16.1. 背景¶
在人类历史上,技术进步、生产关系逻辑和伦理法规的发展是动态演进的。当一种新的技术在实验室获得突破后,其引发的价值产生方式的变化会依次对商品形态、生产关系等带来冲击。而同时当新技术带来的价值提升得到认可后,商业逻辑的组织形态在自发的调整过程中,也会对技术发展的路径、内容甚至速度提出诉求,并当诉求得到满足时适配以新型的伦理法规。在这样的相互作用中,技术系统与社会体系会共振完成演进,是谓技术革命。
近10年来,籍由算力与数据规模的性价比突破临界点,以深度神经网络为代表的联结主义模型架构及统计学习范式(以后简称深度学习)在特征表征能力上取得了跨越级别的突破,大大推动了人工智能的发展,在很多场景中达到令人难以置信的效果。比如:人脸识别准确率达到97%以上;谷歌智能语音助手回答正确率,在2019年的测试中达到92.9%。在这些典型场景下,深度学习在智能表现上的性能已经超过了普通人类(甚至专家),从而到了撬动技术更替的临界点。在过去几年间,在某些商业逻辑对技术友好,或者伦理法规暂时稀缺的领域,如安防、实时调度、流程优化、竞技博弈、信息流分发等,人工智能和深度学习取得了技术和商业上快速突破。
食髓知味,技术发展的甜头自然每个领域都不愿放过。而当对深度学习商业化运用来到某些对技术敏感、与人的生存或安全关系紧密的领域,如自动驾驶、金融、医疗和司法等高风险应用场景时,原有的商业逻辑在进行技术更替的过程中就会遇到阻力,从而导致商业化变现速度的减缓甚至失败。究其原因,以上场景的商业逻辑及背后伦理法规的中枢之一是稳定的、可追踪的责任明晰与责任分发;而深度学习得到的模型是个黑盒,我们无法从模型的结构或权重中获取模型行为的任何信息,从而使这些场景下责任追踪和分发的中枢无法复用,导致人工智能在业务应用中遇到技术上和结构上的困难。
举2个具体的例子:例1,在金融风控场景,通过深度学习模型识别出来小部分用户有欺诈嫌疑,但是业务部门不敢直接使用这个结果进行处理。因为人们难以理解结果是如何得到的,从而无法判断结果是否准确。而且该结果缺乏明确的依据,如果处理了,也无法向监管机构交代; 例2,在医疗领域,深度学习模型根据患者的检测数据,判断患者有肺结核,但是医生不知道诊断结果是怎么来的,不敢直接采用,而是根据自己的经验,仔细查看相关检测数据,然后给出自己的判断。从这2个例子可以看出,黑盒模型严重影响模型在实际场景的应用和推广。
此外,模型的可解释性问题也引起了国家层面的关注,相关机构对此推出了相关的政策和法规。
2017年7月,国务院印发《新一代人工智能发展规划》,首次涵盖可解释AI。
2021年3月,中国人民银行发布金融行业标准《人工智能算法金融应用评价规范》,对金融行业AI模型可解释性提出了明确要求。
2021年8月,网信办《互联网信息服务算法推荐管理规定》, 提出对互联网行业算法推荐可解释性的要求。
2021年9月,科技部发布《新一代人工智能伦理规范》。
因此,从商业推广层面以及从法规层面,我们都需要打开黑盒模型,对模型进行解释,可解释AI正是解决该类问题的技术。
16.2. 可解释AI定义¶
按DARPA(美国国防部先进研究项目局)的描述,如 图16.2.1所示, 可解释AI的概念在于:区别于现有的AI系统,可解释AI系统可以解决用户面对黑盒模型时遇到的问题,使得用户知其然并知其所以然。
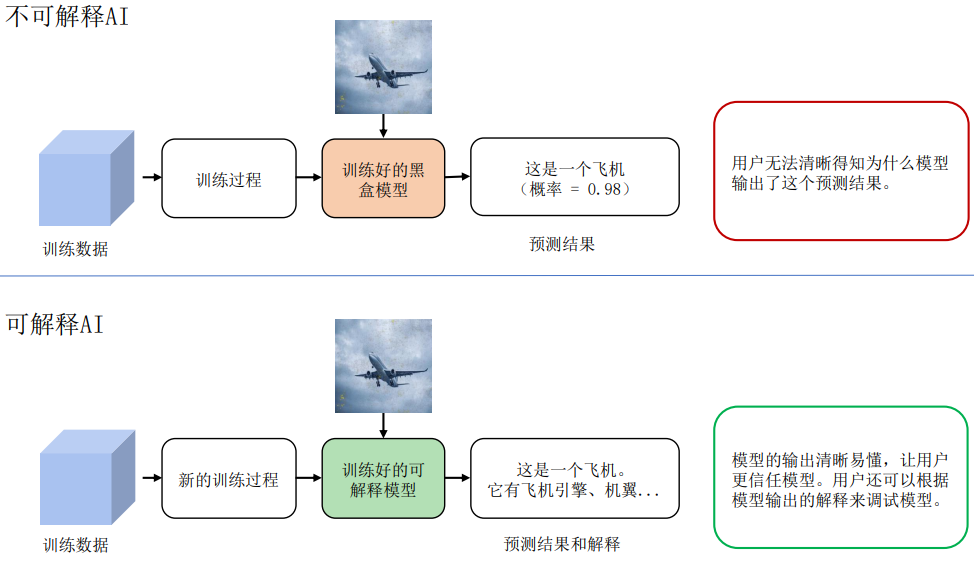
图16.2.1 可解释AI概念(图片来源于Broad Agency Announcement Explainable Artificial Intelligence (XAI) DARPA-BAA-16–53)¶
