局解释方法的实现。
- 华为MindSpore的XAI工具,提供数据工具、解释方法、白盒模型以及度量方法,为用户提供不同级别的解释(局部,全局,语义级别等)。
本节将以MindSpore XAI工具为例,讲解在实践中如何使用可解释AI工具为图片分类模型和表格数据分类模型提供解释,从而协助用户理解模型进行进一步的调试调优。 MindSpore XAI工具的架构如下,其为基于MindSpore深度学习框架的一个可解释工具,可在Ascend及GPU设备上部署。
图15.1.8 MindSpore XAI 架构图
要使用MindSpore可解释AI,读者首先要通过pip安装MindSpore XAI包(支持MindSpore1.7 或以上,GPU及Ascend 处理器,推荐配合JupyterLab使用):
pip install mindspore-xai
在MindSpore XAI的官网教程中,详细介绍了如何安装和使用提供的解释方法, 读者可自行查阅。
MindSpore XAI工具为图片分类场景提供解释
下面结合MindSpore XAI1.8版本中已支持的显着图可视方法 GradCAM 作为一个代码演示例子。读者可参阅官方教程以取得演示用的数据集, 模型和完整脚本代码。
from mindspore_xai.explainer import GradCAM
# 通常指定最后一层的卷积层
grad_cam = GradCAM(net, layer="layer4")
# 3 是'boat'类的ID
saliency = grad_cam(boat_image, targets=3)
如果输入的是一个维度为 \(1*3*224*224\) 的图片Tensor,那返回的saliency就是一个 \(1*1*224*224\) 的显著图Tensor。下面我们将几个例子展示如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优。

图15.1.9 预测结果正确,依据的关键特征合理的例子
上图预测标签是“bicycle”,解释结果给出依据的关键特征 在车轮上,说明这个分类判断依据是合理的, 可以初步判定模型为可信的。

图15.1.10 预测结果正确,依据的关键特征不合理的例子
上图在预测标签中有1个标签是“person”,这个结果是对的;但是解释的时候,高亮区域在马头的上,那么这个关键特征依据很可能是错误的, 这个模型的可靠性还需进一步验证。

图15.1.11 预测结果错误,依据的关键特征不合理的例子
在上图中,预测标签为“boat”,但是原始图像中并没有船只存在,通过图中右侧解释结果可以看到模型将水面作为分类的关键依据,得到预测结果“boat”,这个依据是错误的。通过对训练数据集中标签为“boat”的数据子集进行分析,发现绝大部分标签为“boat”的图片中,都有水面,这很可能导致模型训练的时候,误将水面作为“boat”类型的关键依据。基于此,按比例补充有船没有水面的图片集,从而大幅消减模型学习的时候误判关键特征的概率。
MindSpore XAI工具为表格分类场景提供解释
MindSpore XAI 1.8版本支持了三个业界比较常见的表格数据模型解释方法:LIMETabular、SHAPKernel和SHAPGradient。
以LIMETabular为例针对一个复杂难解释的模型,提供一个局部可解释的模型来对单个样本进行解释:
from mindspore_xai.explainer import LIMETabular
# 将特征转换为特征统计数据
feature_stats = LIMETabular.to_feat_stats(data, feature_names=feature_names)
# 初始化解释器
lime = LIMETabular(net, feature_stats, feature_names=feature_names, class_names=class_names)
# 解释
lime_outputs = lime(inputs, targets, show=True)
解释器会显示出把该样本分类为setosa这一决定的决策边界,返回的 lime_outputs 是代表决策边界的一个结构数据。 可视化解释,可得到

图15.1.12 LIME解释结果
上述解释说明针对setosa这一决策,最为重要的特征为petal length。MindSpore XAI工具提供白盒模型
除了针对黑盒模型的事后解释方法,XAI工具同样提供业界领先的白盒模型,使得用户可基于这些白盒模型进行训练,在推理过程中模型可同时输出推理结果及解释结果。以TB-Net为例(可参考图15.1.7及其官网教程进行使用),该方法已上线商用,为百万级客户提供带有语义级解释的理财产品推荐服务。TB-Net利用知识图谱对理财产品的属性和客户的历史数据进行建模。在图谱中,具有共同属性值的理财产品会被连接起来,待推荐产品与客户的历史购买或浏览的产品会通过共同的属性值连接成路径,构成该客户的子图谱。然后,TB-Net对图谱中的路径进行双向传导计算,从而识别关键产品和关键路径,作为推荐和解释的依据。
一个可解释推荐的例子如下:在历史数据中,该客户近期曾购买或浏览了理财产品A、B和N等等。通过TB-Net的路径双向传导计算可知,路径(产品P,年化利率_中等偏高,产品A)和路径(产品P,风险等级_中等风险,产品N)的权重较高,即为关键路径。此时,TB-Net输出的解释为:“推荐理财产品P给该客户,是因为它的年化利率_中等偏高,风险等级_中等风险,分别与该客户近期购买或浏览的理财产品A和B一致。”

图15.1.13 TBNet应用金融理财场景
除了上面介绍的解释方法外,MindSpore XAI还会提供一系列的度量方法用以评估不同解释方法的优劣,另外也会陆续增加自带解释的白盒模型,用户可直接取用成熟的模型架构以快速构建自己的可解释AI系统。
未来可解释AI
为了进一步推动可解释AI的研究,我们在此总结了一些值得注意的研究方向。
首先,知识感知型XAI仍有很大的研究扩展空间。然而,要有效地利用外部知识,仍有许多悬而未决的问题。其中一个问题是如何在如此广阔的知识空间中获取或检索有用的知识。例如, 维基百科上记载了各式各样各领域相关的知识, 但如果要解决医学图像分类问题, 维基百科上大部分词条都是无关或存在噪音的, 这样便很难准确地寻找到合适的知识引入到XAI系统中。
此外,XAI系统的部署也非常需要一个更加标准和更加统一的评估框架。为了构建标准统一的评估框架,我们可能需要同时利用不同的指标,相互补充。不同的指标可能适用于不同的任务和用户。统一的评价框架应具有相应的灵活性。
最后,我们相信跨学科合作将是有益的。XAI的发展不仅需要计算机科学家来开发先进的算法,还需要物理学家、生物学家和认知科学家来揭开人类认知的奥秘,以及特定领域的专家来贡献他们的领域知识。
参考文献
:bibliography:../references/explainable.bib
参考文献
- Li, Xiao-Hui and Cao, Caleb Chen and Shi, Yuhan and Bai, Wei and Gao, Han and Qiu, Luyu and Wang, Cong and Gao, Yuanyuan and Zhang, Shenjia and Xue, Xun and Chen, Lei. A Survey of Data-driven and Knowledge-aware eXplainable AI. IEEE Transactions on Knowledge and Data Engineering. 2020. ↩
- Erhan, Dumitru and Bengio, Yoshua and Courville, Aaron and Vincent, Pascal. Visualizing higher-layer features of a deep network. University of Montreal. 2009. ↩
- Frosst, Nicholas and Hinton, Geoffrey. Distilling a neural network into a soft decision tree. arXiv preprint arXiv:1711.09784. 2017. ↩
- Zhang, Quanshi and Yang, Yu and Ma, Haotian and Wu, Ying Nian. Interpreting cnns via decision trees. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019. ↩
- Lundberg, Scott M and Lee, Su-In. A unified approach to interpreting model predictions. Advances in neural information processing systems. 2017. ↩
- Chen, Chaofan and Li, Oscar and Tao, Daniel and Barnett, Alina and Rudin, Cynthia and Su, Jonathan K. This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems. 2019. ↩
- Zhang, Quanshi and Wu, Ying Nian and Zhu, Song-Chun. Interpretable convolutional neural networks. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. ↩
- Nauta, Meike and van Bree, Ron and Seifert, Christin. Neural prototype trees for interpretable fine-grained image recognition. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. ↩
- Zeiler, Matthew D and Fergus, Rob. Visualizing and understanding convolutional networks. European conference on computer vision. 2014. ↩
- Selvaraju, Ramprasaath R and Cogswell, Michael and Das, Abhishek and Vedantam, Ramakrishna and Parikh, Devi and Batra, Dhruv. Grad-cam: Visual explanations from deep networks via gradient-based localization. Proceedings of the IEEE international conference on computer vision. 2017. ↩
- Petsiuk, Vitali and Das, Abir and Saenko, Kate. Rise: Randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421. 2018. ↩
- Wang, Haofan and Wang, Zifan and Du, Mengnan and Yang, Fan and Zhang, Zijian and Ding, Sirui and Mardziel, Piotr and Hu, Xia. Score-CAM: Score-weighted visual explanations for convolutional neural networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020. ↩
- Riedl, Mark O.. Human-centered artificial intelligence and machine learning. Human Behavior and Emerging Technologies. 2019. ↩
- Been Kim and Martin Wattenberg and Justin Gilmer and Carrie Cai and James Wexler and Fernanda Viegas and Rory Sayres. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). 2018. ↩
机器人系统
本章介绍机器学习的一个重要分支——机器人及其在系统方面的知识,学习目标包括:
-
掌握机器人系统基本知识。
-
掌握感知系统、规划系统和控制系统。
-
掌握通用机器人操作系统。
机器人系统概述
机器人系统概述
机器人学是一个交叉学科,它涉及了计算机科学、机械工程、电气工程、生物医学工程、数学等多种学科,并有诸多应用,比如自动驾驶汽车、机械臂、无人机、医疗机器人等。机器人能够自主地完成一种或多种任务或者辅助人类完成指定任务。通常,人们把机器人系统划分为感知系统、决策(规划)和控制系统等组成部分。
机器人系统按照涉及的机器人数量,可以划分为单机器人学习系统和多机器人学习系统。多机器人学习系统协作和沟通中涉及的安全和隐私问题,也会是一个值得研究的方向。最近机器人学习系统在室内自主移动 [1][2],道路自动驾驶 [3][4][5],机械臂工业操作等行业场景得到充分应用和发展。一些机器人学习基础设施项目也在进行中,如具备从公开可用的互联网资源、计算机模拟和 真实机器人试验中学习能力的大规模的计算系统RoboBrain。在自动驾驶领域,受联网的自动驾驶汽车 (CAV) 对传统交通运输行业的影响,“车辆计算”(Vehicle Computing) 概念引起广泛关注,并激发了如何让计算能力有限使用周围的CAV计算平台来执行复杂的计算任务的研究。最近,有很多自动驾驶系统的模拟器,代表性的比如CARLA,MetaDrive [6],CarSim和TruckSim,它们可以作为各种自动驾驶算法的训练场并对算法效果进行评估。另外针对自动驾驶的系统开发平台也不断涌现,如ERDOS、D3 (Dynamic Deadline-Driven)和Pylot,可以让模型训练与部署系统与这些平台对接。
![车辆计算框架图 <sup id="cite-9491826"><a href="#ref-9491826">[7]</a></sup>](img/ch13/vehicle_computing.png)
图16.1.1 车辆计算框架图 [7]
图16.1.2是一个典型的感知、规划、控制的模块化设计的自动驾驶系统框架图,绿线表示自主驾驶系统的模块化流程,而橙色虚线表示规划和控制模块是不可微的。但是决策策略可以通过重新参数化技术进行训练,如蓝色虚线所示。接下来将按照这个顺序依次介绍感知系统、规划系统和控制系统。
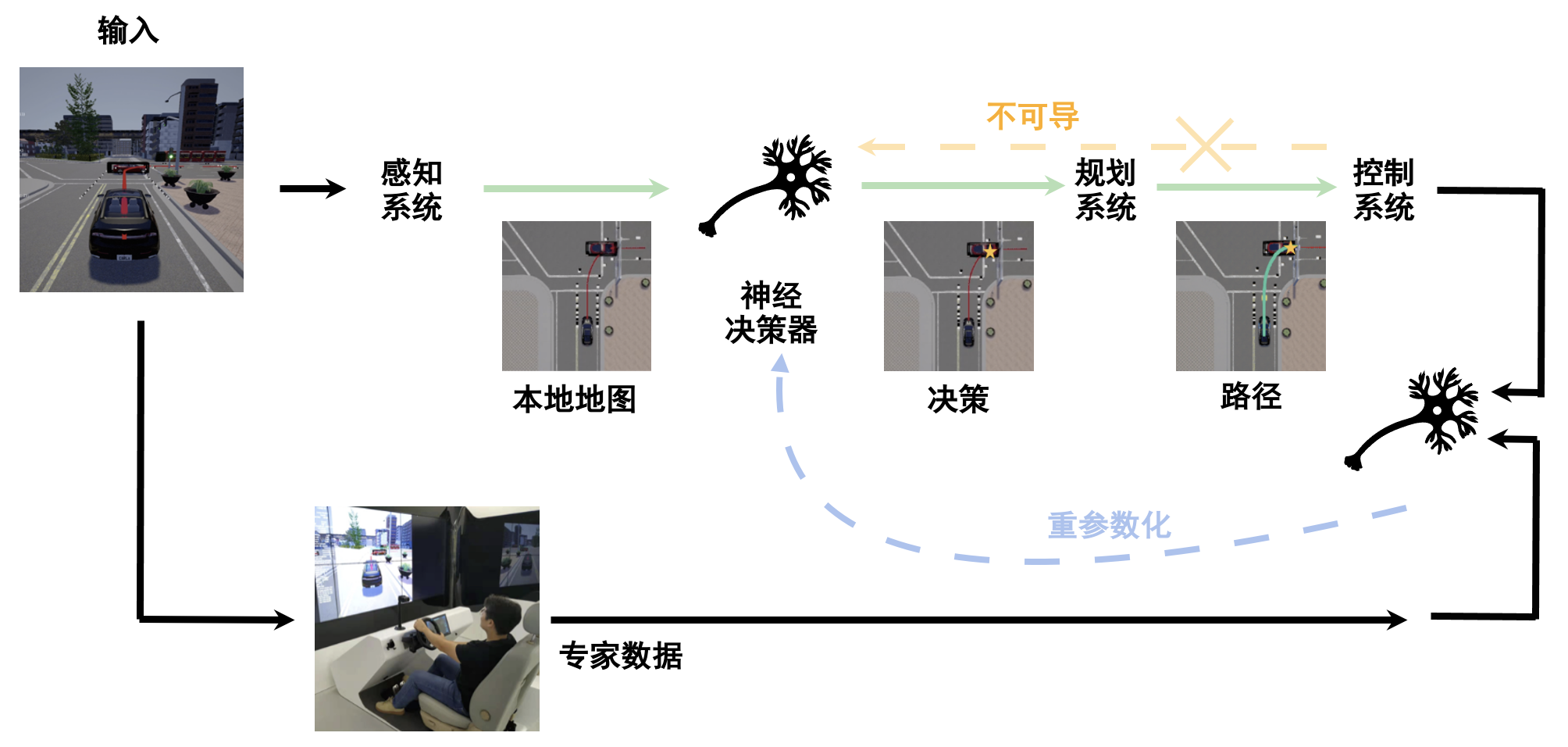
图16.1.2 通过模仿学习进行自动驾驶框架图。
感知系统
感知系统不仅包括视觉感知,还可以包含触觉、声音等。在未知环境中,机器人想实现自主移动和导航必须知道自己在哪(通过相机重定位 [8]),周围什么情况(通过3D物体检测 [9]或语义分割),预测相机在空间的轨迹 [10],这些要依靠感知系统来实现 [11]。 一提到感知系统,不得不提的就是即时定位与建图(Simultaneous Localization and Mapping,SLAM)系统。SLAM大致过程包括地标提取、数据关联、状态估计、状态更新以及地标更新等。视觉里程计Visual Odometry是SLAM中的重要部分,它估计两个时刻机器人的相对运动(Ego-motion)。ORB-SLAM系列是视觉SLAM中有代表性的工作, 图16.1.3 展示了最新的ORB-SLAM3的主要系统组件。香港科技大学开源的基于单目视觉与惯导融合的SLAM技术VINS-Mono也很值得关注。多传感器融合、优化数据关联与回环检测、与前端异构处理器集成、提升鲁棒性和重定位精度都是SLAM技术接下来的发展方向。
