11.4. 机器学习集群架构¶
机器学习模型的分布式训练通常会在计算集群(Compute Cluster)中实现。接下来,我们将介绍计算集群的构成,特别是其集群网络的设计。
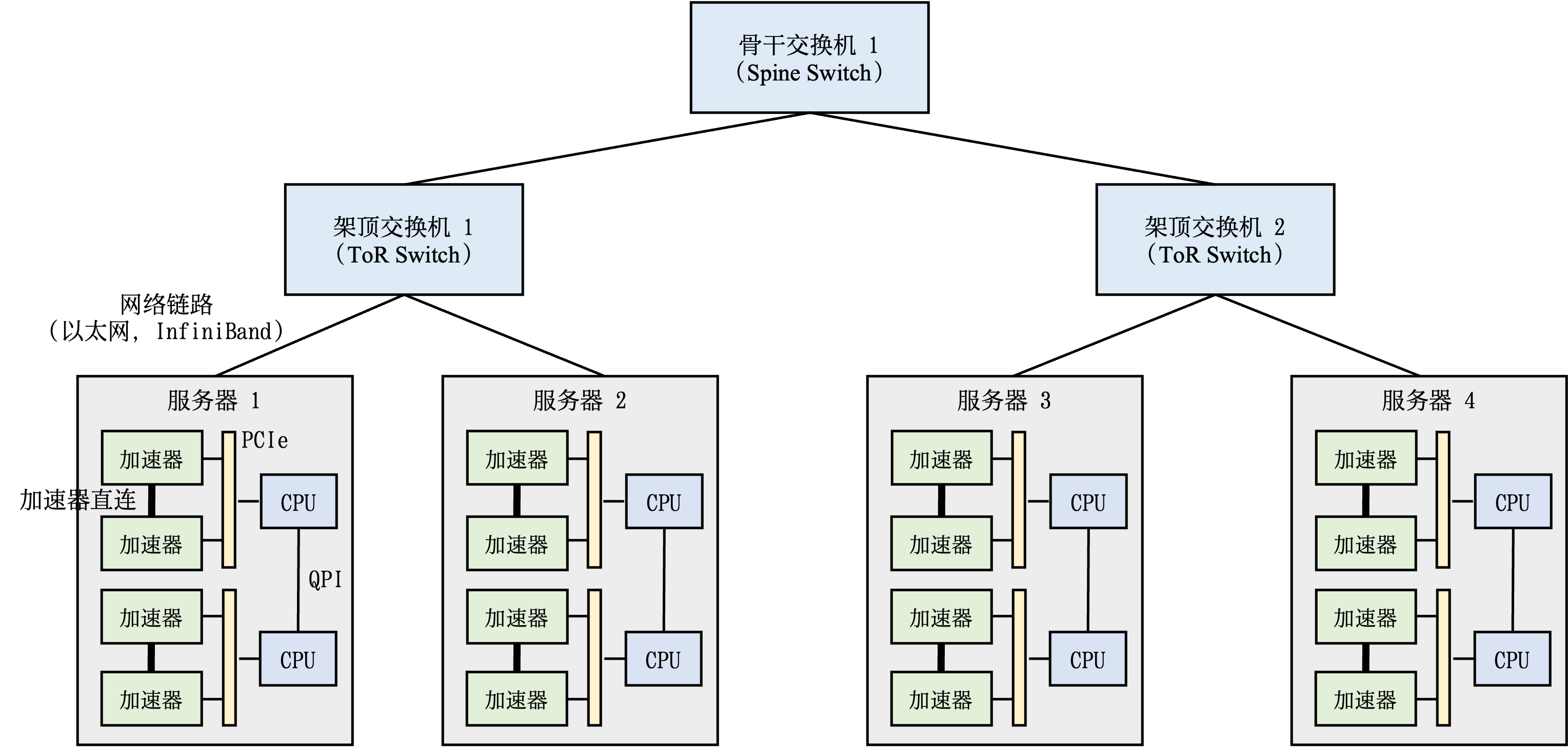
图11.4.1 机器学习集群架构¶
图11.4.1 描述了一个机器学习集群的典型架构。这种集群中会部署大量带有硬件加速器的服务器。每个服务器中往往有多个加速器。为了方便管理服务器,多个服务器会被放置在一个机柜(Rack)中,同时这个机柜会接入一个架顶交换机(Top of Rack Switch)。在架顶交换机满载的情况下,可以通过在架顶交换机间增加骨干交换机(Spine Switch)进一步接入新的机柜。这种连接服务器的拓扑结构往往是一个多层树(Multi-Level Tree)。
需要注意的是,在集群中跨机柜通信(Cross-Rack Communication)往往会有网络瓶颈。这是因为集群网络为了便于硬件采购和设备管理,会采用统一规格的网络链路。因此,在架顶交换机到骨干交换机的网络链路常常会形成网络带宽超额认购(Network Bandwidth Oversubscription),即峰值带宽需求会超过 实际网络带宽。如 图11.4.1 的集群内,当服务器1和服务器2利用各自的网络链路(假设10Gb/s)往服务器3发送数据时,架顶交换机1会汇聚2倍数据(即20Gb/s)需要发往骨干交换机1。然而骨干交换机1和架顶交换机1 之间只有一条网络链路(10Gb/s)。这里,峰值的带宽需求是实际带宽的两倍,因此产生网络超额订购。在实际的机器学习集群中,实际带宽和峰值带宽的比值一般在1:4到1:16之间。因此如果将网络通信限制在机柜内,从而避免网络瓶颈成为了分布式机器学习系统的核心设计需求。
那么,在计算集群中训练大型神经网络需要消耗多少网络带宽呢?假设给定一个千亿级别参数的神经网络(比如OpenAI 发布的大型语言模型GPT-3有最多将近1750亿参数),如果用32位浮点数来表达每一个参数,那么每一轮训练迭代(Training Iteration)训练中,一个数据并行模式下的模型副本(Model Replica)则需要生成700GB,即175G \(*\) 4 bytes = 700GB,的本地梯度数据。假如有3个模型副本,那么至少需要传输1.4TB,即700GB \(*\) \((3-1)\),的梯度数据。这是因为对于\(N\)个副本,只需传送其中的\(N-1\)个副本完成计算。当平均梯度计算完成后,需要进一步将其广播(Broadcast)到全部的模型副本(即1.4TB的数据)并更新其中的本地参数,从而确保模型副本不会偏离(Diverge)主模型中的参数。