然而,不论是学术界还是工业界,对于可解释AI (eXplainable AI(XAI))都没有一个统一的定义。这里列举3种典型定义,供大家参考讨论:
可解释性就是希望寻求对模型工作机理的直接理解,打破人工智能的黑盒子。
可解释AI是为AI算法所做出的决策提供人类可读的以及可理解的解释。
可解释AI是确保人类可以轻松理解和信任人工智能代理做出的决策的一组方法。
我们根据自身的实践经验和理解,将可解释AI定义为:一套面向机器学习(主要是深度神经网络)的技术合集,包括可视化、数据挖掘、逻辑推理、知识图谱等,目的是通过此技术合集,使深度神经网络呈现一定的可理解性,以满足相关使用者对模型及应用服务产生的信息诉求(如因果或背景信息),从而为使用者对人工智能服务建立认知层面的信任。
16.3. 可解释AI算法现状介绍¶
随着可解释AI概念的提出,可解释AI越来越受到学术界及工业界的关注,下图展示了人工智能领域顶级学术会议中可解释AI关键字的趋势。为了让读者更好的对现有可解释AI算法有一个整体认知,我们这里参考 [Li et al., 2020]总结归纳了可解释AI的算法类型,如 图16.3.1所示。
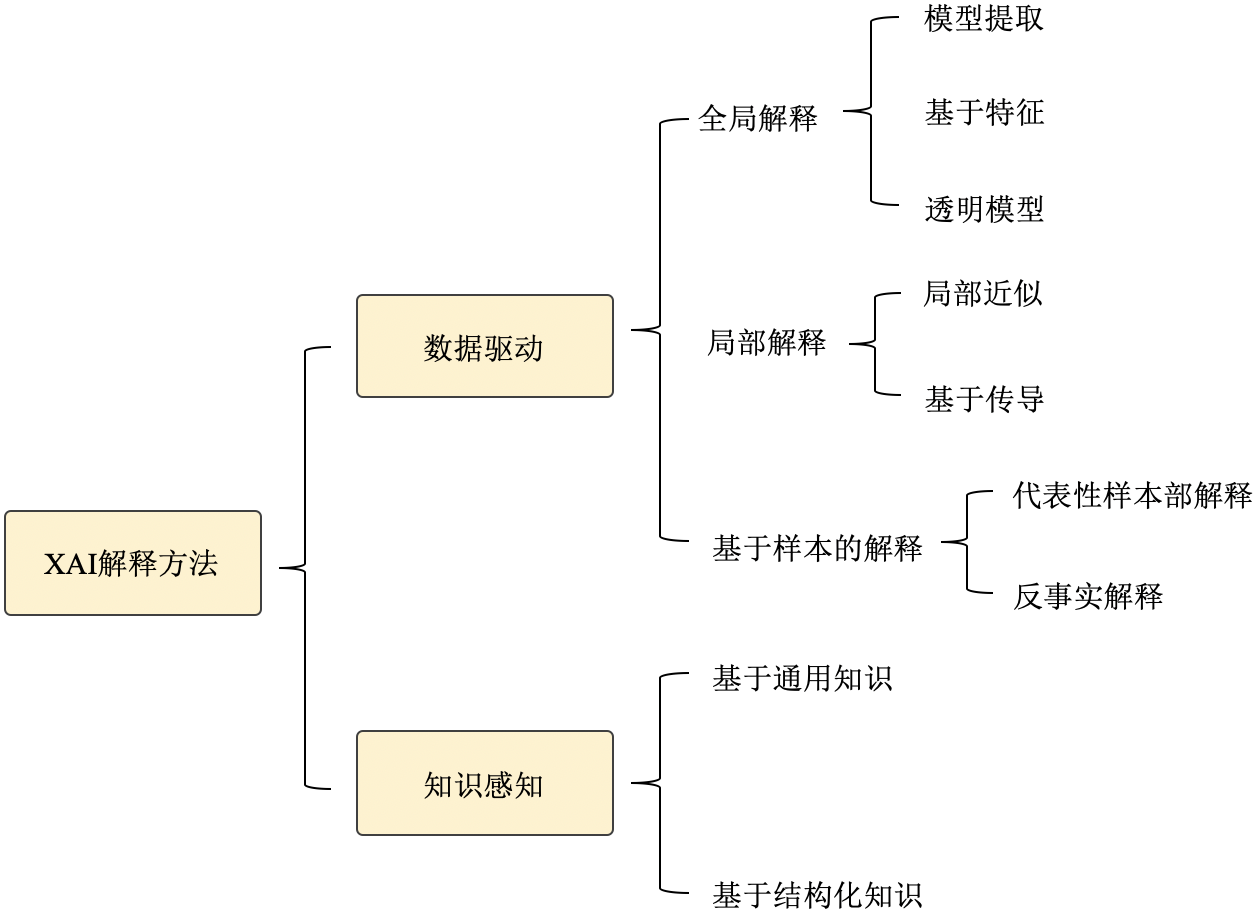
图16.3.1 可解释AI(XAI)算法分支¶
对模型进行解释有多种多样的方法,这里依据解释过程是否引入数据集以外的外部知识,将其分为数据驱动的解释方法和知识感知的解释方法。
数据驱动的解释
数据驱动的解释是指纯粹从数据本身生成解释的方法,而不需要先验知识等外部信息。为了提供解释,数据驱动的方法通常从选择数据集(具有全局或局部分布)开始。然后,将选定的数据集或其变体输入到黑盒模型(在某些情况下,选取数据集不是所必需的。例如, [Erhan et al., 2009]提出的最大激活值方法),通过对黑盒模型的相应预测进行一定的分析(例如,对预测w.r.t.输入特征进行求导)来生成解释。根据可解释性的范围,这些方法可以进一步分为全局方法或局部方法,即它们是解释所有数据点的全局模型行为还是预测子集行为。特别地,基于实例的方法提供了一种特殊类型的解释–它们直接返回数据实例作为解释。虽然从解释范围的分类来看,基于实例的方法也可以适合全局方法(代表性样本)或局部方法(反事实),但我们单独列出它们,以强调它们提供解释的特殊方式。
全局方法旨在提供对模型逻辑的理解以及所有预测的完整推理,基于对其特征、学习到的组件和结构的整体视图等等。有几个方向可以探索全局可解释性。为了便于理解,我们将它们分为以下三个子类: (i) 模型提取——从原始黑盒模型中提取出一个可解释的模型,比如通过模型蒸馏的方式将原有黑盒模型蒸馏到可解释的决策树 [Frosst & Hinton, 2017] [Zhang et al., 2019],从而使用决策树中的规则解释该原始模型; (ii) 基于特征的方法——估计特征的重要性或相关性,如 图16.3.2所示, 该类型解释可提供如“信用逾期记录是模型依赖的最重要特征”的解释,从而协助判定模型是否存在偏见. 一种典型的全局特征解释方法是SHAP(其仅能针对树模型输出全局解释):cite:lundberg2017unified。 (iii) 透明模型设计——修改或重新设计黑盒模型以提高其可解释性。这类方法目前也逐渐成为探索热点,近期的相关工作包括ProtoPNet [Chen et al., 2019], Interpretable CNN [Zhang et al., 2018], ProtoTree [Nauta et al., 2021]等。
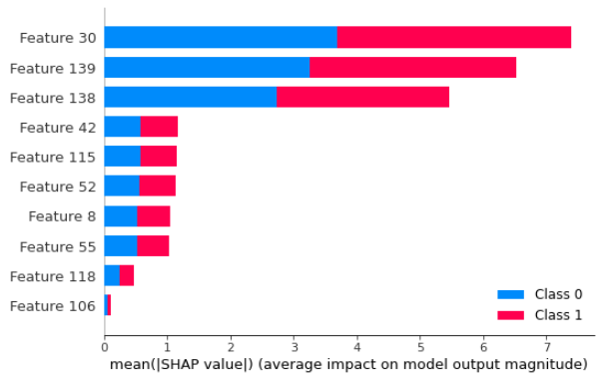
图16.3.2 全局特征重要性解释¶