最近,随着机器学习的兴起,基于学习的SLAM框架也被提了出来。TartanVO是第一个基于学习的视觉里程计(VO)模型,该模型可以推广到多个数据集和现实世界场景,并优于传统基于几何的方法。 UnDeepVO是一个无监督深度学习方案,能够通过使用深度神经网络估计单目相机的 6-DoF 位姿及其视图深度。DROID-SLAM是用于单目、立体和 RGB-D 相机的深度视觉 SLAM,它通过Bundle Adjustment层对相机位姿和像素深度的反复迭代更新,具有很强的鲁棒性,故障大大减少,尽管对单目视频进行了训练,但它可以利用立体声或 RGB-D 视频在测试时提高性能。其中,Bundle Adjustment (BA)与机器学习的结合被广泛研究。CMU提出通过主动神经 SLAM 的模块化系统帮助智能机器人在未知环境中的高效探索。
物体检测与语义分割
感知系统不仅包括视觉感知,还可以包含触觉、声音等。在未知环境中,机器人想实现自主移动和导航必须知道自己在哪(通过相机重定位 [8]),周围什么情况(通过3D物体检测 [9]或语义分割),预测相机在空间的轨迹 [10],这些要依靠感知系统来实现 [11]。
图像语义分割作为一项常用而又经典的感知技术,经过多年不停的迭代,传统的2D技术已经渐渐的趋于成熟,提升空间较小。同时传统的2D语义分割有一定的局限性,很难从2D图像中直接获知物体的空间位置、以及其在整体空间中的布局,要知道整体空间的位置信息还是需要更多的三维信息。为了让机器人从单纯的2D图像出发,得到空间中物体三维的坐标、语义和边界信息,跨视角语义分割 [1]吸引了众多研究者的关注。
即时定位与建图(SLAM)
将一个机器人放到未知的环境中,如何能让它明白自己的位置和周围环境?这要靠即时定位与建图(Simultaneous Localization and Mapping,SLAM)系统来实现。
图16.1.3 展示了最新的ORB-SLAM3的主要系统组件。 SLAM大致过程包括地标提取、数据关联、状态估计、状态更新以及地标更新等。SLAM系统在机器人运动过程中通过重复观测到的地图特征(比如,墙角,柱子等)定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目的。
DROID-SLAM是用于单目、立体和 RGB-D 相机的深度视觉 SLAM,它通过Bundle Adjustment层对相机位姿和像素深度的反复迭代更新,具有很强的鲁棒性,故障大大减少,尽管对单目视频进行了训练,但它可以利用立体声或 RGB-D 视频在测试时提高性能。 其中,Bundle Adjustment (BA)描述了像素坐标和重投影坐标之间误差的和,重投影坐标通常使用3D坐标点和相机参数计算得到。BA计算量较大较为耗时,爱丁堡大学提出通过分布式多GPU系统 [12] 对BA计算进行加速。随着机器学习的发展,BA与机器学习的结合被广泛研究。
视觉里程计Visual Odometry是SLAM中的重要部分,它估计两个时刻机器人的相对运动。 最近,随着机器学习的兴起,基于学习的VO框架也被提了出来。 TartanVO是第一个基于学习的视觉里程计(VO)模型,该模型可以推广到多个数据集和现实世界场景,并优于传统基于几何的方法。
![ORB-SLAM3主要系统组件 <sup id="cite-campos2021orb"><a href="#ref-campos2021orb">[13]</a></sup>](img/ch13/orbslam3.png)
图16.1.3 ORB-SLAM3主要系统组件 [13]
规划系统
机器人规划不仅包含运动路径规划,还包含任务规划 [14] [15] [16]。其中,运动规划是机器人技术的核心问题之一,在给定的两个位置之间为机器人找到一条符合约束条件的路径。这个约束可以是无碰撞、路径最短、机械功最小等,需要有概率完整性和最优性的保证,从导航到复杂环境中的机械臂操作都有运动规划的应用。然而,当经典运动规划在处理现实世界的机器人问题(在高维空间中)时,挑战仍然存在。研究人员仍在开发新算法来克服这些限制,包括优化计算和内存负载、更好地规划表示和处理维度灾难等。
同时,机器学习的一些进展为机器人专家研究运动规划问题开辟了新视角:以数据驱动的方式解决经典运动规划器的瓶颈。基于深度学习的规划器可以使用视觉或语义输入进行规划等。ML4KP是一个可用于运动动力学进行运动规划的C++库,可以轻松地将机器学习方法集成到规划过程中。
强化学习在规划系统上也有重要应用 [17],最近有一些工作基于MetaDrive模拟器 [6]进行多智能体强化学习、驾驶行为分析等 [18] [19] [20]。为了更好地说明强化学习是如何应用在自动驾驶中,尤其是作为自动驾驶规划模块的应用, 图16.1.4展示了一个基于深度强化学习的自动驾驶POMDP模型,包含环境、奖励、智能体等重要组件。
![基于深度强化学习的自动驾驶POMDP模型 <sup id="cite-aradi2020survey"><a href="#ref-aradi2020survey">[21]</a></sup>](img/ch13/rl_ad.png)
图16.1.4 基于深度强化学习的自动驾驶POMDP模型 [21]
控制系统
虽然控制理论已牢牢植根于基于模型(Model-based)的设计思想,但丰富的数据和机器学习方法给控制理论带来了新的机遇。控制理论和机器学习的交叉方向涵盖了广泛的研究方向以及在各种现实世界系统中的应用。
线性二次控制
理论方面,线性二次控制(Linear-Quadratic Control)是经典的控制方法。若动力系统可以用一组线性微分方程表示,而其约束为二次泛函,这类的问题称为线性二次问题。此类问题的解即为线性二次调节器(Linear–Quadratic Regulator),简称LQR。最近有关于图神经网络在分布式线性二次控制的研究,将线性二次问题转换为自监督学习问题,能够找到基于图神经网络的最佳分布式控制器,他们还推导出了所得闭环系统稳定的充分条件。
模型预测控制
模型预测控制(MPC)是一种先进的过程控制方法,用于在满足一组约束条件的同时控制过程。MPC 的主要优势在于它允许优化当前时刻的同时考虑未来时刻。因此与线性二次调节器不同。MPC 还具有预测未来事件的能力,并可以相应地采取控制措施。最近有研究将最优控制和机器学习相结合并应用在陌生环境中的视觉导航任务:比如基于学习的感知模块产生一系列航路点通过无碰撞路径引导机器人到达目标,基于模型的规划器使用这些航路点来生成平滑且动态可行的轨迹,然后使用反馈控制在物理系统上执行。实验表明,与纯粹基于几何映射或基于端到端学习的方案相比,这种新的系统可以更可靠、更有效地到达目标位置。
控制系统的稳定性分析
因为安全对机器人应用是至关重要的,有的强化学习方法通过学习动力学的不确定性来提高安全性,鼓励安全、稳健、以及可以正式认证所学控制策略的方法,如 图16.1.5展示了安全学习控制(Safe Learning Control)系统的框架图。Lyapunov 函数是评估非线性动力系统稳定性的有效工具,最近有人提出Neural Lyapunov来将安全性纳入考虑。
![安全学习控制系统,数据被用来更新控制策略或或安全滤波器 <sup id="cite-brunke2021safe"><a href="#ref-brunke2021safe">[22]</a></sup>](img/ch13/safe_learning_control.png)
图16.1.5 安全学习控制系统,数据被用来更新控制策略或或安全滤波器 [22]
在机器人项目中安全的应用机器学习
机器人和机器学习都是有广阔前景和令人兴奋的前沿领域,而当它们结合在一起后,会变得更加迷人,并且有远大于1+1>2的效果。 因此,当我们在机器人项目中应用机器学习时,我们很容易过于兴奋,尝试着用机器学习去做很多之前只能幻想的成果。 然而,在机器人中应用机器学习和直接使用机器学习有着很多不同。 其中很重要的一点不同就是,一般的机器学习系统更多的是在虚拟世界中造成直接影响,而机器人中的机器学习系统很容易通过机器人对物理世界造成直接影响。 因此,当我们在机器人项目中应用机器学习时,我们必须时刻关注系统的安全性,保证无论是在产品开发时还是在产品上市后的使用期,开发者和用户的安全性都能得到可靠的保证。 而且不仅商业项目要考虑安全性,开发个人项目是也需要确保安全性。 没有人想因为安全性上的疏忽而对自己或朋友/同事造成无法挽回的遗憾。
以上这些并不是危言耸听,让我们设想以下这些情况: 假设你正在为你们公司开发一个物流仓库内使用的移动货运机器人,它被设计为和工人在同一工作环境内运行,以便在需要时及时帮工人搬运货物至目的地。 这个机器人有一个视觉的行人识别系统,以便识别前方是否有人。 当机器人在前进的过程中遇到障碍物的话,这个行人识别系统会参与决定机器人的行为。 如果有人的话,机器人会选择绕大弯来避开行进道路上的行人障碍物;而如果没人的话,机器人可以绕小弯来避障。 可是,如果某次这个行人识别系统检测失误,系统没有检测到前方的障碍物是一个正在梯子上整理货物的工人,所以选择小弯避障。 而当机器人靠近时,工人才突然发现有个机器人正在靠近他,并因此受到惊吓跌落至机器人行进的正前方。如果我们考虑到物流仓库的货运机器人自重加载重一般至少是几百公斤,我们就知道万一真的因此发生碰撞,后果是不堪设想。 如果真的发生这种情况,这个机器人产品的商业前景会毁于一旦,公司和负责人也会被追究相应责任(甚至法律意义上的责任)。更重要的是,对受害者所造成的伤害和自己心里的内疚会对双方的一生都造成严重的影响。
不仅是商业项目,假设你正在开发一个小型娱乐机械臂来尝试帮你完成桌面上的一些小任务,例如移动茶杯或打开关闭开关。 你的这个机械臂也依赖于一个物体识别系统来识别任务目标。 某次在移动茶杯时,机械臂没有识别到规划路线中有一个接线板,因此茶杯不小心摔倒并且水泼到接线板里引起短路。 幸运的话可能只需要换一个接线板,而不幸的时候甚至可能会引起火灾或电击。 我相信,没有人会想遇到这类突发事件。
因此,无论是在怎样的机器人项目中应用机器学习,我们都必须时刻关注和确保系统的安全性。
确保安全性的办法:风险评估和独立的安全系统
风险评估
为了能够确保机器人和机器学习系统的安全性,我们首先要知道可能有哪些危险。 我们可以通过风险评估(Risk Assessment)来做到这一点。 怎样完成一份风险评估网上已经有很多文章了,我们在这里就不过多的介绍。 我们想要强调的是,对于发现的风险,我们需要尽可能的给出一个避免风险的方案(Risk Mitigation)。 更重要的时,我们需要确保这些方案的具体执行,而不仅仅是流于表面的给出方案就完事。 一份没有执行的方案等于没有方案。
独立的安全系统
在了解了可能有哪些风险之后,我们可以通过设计一个独立的安全系统来规避掉风险中和机器人系统相关的那一部分。 具体来讲,这个安全系统应该独立于机器学习系统,并且处于机器人架构的底层和拥有足够或最高等级的优先级。 实际上,这个安全系统不应该只针对机器学习系统,而是应该针对整个机器人的方方面面。 或者换句话来说,当开发机器人项目时,必须要有一个足够安全且独立的安全系统。 而针对于机器学习系统的安全性只是这个独立安全系统“足够安全”的部分体现罢了。 还是以之前的那个物流仓库移动货运机器人为例。 如果机器人的轮子是有独立安全回路并且断电自动刹车的轮子,而机器人又有一个严格符合安全标准且也有安全回路的激光雷达来检测障碍物,同时这个激光雷达的安全回路直接连接至轮子的安全回路。 这样一来,不管机器人是否检测到前方有人或突然有一个人闯入机器人行进路线,激光雷达都会检测到有异物,直接通过独立的安全回路将轮子断电并刹车,以确保不会发生碰撞。 这样一个配置完全独立于任何控制逻辑,从而不受任何上层系统的影响。 而对于开发者来说,当我们有了一个可靠独立的安全系统,我们也可以放心的去使用最新的突破性技术,而不用担心新技术是否会造成不可预期的后果。
机器学习系统的伦理问题
除了上述讨论到的最根本的安全性问题,机器学习系统的伦理问题也会对机器人的使用造成影响。
例如训练数据集中人种类型不平衡这一类经典的伦理问题。 让我们还是以之前的那个物流仓库移动货运机器人为例。 如果我们的训练数据集只有亚洲人的图片,那么当我们想要开拓海外市场时,我们的海外用户很有可能会发现我们的机器人并不能很好的识别他们的工人。 虽然独立的安全系统可以避免事故的发生,但是急停在工人面前肯定不是一个很好的用户体验。 我们机器人的海外销量也会受到影响。
机器学习系统的伦理问题是目前比较火热的一个讨论领域。作为行业相关人员,我们需要了解这个方向上的最新进展。一方面是在系统设计的初期就把这些问题考虑进去,另一方面也是希望我们的成果能够给更多人带来幸福,而不是带去困扰。
参考文献
- Pan, Bowen and Sun, Jiankai and Leung, Ho Yin Tiga and Andonian, Alex and Zhou, Bolei. Cross-View Semantic Segmentation for Sensing Surroundings. IEEE Robotics and Automation Letters. 2020. ↩
- Huang, Junning and Xie, Sirui and Sun, Jiankai and Ma, Qiurui and Liu, Chunxiao and Lin, Dahua and Zhou, Bolei. Learning a Decision Module by Imitating Driver’s Control Behaviors. Proceedings of the 2020 Conference on Robot Learning. 2021. ↩
- Sun, Jiankai and Sun, Hao and Han, Tian and Zhou, Bolei. Neuro-Symbolic Program Search for Autonomous Driving Decision Module Design. Proceedings of the 2020 Conference on Robot Learning. 2021. ↩
- Jiankai Sun and Shreyas Kousik and David Fridovich-Keil and Mac Schwager. Self-Supervised Traffic Advisors: Distributed, Multi-view Traffic Prediction for Smart Cities. arXiv preprint. 2022. ↩
- Li, Quanyi and Peng, Zhenghao and Xue, Zhenghai and Zhang, Qihang and Zhou, Bolei. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. ArXiv preprint. 2021. ↩
- Lu, Sidi and Shi, Weisong. The Emergence of Vehicle Computing. IEEE Internet Computing. 2021. ↩
- Ding, Mingyu and Wang, Zhe and Sun, Jiankai and Shi, Jianping and Luo, Ping. CamNet: Coarse-to-fine retrieval for camera re-localization. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. ↩
- Yi, Hongwei and Shi, Shaoshuai and Ding, Mingyu and Sun, Jiankai and Xu, Kui and Zhou, Hui and Wang, Zhe and Li, Sheng and Wang, Guoping. Segvoxelnet: Exploring semantic context and depth-aware features for 3d vehicle detection from point cloud. 2020 IEEE International Conference on Robotics and Automation (ICRA). 2020. ↩