当前的机器学习集群一般使用以太网(Ethernet)构建不同机柜之间的网络。主流的商用以太网链路带宽一般在10Gb/s到25Gb/s之间。这里需要注意的是,网络带宽常用Gb/s为单位,而内存带宽常用GB/s为单位。前者以比特(bit)衡量,后者以字节(byte)衡量。
利用以太网传输海量梯度会产生严重的传输延迟。新型机器学习集群(如英伟达的DGX系列机器)往往配置有更快的InfiniBand。单个InfiniBand链路可以提供100Gb/s或200Gb/s的带宽。即使拥有这种高速网络,传输TB级别的本地梯度依然需要大量延迟(即使忽略网络延迟,1TB的数据在200Gb/s的链路上传输也需要至少40s)。InfiniBand的编程接口以远端内存直接读取(Remote Direct Memory Access,RDMA)为核心,提供了高带宽,低延迟的数据读取和写入函数。然而,RDMA的编程接口和传统以太网的TCP/IP的Socket接口有很大不同,为了解决兼容性问题,人们可以用IPoIB (IP-over-InfiniBand)技术。这种技术确保了遗留应用(Legacy Application)可以保持Socket调用,而底层通过IPoIB调用InfiniBand的RDMA接口。
为了在服务器内部支持多个加速器(通常2-16个),通行的做法是在服务器内部构建一个异构网络。以 图11.4.1 中的服务器1为例,这个服务器放置了两个CPU,CPU之间通过QuickPath Interconnect (QPI)进行通信。而在一个CPU接口(Socket)内,加速器和CPU通过PCIe总线(Bus)互相连接。由于加速器往往采用高带宽内存(High-Bandwidth Memory,HBM)。HBM的带宽(例如英伟达A100的HBM提供了1935 GB/s的带宽)远远超过PCIe的带宽(例如英伟达A100服务器的PCIe 4.0只能提供64GB/s的带宽)。在服务器中,PCIe需要被全部的加速器共享。当多个加速器同时通过PCIe进行数据传输时,PCIe就会成为显著的通信瓶颈。为了解决这个问题,机器学习服务器往往会引入加速器高速互连(Accelerator High-speed Interconnect),例如英伟达A100 GPU的NVLink提供了600 GB/s的带宽,从而绕开PCIe进行高速通信。