全局解释可以提供黑盒模型的整体认知。但由于黑盒模型的高复杂性,在实践中往往很难通过模型提取/设计得到与原模型行为相近的简单透明模型,也往往很难对整个数据集抽象出统一的特征重要性。此外,在为单个观察生成解释时,全局解释也缺乏局部保真度,因为全局重要的特征可能无法准确解释单个样例的决定。因此,局部方法成为了近些年领域内重要的研究方向。局部方法尝试为单个实例或一组实例检验模型行为的合理性。当仅关注局部行为时,复杂模型也可以变得简单,因此即使是简单的函数也有可以为局部区域提供可信度高的解释。基于获得解释的过程,局部方法可以分为两类:局部近似和基于传播的方法。
局部近似是通过在样本近邻区域模拟黑盒模型的行为生成可理解的子模型。相比于全局方法中的模型提取,局部近似仅需关注样本临近区域,因此更容易获得精确描述局部行为的子模型。如 图16.3.3所示,通过在关注数据点\(x\)附近生成\(m\)个数据点\((x_i^\prime, f(x_i^\prime)), for\ i=1,2, ...m\)(这里\(f\)为黑盒模型决策函数),用线性拟合这些数据点,可以得到一个线性模型\(g=\sum_i^k w_ix^i\),这里\(k\)表示数据的特征维度。那么线性模型中的权重\(w_i\)即可用于表示数据\(x\)中第\(i\)个特征对于模型\(f\)的重要性。
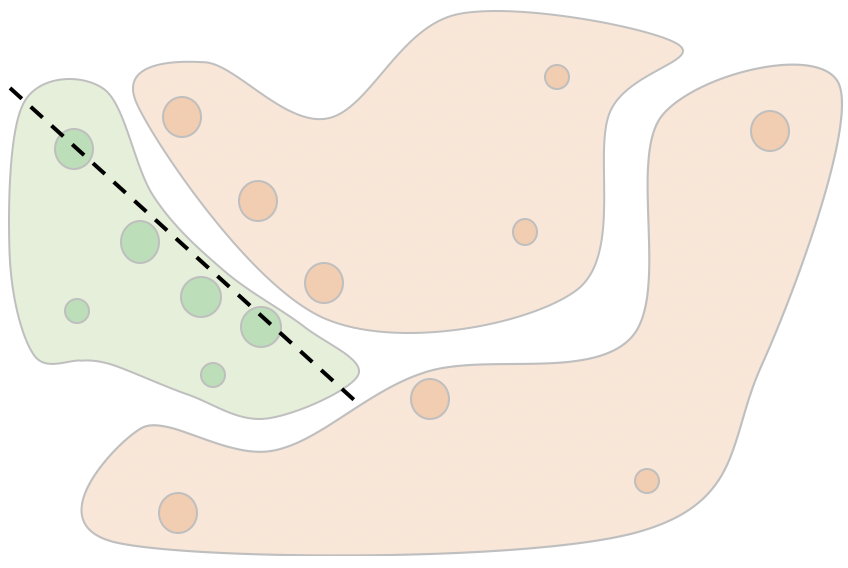
图16.3.3 局部近似方法示例¶
基于传播的方法通常是传播某些信息直接定位相关特征,这些方法包含了基于反向传播的方法和基于前向传播的方法。基于反向传播的方法通过梯度回传将输出的贡献归因于输入特征。如 图16.3.4所示,通过梯度回传,计算模型输出对输入的梯度\(\frac{d(f(x))}{dx}\) 作为模型解释。常见的基于梯度传播的方法有基本Gradient方法,GuidedBackprop [Zeiler & Fergus, 2014], GradCAM [Selvaraju et al., 2017]等. 而基于前向传播的方法通过扰动特征后, 进行前向推理的输出差异来量化输出与特征的相关性。其中,常见的几种方法有RISE [Petsiuk et al., 2018],ScoreCAM [Wang et al., 2020]等。
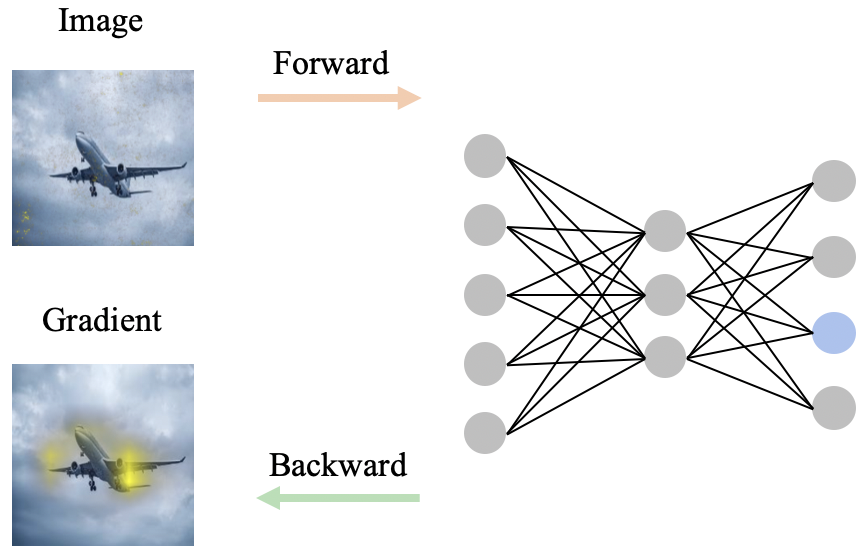
图16.3.4 局部近似方法示例¶
知识感知的解释
数据驱动的解释方法能够从数据集或输入和输出之间的关系提供全面的解释。在此基础上,还可以利用外部知识来丰富解释并使其更加人性化。没有机器学习背景知识的门外汉可能很难直接理解特征的重要性,以及特征和目标之间的联系。借助外部领域知识,我们不仅可以生成表明特征重要性的解释,还可以描述某些特征比其他特征更重要的原因。因此,在过去几年中,基于知识感知的可解释AI方法引起了越来越多的关注。与从多种情景中收集的原始数据集相比,知识通常被视为人类根据生活经验或严格的理论推理得出的实体或关系。一般来说,知识可以有多种形式。它可以保留在人的头脑中,也可以用自然语言、音频或规则记录,具有严格的逻辑。为了对这些方法进行系统回顾,我们在此根据知识来源将它们分为两类:通用知识方法和知识库(KB)方法。前者以非结构化数据为知识源来构建解释,后者以结构化知识库为基础来构建解释。
提供知识的一个相对直接的方法是通过人类的参与。事实上,随着人工智能研究和应用的爆炸式增长,人类在人工智能系统中的关键作用已经慢慢显现。这样的系统被称为以人为中心的人工智能系统。 [Riedl, 2019]认为,以人为中心的人工智能不仅能让人工智能系统从社会文化的角度更好地了解人类,还能让人工智能系统帮助人类了解自己。为了实现这些目标,人工智能需要满足可解释性和透明度等几个属性。