- Qiu, Jianing and Chen, Lipeng and Gu, Xiao and Lo, Frank P.-W. and Tsai, Ya-Yen and Sun, Jiankai and Liu, Jiaqi and Lo, Benny. Egocentric Human Trajectory Forecasting with a Wearable Camera and Multi-Modal Fusion. IEEE Robotics and Automation Letters. 2022. ↩
- Xu, Yan and Zhu, Xinge and Shi, Jianping and Zhang, Guofeng and Bao, Hujun and Li, Hongsheng. Depth completion from sparse lidar data with depth-normal constraints. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. ↩
- Ren, Jie and Liang, Wenteng and Yan, Ran and Mai, Luo and Liu, Shiwen and Liu, Xiao. MegBA: A High-Performance and Distributed Library for Large-Scale Bundle Adjustment. European Conference on Computer Vision. 2022. ↩
- Campos, Carlos and Elvira, Richard and Rodr\'\iguez, Juan J Gomez and Montiel, Jose MM and Tardos, Juan D. Orb-slam3: An accurate open-source library for visual, visual--inertial, and multimap slam. IEEE Transactions on Robotics. 2021. ↩
- Sun, Jiankai and Huang, De-An and Lu, Bo and Liu, Yun-Hui and Zhou, Bolei and Garg, Animesh. PlaTe: Visually-Grounded Planning With Transformers in Procedural Tasks. IEEE Robotics and Automation Letters. 2022. ↩
- Wang, Chen and Fan, Linxi and Sun, Jiankai and Zhang, Ruohan and Fei-Fei, Li and Xu, Danfei and Zhu, Yuke and Anandkumar, Anima. MimicPlay: Long-Horizon Imitation Learning by Watching Human Play. arXiv preprint arXiv:2302.12422. 2023. ↩
- Li, Chengshu and Zhang, Ruohan and Wong, Josiah and Gokmen, Cem and Srivastava, Sanjana and Mart\'\in-Mart\'\in, Roberto and Wang, Chen and Levine, Gabrael and Lingelbach, Michael and Sun, Jiankai and others. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. Conference on Robot Learning. 2023. ↩
- Sun, Jiankai and Yu, Lantao and Dong, Pinqian and Lu, Bo and Zhou, Bolei. Adversarial inverse reinforcement learning with self-attention dynamics model. IEEE Robotics and Automation Letters. 2021. ↩
- Peng, Zhenghao and Li, Quanyi and Hui, Ka Ming and Liu, Chunxiao and Zhou, Bolei. Learning to Simulate Self-Driven Particles System with Coordinated Policy Optimization. Advances in Neural Information Processing Systems. 2021. ↩
- Peng, Zhenghao and Li, Quanyi and Liu, Chunxiao and Zhou, Bolei. Safe Driving via Expert Guided Policy Optimization. 5th Annual Conference on Robot Learning. 2021. ↩
- Li, Quanyi and Peng, Zhenghao and Zhou, Bolei. Efficient Learning of Safe Driving Policy via Human-AI Copilot Optimization. International Conference on Learning Representations. 2021. ↩
- Aradi, Szilard. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Transactions on Intelligent Transportation Systems. 2020. ↩
- Brunke, Lukas and Greeff, Melissa and Hall, Adam W and Yuan, Zhaocong and Zhou, Siqi and Panerati, Jacopo and Schoellig, Angela P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annual Review of Control, Robotics, and Autonomous Systems. 2021. ↩
通用机器人操作系统
通用机器人操作系统
![ROS/ROS2架构概述 <sup id="cite-maruyama2016exploring"><a href="#ref-maruyama2016exploring">[1]</a></sup>](img/ch13/ROS2_arch.png)
图16.2.1 ROS/ROS2架构概述 [1]
在这一章节中,我们来大致了解一下机器人操作系统(ROS)。机器人操作系统(ROS)起源于斯坦福大学人工智能实验室的一个机器人项目。它是一个自由、开源的框架,提供接口、工具来构建先进的机器人。由于机器人领域的快速发展和复杂化,代码复用和模块化的需求日益强烈,ROS适用于机器人这种多节点多任务的复杂场景。目前也有一些机器人、无人机甚至无人车都开始采用ROS作为开发平台。在机器人学习方面,ROS/ROS2可以与深度学习结合,有开发人员为ROS/ROS2开发了的深度学习节点,并支持NVIDIA Jetson和TensorRT。NVIDIA Jetson是NVIDIA为自主机器开发的一个嵌入式系统,包括CPU、GPU、PMIC、DRAM 和闪存的一个模组化系统,可以将自主机器软件运作系统运行速率提升。TensorRT 是由 Nvidia 发布的机器学习框架,用于在其硬件上运行机器学习推理。
作为一个适用于机器人编程的框架,ROS把原本松散的零部件耦合在了一起,为他们提供了通信架构。虽然叫做``操作系统”,ROS更像是一个中间件,给各种基于ROS的应用程序建立起了沟通的桥梁,通过这个中间件,机器人的感知、决策、控制算法可以组织和运行。ROS采用了分布式的设计思想,支持C++、Pyhton等多种编程语言,方便移植。对ROS来讲,最小的进程单元是节点,由节点管理器来管理。参数配置存储在参数服务器中。ROS的通信方式包含:主题(Topic)、服务(Service)、参数服务器(Parameter Server)、动作库(ActionLib)这四种。
ROS提供了很多内置工具,比如三维可视化器rviz,用于可视化机器人、它们工作的环境和传感器数据。它是一个高度可配置的工具,具有许多不同类型的可视化和插件。catkin是ROS 构建系统(类似于Linux下的CMake),Catkin Workspace是创建、修改、编译Catkin软件包的目录。roslaunch可用于在本地和远程启动多个ROS 节点以及在ROS参数服务器上设置参数的工具。此外还有机器人仿真工具Gazebo和移动操作软件和规划框架MoveIt!。ROS为机器人开发者提供了不同编程语言的接口,比如C++语言ROS接口roscpp,python语言的ROS接口rospy。ROS中提供了许多机器人的统一机器人描述格式URDF(Unified Robot Description Format)文件,URDF使用XML格式描述机器人文件。ROS也有一些需要提高的地方,比如它的通信实时性能有限,与工业级要求的系统稳定性还有一定差距。
ROS2项目在ROSCon 2014上被宣布,第一个ROS2发行版 Ardent Apalone 于2017年发布。ROS2增加了对多机器人系统的支持,提高了多机器人之间通信的网络性能,而且支持微控制器和跨系统平台,不仅可以运行在现有的X86和ARM系统上,还将支持MCU等嵌入式微控制器,不止能运行在Linux系统之上,还增加了对Windows、MacOS、RTOS等系统的支持。更重要的是,ROS2还加入了实时控制的支持,可以提高控制的时效性和整体机器人的性能。ROS2的通信系统基于DDS(Data Distribution Service),即数据分发服务,如 图16.2.1所示。
ROS2依赖于使用shell环境组合工作区。“工作区”(Workspace)是一个ROS术语,表示使用ROS2进行开发的系统位置。核心ROS2 工作区称为Underlay。随后的工作区称为Overlays。使用ROS2进行开发时,通常会同时有多个工作区处于活动状态。接下来我们详细介绍一下ROS2的核心概念。这一部分我们参考了文献 1。
ROS2节点
ROS Graph是一个由ROS2元素组成的网络,在同一时间一起处理数据。它包括所有的可执行文件和它们之间的联系。ROS2 中的每个节点都应负责一个单一的模块用途(例如,一个节点用于控制车轮马达,一个节点用于控制激光测距仪等)。每个节点都可以通过主题、服务、动作或参数向其他节点发送和接收数据。一个完整的机器人系统由许多协同工作的节点组成。如 图16.2.2。在ROS2中,单个可执行文件(C++程序、Python 程序等)可以包含一个或多个节点。
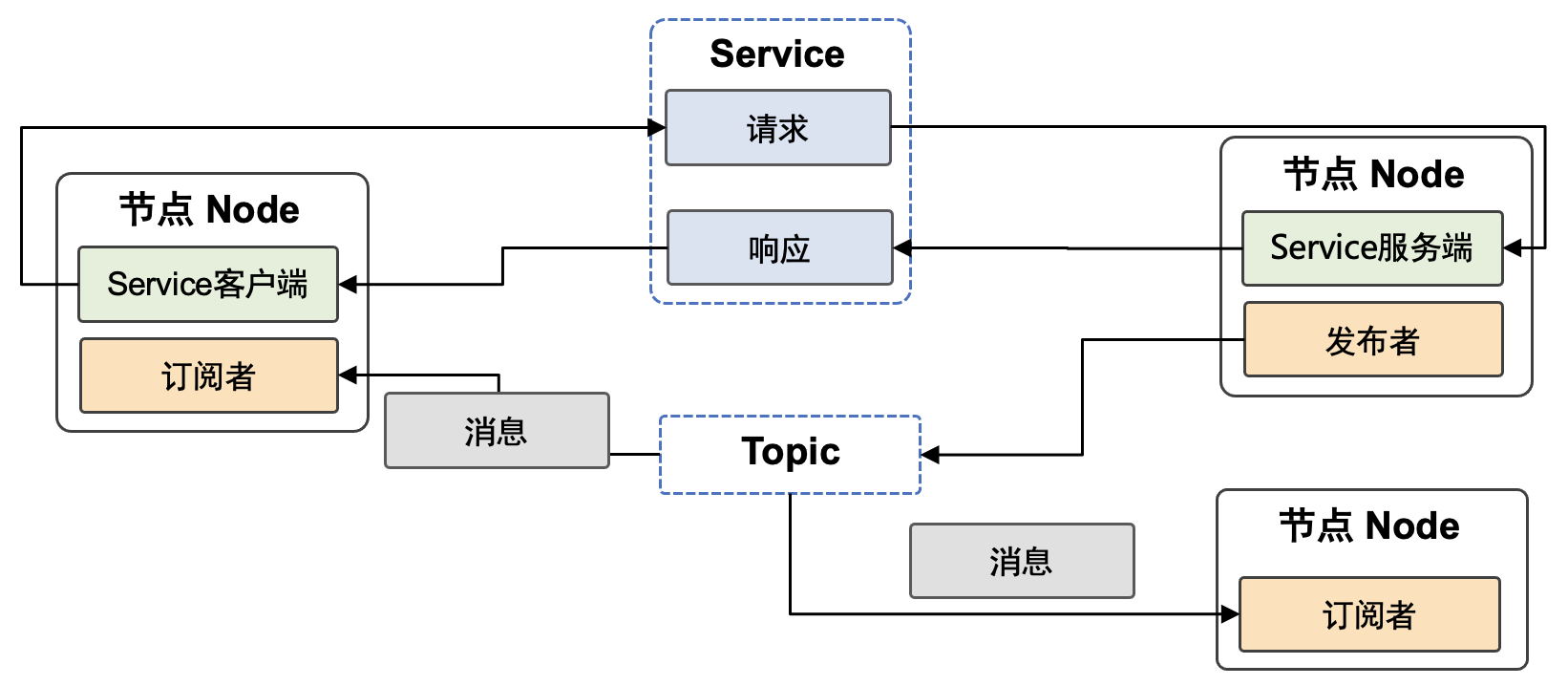
图16.2.2 一个完整的机器人系统由许多协同工作的节点组成
节点之间的互相发现是通过ROS2底层的中间件实现的,过程总结如下:
-
当一个节点启动后,它会向其他拥有相同ROS域名的节点进行广播,说明它已经上线。其他节点在收到广播后返回自己的相关信息,这样节点间的连接就可以建立了,之后就可以通信了。
-
节点会定时广播它的信息,这样即使它已经错过了最初的发现过程,它也可以和新上线的节点进行连接。
-
节点在下线前它也会广播其他节点自己要下线了。
ROS2主题
ROS2将复杂系统分解为许多模块化节点。主题(Topics)是 ROS Graph的重要元素,它充当节点交换消息的总线。如 图16.2.3 所示,一个节点可以向任意数量的主题发布数据,同时订阅任意数量的主题。主题是数据在节点之间以及因此在系统的不同部分之间移动的主要方式之一。
rqt是ROS的一个软件框架,以插件的形式实现了各种 GUI 工具。可以在 rqt 中将所有现有的GUI工具作为可停靠窗口运行。这些工具仍然可以以传统的独立方法运行,但rqt可以更轻松地同时管理屏幕上的所有各种窗口。
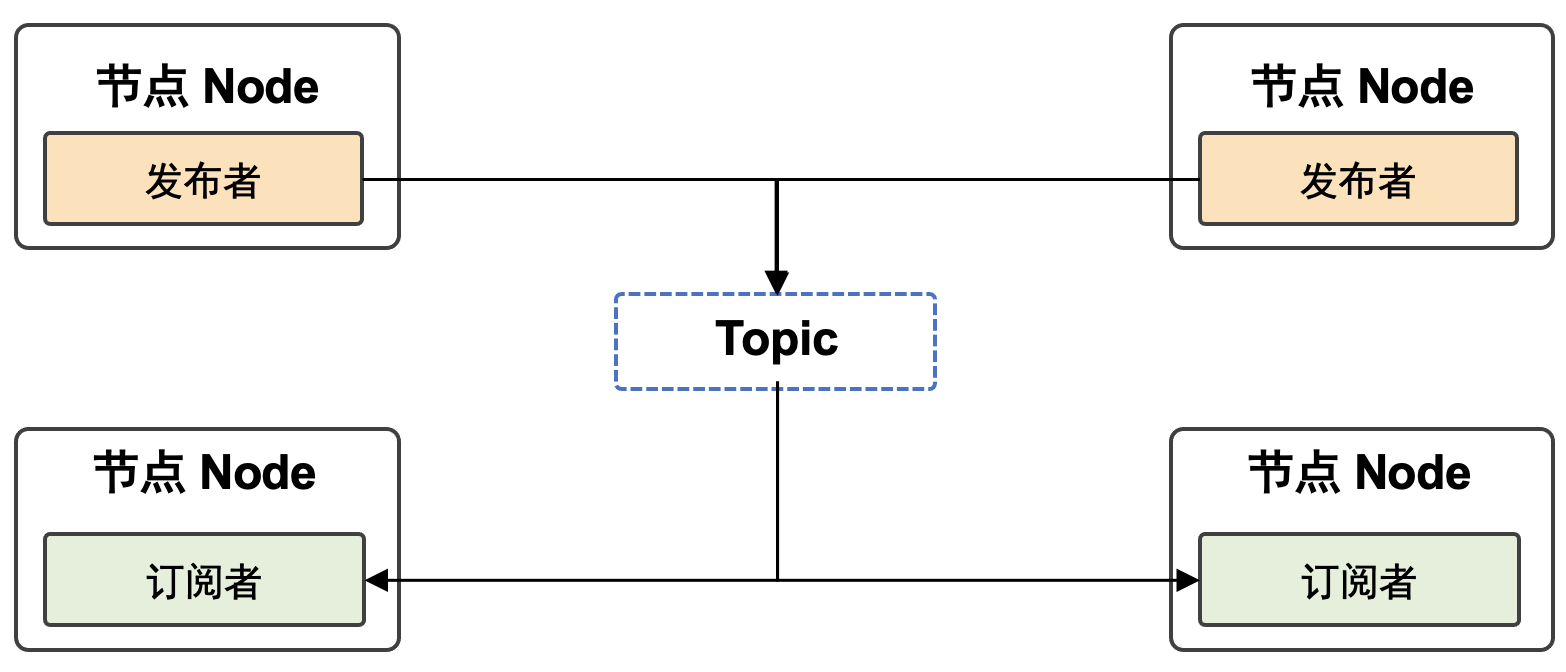
图16.2.3 一个节点可以向任意数量的主题发布数据,同时订阅任意数量的主题
ROS2服务
服务(Services)是 ROS 图中节点的另一种通信方式。服务基于调用和响应模型,而不是主题的发布者-订阅者模型。虽然主题允许节点订阅数据流并获得持续更新,但服务仅在客户端专门调用它们时才提供数据。节点可以使用ROS2中的服务进行通信。与主题那种单向通信模式中节点发布可由一个或多个订阅者使用的信息的方式不同,服务是客户端向节点发出请求的请求/响应模式提供服务,服务处理请求并生成响应,如 图16.2.4
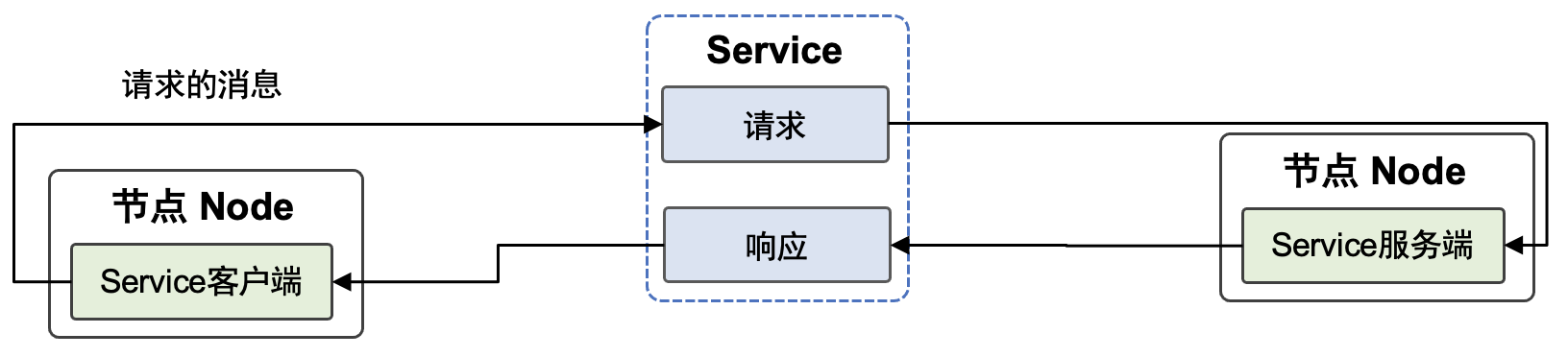
图16.2.4 ROS2服务
ROS2参数
参数(Parameters)是节点的配置值。您可以将参数视为节点设置。节点可以将参数存储为整数、浮点数、布尔值、字符串和列表。在ROS2 中,每个节点都维护自己的参数。
ROS2动作
动作(Actions)是ROS2中的一种通信类型,适用于长时间运行的任务。它们由三个部分组成:目标、反馈和结果,如 图16.2.5 所示。动作建立在主题和服务之上。它们的功能类似于服务,除了可以取消动作。它们还提供稳定的反馈,而不是返回单一响应的服务。动作使用客户端-服务器模型,类似于发布者-订阅者模型。”动作客户端”节点将目标发送到”动作服务器”节点,该节点确认目标并返回反馈流和结果。机器人系统可能会使用动作进行导航。动作目标可以告诉机器人前往某个位置。当机器人导航到该位置时,它可以沿途发送更新(即反馈),然后在到达目的地后发送最终结果消息。
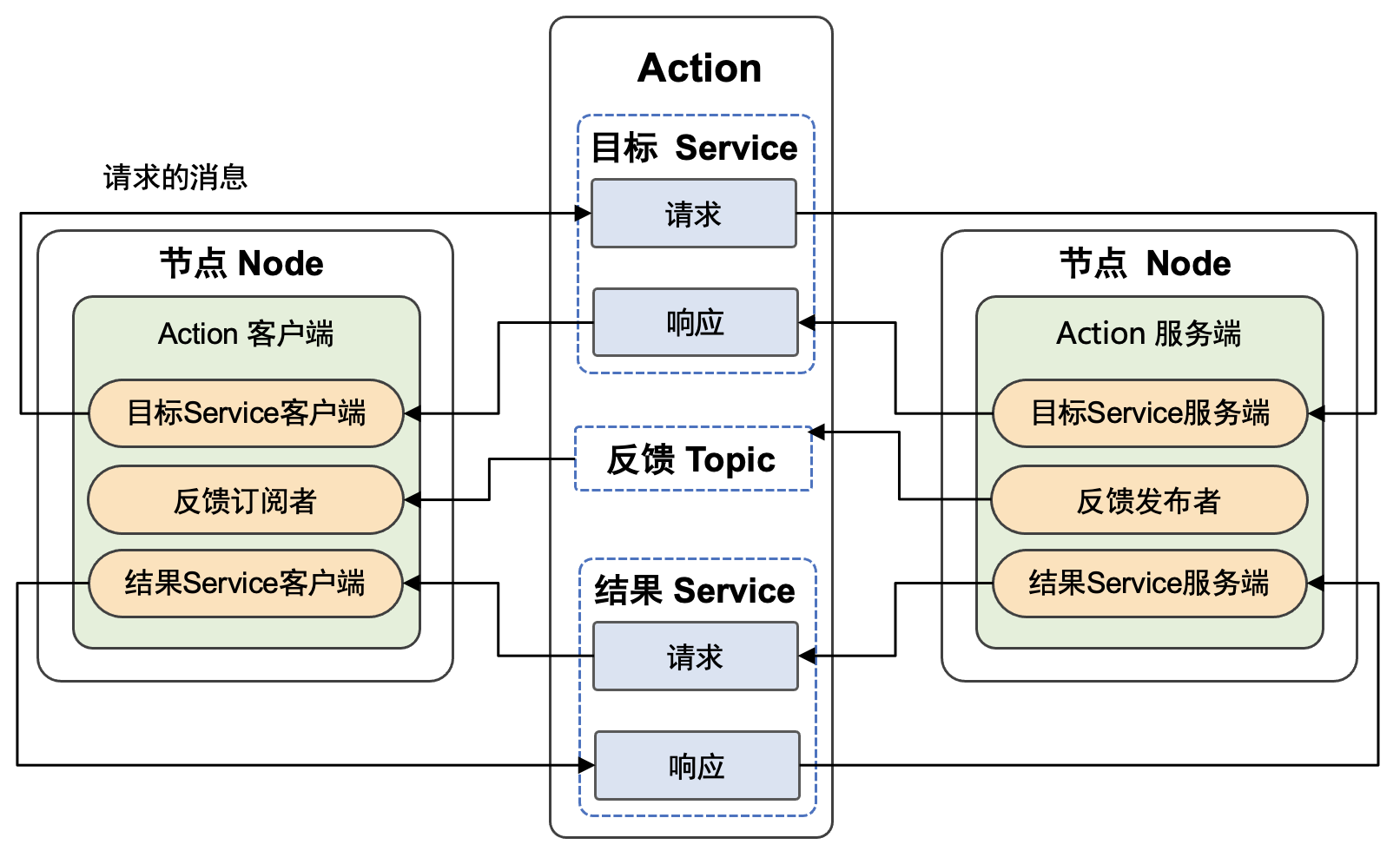
图16.2.5 ROS2动作
参考文献
- Maruyama, Yuya and Kato, Shinpei and Azumi, Takuya. Exploring the performance of ROS2. Proceedings of the 13th ACM SIGBED International Conference on Embedded Software (EMSOFT). 2016. ↩
-
https://docs.ros.org/en/foxy/Tutorials/Understanding-ROS2-Nodes.html ↩
案例分析:使用机器人操作系统
案例分析:使用机器人操作系统
在这一章节中,我们将带领大家安装ROS2并配置好使用环境,然后再通过一些简单的代码示例来让大家更深入的了解如何使用ROS2和上一章节所介绍的概念。
在本章节以及本章后续的案例章节中,我们将使用ROS2 Foxy Fitzroy(笔者撰写时的最新的ROS2 LTS版本),Ubuntu Focal(20.04)和Ubuntu Focal系统所带的Python 3.8(笔者的Ubuntu Focal所带的是3.8.10)。
其中ROS2 Foxy Fitzroy和Ubuntu Focal是官方的搭配,而如果你采用debian安装的方式(官方推荐方式)来安装ROS2的话,则Python必须使用Ubuntu所带的Python3版本。
这是因为debian安装方式会将很多ROS2的Python依赖库以apt install(而非pip install)的方式安装到Ubuntu自带的Python3路径中去。
这也就是说,当你选定ROS2版本后,你所需的Ubuntu版本和Python版本也就随之确定了。
如果想要使用Python虚拟环境(virtual env)的话,也必须指定使用Ubuntu系统所带的Python解释器(interpreter),并在创建时加上site-packages选项。添加这个选项是因为我们需要那些安装在系统Python3路径中的ROS2的依赖库。
举例来说,对于pipenv用户,可以通过下面这条命令来创建一个使用系统Python3并添加了site-packages的虚拟环境。
pipenv --python $(/usr/bin/python3 -V | cut -d" " -f2) --site-packages
因为要使用系统Python3的原因,用conda创建的虚拟环境可能会出现各种不兼容的问题。
对于其它版本的ROS2,安装过程和使用方式基本相同。
在本章节以及本章后续的案例章节中,我们在合适的场合将用ROS2,Ubuntu和Python来分别指代ROS2 Foxy Fitzroy,Ubuntu Focal和Ubuntu Focal所带的Python 3.8。
本章节中的案例有参考ROS2的官方教程。这个官方教程讲解的非常详细,非常适合初学者入门ROS2。
安装ROS2 Foxy Fitzroy
在Ubuntu上安装ROS2相对简单,绝大多数情况跟随官方教程安装即可。
系统区域(locale)需要支持UTF-8
在开始安装之前,我们需要先确保我们Ubuntu系统的区域(locale)已经设置成了支持UTF-8的值。
我们可以通过locale命令来查看目前的区域(locale)设置。
如果LANG的值是以.UTF-8结尾的话,则代表系统已经是支持UTF-8的区域(locale)设置了。
否则,可以使用下面的命令来将系统的区域(locale)设置为支持UTF-8的美式英语。
想设置成其它语言只需更改相应的语言代码即可。
sudo apt update && sudo apt install locales
sudo locale-gen en_US en_US.UTF-8
sudo update-locale LC_ALL=en_US.UTF-8 LANG=en_US.UTF-8
export LANG=en_US.UTF-8
设置软件源
我们还需要将ROS2的软件源加入到系统中。我们可以通过下面这些命令完成这点。
sudo apt update && sudo apt install curl gnupg2 lsb-release
sudo curl -sSL https://raw.githubusercontent.com/ros/rosdistro/master/ros.key -o /usr/share/keyrings/ros-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/ros-archive-keyring.gpg] http://packages.ros.org/ros2/ubuntu $(source /etc/os-release && echo $UBUNTU_CODENAME) main" | sudo tee /etc/apt/sources.list.d/ros2.list > /dev/null
安装ROS2
现在我们可以开始安装ROS2了。我们可以先更新软件源缓存,然后再安装ROS2 Desktop版。这个版本包含了ROS2框架和大部分ROS2开发常用的软件库,如RViz等,因此是首选的版本。
sudo apt update
sudo apt install ros-foxy-desktop
另外,让我们再来安装两个额外的软件,colcon和rosdep。前者是ROS2的编译工具,后者可以帮助我们迅速安装一个ROS2工程所需的依赖库。
sudo apt-get install python3-colcon-common-extensions python3-rosdep
到此,我们已经安装好了ROS2。但是,如果想要使用它,我们还需要一个额外的环境设置步骤。
环境设置
对于任意安装好的ROS2(和ROS)版本,我们需要source对应的setup脚本来为对应的版本设置好所需环境,然后才能开始使用其版本。
例如,对于刚安装好的ROS2 Foxy Fitzroy,我们可以在终端中执行下面的命令来设置好ROS2所需的环境。
source /opt/ros/foxy/setup.bash
如果你用的是bash以外的shell,你可以尝试将setup的文件扩展名改为对应shell的名字。例如zsh的用户可以尝试使用source /opt/ros/foxy/setup.zsh命令。
如果你不想每次使用ROS2之前都要输入上述命令,可以尝试将这条命令加入到你的.bashrc文件中去(或者是.zshrc或其它对应的shell文件)。这样,你以后的每个新命令行终端都会自动设置到ROS2所需的环境。
这种环境设置方式的好处在于你可以放心的安装多个不同版本的ROS2(和ROS),然后只需在需要时source对应版本的setup.bash文件,从而使用这个版本的ROS2并不受其它版本的干扰。
如果你是一个Python的重度用户,上面这种将setup.bash加入到.bashrc的方式可能会对你造成一些困扰。因为你的所有virtual env从此都会自动引入ROS2的环境设置,并且ROS2所包含的python libraries也会加入到你的virtual env的路径里面去。
我相信,你可能对于virtual env会检测到ROS2的库这种情况不会感到特别开心,即使这些库并不会被用到或破坏你virtual env中程序的运行。
解决这个问题的方法也很简单。当你准备主要用Python来开发一个ROS2项目时,你可以为这个项目新建一个virtual env,然后将source /opt/ros/foxy/setup.bash这条命令加入到这个virtual env的activate脚本中去。
注意!你可能需要将这条source命令添加到脚本结尾前一些的位置或脚本最开头,要不然当你进入(activate)virtual env时你有可能会遇到下面这个错误(例如,对于pipenv的用户就需要添加到脚本结尾处的hash -r 2>/dev/null这条命令之前而不是最末尾)。
Shell for UNKNOWN_VIRTUAL_ENVIRONMENT already activated.
No action taken to avoid nested environments.
测试安装成功
当我们执行了上述的source命令之后,我们可以测试ROS2的安装以及环境设置时成功的。
我们只需在执行了source命令的命令行中执行printenv | grep -i ^ROS。输出的结果应该包含以下三个环境变量。
ROS_VERSION=2
ROS_PYTHON_VERSION=3
ROS_DISTRO=foxy
此外,我们可以新开两个执行了source命令的终端窗口,然后分别执行以下两条命令。
终端1:
ros2 run demo_nodes_cpp talker
终端2:
ros2 run demo_nodes_py listener
如果成功安装并执行了source命令的话,我们将会看到talker显示它正在发布消息,同时listener显示它听到了这些消息。
恭喜!您已经成功安装好了ROS2并配置到了环境。下面我们将会通过几个简单的案例来展示上章节中介绍过的ROS2的核心概念。
ROS2节点和Hello World
在这一小节中,我们将会创建一个ROS2项目,并使用Python来编写一个Hello World案例,以便展示ROS2 Node的基本结构。
新建一个ROS2项目
首先,在一个合适的位置新建一个文件夹。这个文件夹将是我们ROS2项目的根目录,同时也是上一章节中介绍过的“工作区”(Workspace)。这个工作区是我们自己创建的,所以它是一个Overlay Workspace。相对的,我们之前执行的source命令会帮我们准备好这个Overlay所基于的核心工作区(Underlay Workspace)。
假设我们创建了名为openmlsys-ros2的工作区。
mkdir openmlsys-ros2
cd openmlsys-ros2
然后让我们为这个工作区创建一个Python的虚拟环境(virtual env)并依照上面环境设置小节中所介绍的那样将source命令添加到虚拟环境对应的activate脚本中去。
我们默认之后所有案例章节的命令都是在这个新建的虚拟环境中执行的。
不同的虚拟环境管理工具会有不同的指令,因此这一步笔者没有提供可执行命令的示例,而是留给读者自行处理。
接下来,我们要在这个工作区文件夹内新建一个名为src的子文件夹。在这个子文件夹内,我们将会创建不同的ROS2的程序库(package)。这些程序库相互独立,但又会互相调用其他库的功能来达成整个ROS2项目想要达成的各种目的。
在创建好src文件夹后,我们可以尝试调用colcon build命令。colcon是ROS2项目常用的一个编译工具(build tool)。这个命令会尝试编译整个ROS2项目(即目前工作区内的所有的程序库)。在成功运行完命令后,我们可以发现工作区内多出了三个新文件夹:build,install和log。其中build内是编译过程的中间产物,install内是编译的最终产物(即编译好的库),而log内是编译过程的日志。
到此,我们已经新建好了一个ROS2项目的框架,可以开始编写具体的代码了。
新建一个ROS2框架下的Python库
下面,让我们在src文件夹内新建一个ROS2的程序库。我们将在这个程序库内编写我们的Hello World案例。
cd src
ros2 pkg create --build-type ament_python --dependencies rclpy std_msgs --node-name hello_world_node my_hello_world
ros2命令的pkg create子项可以帮助我们快速的创建一个ROS2程序库的框架。build-type参数指明了这是一个纯Python库,dependencies参数指明了这个库将会使用rclpy和std_msgs这两个依赖库,node-name参数指明了我们创建的程序库中会有一个名为hello_world_node的ROS2节点,而最后的my_hello_world则是新建程序库的名字。
进入新建好的程序库文件夹my_hello_world,我们可以看到刚运行的命令已经帮我们建好一个Python库文件夹my_hello_world。其与程序库同名,且内含__init__.py文件和hello_world_node.py文件。后者的存在是由于我们使用了node_name参数的原因。我们将在这个Python库文件夹内编写我们的Python代码。
除此之外,还有resource和test这两个文件夹。前者帮助ROS2来定位Python程序库,因此我们不需要管它。后者用来包含所有的测试代码,并且我们可以看到里面已经有了三个测试文件。
除了这三个文件夹外,还有三个文件,package.xml,setup.cfg和setup.py。
package.xml是ROS2程序库的标准配置文件。打开后我们可以发现很多内容已经预生成好了,但是我们还需填写或更新version,description,maintainer和license这几项的内容。在此笔者推荐大家每次新建一个ROS2库的时候都第一时间将这些信息补全。除了这些项,我们还能看到rclpy和std_msgs已经被列为依赖库了,这是因为我们使用了dependencies参数的原因。如果我们要添加或修改依赖库,可以直接在package.xml内的depend列表处修改。除了最常用的depend(同时针对build,export和execution),我们还有build_depend,build_export_depend,exec_depend,test_depend,buildtool_depend和dec_depend。关于package.xml的具体介绍可以参考此英文Wiki Page。
setup.cfg和setup.py都是Python库的相关文件,但是ROS2也会通过这两个文件来了解怎么安装这个Python库至install文件夹以及有哪些需要注册的entry points,即可以直接用ROS2命令行命令来直接调用的程序。我们可以看到在setup.py中的entry_points项的console_scripts子项中已经将hello_world_node这个名字设置为my_hello_world/hello_world_node.py这个Python文件中main()函数的别名。我们后续就可以使用ROS2命令行命令和这个名字来直接调用这个函数。具体方式如下:
# ros2 run <package_name> <entry_point>
ros2 run my_hello_world hello_world_node
后续如果需要添加新的entry point的话可以直接在此位置添加。
除了entry point需要关注之外,我们也需要及时将setup.py中的version,maintainer,maintainer_email,description和license项都更新好。
第一个ROS2节点
让我们打开my_hello_world/hello_world_node.py这个Python文件,清空里面全部内容,以便于编写我们需要的代码。
首先,让我们引入必要的库:
import rclpy
from rclpy.node import Node
from std_msgs.msg import String
rclpy(ROS Client Library for Python)让我们能够通过Python来使用ROS2框架内的各种功能。而Node类则是所有ROS2节点的基类(Base Class),我们的节点类也需要继承这个基类。std_msgs则包含了ROS2预定义的一些用于框架内通信的标准信息格式,我们需要使用String这种消息格式来传递字符串信息。
接下来让我们定义我们自己的ROS2节点:
class HelloWorldNode(Node):
def __init__(self):
super().__init__('my_hello_world_node')
self.msg_publisher = self.create_publisher(String, 'hello_world_topic', 10)
timer_period = 1.
self.timer = self.create_timer(timer_period, self.timer_callback)
self.count = 0
def timer_callback(self):
msg = String()
msg.data = f'Hello World: {self.count}'
self.msg_publisher.publish(msg)
self.get_logger().info(f'Publishing: "{msg.data}"')
self.count += 1
如上所述,我们的节点类HelloWorldNode继承于Node基类。
在__init__()方法中,我们先调用基类的初始化方法,并通过这个调用将我们的节点命名为my_hello_world_node。接着我们创建一个信息发布者,它可以将字符串类型的信息发布到hello_world_topic这个主题上,并且会维持一个大小为10的缓冲区。再接着我们创建一个计时器,它会每秒钟调用一次timer_callback()方法。最后,我们初始化一个计数器,来统计总共有多少条信息被发布了。
在timer_callback()方法中,我们简单的创建一条带计数器的Hello World信息,并通过信息发布者发送出去。然后我们在日志中记录这次操作并将计数器加一。
定义好我们的HelloWorldNode类后,我们可以开始定义main()函数。这个函数就是我们之前在setup.py中看到的那个entry point。
def main(args=None):
rclpy.init(args=args)
hello_world_node = HelloWorldNode()
rclpy.spin(hello_world_node)
hello_world_node.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
这个main()也比较简单。我们先通过rclpy.init()方法来启动ROS2框架。然后我们创建一个HelloWorldNode的实例。接着我们通过rclpy.spin()方法将这个实例加入到运行的ROS2框架中去,让其参与ROS2的事件循环并正确运行。rclpy.spin()是一个阻碍方法,它会一直运行一直到被阻止(例如ROS2框架停止运行)。这时候我们就会摧毁我们的节点,并且确保关闭ROS2框架。如果我们忘记了摧毁不再使用的节点,不用慌,garbage collector也会帮忙摧毁这个节点。
到此,我们创建了第一个ROS2节点!