具体来说,人类能够通过提供相当多的人类定义的概念来在人工智能系统中发挥作用。 [kim2018interpretability]利用概念激活向量(CAV)来测试概念在分类任务中的重要性(TCAV)。CAV是与感兴趣目标概念的激活与否决策边界垂直的矢量,该矢量可以这样获取: 输入目标概念的正负样本, 进行线性回归, 得到决策边界, 从而得到CAV。以“斑马”的“条纹”概念为例,用户首先收集包含有“条纹”的数据样本及不含“条纹”的数据样本,输入到网络中,获取中间层的激活值,基于正负样本的标签(\(1\)代表含有概念,\(0\)代表不含概念)对中间层激活值进行拟合,获取决策边界,CAV即为该决策边界的垂直向量。
如 图16.3.5所示,为了计算TCAV评分,代表第\(l\)层概念对类\(k\)预测的重要性的“概念敏感度”可以首先计算为方向导数\(S_{C,k,l}(\mathbf{x})\):
其中\(f_{l}(\mathbf{x})\)是在第\(l\)、\(h_{l,k}(\cdot)\)是类\(k\)的logit,\(\nabla h_{l,k}(\cdot)\)是\(h_{l,k}\) w.r.t层\(l\)的激活的梯度。\(\mathbf{v}^{l}_{C}\)是用户旨在探索的概念\(C\)的CAV。正(或负)敏感性表明概念\(C\)对输入的激活有正(或负)影响。
基于\(S_{C,k,l}\), TCAV就可以通过计算类\(k\)的具有正\(S_{C,k,l}\)’s的样本的比率来获得:
结合\(t\)-分布假设方法,如果\(\textbf{TCAV}_{Q_{C,k,l}}\)大于0.5,则表明概念\(C\)对类\(k\)有重大影响。

图16.3.5 TCAV流程(图片来源于 [Li et al., 2020])¶
人类的知识可以是主观的,而KB可以是客观的。在当前研究中,KB通常被建模为知识图谱(KG)。以下以MindSpore支持的可解释推荐模型TB-Net为例,讲解如何使用知识图谱构建可解释模型。知识图谱可以捕捉实体之间丰富的语义关系。TB-Net的目的之一就是确定哪一对实体(即,物品-物品)对用户产生最重大的影响,并通过什么关系和关键节点进行关联。不同于现有的基于KG嵌入的方法(RippleNet使用KG补全方法预测用户与物品之间的路径),TB-Net提取真实路径,以达到推荐结果的高准确性和优越的可解释性。
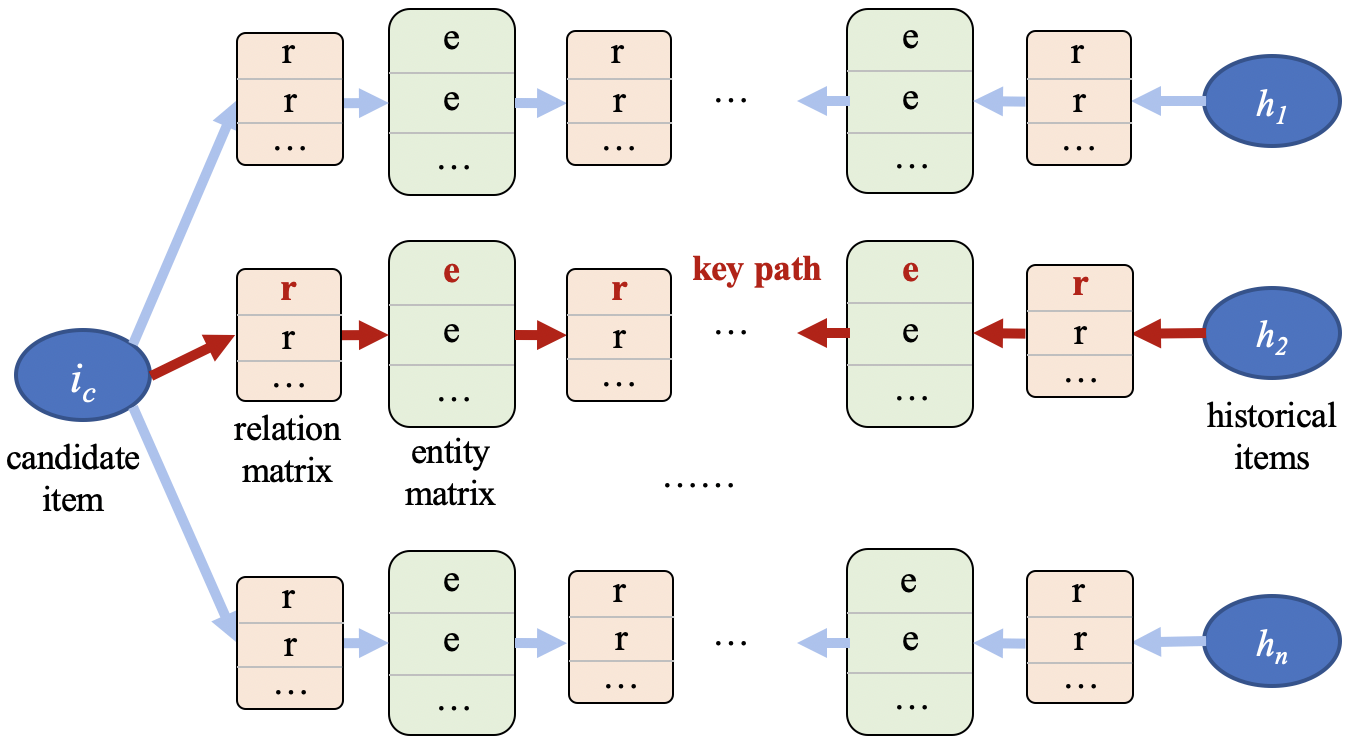
图16.3.6 TB-Net网络训练框架¶
TB-Net的框架如 图16.3.6所示:其中,\(i_c\)代表待推荐物品,\(h_n\)代表历史记录中用户交互的物品,\(r\)和\(e\)代表图谱中的关系(relation)和实体(entity),它们的向量化表达拼接在一起形成关系矩阵和实体矩阵。首先,TB-Net通过\(i_c\)和\(h_n\)的相同特征值来构建用户\(u\)的子图谱,每一对\(i_c\)和\(h_n\)都由关系和实体所组成的路径来连接。然后,TB-Net的路径双向传导方法将物品、实体和关系向量的计算从路径的左侧和右侧分别传播到中间节点,即计算左右两个流向的向量汇集到同一中间实体的概率。该概率用于表示用户对中间实体的喜好程度,并作为解释的依据。最后,TB-Net识别子图谱中关键路径(即关键实体和关系),输出推荐结果和具有语义级别的解释。
以游戏推荐为场景,随机对一个用户推荐新的游戏,如 图16.3.7所示,其中Half-Life, DOTA 2, Team Fortress 2等为游戏名称。关系属性中,game.year 代表游戏发行年份,game.genres代表游戏属性,game.developer代表游戏的开发商,game.categories代表游戏分类。属性节点中,MOBA代表多人在线战术竞技游戏,Valve代表威尔乌游戏公司,Action代表动作类,Multi-player代表多人游戏,Valve Anti-Cheat enabled代表威尔乌防作弊类,Free代表免费,Cross-Platform代表跨平台。右边的游戏是用户历史记录中玩过的游戏。而测试数据中正确推荐的游戏是“Team Fortress 2”。
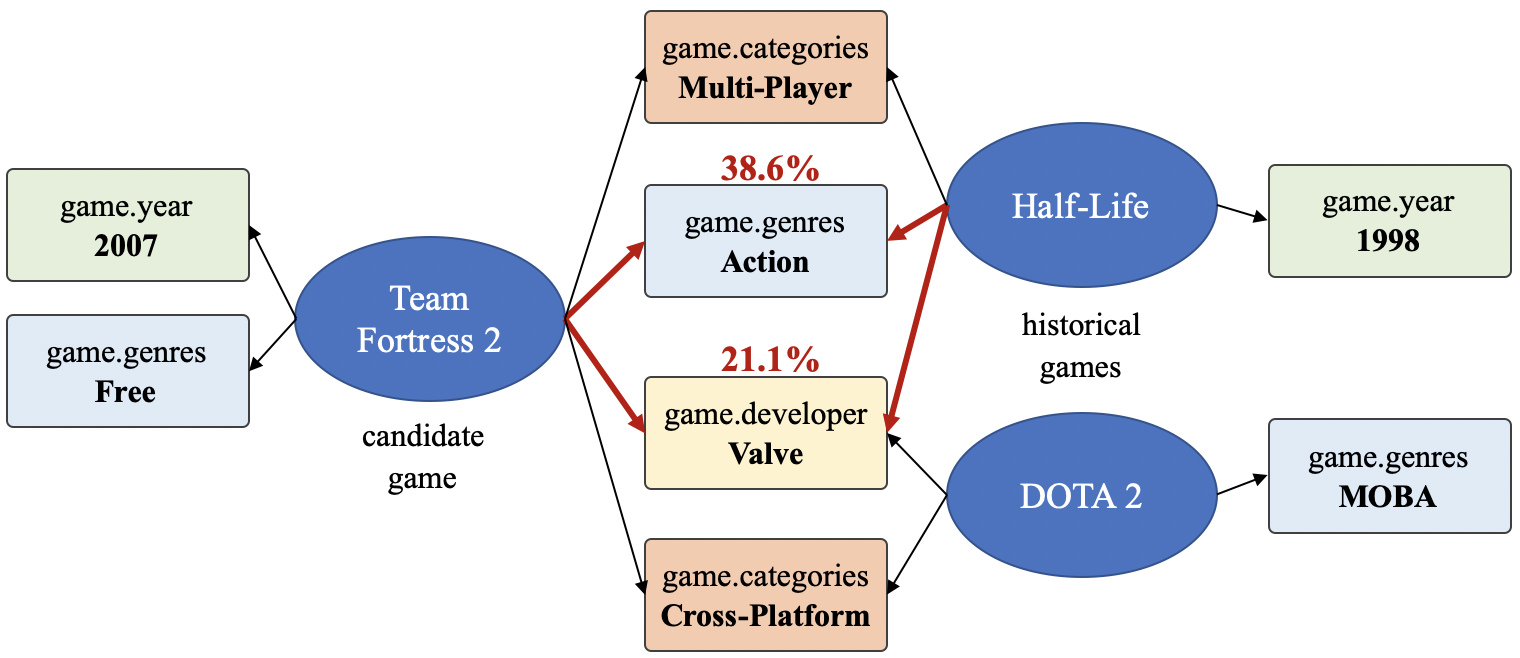
图16.3.7 Steam游戏推荐可解释示例 (用户玩过的游戏: Half-Life, DOAT 2. 推荐命中的游戏: “Team Fortress 2”。具有属性信息的节点如,game.geners: Action, free-to-play; game.developer: Valve; game.categories: Multiplayer, MOBA.)¶
在 图16.3.7中,有两个突出显示的相关概率(38.6%, 21.1%),它们是在推荐过程中模型计算的关键路径被激活的概率。红色箭头突出显示从“Team Fortress 2”到历史项目“Half-Life”之间的关键路径。它表明TB-Net能够通过各种关系连接向用户推荐物品,并找出关键路径作为解释。因此,将“Team Fortress 2”推荐给用户的解释可以翻译成固定话术:“Team Fortress 2”是游戏公司“Valve”开发的一款动作类、多人在线、射击类电子游戏。这与用户历史玩过的游戏“Half-Life”有高度关联。
16.4. 可解释AI系统及实践¶
随着各领域对可解释的诉求快速增长,越来越多企业集成可解释AI工具包,为广大用户提供快速便捷的可解释实践,业界现有的主流工具包有: - TensorFlow团队的What-if Tool,用户不需编写任何程序代码就能探索学习模型,让非开发人员也能参与模型调校工作。 - IBM的AIX360,提供了多种的解释及度量方法去评估模型在各个不同维度上的可解释及可信性能。 - Facebook Torch团队的captum,针对图像及文本场景,提供了多种主流解释方法。 -
微软的InterpretML,用户可以训练不同的白盒模型及解释黑盒模型。 - SeldonIO的Alibi,专注于查勘模型内部状况及决策解释,提供各种白盒、黑盒模型、单样本及全局解释方法的实现。 - 华为MindSpore的XAI工具,提供数据工具、解释方法、白盒模型以及度量方法,为用户提供不同级别的解释(局部,全局,语义级别等)。
本节将以MindSpore
XAI工具为例,讲解在实践中如何使用可解释AI工具为图片分类模型和表格数据分类模型提供解释,从而协助用户理解模型进行进一步的调试调优。
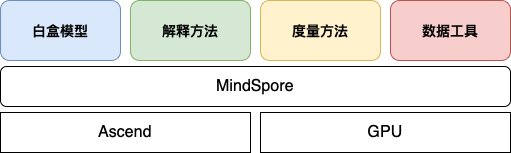
MindSpore
XAI工具的架构如下,其为基于MindSpore深度学习框架的一个可解释工具,可在Ascend及GPU设备上部署。
- width
800px
要使用MindSpore可解释AI,读者首先要通过pip安装MindSpore XAI包(支持MindSpore1.7 或以上,GPU及Ascend 处理器,推荐配合JupyterLab使用):
pip install mindspore-xai
在MindSpore XAI的官网教程中,详细介绍了如何安装和使用提供的解释方法, 读者可自行查阅。
16.4.1. MindSpore XAI工具为图片分类场景提供解释¶