第一次编译和运行
让我们尝试编译新编写的这个库。这里,我们并不是真的要编译一个Python项目,而是将我们写的Python库安装到一个ROS2能找到的地方。
# cd <workspace>
cd openmlsys-ros2
colcon build --symlink-install
通过在运行这个编译命令,我们会编译工作区内src文件夹下所有的Python和C++库,并将编译好的C++库和Python库安装到install文件夹下。
通过指定--symlink-install这个选项,我们要求colcon对于Python库用生成symlink的方式来代替复制安装。这样一来,我们在src中做的后续改动都会直接反应到install中去,而不用一直反复执行编译命令。
在编译成功之后,编译好的库还不能直接使用。例如你现在执行ros2 run my_hello_world hello_world_node的话很有可能会得到Package 'my_hello_world' not found这样一个结果。
为了使用编译好的库,我们需要让ROS2知道install文件夹。具体来说,我们需要source在install文件夹下的local_setup.bash文件。即:
source install/local_setup.bash
有些机敏的读者可能会想到我们可以像之前添加那个setup.bash一样将这个install/local_setup.bash也加入到虚拟环境的activate脚本中去,这样我们就不用每次都单独source这个文件了。很可惜,这样会带来一些问题。
具体来说,一方面我们需要将这两个文件都source了(不管是通过activate脚本还是手动输入)才能顺利运行编译好的ROS2程序,但另一方面我们必须只source第一个setup.bash而不source第二个local_setup.bash才能顺利编译带有C++依赖项的纯Python的ROS2库。
在稍后面一点的案例中我们会看到,对于一个使用了自定义消息接口库(自己编写的C++库)的纯Python的ROS2程序库来说,必须只source第一个setup.bash而不source第二个local_setup.bash才能顺利编译。
在成功source了install/local_setup.bash之后,我们就可以尝试调用写好的节点了。
从现在开始,除非特殊说明,新开一个终端窗口都是指新开一个确保setup.bash和install/local_setup.bash都已经被source了的终端窗口,而在工作区执行colcon build命令则都是在一个只source了setup.bash而忽略了install/local_setup.bash的终端窗口中执行此编译命令。
ros2 run my_hello_world hello_world_node
我们应该会看到类似下面这样的信息:
[INFO] [1653270247.805815900] [my_hello_world_node]: Publishing: "Hello World: 0"
[INFO] [1653270248.798165800] [my_hello_world_node]: Publishing: "Hello World: 1"
我们还可以再新开一个终端窗口,然后执行ros2 topic echo /hello_world_topic。我们应该能看到类似下面的信息:
data: 'Hello World: 23'
---
data: 'Hello World: 24'
---
这代表着我们的信息确实被发布到了目标主题上。因为ros2 topic echo <topic_name>这条命令输出的就是给定名字的主题所接收到的信息。
恭喜!您已成功运行了您的第一个ROS2节点!
一个消息订阅者节点
只是发布消息并不能组成一个完整的流程,我们还需要一个消息订阅者来消费我们发布的信息。
让我们在hello_world_node.py所在的文件夹内新建一个名为message_subscriber.py的文件,并添加以下内容:
import rclpy
from rclpy.node import Node
from std_msgs.msg import String
class MessageSubscriber(Node):
def __init__(self):
super().__init__('my_hello_world_subscriber')
self.msg_subscriber = self.create_subscription(
String, 'hello_world_topic', self.subscriber_callback, 10
)
def subscriber_callback(self, msg):
self.get_logger().info(f'Received "{msg.data}"')
def main(args=None):
rclpy.init(args=args)
message_subscriber = MessageSubscriber()
rclpy.spin(message_subscriber)
message_subscriber.destroy_node()
rclpy.shutdown()
if __name__ == "__main__":
main()
这个新添加的文件以及其中的消息订阅者节点类和上面的HelloWorldNode类十分相似,甚至更为简单些。我们只需要在初始化时通过基类初始化方法赋予节点my_hello_world_subscriber这个名字,然后创建一个消息订阅者来订阅hello_world_topic主题下的消息,并指定subscriber_callback()方法来处理接收到的消息。而在subscriber_callback()中,我们将接收到的消息记录进日志。main()方法则和HelloWorld节点类的基本一样。
在能正式使用这个新节点之前,我们需要将其添加成为一个entry point。为此,我们只需在setup.py的对应位置添加下面这行:
'message_subscriber = my_hello_world.message_subscriber:main'
但是,添加完成之后在终端窗口运行ros2 run my_hello_world message_subscriber还是会得到No executable found这样的错误反馈。这是因为我们新增了一个entry point,必须重新编译整个ROS2项目才能让ROS2知道这个新增点。
让我们再次在工作区目录执行colcon build --symlink-install。在成功编译后,让我们新建两个终端窗口,都分别确保source好了两个setup文件。然后分别用ros2命令调用它们:
# in terminal 1
ros2 run my_hello_world hello_world_node
# in terminal 2
ros2 run my_hello_world message_subscriber
我们应该可以看到终端窗口1中会不断显示发布了第N号Hello World消息,而终端窗口2中则不断显示收到了第N号Hello World消息。
恭喜!你完成了一对ROS2节点,一个负责发送信息,一个负责订阅接受信息。
ROS2参数
顺利完成上面的消息发布者和消息订阅者是个很好的开始,但是实际项目的节点不会这么简单。 至少,实际项目的节点会是参数化的。下面,就让我们一起看看怎样让一个节点读取一个参数。
让我们在hello_world_node.py所在的文件夹内新建一个名为parametrised_hello_world_node.py的文件,并添加以下内容:
import rclpy
from rclpy.node import Node
from std_msgs.msg import String
class ParametrisedHelloWorldNode(Node):
def __init__(self):
super().__init__('parametrised_hello_world_node')
self.msg_publisher = self.create_publisher(String, 'hello_world_topic', 10)
timer_period = 1.
self.timer = self.create_timer(timer_period, self.timer_callback)
self.count = 0
self.declare_parameter('name', 'world')
def timer_callback(self):
name = self.get_parameter('name').get_parameter_value().string_value
msg = String()
msg.data = f'Hello {name}: {self.count}'
self.msg_publisher.publish(msg)
self.get_logger().info(f'Publishing: "{msg.data}"')
self.count += 1
def main(args=None):
rclpy.init(args=args)
hello_world_node = ParametrisedHelloWorldNode()
rclpy.spin(hello_world_node)
hello_world_node.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
我们可以看到,这个新的参数化HelloWorld节点类和之前的HelloWorld节点类基本相同。
唯二的区别在于:1)这个新类在初始化方法中额外通过self.declare_parameter()方法来向ROS2框架声明新的节点实例会有一个名为name的参数,并且这个参数的初始值为world;2)这个新类在timer_callback()回调函数中尝试获取这个name参数的实际值,并以这个实际值来组成要发送的信息的内容。
让我们先将这个新文件的main()方法注册为一个新的entry point。
同样的,在setup.py中的相应位置加入下面这行即可。
然后别忘了在工作区根目录下执行colcon build --symlink-install来重新编译项目。
'parametrised_hello_world_node = my_hello_world.parametrised_hello_world_node:main'
在编译完成之后,如果我们在终端中执行ros2 run my_hello_world parametrised_hello_world_node,我们将看到这个参数化HelloWorld节点将正常运行,并持续发布“Hello World: N“这样的信息。此时节点使用的是world这个初始值。
让我们在一个新的终端中执行ros2 param list,我们将看到下面的信息:
/parametrised_hello_world_node:
name
use_sim_time
这个信息表示parametrised_hello_world_node这个节点的确申明并使用一个name参数。
另外一个名为use_sim_time的参数是ROS2默认给与的一个参数,用来表示这个节点是否使用ROS2框架内部的模拟时间,而不是电脑的系统时间。
我们可以继续在这个终端中输入下面这个命令来将值ROS2赋予给name这个参数。
ros2 param set /parametrised_hello_world_node name "ROS2"
如果赋值成功的话,这个命令会返回Set parameter successful,并且我们可以在持续运行参数化HelloWorld节点的那个终端窗口内看到其发布的信息变为了“Hello ROS2: N“。
恭喜!你现在掌握了如何让ROS2节点(和其它类型的ROS2程序)使用参数的方法。
服务端-客户端服务模式
在上一章节中我们知道了ROS2框架除了发布者-订阅者这种通信模式,还有服务端-客户端这种模式。 在这一小节中,我们将通过一个简单的串联两个字符串的服务来演示如何使用这种模式。
自定义的服务接口
在正式开始编写服务端和客户端的代码之前,我们需要先定义好它们之间进行沟通的信息接口。
ROS2框架内有三种类型的信息接口:
- 发布者-订阅者模式下的节点所用的消息类型接口(message/msg):这种接口只负责单向的消息传递,也只用定义单向传递的信息的格式。
- 服务端-客户端模式下的服务节点所用的服务类型接口(service/srv):这种接口需要负责双向的消息传递,即需要定义客户端发给服务端的请求的格式和服务端发给客户端的响应的格式。
- 动作模式下的动作节点所用的动作类型接口(action):这种接口需要负责双向的消息传递以及中间的进展反馈,即需要定义动作发起节点发给动作节点的请求的格式,动作节点发给发起节点的结果的格式,以及动作节点发给发起节点的中间进展反馈的格式。
对于前面定义的那些HelloWorld节点,我们使用的是已经预定义好的std_msgs库内的std_msgs.msg.String类型的消息类型接口。
实际上,因为消息类型接口只负责定义单向的信息格式,我们很容易找到现成的符合我们需求的类型。
但是对于服务(service)和动作(action)来说,因为涉及到定义双向沟通的格式,很多时候我们需要自己定义一个接口类型。接下来,就让我们自行定义我们的字符串串联服务将要使用的服务类型接口。
首先,让我们在工作区的src文件夹内新建一个库来专门维护自定义的消息,服务和动作类型接口。
cd openmlsys-ros2/src
ros2 pkg create --build-type ament_cmake my_interfaces
这个新建的库是一个C++库,而不是Python库。这是因为ROS2的自定义接口类型只能以C++库的方式存在。新建好库之后,记得更新package.xml中的相关项。
下面,让我们在新建的src/my_interfaces文件夹内新建三个子文件夹:msg,srv和action。这是因为一般会将自定义的接口放到相对应的子文件夹中去,以方便维护。
cd my_interfaces
mkdir msg srv action
接着,让我们在srv子目录下创建我们想要定义的服务类型接口。
cd srv
touch ConcatTwoStr.srv
然后,让我们将以下内容添加到ConcatTwoStr.srv中去:
string str1
string str2
---
string ret
其中,---之上的是客户端发给服务端的请求的格式,而之下的是服务端发给客户端的响应的格式。
定义好了接口后,我们还需要更改CMakeLists.txt以便让编译器知道有自定义接口需要编译并能找到它们。让我们打开my_interfaces/CMakeLists.txt并在if(BUILD_TESTING)这行之前添加下面的内容。
find_package(rosidl_default_generators REQUIRED)
rosidl_generate_interfaces(${PROJECT_NAME}
"srv/ConcatTwoStr.srv"
)
上面这两段代码的主要作用是告诉编译器需要rosidl_default_generators这个库并生成我们指明的自定义接口。
在更新好CMakeLists.txt之后,我们还需要把rosidl_default_generators添加到package.xml中作为自定义接口库的依赖项。打开package.xml,在<test_depend>ament_lint_auto</test_depend>这行前添加下面内容。
<build_depend>rosidl_default_generators</build_depend>
<exec_depend>rosidl_default_runtime</exec_depend>
<member_of_group>rosidl_interface_packages</member_of_group>
更新好package.xml后,我们就可以编译这个自定义接口库了。
cd openmlsys-ros2
colcon build --packages-select my_interfaces
上述命令中我们通过--packages-select选项指定了只编译my_interfaces这一个库从而节省时间,因为my_hello_world这个库目前并没有任何更改。另外,我们没有使用--symlink-install选项是因为这个自定义接口库是一个C++库,每次更改后必须重新编译。
在运行这次的编译命令时,读者有可能会遇到ModuleNotFoundError: No module named 'XXX'这类的错误(XXX可以是em,catkin_pkg,lark,numpy或其它Python库)。
遇到这类错误多半是因为所使用的Python虚拟环境并不是指向Ubuntu系统Python3或site-packages并没有被包含在虚拟环境中。
读者可能需要删除当前的虚拟环境并按照本章节开头所讲解的那样重新创建一个符合要求的虚拟环境。
我们可以通过在新的终端窗口运行ros2 interface show my_interfaces/srv/ConcatTwoStr来验证是否已经编译成功了。成功的话终端会显示自定义服务接口ConcatTwoStr的具体定义。
现在,我们定义好了需要使用的服务接口,下面可以开始编写我们的服务端和客户端了。
ROS2服务端
让我们在hello_world_node.py所在的文件夹内新建一个名为concat_two_str_service.py的文件,并添加以下内容:
from my_interfaces.srv import ConcatTwoStr
import rclpy
from rclpy.node import Node
class ConcatTwoStrService(Node):
def __init__(self):
super().__init__('concat_two_str_service')
self.srv = self.create_service(ConcatTwoStr, 'concat_two_str', self.concat_two_str_callback)
def concat_two_str_callback(self, request, response):
response.ret = request.str1 + request.str2
self.get_logger().info(f'Incoming request\nstr1: {request.str1}\nstr2: {request.str2}')
return response
def main(args=None):
rclpy.init(args=args)
concat_two_str_service = ConcatTwoStrService()
rclpy.spin(concat_two_str_service)
concat_two_str_service.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
我们可以发现,编写一个服务(Service)和编写一个一般的节点(Node)很相似,甚至它们都是继承自同一个基类rclpy.node.Node。在这个文件中,我们先从编译好的my_interfaces库中引入自定义的服务接口ConcatTwoStr。然后在服务端节点的初始化方法中通过self.create_service()创建一个服务器对象,并指明服务接口类型是ConcatTwoStr,服务名字是concat_two_str,处理服务请求的回调函数是self.concat_two_str_callback。而在回调函数self.concat_two_str_callback()中,我们通过request对象取得请求的str1和str2,计算出结果并赋值到response对象的ret上,并进行日志记录。我们可以看到,request和response对象的结构符合我们在ConcatTwoStr.srv中的定义。
另外别忘记了将此文件的main()方法作为一个entry point添加到setup.py中去。
'concat_two_str_service = my_hello_world.concat_two_str_service:main'
ROS2客户端
让我们在hello_world_node.py所在的文件夹内新建一个名为concat_two_str_client_async.py的文件,并添加以下内容:
import sys
from my_interfaces.srv import ConcatTwoStr
import rclpy
from rclpy.node import Node
class ConcatTwoStrClientAsync(Node):
def __init__(self):
super().__init__('concat_two_str_client_async')
self.cli = self.create_client(ConcatTwoStr, 'concat_two_str')
while not self.cli.wait_for_service(timeout_sec=1.0):
self.get_logger().info('service not available, waiting again...')
self.req = ConcatTwoStr.Request()
def send_request(self):
self.req.str1 = sys.argv[1]
self.req.str2 = sys.argv[2]
self.future = self.cli.call_async(self.req)
def main(args=None):
rclpy.init(args=args)
concat_two_str_client_async = ConcatTwoStrClientAsync()
concat_two_str_client_async.send_request()
while rclpy.ok():
rclpy.spin_once(concat_two_str_client_async)
if concat_two_str_client_async.future.done():
try:
response = concat_two_str_client_async.future.result()
except Exception as e:
concat_two_str_client_async.get_logger().info(
'Service call failed %r' % (e,))
else:
concat_two_str_client_async.get_logger().info(
'Result of concat_two_str: (%s, %s) -> %s' %
(concat_two_str_client_async.req.str1, concat_two_str_client_async.req.str2, response.ret))
break
concat_two_str_client_async.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
相比于服务端,这个客户端较为复杂一点。在客户端节点的初始化方法中,我们先创建一个客户端对象,并指明服务接口类型是ConcatTwoStr,服务名字为concat_two_str。然后通过一个while循环,这个客户端将一直等待知道对应服务上线才会进行下一步。这个循环等待的技巧是很多客户端都会使用的。当服务端上线以后,初始化方法将创建一个服务请求对象的模板并暂存于客户端节点的req属性上。除了初始化方法,客户端节点还定义了另一个方法send_request()来读取程序启动时命令行的前两个参数,然后存入服务请求对象并异步发送给服务端。
而在main()方法中,我们先创建一个客户端并发送服务请求,然后通过一个while循环来等待服务返回结果并记录进日志。其中,rclpy.ok()是用来检测ROS2是否还在正常运行,以保证当ROS2在服务结束前就停止运行了的话,客户端这边不会陷入死循环。而rclpy.spin_once()和rclpy.spin()略有不同,后者会不断执行事件循环直到ROS2停止,而前者则只会执行一次事件循环。这也是为什么前者更适合用在这里,因为我们已经有了一个while循环了。另外我们可以看到,concat_two_str_client.future对象提供了很多方法来帮助我们确定目前服务请求的状态。
同样的,别忘记了将此文件的main()方法作为一个entry point添加到setup.py中去。
'concat_two_str_client_async = my_hello_world.concat_two_str_client_async:main'
我们现在编写好了我们的服务端和客户端,让我们在工作区根目录下重新编译一边my_hello_world库。
cd openmlsys-ros2
colcon build --packages-select my_hello_world --symlink-install
然后让我们在两个新的终端窗口中分别运行以下命令。
# in terminal 1
ros2 run my_hello_world concat_two_str_client_async Hello World
# in terminal 2
ros2 run my_hello_world concat_two_str_service
如果一切正常的话,我们应该看到类似以下的信息。
# in terminal 1
[INFO] [1653525569.843701600] [concat_two_str_client_async]: Result of concat_two_str: (Hello, World) -> HelloWorld
# in terminal 2
[INFO] [1653516701.306543500] [concat_two_str_service]: Incoming request
str1: Hello
str2: World
恭喜!您现在已经了解如何在ROS2框架中新建自定义的接口类型和创建服务端节点和客户端节点了!