下面结合MindSpore XAI1.8版本中已支持的显着图可视方法 GradCAM 作为一个代码演示例子。读者可参阅官方教程以取得演示用的数据集, 模型和完整脚本代码。
from mindspore_xai.explainer import GradCAM
# 通常指定最后一层的卷积层
grad_cam = GradCAM(net, layer="layer4")
# 3 是'boat'类的ID
saliency = grad_cam(boat_image, targets=3)
如果输入的是一个维度为 \(1*3*224*224\) 的图片Tensor,那返回的saliency就是一个 \(1*1*224*224\) 的显著图Tensor。下面我们将几个例子展示如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优。

图16.4.1 预测结果正确,依据的关键特征合理的例子¶
上图预测标签是“bicycle”,解释结果给出依据的关键特征 在车轮上,说明这个分类判断依据是合理的, 可以初步判定模型为可信的。

图16.4.2 预测结果正确,依据的关键特征不合理的例子¶
上图在预测标签中有1个标签是“person”,这个结果是对的;但是解释的时候,高亮区域在马头的上,那么这个关键特征依据很可能是错误的, 这个模型的可靠性还需进一步验证。

图16.4.3 预测结果错误,依据的关键特征不合理的例子¶
在上图中,预测标签为“boat”,但是原始图像中并没有船只存在,通过图中右侧解释结果可以看到模型将水面作为分类的关键依据,得到预测结果“boat”,这个依据是错误的。通过对训练数据集中标签为“boat”的数据子集进行分析,发现绝大部分标签为“boat”的图片中,都有水面,这很可能导致模型训练的时候,误将水面作为“boat”类型的关键依据。基于此,按比例补充有船没有水面的图片集,从而大幅消减模型学习的时候误判关键特征的概率。
16.4.2. MindSpore XAI工具为表格分类场景提供解释¶
MindSpore XAI 1.8版本支持了三个业界比较常见的表格数据模型解释方法:LIMETabular、SHAPKernel和SHAPGradient。
以LIMETabular为例针对一个复杂难解释的模型,提供一个局部可解释的模型来对单个样本进行解释:
from mindspore_xai.explainer import LIMETabular
# 将特征转换为特征统计数据
feature_stats = LIMETabular.to_feat_stats(data, feature_names=feature_names)
# 初始化解释器
lime = LIMETabular(net, feature_stats, feature_names=feature_names, class_names=class_names)
# 解释
lime_outputs = lime(inputs, targets, show=True)
解释器会显示出把该样本分类为setosa这一决定的决策边界,返回的
lime_outputs 是代表决策边界的一个结构数据。 可视化解释,可得到

- width
400px
上述解释说明针对setosa这一决策,最为重要的特征为petal length。
16.4.3. MindSpore XAI工具提供白盒模型¶