动作模式
在上一章节中我们了解了ROS2框架内的服务端-客户端模式。这样一来,我们只剩下动作(action)这一种模式了。 在这一小节中,我们将通过一个简单的逐个累加一个数列的每项元素来求和的动作来演示如何使用这种模式。
自定义的动作接口
在正式开始编写动作相关的节点代码之前,我们需要先定义好动作的信息接口。
我们可以继续使用之前建好的my_interfaces库。
让我们在my_interfaces/action中新建一个MySum.action文件,并添加以下内容。
# Request
int32[] list
---
# Result
int32 sum
---
# Feedback
int32 sum_so_far
可以看到,整个信息接口十分简单。动作的请求信息只有一项类型为整数数列的项list,动作的最终结果信息只有一项类型为整数的项sum``,而中间反馈信息则只有一项类型同为整数的项sum_so_far`,用以计算到目前位置累加的和。
接下来,让我们在CMakeLists.txt中添加这个新的信息接口。具体来说只用将"action/MySum.action"添加到rosidl_generate_interfaces()方法内的"srv/ConcatTwoStr.srv"之后即可。
最后别忘了编译所做的更改:在工作区根目录中运行colcon build --packages-select my_interface。
ROS2动作服务器
让我们在hello_world_node.py所在的文件夹内新建一个名为my_sum_action_server.py的文件,并添加以下内容:
import rclpy
from rclpy.action import ActionServer
from rclpy.node import Node
from my_interfaces.action import MySum
class MySumActionServer(Node):
def __init__(self):
super().__init__('my_sum_action_server')
self._action_server = ActionServer(
self, MySum, 'my_sum', self.execute_callback
)
def execute_callback(self, goal_handle):
self.get_logger().info('Executing goal...')
feedback_msg = MySum.Feedback()
feedback_msg.sum_so_far = 0
for elm in goal_handle.request.list:
feedback_msg.sum_so_far += elm
self.get_logger().info(f'Feedback: {feedback_msg.sum_so_far}')
goal_handle.publish_feedback(feedback_msg)
goal_handle.succeed()
result = MySum.Result()
result.sum = feedback_msg.sum_so_far
return result
def main(args=None):
rclpy.init(args=args)
my_sum_action_server = MySumActionServer()
rclpy.spin(my_sum_action_server)
if __name__ == '__main__':
main()
对于这个动作服务器节点类,类似的,我们还是在其初始化方法中新建一个动作服务器对象,并指定了之前定义的MySum作为信息接口类型,my_sum是动作名字,self.execute_callback方法则作为动作执行的回调函数。
紧接着,我们在self.execute_callback()方法中定义了当接收到了一个新目标是应做什么处理。在这里,我们可以把一个目标当作之前定义的MySum信息接口里的request部分来处理,因为这里的目标就是包含了动作请求的目的的相关信息的结构体,即request部分所定义的部分。
当我们接收到一个目标后,我们先从MySum创建一个反馈消息对象feedback_msg,并将其sum_so_far项用作一个累加器。然后我们遍历目标请求中的list项里面的数据,并这些数据逐项进行累加。每当我们累加一项后,我们都会通过goal_handle.publish_feedback()方法发送一次反馈消息。最后,当全部计算完成后,我们通过goal_handle.succeed()来标记此次动作已经成功完成,并且通过MySum新建一个结果对象,填充结果值并返回。
在main()函数中,我们只需要新建一个动作服务器节点类的新实例,并调用rclpy.spin()将其加入事件循环即可。
最后别忘了将main()也添加成为一个entry point。我们只需在setup.py中适当位置添加下面行即可。
'my_sum_action_server = my_hello_world.my_sum_action_server:main'
ROS2动作客户端
让我们在hello_world_node.py所在的文件夹内新建一个名为my_sum_action_client.py的文件,并添加以下内容:
import sys
import rclpy
from rclpy.action import ActionClient
from rclpy.node import Node
from my_interfaces.action import MySum
class MySumActionClient(Node):
def __init__(self):
super().__init__('my_sum_action_client')
self._action_client = ActionClient(self, MySum, 'my_sum')
def send_goal(self, list):
goal_msg = MySum.Goal()
goal_msg.list = list
self._action_client.wait_for_server()
self._send_goal_future = self._action_client.send_goal_async(
goal_msg, feedback_callback=self.feedback_callback
)
self._send_goal_future.add_done_callback(self.goal_response_callback)
def goal_response_callback(self, future):
goal_handle = future.result()
if not goal_handle.accepted:
self.get_logger().info('Goal rejected...')
return
self.get_logger().info('Goal accepted.')
self._get_result_future = goal_handle.get_result_async()
self._get_result_future.add_done_callback(self.get_result_callback)
def get_result_callback(self, future):
result = future.result().result
self.get_logger().info(f'Result: {result.sum}')
rclpy.shutdown()
def feedback_callback(self, feedback_msg):
feedback = feedback_msg.feedback
self.get_logger().info(f'Received feedback: {feedback.sum_so_far}')
def main(args=None):
rclpy.init(args=args)
action_client = MySumActionClient()
action_client.send_goal([int(elm) for elm in sys.argv[1:]])
rclpy.spin(action_client)
if __name__ == '__main__':
main()
我们可以看到,这个动作客户端节点类比上面的服务器节点类要稍许复杂些,这是因为我们要适当的处理发送请求,接受反馈和处理结果这三件事。
首先,还是类似的,我们在这个动作客户端节点类的初始化方法中新建一个动作客户端对象,并指定MySum作为消息接口类型和my_sum作为动作名称。
然后,我们申明self.send_goal()方法来负责生成并发送一个目标/请求。具体来说,我们先从MySum新建一个目标对象并将接收到的list参数赋值到目标对象的list属性上去。紧接着,让我们等待动作服务器准备就绪。当动作服务器准备就绪后,让我们异步发送目标并指定self.feedback_callback作为反馈信息回调函数。最后,我们设定self.goal_response_callback作为发送目标信息这个异步操作的回调函数。
在self.goal_response_callback()这个异步发送目标信息的回调函数中,我们先检查目标请求是否被接受了,并日志记录相关结果。如果目标请求被接受了的话,我们就通过goal_handle.get_result_async()来得到处理结果这个异步操作的future对象,并通过这个future对象将self.get_result_callback设定为最终结果的回调函数。
在self.get_result_callback()这个最终结果的回调函数中,我们就简单的获取累加结果并记录进日志。最后我们调用rclpy.shutdown()来结束当前节点。
相对的,在self.feedback_callback()这个反馈消息的回调函数中。我们仅仅简单的获取反馈信息的内容并记录进日志。值得注意的是,反馈消息的回调函数可能被执行多次,所以最好不要在其中写入太多的处理逻辑,而是尽量让其轻量化。
最后,在main()方法中,我们创建一个动作客户端节点类的实例,将命令行的参数转化为需要被求和的目标数列,最后调用动作客户端节点类实例的send_goal()方法并传入目标求和数列来发起求和请求。
同样的,别忘了将main()也添加成为一个entry point。我们只需在setup.py中适当位置添加下面行即可。
'my_sum_action_client = my_hello_world.my_sum_action_client:main'
我们现在编写好了我们的动作服务器和动作客户端,让我们在工作区根目录下重新编译一遍my_hello_world库。
cd openmlsys-ros2
colcon build --packages-select my_hello_world --symlink-install
然后让我们在两个新的终端窗口中分别运行以下命令。
# in terminal 1
ros2 run my_hello_world my_sum_action_client 1 2 3
# in terminal 2
ros2 run my_hello_world my_sum_action_server
如果一切正常的话,我们应该看到类似以下的信息。
# in terminal 1
[INFO] [1653561740.000499500] [my_sum_action_client]: Goal accepted.
[INFO] [1653561740.001171900] [my_sum_action_client]: Received feedback: 1
[INFO] [1653561740.001644000] [my_sum_action_client]: Received feedback: 3
[INFO] [1653561740.002327500] [my_sum_action_client]: Received feedback: 6
[INFO] [1653561740.002761600] [my_sum_action_client]: Result: 6
# in terminal 2
[INFO] [1653561739.988907200] [my_sum_action_server]: Executing goal...
[INFO] [1653561739.989213900] [my_sum_action_server]: Feedback: 1
[INFO] [1653561739.989549000] [my_sum_action_server]: Feedback: 3
[INFO] [1653561739.989855400] [my_sum_action_server]: Feedback: 6
恭喜!您现在已经了解如何在ROS2框架中新建自定义的接口类型和创建动作服务端节点和动作客户端节点了!
总结
总结
在这一章,我们简单介绍了机器人系统的基本概念,包括通用机器人操作系统、感知系统、规划系统和控制系统等,给读者对机器人问题的基本认识。对通用机器人操作系统部分,我们回顾了其中的基本概念,并通过代码实例让读者对ROS能有直接的体验,体会到搭建一个简单机器人系统的乐趣。当前,机器人是一个快速发展的人工智能分支,许多实际问题都需要通过机器人算法和系统设计的进一步发展得到解决。
附录:机器学习介绍
本书假设读者有一定的机器学习算法基础,因此本章只会简略地介绍一下机器学习,其中的梯度下降方法对本书机器学习系统来说尤为重要,是必须掌握的内容。
神经网络
神经网络
感知器
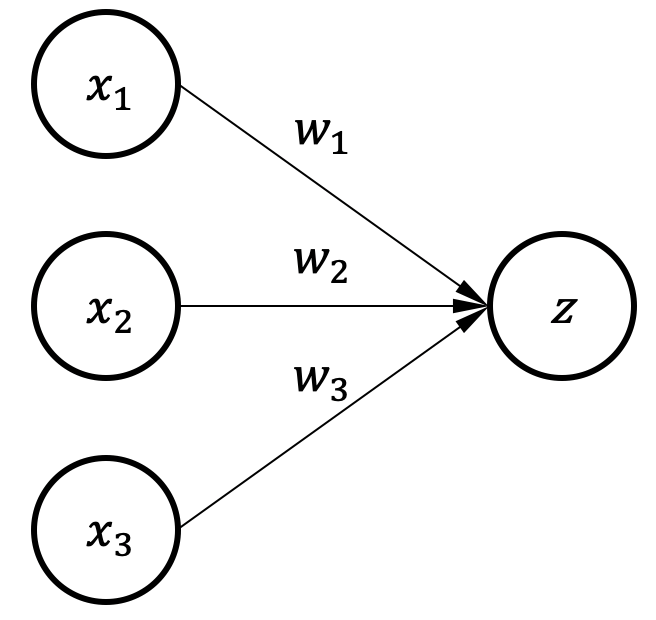
图17.1.1 有三个输入和单一输出的神经元
图17.1.1是一个神经元的例子,输入数据\(x\)根据连线上的权重\(w\)做加权求和得到输出\(z\),我们把这样的模型叫作感知器(Perceptron)。 因为输入和输出之间只有一层神经连接,这个模型也叫做单层感知器。 图17.1.1的模型计算可以写为:\(z = w_{1}x_{1}+ w_{2}x_{2} + w_{3}x_{3}\)。
当输入数据用列向量\({x}=[x_1,x_2,x_3]^T\)表示,模型权重用行向量\({w}=[w_1,w_2,w_3]\)表示,那么输出的标量\(z\)可以写为:
\[z = \begin{bmatrix} w_1,w_2,w_3\\ \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ x_3 \end{bmatrix} ={w}{x}\]
我们可以利用输出标量\(z\)为输入的加权组合来实现特定任务。 比如,可以对“好苹果“和“坏苹果“进行分类,输入的\(x_1,x_2,x_3\)分别代表三种不同的特征:1)红色的程度,2)有没有洞,3)大小。如果苹果的大小对这个判断没有影响,那么对应的权重就为零。 这个神经网络的训练,其实就是选择合适的权重,来实现我们的任务。比如我们可以选择合适的权重,使得当\(z\)小于等于\(0\)时代表“坏苹果“,而当\(z\)大于\(0\)时则是“好苹果“。 则最终的分类输出标签\(y\)如下,为\(1\)时代表好,\(0\)代表坏。这个神经元的输入和输出之间只有一层,所以可以成为单层神经网络。
\[ y = \begin{cases} 1 & z>0 \\ 0 & z \leq 0 \\ \end{cases}\]
决策边界vs.偏置
通过选择合适的权重以\(z\)大于或小于\(0\)来对输入数据做分类的话,可以在数据空间上获得一个决策边界 (Decision Boundary)。如 single_neuron_decision_boundary2所示,以神经元输出\(z=0\)作为输出标签\(y\)的决策边界, 没有偏置时决策边界必然经过坐标原点,如果数据样本点不以原点来分开,会导致分类错误。 为了解决这个问题,可以在神经元上加入一个偏置(Bias)。 图17.1.2 是一个有偏置\(b\)的神经元模型,可以用 (1)表达: \[z = w_{1}x_{1}+ w_{2}x_{2}+ w_{3}x_{3} + b\tag{1}\label{singleneuron_bias}\]
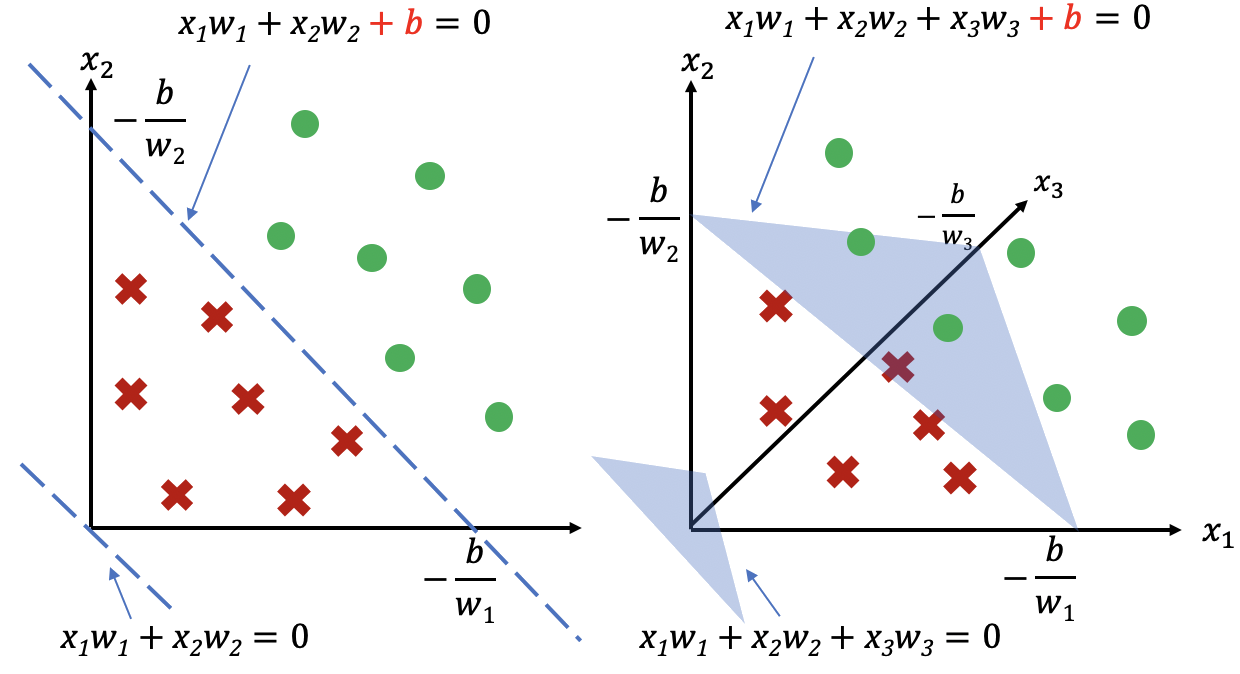
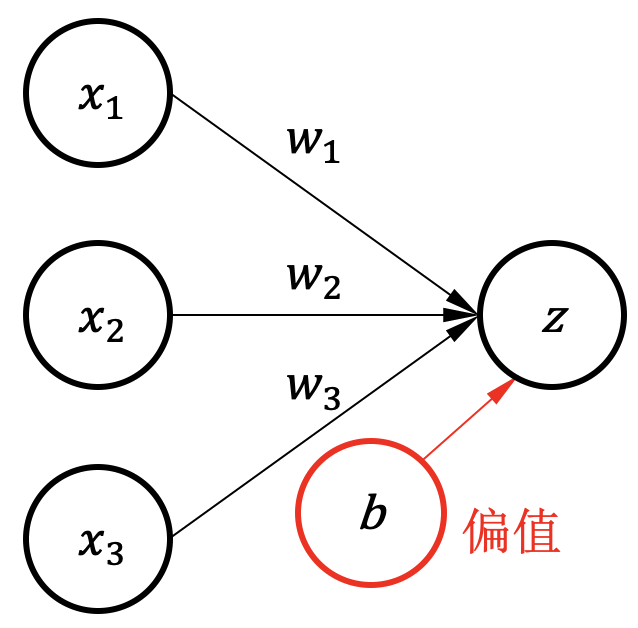
图17.1.2 一个有偏置的单层神经网络
有了偏置以后,决策边界(直线、平面或超平面)可以不经过坐标原点,因此能更好地分类样本。 准确来说,决策边界把这些样本数据分成两个不同的类别,这个边界是 \({x_1, x_2, x_3 | w_{1}x_{1}+ w_{2}x_{2}+ w_{3}x_{3} + b = 0}\)。
逻辑回归
上述神经元的输入和输出是线性关系,为了提供非线性的数据表达能力,可以在神经元输出上加上激活函数(Activation Function),最常见的激活函数有Sigmoid、Tanh、ReLU和Softmax等。 比如,上述神经元以\(z=0\)为分界来做分类任务,那么我们可不可以让神经元输出一个概率呢?比如输出\(0~1\),\(1\)代表输入数据\(100%\)为某一类。 为了让神经元输出\(0~1\),可以在\(z\)上加一个逻辑函数Sigmoid, 如 (2)所示,Sigmoid把数值限制在0和1之中,通过一个简单的临界值(如:0.5)来决定最终输出的标签是否属于某个类别。这个方法叫做逻辑回归(Logistic Regression)。
\[a = f({z}) = \frac{1}{1+{\rm e}^{-{z}}}\tag{2}\label{sigmoid}\]
多个神经元
图17.1.3 多个神经元
上述网络只有一个输出,若多个神经元在一起就可以有多个输出。 图17.1.3是有两个输出的网络,每个输出都和所有输入相连,所以也被称全连接层(Fully-Connected(FC) Layer), 可由下述式子 (3)表示X。
\[z_{1} &= w_{11}x_{1} + w_{12}x_{2} + w_{13}x_{3} + b_1 \notag \\ z_{2} &= w_{21}x_{1} + w_{22}x_{2} + w_{23}x_{3} + b_2\tag{3}\label{fc_cal}\]
如下式子表示了矩阵方法的实现:
\[ {z} = \begin{bmatrix} z_1 \\ z_2 \end
\begin{bmatrix} w_{11} & w_{12} & w_{13}\\ w_{21} & w_{22} & w_{23}\\ \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ x_3 \end{bmatrix} + \begin{bmatrix} b_1 \\ b_2 \end{bmatrix} = {W}{x} + {b}\]
多输出的网络可以实现多分类问题,比如有10个数值输出,每个数值分别代表一类物品的概率,每个输出在\(0\)到\(1\)之间,10个输出之和为\(1\)。 可用 (4)的Softmax 函数来实现,\(K\)为输出的个数:
\[f({z})_{i} = \frac{{\rm e}^{z_{i}}}{\sum_{k=1}^{K}{\rm e}^{z_{k}}}\tag{4}\label{e_softmax}\]
多层感知器
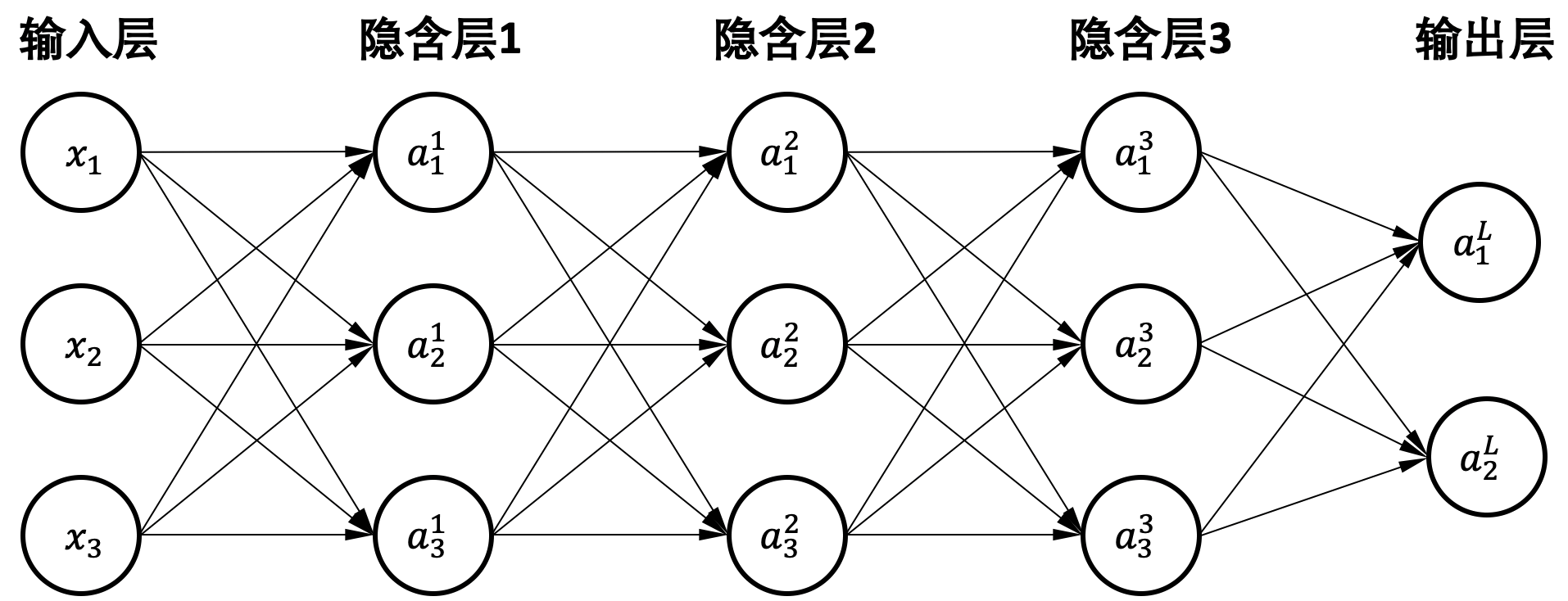
多层感知器(Multi-Layer Perceptron,MLP) [1]通过叠加多层全连接层来提升网络的表达能力。相比单层网络,多层感知器有很多中间层的输出并不暴露给最终输出,这些层被称为隐含层(Hidden Layers)。这个例子中的网络可以通过下方的串联式矩阵运算实现,其中\(W^l\)和\(b^l\)代表不同层的权重矩阵和偏置,\(l\)代表层号,\(L\)代表输出层。
\[{z} = f({W^L}f({W^3}f({W^2}f({W^1}{x} + {b^1}) + {b^2}) + {b^3}) + {b^L})\]
在深度学习时代,网络模型基本都是多层的神经网络层连接起来的,输入数据经过多层的特征提取,可以学到不同抽象层级的特征向量(Feature Vector)。下面我们介绍一下其他常用的神经网络层。
卷积网络
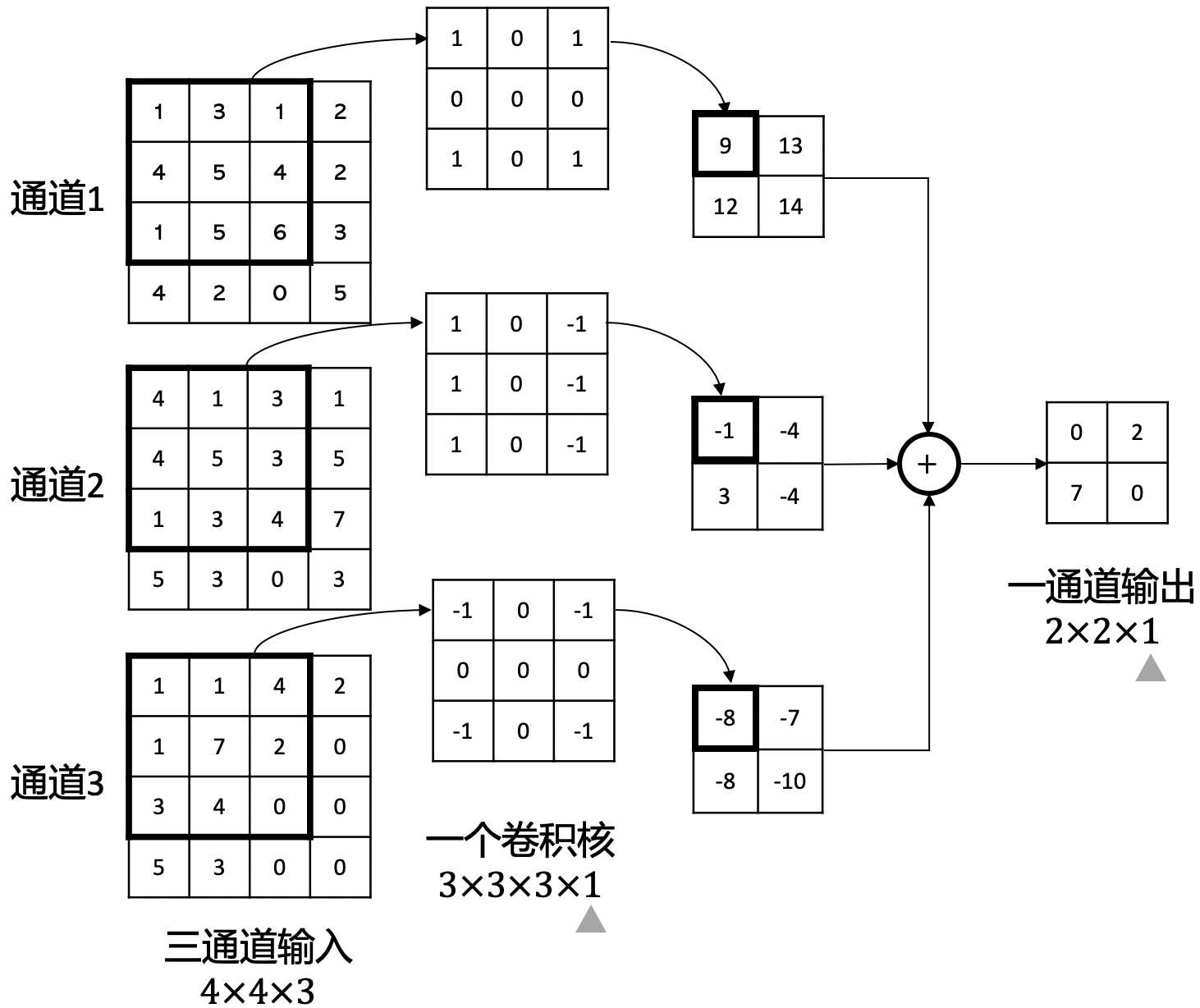
卷积神经网络 (Convolutional Neural Network,CNN) [2]由多层卷积层(Convolutional Layer)组成,常用于计算机视觉任务 [3][4]。 conv_computation_v4描述了一个卷积运算的例子。 根据卷积的特点,我们可以知道两个事实:1)一个卷积核的通道数,等于输入的通道数;2)输出的通道数,等于卷积核的数量。
conv_computation_v4例子中,卷积核每次滑动一个数值的范围来进行卷积操作,我们称它的步长(Stride)为1。此外,如果希望输入的边缘数值也能被考虑在内的话,则需要对边缘做填零(Zero Padding)操作。 conv_computation_v4例子中,如果输入的每个通道上下左右都填充一圈零,那么输出的大小则为\(4\times 4\times 1\)。填零的圈数取决于卷积核的大小,卷积核越大则填零圈数越大。
为了对输入的图像数据做特征提取,卷积核数量往往比输入数据的通道数据要多,这样的话输出数据的数值会很多,计算量变大。然而图像数据中相邻像素的特征往往相似,所以我们可以对相邻的输出特征进行聚合操作。池化层就是为了实现这个目的,我们通常有两种池化方法最大值池化(Max Pooling)和平均值池化(Mean Pooling)。如 pooling_v3所示,假设池化的卷积核高宽为\(2\times2\),输入\(4\times4\)的数据,步长为2(步长为1时,则输出等于输入),则输出为\(2\times2\)。
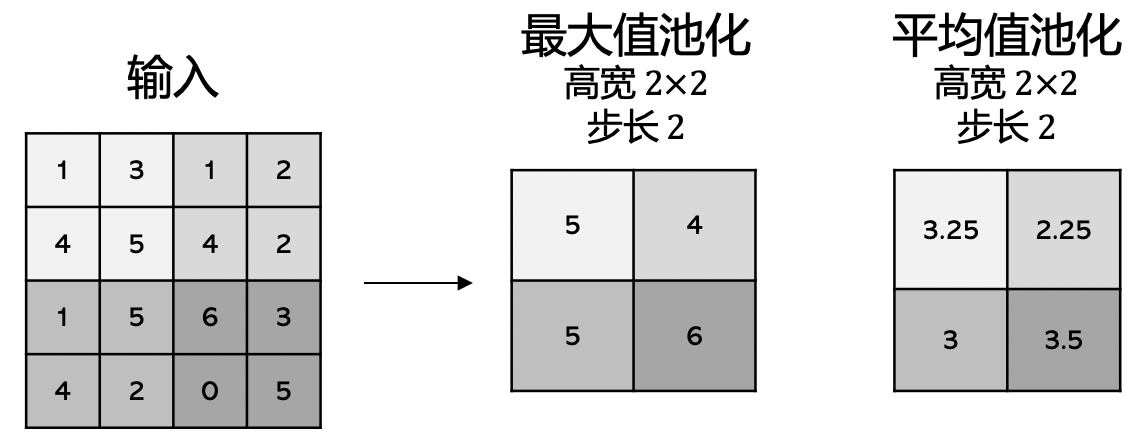
卷积层和全连接层都是很常用的,但是卷积层在输入是高维度的图像时,需要的参数量远远小于全连接层。卷积层的运算和全连接层是类似的,前者基于高维度张量运算,后者基于二维矩阵运算。
时序模型
现实生活中除了图像还有大量时间序列数据,例如视频、股票价格等等。循环神经网络(Recurrent Neural Networks,RNN) [5]是一种处理序列数据的深度学习模型结构。序列数据是一串连续的数据\({x_1, x_2, \dots, x_n}\),比如每个\(x\)代表一个句子中的单词。
为了可以接收一连串的输入序列,如 图17.1.4所示,朴素循环神经网络使用了循环单元(Cell)作为计算单元,用隐状态(Hidden State)来存储过去输入的信息。具体来说,对输入模型的每个数据\(x\),根据公式 (5),循环单元会反复计算新的隐状态,用于记录当前和过去输入的信息。而新的隐状态会被用到下一单元的计算中。
\[{h}_t = {W}[{x}_t; {h}_{t-1}] + {b}\tag{5}\label{aligned}\]
图17.1.4 朴素循环神经网络。 在每一步的计算中,循环单元通过过去时刻的隐状态\\({h}\_{t-1}\\)和当前的输入\\({x}\_t\\),求得当前的隐状态\\({h}\_t\\)。
然而这种简单的朴素循环神经网络有严重的信息遗忘问题。比如说我们的输入是“我是中国人,我的母语是___“,隐状态记住了“中国人“的信息,使得网络最后可以预测出“中文“一词;但是如果句子很长的时候,隐状态可能记不住太久之前的信息了,比如说“我是中国人,我去英国读书,后来在法国工作,我的母语是___”,这时候在最后的隐状态中关于“中国人“的信息可能会被因为多次的更新而遗忘了。 为了解决这个问题,后面有人提出了各种各样的改进方法,其中最有名的是长短期记忆(Long Short-Term Memory,LSTM) [6]。关于时序的模型还有很多很多,比如近年来出现的Transformer [7]等等。
参考文献
- Rosenblatt, Frank. The perceptron: a probabilistic model for information storage and organization in the brain.. Psychological Review. 1958. ↩
- LeCun, Yann and Boser, Bernhard and Denker, John S and Henderson, Donnie and Howard, Richard E and Hubbard, Wayne and Jackel, Lawrence D. Backpropagation applied to handwritten zip code recognition. Neural computation. 1989. ↩
- Krizhevsky, Alex and Sutskever, Ilya and Hinton, Geoffrey E. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems. 2012. ↩
- He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian. Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016. ↩
- Rumelhart, David E and Hinton, Geoffrey E and Williams, Ronald J. Learning representations by back-propagating errors. Nature. 1986. ↩
- Hochreiter, Sepp and Hochreiter, S and Schmidhuber, J\"urgen and Schmidhuber, J. Long Short-Term Memory.. Neural Computation. 1997. ↩
- Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, \Lukasz and Polosukhin, Illia. Attention is all you need. Advances in Neural Information Processing Systems. 2017. ↩
梯度下降与反向传播
梯度下降与反向传播
上面大体上介绍了经典神经网络的内容,那么现在有一个问题,这些网络中的参数是如何确定的呢?如果要解决的问题是一个小感知器就能解决的话,参数可以人为地去确定。但是如果是一个深度网络的话,参数的确定需要自动化,也就是所谓的网络训练,而这个过程需要我们设定一个损失函数(Loss Function)来作为训练优化的一个方向。 常见的损失函数有:1)用来衡量向量之间距离的均方误差(Mean Squared Error,MSE) \(\mathcal{L} = \frac{1}{N}|{y}-\hat{{y}}|^{2}_{2} = \frac{1}{N}\sum_{i=1}^N(y_{i}-\hat{y}_{i})^{2}\) 和 平均绝对误差(Mean Absolute Error,MAE) \(\mathcal{L} = \frac{1}{N}\sum_{i=1}^{N}|y_{i}-\hat{y}_{i}|\) ,其中\(N\)代表数据样本的数量,用以求平均用,而\(y\)代表真实标签(Ground Truth)、\(\hat{y}\)代表网络输出的预测标签。 2)分类任务可以用的交叉熵损失(Cross Entropy) \(\mathcal{L} = - \frac{1}{N} \sum_{i=1}^N \bigg(y_{i}\log\hat{y}_{i} + (1 - y_{i})\log(1 - \hat{y}_{i})\bigg)\)来作为损失数,当且仅当输出标签和预测标签一样的时候损失值才为零。
有了损失值之后,我们就可以利用大量真实标签的数据和优化方法来更新模型参数了,其中最常用的方法是梯度下降(Gradient Descent)。如 gradient_descent2所示, 开始的时候,模型的参数\({w}\)是随机选取的,然后求出损失值对参数的偏导数\(\frac{\partial \mathcal{L}}{\partial {w}}\),通过反复迭代 \({w}:={w}-\alpha\frac{\partial \mathcal{L}}{\partial {w}}\)完成优化。这个优化的过程其实就可以降低损失值以达到任务目标,其中\(\alpha\)是控制优化幅度的学习率(Learning Rate)。 在实践中,梯度下降最终得到的最小值很大可能是一个局部最小值,而不是全局最小值。不过由于深度神经网络能提供一个很强的数据表达能力,所以局部最小值可以很接近全局最小值,损失值可以足够小。
![梯度下降介绍。(左图)只有一个可以训练的参数\(w\);(右图)有两个可以训练的参数\({w}=[w_1,w_2]\)。在不断更新迭代参数后,损失值\(\mathcal{L}\)会逐渐地减小。但是由于存在很多局部最优解,我们往往不能更新到全局最优解。](img/ch_basic/gradient_descent2.png)