除了针对黑盒模型的事后解释方法,XAI工具同样提供业界领先的白盒模型,使得用户可基于这些白盒模型进行训练,在推理过程中模型可同时输出推理结果及解释结果。以TB-Net为例(可参考:numref:tb_net及其官网教程进行使用),该方法已上线商用,为百万级客户提供带有语义级解释的理财产品推荐服务。TB-Net利用知识图谱对理财产品的属性和客户的历史数据进行建模。在图谱中,具有共同属性值的理财产品会被连接起来,待推荐产品与客户的历史购买或浏览的产品会通过共同的属性值连接成路径,构成该客户的子图谱。然后,TB-Net对图谱中的路径进行双向传导计算,从而识别关键产品和关键路径,作为推荐和解释的依据。
一个可解释推荐的例子如下:在历史数据中,该客户近期曾购买或浏览了理财产品A、B和N等等。通过TB-Net的路径双向传导计算可知,路径(产品P,年化利率_中等偏高,产品A)和路径(产品P,风险等级_中等风险,产品N)的权重较高,即为关键路径。此时,TB-Net输出的解释为:“推荐理财产品P给该客户,是因为它的年化利率_中等偏高,风险等级_中等风险,分别与该客户近期购买或浏览的理财产品A和B一致。”

图16.4.4 TBNet应用金融理财场景¶
除了上面介绍的解释方法外,MindSpore XAI还会提供一系列的度量方法用以评估不同解释方法的优劣,另外也会陆续增加自带解释的白盒模型,用户可直接取用成熟的模型架构以快速构建自己的可解释AI系统。
16.5. 未来可解释AI¶
为了进一步推动可解释AI的研究,我们在此总结了一些值得注意的研究方向。
首先,知识感知型XAI仍有很大的研究扩展空间。然而,要有效地利用外部知识,仍有许多悬而未决的问题。其中一个问题是如何在如此广阔的知识空间中获取或检索有用的知识。例如, 维基百科上记载了各式各样各领域相关的知识, 但如果要解决医学图像分类问题, 维基百科上大部分词条都是无关或存在噪音的, 这样便很难准确地寻找到合适的知识引入到XAI系统中。
此外,XAI系统的部署也非常需要一个更加标准和更加统一的评估框架。为了构建标准统一的评估框架,我们可能需要同时利用不同的指标,相互补充。不同的指标可能适用于不同的任务和用户。统一的评价框架应具有相应的灵活性。
最后,我们相信跨学科合作将是有益的。XAI的发展不仅需要计算机科学家来开发先进的算法,还需要物理学家、生物学家和认知科学家来揭开人类认知的奥秘,以及特定领域的专家来贡献他们的领域知识。
16.6. 参考文献¶
- Chen et al., 2019
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., & Su, J. K. (2019). This looks like that: deep learning for interpretable image recognition. Advances in neural information processing systems, 32.
- Erhan et al., 2009
Erhan, D., Bengio, Y., Courville, A., & Vincent, P. (2009 , 01). Visualizing higher-layer features of a deep network. Technical Report, Univeristé de Montréal.
- Frosst & Hinton, 2017
Frosst, N., & Hinton, G. (2017). Distilling a neural network into a soft decision tree. arXiv preprint arXiv:1711.09784.
- Li et al., 2020(1,2)