那么接下来,在深度神经网络中如何实现梯度下降呢,这需要计算出网络中每层参数的偏导数\(\frac{\partial \mathcal{L}}{\partial {w}}\),我们可以用反向传播(Back-Propagation) [1][2]来实现。 接下来, 我们引入一个中间量\({\delta}=\frac{\partial \mathcal{L}}{\partial {z}}\)来表示损失函数\(\mathcal{L}\) 对于神经网络输出\({z}\)(未经过激活函数,不是\(a\))的偏导数, 并最终得到\(\frac{\partial \mathcal{L}}{\partial {w}}\)。
我们下面用一个例子来介绍反向传播算法, 我们设层序号为\(l=1, 2, \ldots L\)(输出层(最后一层)序号为\(L\))。 对于每个网络层,我们有输出\({z}^l\),中间值\({\delta}^l=\frac{\partial \mathcal{L}}{\partial {z}^l}\)和一个激活值输出\({a}^l=f({z}^l)\) (其中\(f\)为激活函数)。 我们假设模型是使用Sigmoid激活函数的多层感知器,损失函数是均方误差(MSE)。也就是说,我们设定:
-
网络结构\({z}^{l}={W}^{l}{a}^{l-1}+{b}^{l}\)
-
激活函数\({a}^l=f({z}^l)=\frac{1}{1+{\rm e}^{-{z}^l}}\)
-
损失函数\(\mathcal{L}=\frac{1}{2}|{y}-{a}^{L}|^2_2\)
我们可以直接算出激活输出对于原输出的偏导数:
- \(\frac{\partial {a}^l}{\partial {z}^l}=f’({z}^l)=f({z}^l)(1-f({z}^l))={a}^l(1-{a}^l)\)
和损失函数对于激活输出的偏导数:
- \(\frac{\partial \mathcal{L}}{\partial {a}^{L}}=({a}^{L}-{y})\)
有了这些后,为了进一步得到损失函数对于每一个参数的偏导数,可以使用链式法则(Chain Rule),细节如下:
首先,从输出层(\(l=L\),最后一层)开始向后方传播误差,根据链式法则,我们先计算输出层的中间量:
- \({\delta}^{L} =\frac{\partial \mathcal{L}}{\partial {z}^{L}} =\frac{\partial \mathcal{L}}{\partial {a}^{L}}\frac{\partial {a}^L}{\partial {z}^{L}}=({a}^L-{y})\odot({a}^L(1-{a}^L))\)
除了输出层(\(l=L\))的中间值\({\delta}^{L}\),其他层(\(l=1, 2, \ldots , L-1\))的中间值\({\delta}^{l}\)如何计算呢?
-
已知模型结构\({z}^{l+1}={W}^{l+1}{a}^{l}+{b}^{l+1}\),我们可以直接得到\(\frac{\partial {z}^{l+1}}{\partial {a}^{l}}={W}^{l+1}\);而且我们已知\(\frac{\partial {a}^l}{\partial {z}^l}={a}^l(1-{a}^l)\)
-
那么根据链式法则,我们可以得到 \({\delta}^{l} =\frac{\partial \mathcal{L}}{\partial {z}^{l}} =\frac{\partial \mathcal{L}}{\partial {z}^{l+1}}\frac{\partial {z}^{l+1}}{\partial {a}^{l}}\frac{\partial {a}^{l}}{\partial {z}^{l}} =({W}^{l+1})^\top{\delta}^{l+1}\odot({a}^l(1-{a}^l))\)
根据上面的计算有所有层的中间值\({\delta}^l, l=1, 2, \ldots , L\)后,我们就可以在此基础上求出损失函数对于每层参数的偏导数:\(\frac{\partial \mathcal{L}}{\partial {W}^l}\)和\(\frac{\partial \mathcal{L}}{\partial {b}^l}\),以此来根据梯度下降的方法来更新每一层的参数。
-
已知模型结构\({z}^l={W}^l{a}^{l-1}+{b}^l\),我们可以求出 \(\frac{\partial {z}^{l}}{\partial {W}^l}={a}^{l-1}\) 和 \(\frac{\partial {z}^{l}}{\partial {b}^l}=1\)
-
那么根据链式法则,我们可以得到\(\frac{\partial \mathcal{L}}{\partial {W}^l}=\frac{\partial \mathcal{L}}{\partial {z}^l}\frac{\partial {z}^l}{\partial {W}^l}={\delta}^l({a}^{l-1})^\top\) , \(\frac{\partial \mathcal{L}}{\partial {b}^l}=\frac{\partial \mathcal{L}}{\partial {z}^l}\frac{\partial {z}^l}{\partial {b}^l}={\delta}^l\)
求得所有偏导数\(\frac{\partial \mathcal{L}}{\partial {W}^l}\) 和 \(\frac{\partial \mathcal{L}}{\partial {b}^l}\)后,我们就可以用梯度下降更新所有参数\({W}^l\) 和 \({b}^l\):
- \({W}^l:={W}^l-\alpha\frac{\partial \mathcal{L}}{\partial {W}^l}\), \({b}^l:={b}^l-\alpha\frac{\partial \mathcal{L}}{\partial {b}^l}\)
但是还有一个问题需要解决,那就是梯度下降的时候每更新一次参数,都需要计算一次当前参数下的损失值。然而,当训练数据集很大时(\(N\)很大),若每次更新都用整个训练集来计算损失值的话,计算量会非常巨大。 为了减少计算量,我们使用随机梯度下降(Stochastic Gradient Descent,SGD)来计算损失值。具体来说,我们计算损失值不用全部训练数据,而是从训练集中随机选取一些数据样本来计算损失值,比如选取16、32、64或者128个数据样本,样本的数量被称为批大小(Batch Size)。 此外,学习率的设定也非常重要。如果学习率太大,可能无法接近最小值的山谷,如果太小,训练又太慢。 自适应学习率,例如Adam [3]、RMSProp [4]和 Adagrad [5]等,在训练的过程中通过自动的方法来修改学习率,实现训练的快速收敛,到达最小值点。
参考文献
- Rumelhart, David E and Hinton, Geoffrey E and Williams, Ronald J. Learning representations by back-propagating errors. Nature. 1986. ↩
- LeCun, Yann and Bengio, Yoshua and Hinton, Geoffrey. Deep learning. Nature. 2015. ↩
- Kingma, Diederik and Ba, Jimmy. Adam: A Method for Stochastic Optimization. Proceedings of the International Conference on Learning Representations (ICLR). 2014. ↩
- Tieleman, T and Hinton, G. Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning. 2017. ↩
- Duchi, John and Hazan, Elad and Singer, Yoram. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research (JMLR). 2011. ↩
经典机器学习方法
经典机器学习方法
大量经典机器学习算法,如 支持向量机(Support Vector Machine,SVM), K最近邻(K-Nearest Neighbor, KNN)分类算法 和K均值聚类算法(K-Means Clustering Algorithm)等, 虽然它们有的有网络参数,有的没有网络参数,有的是监督学习算法,有的是无监督学习算法, 训练过程也不一样,但是从系统的角度,它们都是以矩阵运算为基础的。下面,我们来简要介绍一下这些算法。
支持向量机
支持向量机(Support Vector Machine,SVM),是一种经典的机器学习分类算法,其核心思想在于最大化决策边界到数据点的距离。在这里,我们以线性可分数据为例;对于非线性可分的数据,运用核方法(Kernel Method)即可类似处理。
如果训练数据是线性可分的,SVM的目标则是最大化间隔(Margin)。首先,我们先来定义最大化间隔的分类器,如下: \[\min_{{w},b} ~~~\frac{1}{2} ||{w}||^2\] \[s.t. ~~~y_i ({w}^T {x_i} + b) \geq 1, ~~~\forall 1 \leq i \leq n\] 其拉格朗日乘子为 \[L({w},b,{\lambda}) = \frac{1}{2} ||{w}||^2 + \sum_{i=1}^n \lambda_i (1-y_i({w}^T {x_i} + b))\] 由于\(\frac{1}{2} ||{w}||^2\)是凸的,并且\(\lambda_i (1-y_i({w}^T {x_i} + b))\)是线性的(也是凸的),所以优化问题的解为 \[\max_{\lambda>0} \min_{{w},b} L({w},b, {\lambda})\] 求\(L\)关于\({w},b\)的导数有 \[\nabla_{{w}} L= {w} - \sum_{i=1}^n \lambda_i y_i {x_i}\] \[\nabla_b L = - \sum_{i=1}^n \lambda_i y_i\] 令\(L\)关于\({w},b\)的导数均为0得到,\({w}^* = \sum_{i=1}^n \lambda_i y_i {x_i}\)以及\(\sum_{i=1}^n \lambda_i y_i = 0\)。 由于当\(\lambda\)固定的时候,\(b\)的值对目标函数无贡献,所以可以令\(b^* = 0\)。 这时,由对偶性理论和KTT条件,我们得到: \[y_i ({w}^{*T} {x_i} + b^*) > 1 \Rightarrow \lambda_i^* = 0\] \[\lambda_i^* > 0 \Rightarrow y_i ({w}^{*T} {x_i} + b^*) = 1\] \[{w}^* = \sum_{i=1}^n \lambda_i^* y_i {x_i}\] 如果\(y_i ({w}^{*T} {x_i} + b^*) = 1\),那么\({x_i}\)就是离超平面\(({w}^*,b^*)\)最近的点之一,否则就不是。因此,\({w}^*\)就是离超平面\(({w}^*,b^*)\)最近的点\({x_i}\)的线性组合。
如此,通过SVM算法,我们实现了数据的分类,并且能够最大化了决策边界到最近点的距离。 我们定义满足\(y_i ({w}^{*T} {x_i} + b^*) = 1\)的\({x_i}\)为支持向量(Support Vectors),同时把分类器\(\hat{y}=sgn({w}^{*T} {x_i} + b^*)\)称为支持向量机。
K最近邻算法
K最近邻算法(K-Nearest Neighbor,KNN)也是一种传统的机器学习算法,可用于分类、回归等基本的机器学习任务。和上面介绍的SVM算法不同,K最近邻算法的核心思想并不是用一个决策边界把属于不同类的数据分开,而是依靠每个数据点周围几个距离最近的数据的性质,来预测数据点本身的性质。
KNN用于分类时,为了预测某个样本点的类别,会进行一次投票。投票的对象为离这个观测样本点最近的K个样本点,每个要投票的样本点可能会被赋予不同的权重,而投票的“内容“则是样本点的类别。处理投票结果的时候,采用的是少数服从多数的决策方法(Majority Vote)。也就是说,若一个样本点最近的K个样本点中大多数属于某个类别,那么该样本点也属于这个类别。
KNN算法的具体描述如下:(1)计算待分类点到各已知类别点的距离;(2)将这些点按照距离排序,并按照距离挑选出最近的K个点;(3)按照每个点的权重进行“统票“,票面内容为点所处的类别;(4)返回得票最高的类别,并作为待分类点的预测类别。
KNN算法有几个需要注意的关键问题,包括超参数K的选择,距离的度量方式,还有分类决策规则。对于超参数K,不宜过大,否则会导致很大的近似误差,反之亦不宜过小,否则会导致很大的估计误差。距离的度量,则可以选择曼哈顿距离、欧式距离和闵可夫斯基距离等等。为了降低K值对于预测结果产生的误差和影响,我们通常可以对分类决策规则做一定的规定,比如在投票决策时让距离小的点有更大的权重,距离较大的点权重较小。在编程实现KNN算法的时候,权重等参数都会以矩阵的形式进行运算,以提高运算效率。
K均值聚类算法
K均值聚类算法(K-Means Clustering Algorithm)是机器学习中一种常见的无监督聚类算法。在这里,我们首先定义聚类问题:给定数据点\({x_1},\cdots, {x_n} \in \mathbb{R}^d\)和\(K\in \mathbb{N}\),需要划分为\(K\)个簇\({C_1}, \cdots, {C_K} \in \mathbb{R}^d\)以及每个数据点所对应的分类中心点\({ C_{(1)}}, \cdots, {C_{(n)}}\),以最小化距离和\(\sum_i ||{x_i} - {C_{(i)}}||^2\)。
K均值聚类算法是一种解决聚类问题的算法,算法过程如下:
-
随机选择\({C_1}, \cdots, {C_K}\)
-
把\({x_i}\)所对应的分类置为距离其最近的聚类中心点的分类
-
计算并赋值\({C_K} = \frac{\sum_{{C_{(i)}}={C_K}} {x_i}}{\sum_{{C_{(i)}}={C_K}} 1}\)
-
重复以上步骤直到算法收敛
可以证明,K均值聚类算法会使得距离和\(\sum_i ||{x_i} - {C_{(i)}}||^2\)不断地单调减小,并且最终能够收敛。不过,算法可能收敛到局部最小值。
本章结束语:
在系统角度,机器学习的算法无论是什么算法,涉及到高维数据任务的现都是矩阵运算实现的。
参考文献
:bibliography:../references/appendix.bib