Li, X.-H., Cao, C. C., Shi, Y., Bai, W., Gao, H., Qiu, L., … Chen, L. (2020). A survey of data-driven and knowledge-aware explainable ai. IEEE Transactions on Knowledge and Data Engineering, (), 1-1. doi:10.1109/TKDE.2020.2983930
- Nauta et al., 2021
Nauta, M., van Bree, R., & Seifert, C. (2021). Neural prototype trees for interpretable fine-grained image recognition. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14933–14943).
- Petsiuk et al., 2018
Petsiuk, V., Das, A., & Saenko, K. (2018). Rise: randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421.
- Riedl, 2019
Riedl, M. O. (2019). Human-centered artificial intelligence and machine learning. Human Behavior and Emerging Technologies, 1(1), 33–36.
- Selvaraju et al., 2017
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., & Batra, D. (2017). Grad-cam: visual explanations from deep networks via gradient-based localization. Proceedings of the IEEE international conference on computer vision (pp. 618–626).
- Wang et al., 2020
Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., … Hu, X. (2020). Score-cam: score-weighted visual explanations for convolutional neural networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 24–25).
- Zeiler & Fergus, 2014
Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. European conference on computer vision (pp. 818–833).
- Zhang et al., 2018
Zhang, Q., Wu, Y. N., & Zhu, S.-C. (2018). Interpretable convolutional neural networks. Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8827–8836).
- Zhang et al., 2019
Zhang, Q., Yang, Y., Ma, H., & Wu, Y. N. (2019). Interpreting cnns via decision trees. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6261–6270).